Original link: https://www.luozhiyun.com/archives/710
Please declare the source for reprinting~, this article was published on luozhiyun’s blog: https://www.luozhiyun.com/archives/710
The kernel code for this article is Linux 0.11
In the previous article, we looked at how exceptions and interrupts in computer systems are done. In this article, we will look at how fork uses exceptions to create processes and how COW is implemented.
use
The fork function is a system call function, which is used to create a new process, as follows:
#include <unistd.h> #include <stdlib.h> #include <stdio.h> int main(int argc, char *argv[]) { printf("hello world (pid:%d)\n", (int) getpid()); int rc = fork(); if (rc < 0) { // fork failed fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child (new process) printf("hello, I am child (pid:%d)\n", (int) getpid()); } else { // parent goes down this path (main) printf("hello, I am parent of %d (pid:%d)\n", rc, (int) getpid()); wait(NULL); } return 0; }
Let’s do it:
hello world (pid:5093) hello, I am parent of 5094 (pid:5093) hello, I am child (pid:5094)
In the above example, the process number is output three times. After calling the fork function, if it is the parent process, it will return the child process number, and if it is a child process, it will return 0. Therefore, the parent and child processes can be judged above by the process number returned by fork. And the child process that is forked will not start executing from the main function, but will then execute the fork function down, as if calling the fork function by itself.
The reason why the parent process calls the wait function is to wait for the child process and synchronize the state of the child process. Otherwise, orphan processes or zombie processes may be generated, which we will talk about later.
Another point to note is that the scheduling of the parent and child processes is random, and there is no requirement that the parent process scheduling will be scheduled before the child process.
Fork function implementation process
Processes are created by other processes. Each process has its own PID (process identification number). There is an inheritance relationship between processes in the Linux system. All processes are descendants of the init process (process No. 1). . You can view the family tree of the process with the pstree command. All processes in Linux are described by task_struct, which maintains a linked list structure of parent-child process tree through parent and children fields.
The fork function is a way to create a child process. It is a system call function, so let’s take a look at system_call before looking at the fork system call.
The system call handler function system_call is hooked up with the int 0x80 interrupt descriptor table. system_call is the general entry for system call soft interrupts in the entire operating system. All user programs use system calls. After the int 0x80 soft interrupt is generated, the operating system finds the specific system call function through this general entry.
The system call function is the basic support of the operating system for the user program. In the operating system, things like reading disks and creating child processes need to be implemented through system calls. After the system call is called, it will trigger the int 0x80 soft interrupt, and then switch from user mode to kernel mode (flip from the 3 privilege level of the user process to the 0 privilege level of the kernel), find the system call port through IDT, and call the specific system call function To process things, after the processing is completed, the iret instruction returns to the user mode to continue to execute the original logic.
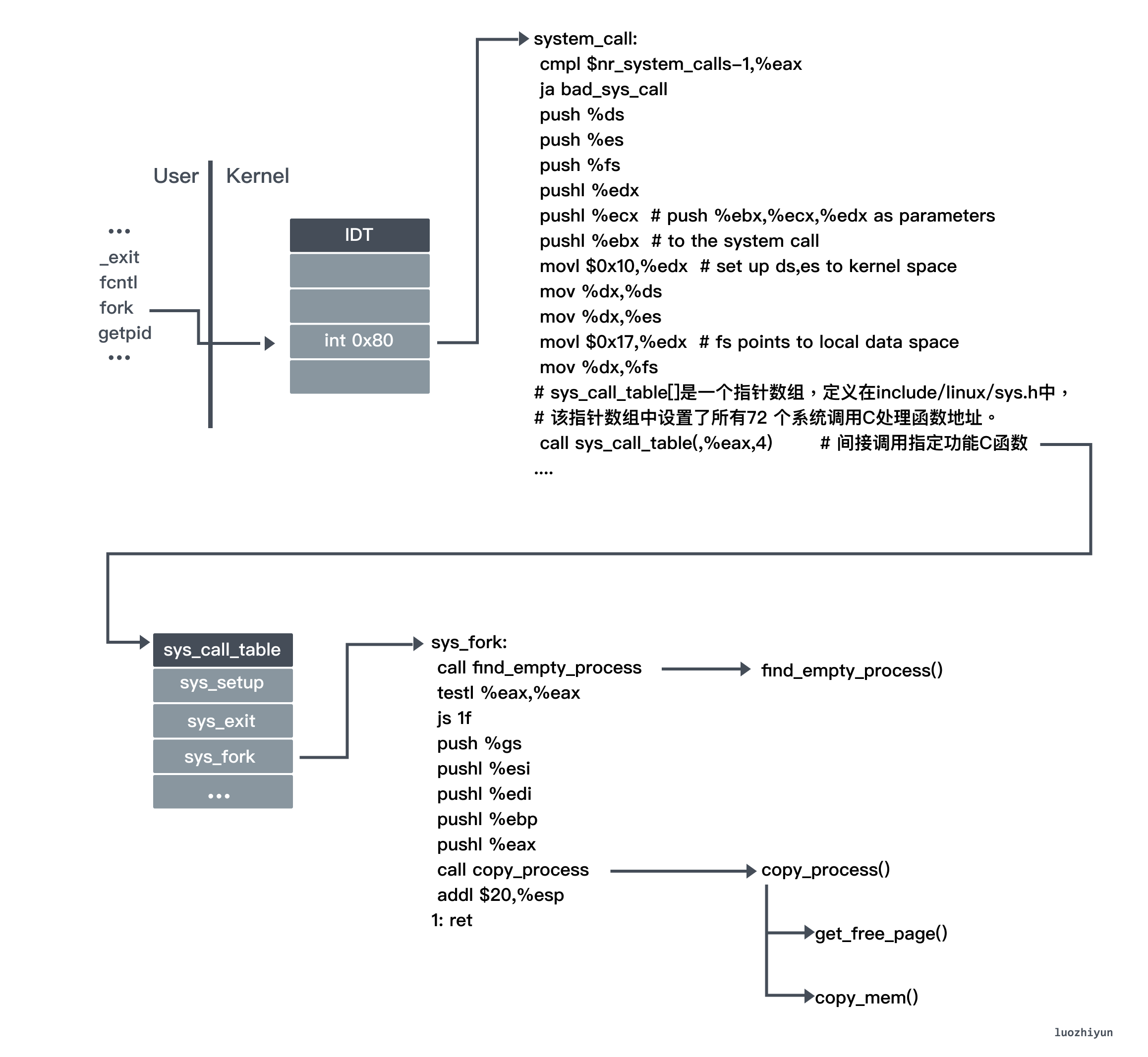
Because the fork function is also one of the functions of the system call, it is also triggered by the int 0x80 soft interrupt. After triggering the int 0x80 soft interrupt, it will switch to the kernel state, and find the corresponding function in sys_call_table according to the fork index (that is, 2):
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read, sys_write, sys_open, sys_close... };
Then get the corresponding C function sys_fork. Because the function name corresponding to C in the change will be preceded by an underscore, it will jump to _sys_fork for execution.
In _sys_fork, find_empty_process will be called first to apply for a free position and obtain a new process number pid. The free position is determined by the task[64] array, which means that at most 64 processes can be running at the same time, and the global variable last_pid is used to store the accumulated number of processes since the system was started. If there is a free position, then ++last_pid is used as the The process ID of the new process, the index of the free position found in task[64] is used as the task ID .
_sys_fork then calls copy_process to copy the process:
- Copy the task_struct to the child process, the task_struct is used to define the process structure, which contains all the information about the process;
- Then make some modifications and initialize the contents of the copied process structure to 0. For example, status, process ID, parent process ID, running time, etc., as well as initialization of some statistical information, most of the rest remain unchanged;
- Then copy_mem will be called to copy the page table of the process, but since the Linux system adopts the copy on write technology, only the new process will set its own page directory table entry and page table entry, but not actually for the new process. Physical memory pages are allocated, at which point the new process shares all physical memory pages with its parent process.
-
Finally, the TSS (Task State Segment) segment and the LDT (Local Descriptor Table) segment descriptor item of the child process are set in the GDT table, and the child process number is returned. The TSS segment is used to store information describing the process, such as some registers, the current privilege level, etc.;
It should be noted that the child process will also inherit the file descriptor of the parent process, that is, the child process will copy all the file descriptor entries of the parent process, that is to say, if the parent process and the child process write a file at the same time, it may occur. The problem of concurrent writing causes the data to be written to be chaotic.
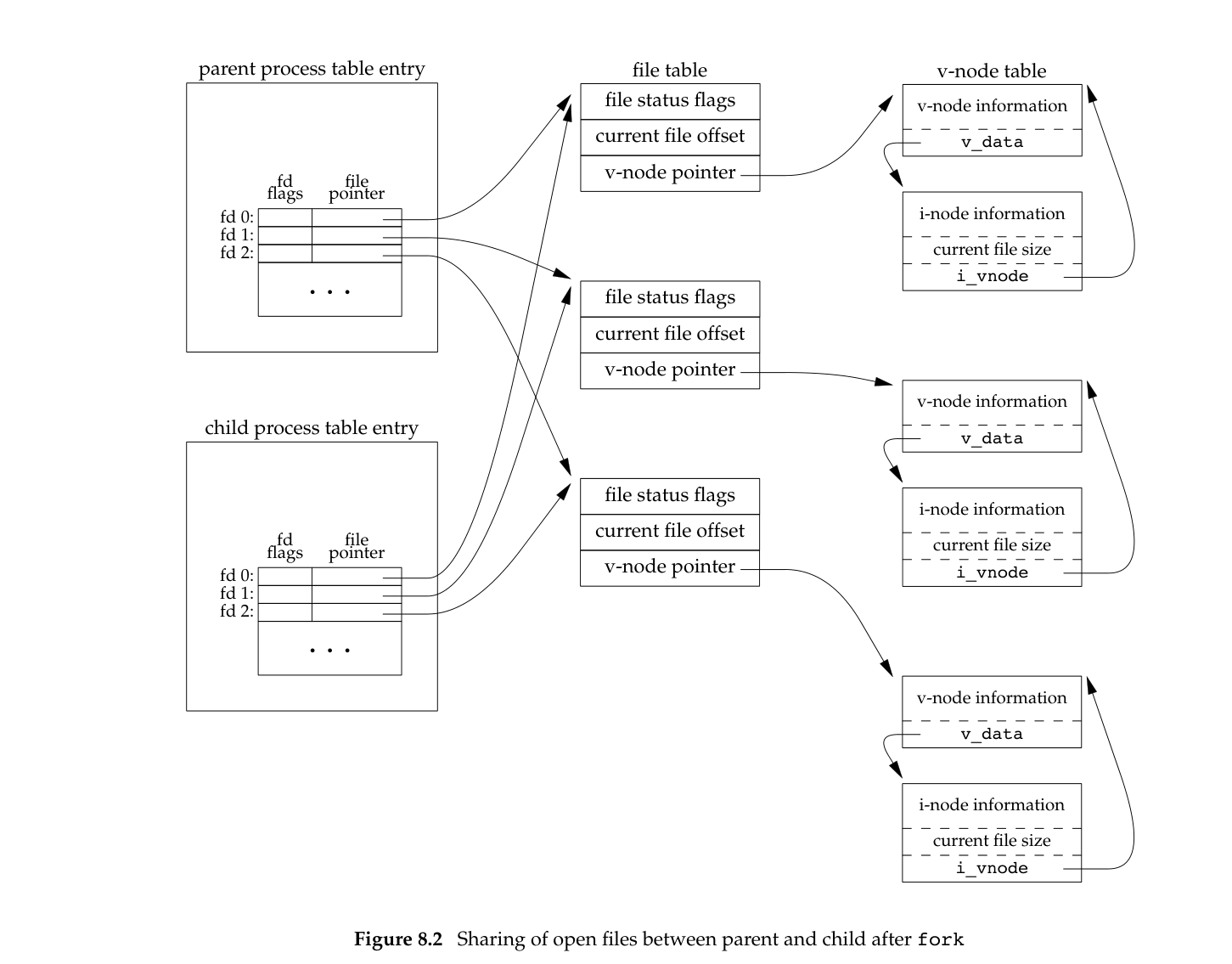
Copy-On-Write
Copy-on-write ( COW ), sometimes referred to as implicit sharing [1] or shadowing , [2] is a resource-management technique used in computer programming to efficiently implement a “duplicate” or “copy” operation on modifiable resources. [3] If a resource is duplicated but not modified, it is not necessary to create a new resource; the resource can be shared between the copy and the original. Modifications must still create a copy, hence the technique: the copy operation is deferred until the first write.
According to the definition of COW above, it is a resource optimization strategy for delayed copying. It is usually used in copy replication operations. If a resource is only copied but not modified, the resource will not be really created, but will be the same as the original one. data sharing. So this technique can defer the copy operation until after the first write.
After the fork function is called, at this time, because of the existence of Copy-On-Write (COW), the parent and child processes actually share the physical memory, and do not directly copy a copy. The kernel sets the permissions of all memory pages that will be shared to read-only. When the parent and child processes read only memory, and then execute the exec function, a lot of data copying overhead can be saved.
// todo is equipped with a picture here, the memory is shared
When one of the processes writes to the memory, the memory management unit MMU detects that the memory page is read-only, so it triggers a page-fault exception, and the processor obtains the corresponding data from the Interrupt Descriptor Table (IDT). handler. In the interrupt program, the kernel will copy a page of the triggered exception , so the parent and child processes each hold an independent copy, and then the process will modify the corresponding data.
The benefits of COW are obvious, but it also has corresponding disadvantages. If both parent and child processes need to perform a large number of write operations, a large number of page-faults will be generated. The page fault exception is not without cost, it will cause the processor to stop executing the current program or task and instead execute the program dedicated to handling interrupts or exceptions. The processor will obtain the corresponding processing program from the Interrupt Descriptor Table (IDT). When the exception or interrupt is executed, it will continue to return to the interrupted program or task to continue execution.

That is to say, a page fault exception will cause a context switch, and then query the process of copying data to a new physical page. If you find that the memory is not enough when allocating a new physical page, you need to perform swap, execute the corresponding elimination strategy, and then Replace with a new page. So avoid a lot of write operations after fork.
Orphan Processes & Zombie Processes
Because Linux provides a mechanism to ensure that as long as the parent process wants to know the status information when the child process ends, it can get it. So even if the child process finishes running, it will still hang there, and the parent process can get some status information, and it will not be released until the parent process gets it through wait / waitpid.
If the process does not call wait / waitpid, the reserved information will not be released, and its process ID will always be occupied, which is how the zombie process is born. If a large number of zombie processes are generated, the system will not be able to generate new processes because there is no available process ID, so it is harmful to some extent.
An orphan process is a parent process that exits while one or more of its child processes are still running, then those child processes will become orphan processes. The orphan process will be hung under the init process (process 1), and the init process will wait for its exited child process cyclically, so the orphan process is fine.
Summarize
This article is still relatively clear, and there is no major concept. First of all, before understanding fork, you need to understand the exception & interrupt mechanism of the operating system. Fork will trigger a soft interrupt and fall into the system call function. Finally, according to the system function call table, find the corresponding processing function to create a child process. Colleagues copy some data of the parent process. However, although the virtual page table is copied at this time, due to the existence of COW, the physical memory will not be copied immediately, but will be delayed until the time of writing, and the physical memory data will be copied through the page fault interrupt, and finally the orphan process is added. & the knowledge point of the zombie process as a finishing touch.
Reference
“Understanding Computer Systems”
“The Artistic Illustration of Linux Kernel Design”
“Advanced.Programming.in.the.UNIX.Environment.3rd.Edition”
https://en.wikipedia.org/wiki/Copy-on-write

The principle of Fork & Copy-on-Write COW first appeared on luozhiyun`s Blog .
This article is reproduced from: https://www.luozhiyun.com/archives/710
This site is for inclusion only, and the copyright belongs to the original author.