Original link: https://luyuhuang.tech/2022/10/30/lock-free-queue.html
In the previous article we discussed the memory order of atomic variables in C++, now let’s look at the application of atomic variables and memory order – lock-free queues. This article introduces the simplicity of write-single-read and multi-write-multiple-read lock-free queues Implementation, from which you can see some basic ideas of lock-free data structure design.
What is lock-free
In order to implement a thread-safe data structure, the easiest way is to lock. For queues, the enqueue and dequeue operations should be locked.
template < typename T > void queue :: push ( const T & val ) { std :: lock_guard < std :: mutex > guard ( m_lock ); auto node = new node ( val ); ... } template < typename T > T queue :: pop () { std :: lock_guard < std :: mutex > guard ( m_lock ); ... }
The problem with such a queue is that only one thread can perform enqueue and dequeue operations at a time, so the operations of the queue are actually serialized. If multiple threads access the same queue at the same time, the queue may become concurrent The bottleneck. To solve this problem, we can consider using lock-free queues in some scenarios.
Lock-free data interfaces can be divided into three categories:
- nonblocking structure
- Using spinlocks instead of mutexes, no context switching occurs.
- It is not lock-free, it does not allow concurrent access, and there is also the problem of serialization of operations.
- lock-free structure
- Well-designed operations to achieve concurrent access through CAS (compare and swap) atomic operations. Multiple threads can access at the same time.
- There are spinlock-like loops that need to be checked and waited in the loop.
- wait-free structure
- There are no spinlock-like loops, operations only need to execute a certain number of instructions.
Below we introduce several simple implementations of lock-free queues.
write-single-read queue
The single-write single-read queue is relatively simple. Here we use a circular queue to implement it. As shown in the figure below, the queue maintains two pointers head and tail , which point to the head and tail of the queue respectively. The tail always points to the dummy node, so tail == head means The queue is empty, (tail + 1) % Cap == head means the queue is full, no need to maintain size members.

The tail pointer is moved when entering the queue, and the head pointer is moved when dequeuing. There is no conflict between the two operations. However, the tail pointer needs to be read before leaving the queue, and it is judged that tail != head to confirm that the queue is not empty; Also check (tail + 1) % Cap != head to confirm that the queue is not full. Since there are multiple threads reading and writing these two pointers, they should both be atomic variables.
In addition, since the two operations are performed in different threads, we also need to consider the memory order. If the initial queue is empty, thread a performs the enqueue operation first, and thread b performs the dequeue operation later, the content of thread a’s enqueue operation must be Visible to thread b.

In order to do this, there needs to be a(2) “happens-before” b(3). And a(3) and b(2) modify and read tail respectively, so atomic variable synchronization should be used, so that a( 3) “synchronizes-with” b(2). You can use release in the operation of a(3) writing the tail , and b(2) using acquire in the operation of reading the tail . Students who are not familiar with the memory order can refer to Previous article .
Similarly, if the initial queue is full, thread a performs the dequeue operation first, and thread b performs the enqueue operation after that, the result of the dequeue operation of thread a should be visible to thread b. The dequeue element needs to be called when dequeuing. function, it is necessary to ensure that the dequeued element is destroyed normally before writing a new element in that position, otherwise it will cause memory corruption. You can use release in the operation of dequeuing to write the head , and use acquire in the operation of entering the queue to read the head . The team “synchronizes-with” is enqueued.
template < typename T , size_t Cap > class spsc : private allocator < T > { T * data ; atomic < size_t > head { 0 }, tail { 0 }; public: spsc () : data ( allocator < T >:: allocate ( Cap )) {} spsc ( const spsc & ) = delete ; spsc & operator = ( const spsc & ) = delete ; spsc & operator = ( const spsc & ) volatile = delete ; bool push ( const T & val ) { return emplace ( val ); } bool push ( T && val ) { return emplace ( std :: move ( val )); } template < typename ... Args > bool emplace ( Args && ... args ) { // 入队操作size_t t = tail . load ( memory_order_relaxed ); if (( t + 1 ) % Cap == head . load ( memory_order_acquire )) // (1) return false ; allocator < T >:: construct ( data + t , std :: forward < Args > ( args )...); // (2) synchronizes-with (3) tail . store (( t + 1 ) % Cap , memory_order_release ); // (2) return true ; } bool pop ( T & val ) { // 出队操作size_t h = head . load ( memory_order_relaxed ); if ( h == tail . load ( memory_order_acquire )) // (3) return false ; val = std :: move ( data [ h ]); allocator < T >:: destroy ( data + h ); // (4) synchronizes-with (1) head . store (( h + 1 ) % Cap , memory_order_release ); // (4) return true ; } };
The two operations of this single-write single-read lock-free queue can be performed at the same time, and both operations only need to execute a certain number of instructions, so the data wait-free structure has high performance.
CAS operation
CAS (compare and swap) is an atomic operation that performs comparison and exchange in an uninterruptible process. There are two CAS operations in C++’s std::atomic , compare_exchange_weak and compare_exchange_strong
bool std :: atomic < T >:: compare_exchange_weak ( T & expected , T desired ); bool std :: atomic < T >:: compare_exchange_strong ( T & expected , T desired );
The two CAS operations are basically the same: if the atomic variable is equal to expected , assign it to desired and return true ; otherwise, assign expected to the current value of the atomic variable and return false . Below is a pseudo-implementation of compare_exchange_strong
template < typename T > bool atomic < T >:: compare_exchange_strong ( T & expected , T desired ) { std :: lock_guard < std :: mutex > guard ( m_lock ); if ( m_val == expected ) return m_val = desired , true ; else return expected = m_val , false ; }
Of course the actual implementation cannot be like this. On x86 compare_exchange_* will be compiled into a cmpxchgl instruction, so the operation is atomic and lock-free.
int foo ( std :: atomic < int > & a ) { int e = 42 ; a . compare_exchange_strong ( e , e + 1 ); return a . load (); }
Under x86-64 -O2 compiles to:
foo ( std :: atomic < int >& ): movl $ 42 , % eax movl $ 43 , % edx lock cmpxchgl % edx , ( % rdi ) # % rdi为函数的第一个参数movl ( % rdi ), % eax ret
The difference between compare_exchange_weak and compare_exchange_strong is that compare_exchange_weak may still not perform the exchange and return false when the current value is equal to expected ; compare_exchange_strong will not have this problem. The weak version allows the compiler to generate some better code on some platforms, There is no difference under x86.
compare_exchange_* supports specifying two memory orders: memory order on success and memory order on failure.
bool compare_exchange_weak ( T & expected , T desired , std :: memory_order success , std :: memory_order failure );
We can implement many lock-free data structures using CAS operations. Let’s see how to implement a multi-write multi-read queue.
multi-write multi-read queue
To illustrate that the single-write-single-read queue implemented earlier cannot perform multiple writes and multiple reads, let’s look at an example.
bool spsc < T , Cap >:: pop ( T & val ) { size_t h = head . load (); // (1) if ( h == tail . load ()) return false ; val = std :: move ( data [ h ]); // (2) allocator < T >:: destroy ( data + h ); head . store (( h + 1 ) % Cap ); // (3) return true ; }
Suppose there are two threads a and b calling pop at the same time, the execution order is a(1), b(1), b(2) a(2). In this case, both thread a and thread b read the same head Pointer, stored in variable h . When a(2) tries to read data[h] , the data in it has been moved in b(2). Therefore, such a queue does not allow multiple threads to perform pop operations at the same time .
Solve the preemption problem
It can be seen that the entire pop function is a non-atomic process. Once the process is preempted by other threads, there will be problems. How to solve this problem? In lock-free data structures, a common practice is to keep retrying . Specifically The approach is to design a CAS operation in the last step of the non-atomic process. If the process is preempted by other threads, the CAS operation fails and the entire process is re-executed. Otherwise, the CAS operation succeeds and the last step of the entire process is completed.
bool spsc < T , Cap >:: pop ( T & val ) { size_t h ; do { h = head . load (); // (1) if ( h == tail . load ()) return false ; val = data [ h ]; // (2) } while ( ! head . compare_exchange_strong ( h , ( h + 1 ) % Cap )); // (3) return true ; }
First notice that we no longer use std::move and allocator::destroy , but copy directly, so that operations inside the loop do not modify the queue itself. (3) is the last step in the whole process, and the only one that modifies the queue , we use a CAS operation. Only when the value of head is equal to the value obtained in step (1), will the head pointer be moved, and return true to break out of the loop; otherwise, keep retrying.
In this way, if multiple threads execute pop concurrently, only the thread that successfully executes (3) is considered to have successfully executed the entire process, and other threads will be preempted, resulting in the head being modified when executing (3), so it is different from the local variable. h is not equal, causing the CAS operation to fail. This makes them retry the entire process.
A similar idea can be used for push . See what happens if we modify push in the same way:
bool spsc < T , Cap >:: push ( const T & val ) { size_t t ; do { t = tail . load (); // (1) if (( t + 1 ) % Cap == head . load ()) return false ; data [ t ] = val ; // (2) } while ( ! tail . compare_exchange_strong ( t , ( t + 1 ) % Cap )); // (3) return true ; }
Different from the pop operation, the step (2) of the push operation needs to assign a value to data[t] , which causes the operation in the loop body to modify the queue. Suppose the execution order of the two threads a and b is a(1), a(2) , b(1), b(2), a(3). a can be successfully executed to (3), but the enqueued value is overwritten by b(2).
We try to move the assignment data[t] = val outside the loop, so that the operations inside the loop don’t modify the queue. When the loop exits, it ensures that tail is moved back one space and t points to before tail moved The location. This way no other thread will overwrite the value we write during concurrency.
bool spsc < T , Cap >:: push ( const T & val ) { size_t t ; do { t = tail . load (); // (1) if (( t + 1 ) % Cap == head . load ()) return false ; } while ( ! tail . compare_exchange_strong ( t , ( t + 1 ) % Cap )); // (2) data [ t ] = val ; // (3) return true ; }
But the problem with this is that we move the tail pointer first and then assign data[t] , which will cause incorrect concurrency of push and pop . Review the code of pop :
bool spsc < T , Cap >:: pop ( T & val ) { size_t h ; do { h = head . load (); if ( h == tail . load ()) // (4) return false ; val = data [ h ]; // (5) } while ( ! head . compare_exchange_strong ( h , ( h + 1 ) % Cap )); return true ; }
Also assume there are two threads a and b. Suppose the queue is initially empty
- Thread a calls
push, executes a(1), a(2).tailis updated, then switches to thread b - Thread b calls
popand executes b(4). Becausetailis updated, it is judged that the queue is not empty - Execute to b(5), an invalid value will be read

In order to realize the concurrency of push and pop , the writing of push to data[t] must “happens-before” the reading of data[h] by pop . Therefore, this requires the push operation to assign data[t] first, and then move the tail Pointer. But in order to realize the concurrency of push and push , we let the push operation move tail first and then assign data[t] . How to solve this contradiction?
The solution is to introduce a new pointer write for push and pop synchronization. It indicates where the push operation is written to .
template < typename T , size_t Cap > class ring_buffer { T data [ Cap ]; atomic < size_t > head { 0 }, tail { 0 }, write { 0 }; public: ring_buffer () = default ; ring_buffer ( const ring_buffer & ) = delete ; ring_buffer & operator = ( const ring_buffer & ) = delete ; ring_buffer & operator = ( const ring_buffer & ) volatile = delete ; bool push ( const T & val ) { size_t t , w ; do { t = tail . load (); if (( t + 1 ) % Cap == head . load ()) return false ; } while ( ! tail . compare_exchange_weak ( t , ( t + 1 ) % Cap )); // (1) data [ t ] = val ; // (2) do { w = t ; } while ( ! write . compare_exchange_weak ( w , ( w + 1 ) % Cap )); // (3), (3) synchronizes-with (4) return true ; } bool pop ( T & val ) { size_t h ; do { h = head . load (); if ( h == write . load ()) // (4) 读write 的值return false ; val = data [ h ]; // (5) } while ( ! head . compare_exchange_strong ( h , ( h + 1 ) % Cap )); return true ; } };
The basic steps of the push operation are:
- move the
tail; - Assign value to
data[t],tis equal to the position beforetailmoves; - Move
write.writeequalstailafter moving.
The pop operation uses the write pointer to determine whether there is an element in the queue. Because there are (3) “synchronizes-with” (4), so (2) “happens-before” (5), pop can read the value written by push . In the push function, only when the current write is equal to t can write be moved by one space, which can ensure that the final write is equal to tail .
The two operations of this multi-write multi-read lock-free queue can be performed at the same time, but each operation may have to be retried, so it belongs to a lock-free structure.
Consider memory order
The previous example uses the default memory order, which is memory_order_seq_cst. In order to optimize performance, a more relaxed memory order can be used. To consider the memory order, it is necessary to find out the happens-before relationship.
As analyzed earlier, the assignment operation data[t] = val in push requires “happens-before” the read operation val = data[h] in pop , which is achieved through the write atomic variable: the modification of write in push requires “synchronizes-with” the read of write in pop . Therefore, the CAS operation of push to modify write should use release, and when pop reads write , acquire should be used.
Similarly, when the queue is initially full, first run pop and then push , to ensure that the read operation in pop is val = data[h] “happens-before” The assignment operation in push is data[t] = val . This It is implemented through the head atomic variable: the modification of the head in pop “synchronizes-with” the read of the head in the push . Therefore, the CAS operation of pop modifying the head should use release, and the push should use acquire when reading the head .
bool ring_buffer < T , Cap >:: push ( const T & val ) { size_t t , w ; do { t = tail . load ( memory_order_relaxed ); // (1) if (( t + 1 ) % Cap == head . load ( memory_order_acquire )) //(2) return false ; } while ( ! tail . compare_exchange_weak ( t , ( t + 1 ) % Cap , memory_order_relaxed )); // (3) data [ t ] = val ; // (4), (4) happens-before (8) do { w = t ; } while ( ! write . compare_exchange_weak ( w , ( w + 1 ) % Cap , memory_order_release , memory_order_relaxed )); // (5), (5) synchronizes-with (7) return true ; } bool ring_buffer < T , Cap >:: pop ( T & val ) { size_t h ; do { h = head . load ( memory_order_relaxed ); // (6) if ( h == write . load ( memory_order_acquire )) // (7) return false ; val = data [ h ]; // (8), (8) happens-before (4) } while ( ! head . compare_exchange_strong ( h , ( h + 1 ) % Cap , memory_order_release , memory_order_relaxed )); // (9), (9) synchronizes-with (2) return true ; }
When push and push move the tail pointer concurrently, only the tail itself is affected. Therefore, (1) and (3) can use relaxed for tail reading and writing. Similarly, when push and push move the write pointer concurrently, there is no need to use it to do synchronization, so the action at (5) is
write . compare_exchange_weak ( w , ( w + 1 ) % Cap , memory_order_release , memory_order_relaxed )
Use release on success, in order to synchronize with pop ; and use relaxed on failure.
In the same way, when pop and pop move the head concurrently, it also affects the head itself. Therefore, (6) To read the head , use relaxed. In (9), in order to synchronize with the push , use release when it succeeds, and use relaxed when it fails. Can.
Advantages and disadvantages
Advantage
- Simple to implement and easy to understand (compared to more complex chain structures)
- Lock-free high concurrency. Although there are cyclic retries, this only occurs when the same operation is concurrent. push will not be retried because it is concurrent with pop, and vice versa.
defect
- This way the queue should only store scalars, not objects (but can store pointers), for two reasons
- In pop, val = data[h] will be executed in a loop, and the copy of the object will have performance overhead
- Executing data[t] = val in push is similar. If the copy time is too long, it may cause threads that concurrently execute push to wait all the time.
- If data[t] = val in push throws an exception, it may lead to deadlock of threads executing push concurrently
- Smart pointers cannot be stored. Because the object is still in the data array after dequeuing, it is not destroyed.
- The capacity is fixed and cannot be dynamically expanded.
Performance Testing
Set different number of producer and consumer threads, each producer inserts 10000 elements into the sequential queue. The following is the test result, ” X p Y c” means X producers and Y consumers. The ordinate is the time-consuming .
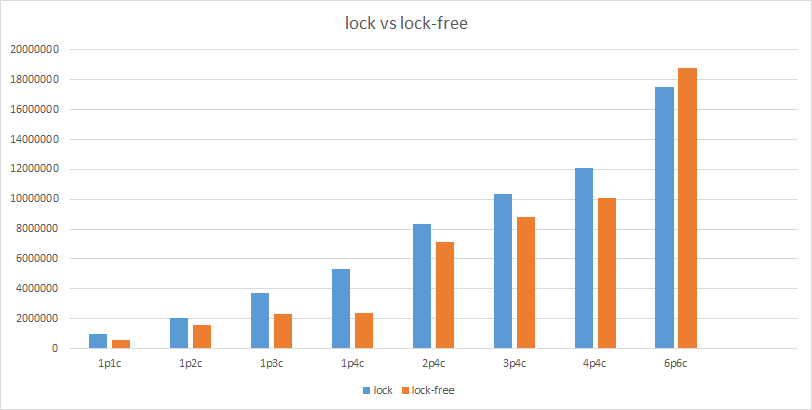
It can be seen that the lock-free queue is not always the fastest. When the number of producers increases, the performance begins to decline, because tail and write need to be preempted when entering the queue. In practical applications, specific analysis is required.
References:
- C++ Concurrency in Action: Practical Multithreading, Anthony Williams.
This article is reprinted from: https://luyuhuang.tech/2022/10/30/lock-free-queue.html
This site is for inclusion only, and the copyright belongs to the original author.