Content source: ChatGPT and large-scale model seminar sharing guest: Fudan University professor Qiu Xipeng sharing topic: “Conversational large-scale language model”
Reprinted from CSDN manuscript
Since its inception, ChapGPT has demonstrated its amazing dialogue ability. In just two months, ChatGPT has 100 million monthly active users, making it the fastest growing consumer app in history. It is a great opportunity and challenge for academia, industry, or other related applications. In fact, the success of ChatGPT is not accidental, and there are many innovations behind it. This article is compiled at the “ChatGPT and Large Model Symposium” organized by Daguan Data. Professor Qiu Xipeng of Fudan University brought the topic sharing of “Conversational Large-scale Language Model”. He brought changes from large-scale pre-trained language models, ChatGPT The relevant knowledge of large-scale language models is introduced in depth from the perspective of key technologies and their limitations.

Qiu Xipeng, professor of School of Computer Science, Fudan University, director of MOSS system
Why a big language model?
With the continuous improvement of computing power, the language model has developed from the initial model based on probability prediction to the pre-trained language model based on Transformer architecture, and is gradually moving towards the era of large models. Why highlight the large language model or add “Large” in front? What’s more important is its emergent ability.
When the model size is small, the performance and parameters of the model roughly conform to the law of scaling, that is, the performance improvement of the model and the parameter growth basically have a linear relationship. However, when GPT-3/ChatGPT, a large-scale model of hundreds of billions, was proposed, it was found that it could break the law of scaling and achieve a qualitative leap in model capabilities. These capabilities are also known as the “emergent capabilities” of the large model (such as understanding human instructions, etc.).

The figure above shows the performance change curves of multiple NLP tasks as the scale of the model expands. It can be seen that the previous performance and the scale of the model are roughly linear. When the scale of the model reaches a certain level, the performance of the task changes significantly.
Therefore, the amount of tens of billions/hundred billions of parameters is usually used as a watershed for LLM research. In addition, the large-scale language model base is highly scalable, and it can easily connect with the outside world, continuously accept knowledge updates from the outside world, and then achieve repeated self-iteration. Therefore, large-scale language models are also seen as the hope of realizing general artificial intelligence.
Three key technologies of ChatGPT
At present, many companies and organizations are following the trend of ChatGPT and launching similar chat robot products. This is mainly because the success of ChatGPT has brought confidence to people, proved the feasibility and potential of chat robot technology, and allowed people to see the huge market and application prospects of chat robots in the future.
The three key technologies of ChatGPT are: situational learning, thinking chain, and natural instruction learning. Next, we will introduce these three technologies in detail.
- In-context learning
This changes the previous paradigm that required the use of large models for downstream tasks. For some new tasks that LLM has never seen, it is only necessary to design some task language descriptions and give a few task examples as input to the model, so that the model can learn new tasks from a given situation and give satisfactory results. Answer the result. This training method can effectively improve the ability of the model to learn from small samples.

Example Diagram of Situational Learning
It can be seen that LLM can judge the emotional polarity of the new input data only by describing two examples of the input and output of the sentiment classification task in the form of natural language. For example, if you make a movie review and give the corresponding task model, you can output a positive answer.
- Chain-of-Thought (CoT)
For some logically complex questions, asking questions directly to a large-scale language model may get inaccurate answers, but if you give examples of logical problem-solving steps in the input in a prompt manner and then ask questions, the large-scale model will be more accurate. can give the correct solution. That is to say, the correct answer can be obtained by dismantling complex problems into multiple sub-problems and then extracting answers from them.
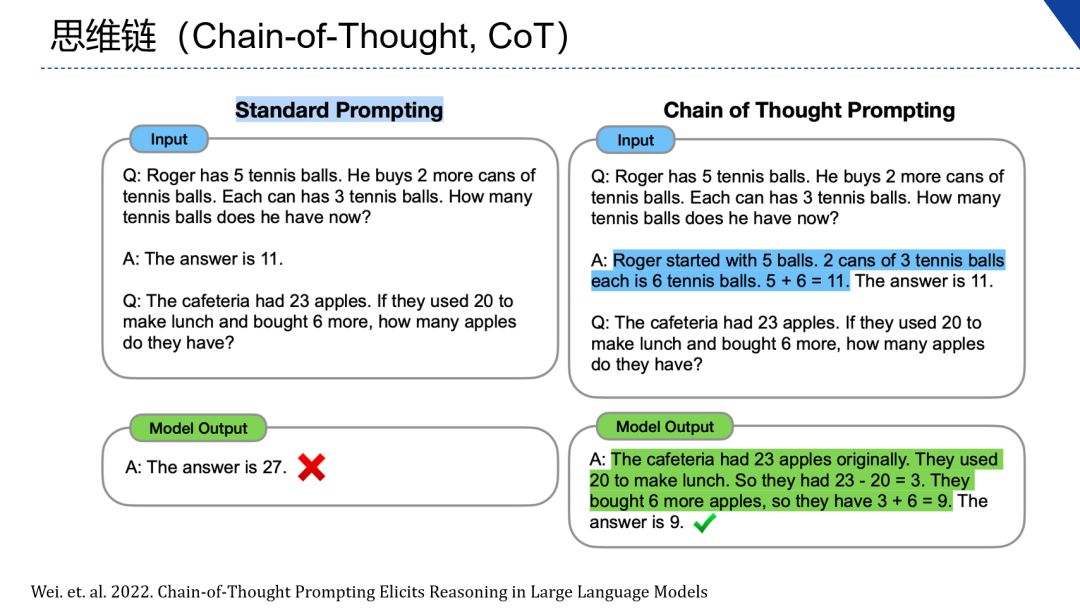
Schematic diagram of chain of thought
As shown in the schematic diagram of the thinking chain, the left side is directly asking the model to perform calculations on math problems to get wrong results, while the right side adds an example in the problem-solving process, and introducing the problem-solving process can stimulate the reasoning ability of the model, thereby obtaining correct result.

This is a simple method that can be separated from the chain of thinking through computing power, which helps the large model to complete the task, thereby reducing the burden on the neural network.
Because CoT technology can stimulate the ability of large-scale language models to solve complex problems, this technology is also considered to be the key to breaking the law of scaling.
- Learning from Natural Instructions
Early researchers hoped to instruct all natural language processing tasks and label data for each task. This training method is to add an “instruction” in front, which can describe the task content in the form of natural language, so that the large model can output the expected answer of the task according to the input. This method further aligns downstream tasks with natural language forms, which can significantly improve the generalization ability of the model for unknown tasks.

Schematic diagram of natural instruction learning
As shown in the schematic diagram of natural instruction learning, the test scene of natural instructions is on the left. People perform more than 1,000 NLP tasks. Currently, the latest model can perform more than 2,000 NLP tasks. Next, classify NLP tasks, such as ability A , Ability B, large model instruction ability, generalization ability is very strong, can generalize to hundreds of tasks after learning forty or fifty tasks. But there is still one step away from the real ChatGPT, which is to align with real human intentions. This is the GPT made by OpenAI.
The core logic is very simple. In the beginning, people wrote the answers, but the cost was too high. Instead, people choose the answers. This requires a little less ability for the annotators, and can quickly increase the iteration and scale. Based on the scoring, train a scorer, automatically evaluate the quality of the model through the scorer, and then use reinforcement learning to start iterating. This method can iterate the data model on a large scale. This is the Instruct GPT logic made by OpenAI. Strengthening Human Feedback for Learning.
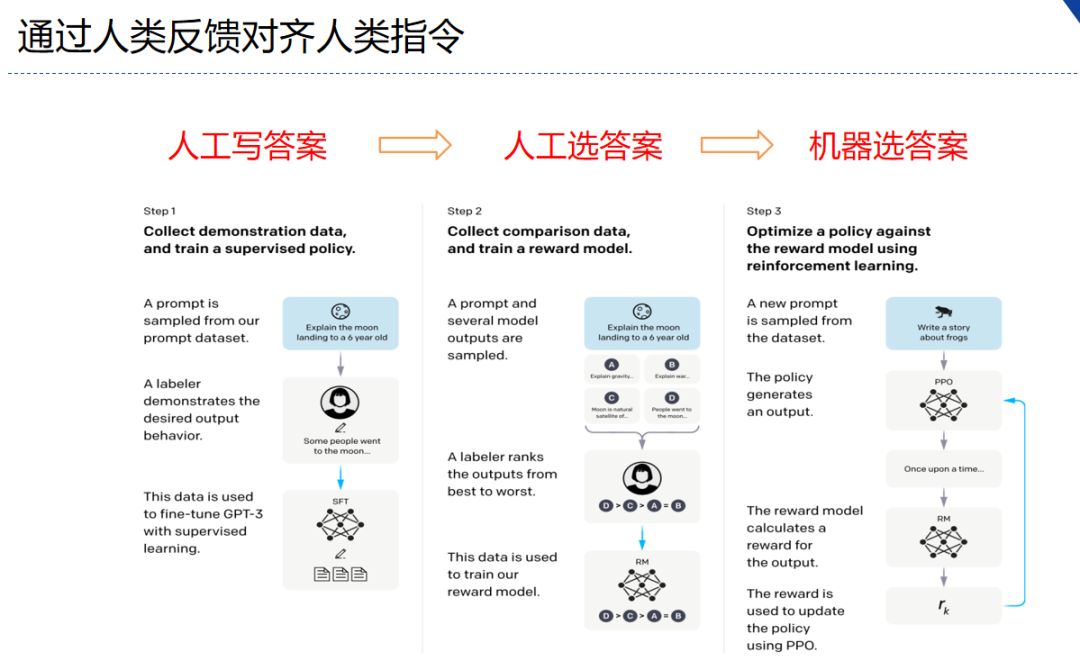
Instruct GPT Diagram
Based on the Instruct GPT technical route, ChatGPT does not have a particularly good technical innovation, but its greatest feature is that it endows large-scale language models with the ability to talk. This is a product innovation, and this innovation is great!
How to build a large language model?
At present, the ability of large language models can be measured mainly from the following four dimensions.
- Know Knowns: LLM knows what it knows.
- Know Unknowns: LLM knows what it doesn’t know.
- Unknown Knowns: LLM doesn’t know what it knows.
- Unknown Unknowns: LLM doesn’t know what it doesn’t know.
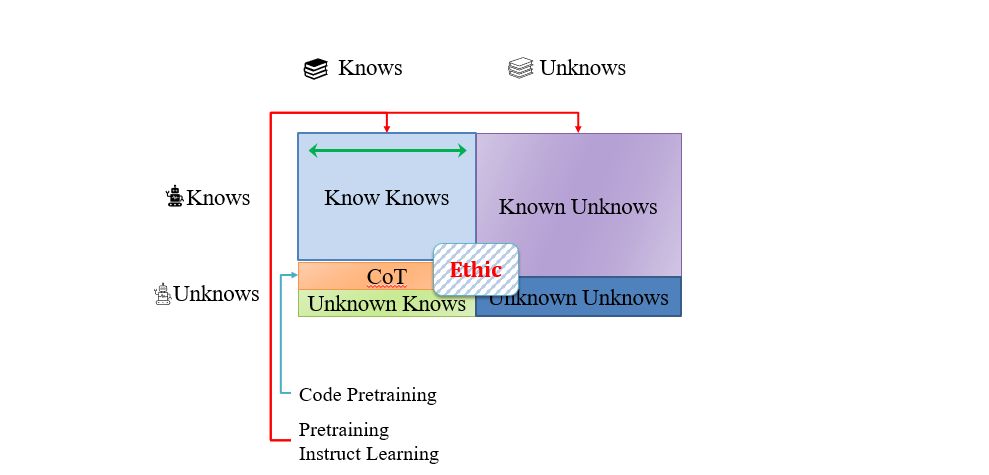
Building Conversational Large-Scale Language Models
ChatGPT has gained more knowledge through larger-scale pre-training, that is, the scope of Knowns has expanded.
In addition, ChatGPT also pays attention to ethical issues, and uses manual annotation and feedback in a similar way to solve Know Unknowns, and refuses to answer some requests containing ethical issues.
Here, we also have to mention MOSS, the first large-scale conversational language model in China, which has attracted great attention since it was released to the public platform on February 21. “The conversational large-scale language model MOSS has about 20 billion parameters. Unlike traditional language models, it also iterates through the ability to interact with humans.” Professor Qiu Xipeng talked about why MOSS chose 20 billion parameters. Very simple, it just has the ability to emerge, and the cost of talking to people is low.
MOSS is trained based on public Chinese and English data, and iteratively optimized through the ability to interact with humans. At present, MOSS has collected millions of real human dialogue data, and it is further iteratively optimized, and it also has the ability of multi-round interaction, so in terms of command understanding ability and general semantic understanding ability, it is very similar to ChatGPT. It can be accepted, but its quality is not as good as ChatGPT, because the model is relatively small and the amount of knowledge is not enough.
Limitations of ChatGPT
Why ChatGPT is important academically, because it not only shows the general framework of artificial intelligence, but also because it can access multi-modal information, enhance thinking ability, increase output ability, and become better The base of general artificial intelligence can bring more academic applications.
Compared with ChatGPT’s own capabilities, its limitations are relatively few and relatively easy to solve. Yann LeCun, winner of the Turing Award and one of the three giants of artificial intelligence, believes that the shortcomings of ChatGPT are as follows:
- Currently in limited form. The current ChatGPT is limited to text orientation, but as mentioned earlier, some multimodal models can be used upstream to initially solve this problem.
- Not controllable. At present, many reports have unlocked the model’s Ethic and some Know Unknowns restrictions in various ways, but this part can be solved through more manual labeling and alignment.
- Reasoning skills are poor. Through the way of thinking chain, the reasoning ability of the model can be enhanced to a certain extent.
- Unable to contact the real world. This is also one of the biggest problems of ChatGPT at present. As a large-scale language model, it cannot interact with the outside world in real time, nor can it use external tools such as calculators, databases, search engines, etc., resulting in its relatively backward knowledge.

In the future, it should improve timeliness, immediacy, harmlessness and so on.
In general, if the LLM is used as the agent itself and can interact with the outside world, the capabilities of these models will definitely be greatly improved.
But we want to always keep the models of these AI models believable: helpful, harmless, honest.
This article was compiled from March 11, sponsored by the Chinese Association for Artificial Intelligence, co-organized by Daguan Data, a leading domestic AI company, together with the Natural Language Understanding Committee of the Chinese Association for Artificial Intelligence, and the ZhenFund, and supported by the Institute of Cloud Computing and Big Data, China Academy of Information and Communications Technology ChatGPT and large-scale model seminars. Focusing on the development and application of ChatGPT and large-scale language models, the conference gathered many big names in artificial intelligence production and research to discuss cutting-edge technologies and the future of the industry, presenting a wonderful feast of thought exchanges. The seminar was broadcasted online in real time through five major platforms, attracting more than 100,000 offline and online audiences.
Search and follow “Daguan Data Video Account” to view the full live playback immediately!
This article is reproduced from: https://www.52nlp.cn/%E5%A4%8D%E6%97%A6%E9%82%B1%E9%94%A1%E9%B9%8F%EF%BC%9A% E6%B7%B1%E5%BA%A6%E5%89%96%E6%9E%90-chatgpt-%E7%B1%BB%E5%A4%A7%E8%AF%AD%E8%A8%80 %E6%A8%A1%E5%9E%8B%E7%9A%84%E5%85%B3%E9%94%AE%E6%8A%80%E6%9C%AF
This site is only for collection, and the copyright belongs to the original author.