Content source: ChatGPT and large model seminars
Sharing guest: Zhang Jiajun, a researcher at the Institute of Automation, Chinese Academy of Sciences
Sharing topic: “Tips and instruction learning in ChatGPT”
Zhang Jiajun, a researcher at the Institute of Automation, Chinese Academy of Sciences, took the topic of prompt and instruction learning in ChatGPT, from the perspective of a brief technical review of ChatGPT, prompt learning towards generality, from prompt learning to instruction learning, related exploration and learning, and other audiences. share. There are two main directions for the large model, one is “pre-training + parameter fine-tuning”, that is, after the large model is obtained, it is fine-tuned for downstream tasks, and then a large model for downstream tasks is obtained, and the other is “pre-training + prompt learning” , unchanged after pre-training, using hint learning to motivate large models to complete specific tasks. Relevant practice has proved that learning hints are very effective in improving model performance, and how to learn or find hints is very critical. Below are the details to share.

Brief Technical Review of ChatGPT
1. Basic introduction
ChatGPT is no longer just a traditional human-computer dialogue system. It is a general language processing platform that interacts with natural language. It has excellent performance in three aspects: first, it has made major breakthroughs in the technical realization of basic data, core models and optimization algorithms; second, its application is very down-to-earth, and it can complete almost all language-related functions ; Finally, compared with the past intelligent dialogue system, its interactive experience effect has produced a qualitative leap.
The interactive experience that exceeds expectations can be attributed to four key capabilities: general intent understanding ability, powerful continuous dialogue ability, intelligent interaction correction ability and strong logical reasoning ability. These abilities have always been difficult tasks for natural language processing researchers, because we only studied a single task before. However, with the birth and development of ChatGPT, we now realize that it can achieve more complex tasks.
2. The integrated technology composition of ChatGPT
ChatGPT is a major integrated innovation driven by product thinking. It is a major achievement of OpenAI’s adherence to generative AI and long-term technology accumulation since 2018. Quantitative changes lead to qualitative changes. It is a phased achievement towards AGI.
The integration technology of ChatGPT mainly includes three aspects:
- Basic model architecture. The basic model architecture is mainly a generative decoder, which comes from Transformer[1] proposed by Google in 2017.
- instruction learning. It also comes from the instruction learning FLAN [2] proposed by Google in 2021.
- Reinforcement Learning with Human Feedback. The reinforcement learning part is the field that OpenAI has been focusing on since its establishment. In 2017, the reinforcement learning algorithm PPO [3] was proposed. In 2021, it showed very good performance on the automatic summary task [4], so it was directly used. dialogue scene.
3. The basic model of ChatGPT
The underlying model of ChatGPT is essentially a language model. What the language model does is to give a prefix, predict what the next word is, or calculate the distribution of the possibility of the next word, and choose an optimal one from it. The essence of the language model training process is self-supervised learning based on massive data, by learning a large amount of text. For example, when predicting the next word for the sentence “artificial intelligence is to simulate and expand human intelligence”, the model found that in the historical text, “artificial intelligence” was followed by “theory” four times, three times “Theory” was picked up, and “Technology” was picked up twice, so when predicting, the model will predict the result as the word “theory” with a greater probability. This process is somewhat similar to word Solitaire.
For the language model, if the previous historical information can be seen longer, the prediction will be more accurate. Each input word is represented by a vector, and the higher the representation dimension of each word, the better its semantic representation ability. Secondly, mainstream language models are constructed through deep learning neural networks. The deeper the network level, the stronger the predictive ability. The representation dimension of the vector and the level of the network are the main factors affecting the parameter scale. The larger the parameter scale, the higher the capacity of the model. From 2018 to 20201, the scale of parameters ranged from 117 million to 175 billion. The model has shown tremendous changes, showing the characteristics of emerging capabilities.
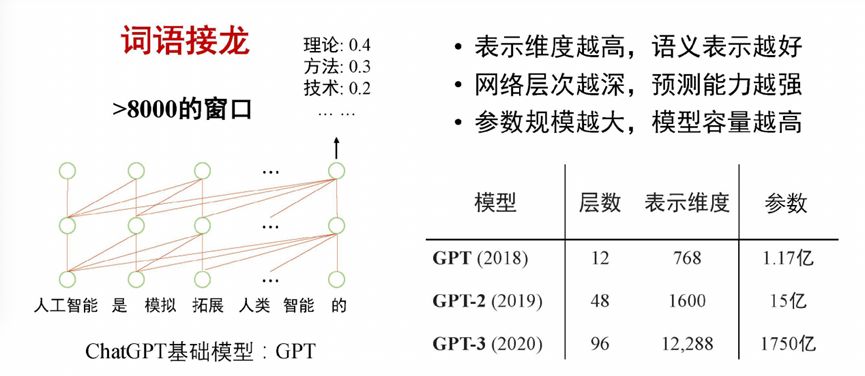 Figure 1 ChatGPT basic model
Figure 1 ChatGPT basic model
The emergence of capabilities just mentioned means that some capabilities do not exist in models with small parameter scales, but if they exist in models with large parameter scales, the capabilities are emerging. The reasoning of the thinking chain in the figure below and the generalization of new instructions will produce the emergence of capabilities between 10 billion and 100 billion parameter scales.
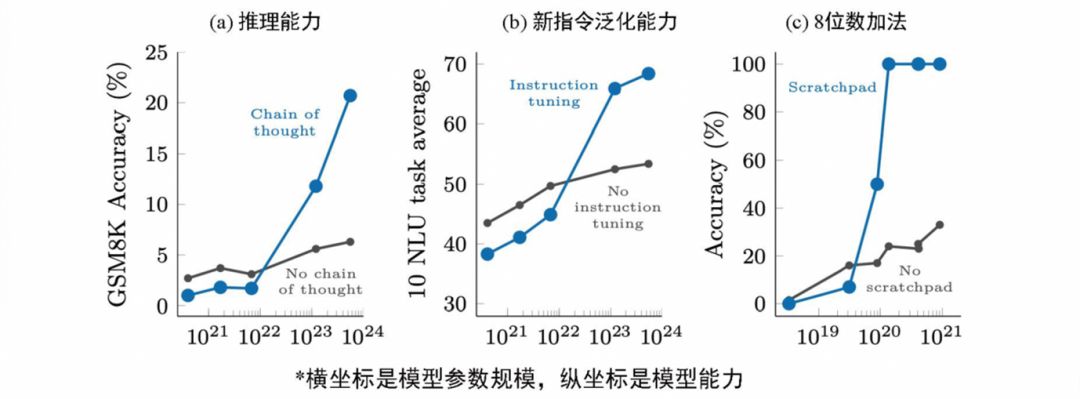 Figure 2 Emergence of Capabilities
Figure 2 Emergence of Capabilities
4. Self-supervised learning based on massive data
ChatGPT builds a basic model based on self-supervised learning of massive data, and this process does not happen overnight. In 2020, openAI used 45T text data training to obtain the basic large model GPT-3, which achieved fluency and knowledge. In terms of performance, the fluency of text generated by GPT-3 is relatively high, but the processing ability of general tasks is not so strong. In 2021, on the basis of GPT-3, openAI will use 179G code data to realize the logic programming model CodeX through self-supervised training, which has a certain reasoning ability. In 2022, openAI uses the mixed learning of more updated text data and code data to obtain a stronger basic large model GPT-3.5, which becomes the basic model of ChatGPT and achieves fluency, knowledge and logic (reasoning ability).
After getting a basic model that is powerful enough and versatile enough, ChatGPT still uses instruction learning and learning based on human feedback to further improve the interactive experience. Among them, the instruction learning guidance model can follow human instructions to output the expected content, and the reinforcement learning based on human feedback makes the model more in line with human preferences. ChatGPT achieves fluency, knowledge, logic, and anthropomorphism by combining basic large models, instruction learning, and reinforcement learning based on human feedback.
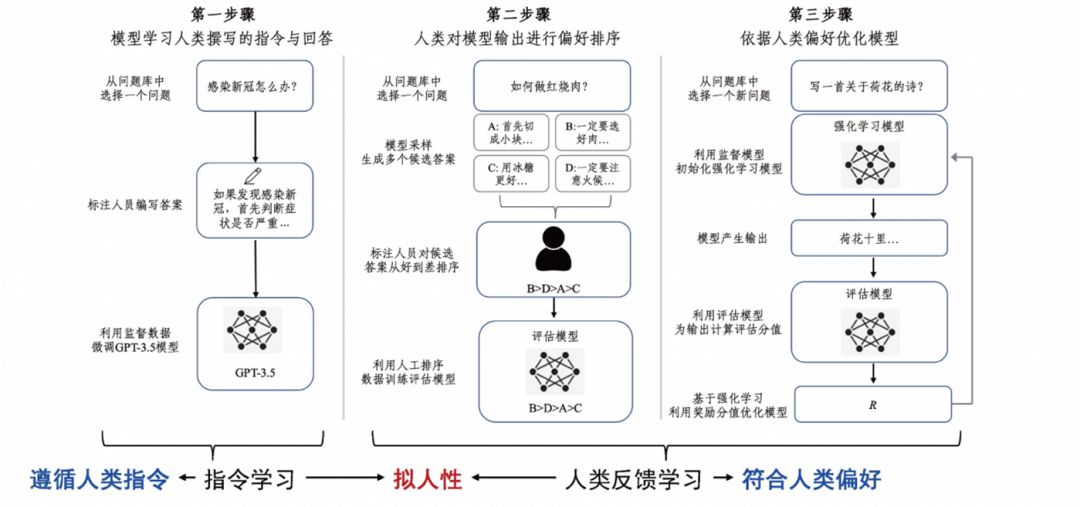 Figure 3 Instruction learning and human feedback learning
Figure 3 Instruction learning and human feedback learning
Tips for Learning Towards Versatility
1. Two directions of pre-training large models
The pre-training large model mainly realizes the prediction of downstream tasks through two methods: “Pre-training + Fine-tuning” and “Pre-training + Prompt Learning”.
2. Pre-training + parameter fine-tuning
“Pre-training + parameter fine-tuning” means that after the large model is pre-trained, it serves as a well-initialized basic model, structurally adapts to each downstream task, and fine-tunes the parameters of the large model to optimize the performance of downstream tasks. For example, take a large model adapting to classification tasks as an example. The model is implemented by adding a simple classification network (softmax) to the last node of the pre-training model. During the training process, not only the parameters of the classification network are updated, but also the entire Parameters of the pretrained model. After the training is completed, the model can be more suitable for classification tasks, but at the same time, the generality of the model becomes weaker. Sequence labeling and text generation tasks also use pre-training + parameter fine-tuning to update model parameters, and the general ability of the model will also be weakened. The same situation can be extended to the tasks of machine translation, automatic question answering, and sentiment analysis.
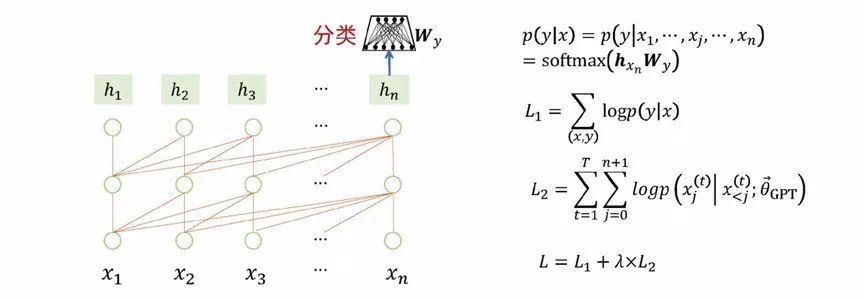
Figure 4 Pre-training + parameter fine-tuning: adapting to classification tasks
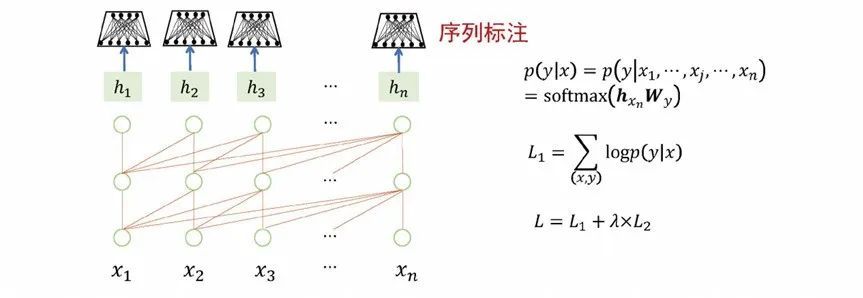
Figure 5 Pre-training + parameter fine-tuning: adapting to sub-sequence tasks
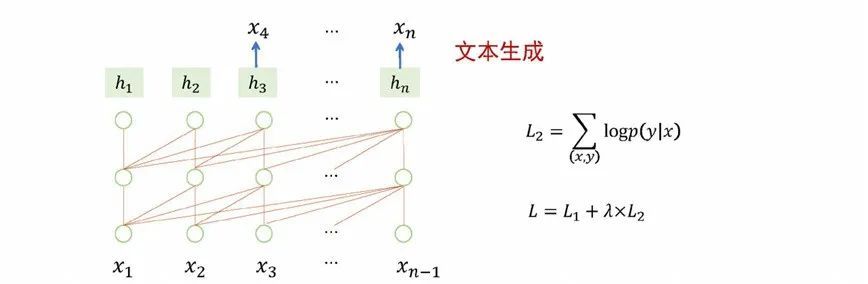
Figure 6 Pre-training + parameter fine-tuning: adapting to text generation tasks
Figure 7 “Pre-training + parameter fine-tuning” paradigm
To sum up from the above examples, the method of pre-training + parameter fine-tuning can achieve good results in specific tasks, but this method has some limitations. First, the way of pre-training + parameter fine-tuning lacks the ability to deal with general problems. Second, model training needs to be performed independently for each task, which consumes too much resources. Third, there will be a problem of overfitting, because not all types of tasks have a large amount of labeled data, and there are problems with generalization ability in the case of less data in downstream tasks.
3. Pre-training + prompt learning
“Pre-training + hint learning” refers to pre-training a large model first, keeping the parameters unchanged in subsequent tasks, and using the form of prompts to enable the pre-training model to meet the needs of various downstream tasks. Specifically, we will convert the downstream tasks to the input and output formats of the pre-trained model, such as text classification, sequence labeling, and text generation, all of which need to format the text input into the input format of the pre-trained model, and convert the pre-trained model The output of the task is converted into the output format required by the task, and finally the specific task is completed by using the prompt to activate the large model.
We describe the process of pre-training + hint learning for several common NLP tasks. For example, in a text classification scenario, it is necessary to predict whether the sentiment expressed by the comment “I truly love this film” is “positive” or “negative”. The method of prompt learning is to add a prompt “Its sentiment is” after the sentence “I truly love this film”, and use the language model to predict what the next word will be. If the prediction result is “positive” or “negative”, it is OK. As the final prediction result, or if neither word hits, you can complete the processing of the entire task by judging whether “positive” or “negative” has a higher probability. The processing process of other tasks is similar, the main difference lies in the prompts. When processing part-of-speech tagging, the prompt “Its POS is” is added after the sentence, and then the part-of-speech tagging result is generated in the way of the language model. When processing translation, the prompt “Its Chinese Translation is” is added after the sentence, and then the language model will predict the output “I really like this movie”.
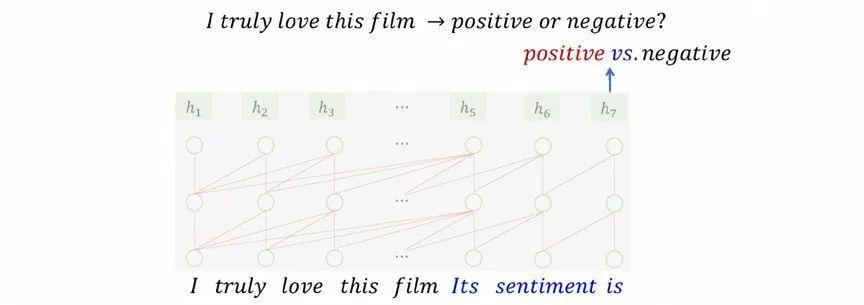 Figure 8 Pre-training + hint learning: classification tasks adapt to large models
Figure 8 Pre-training + hint learning: classification tasks adapt to large models
 Figure 9 Pre-training + hint learning: sequence labeling task adapts to large model
Figure 9 Pre-training + hint learning: sequence labeling task adapts to large model
 Figure 10 Pre-training + Hint Learning: Text Generation Task Adaptation to Large Models
Figure 10 Pre-training + Hint Learning: Text Generation Task Adaptation to Large Models
4. Prompts
Prompt language is an important element in pre-training + prompt learning. How to understand the prompt, the prompt is a special text inserted into the downstream task text input, which can be regarded as a set of special parameters, triggering the pre-training large model to achieve specific downstream tasks, while keeping the pre-training large model training and testing consistent .
Prompts can be discrete or continuous. Discrete prompts are more common, and the prompts mentioned above are discrete prompts. There are two main ways to generate discrete prompts: manually analyze specific downstream tasks, summarize the rules of downstream tasks, and design prompts suitable for specific downstream tasks; find appropriate prompts to complete specific downstream tasks by automatically searching from text data. hint. Finding suitable cues for each sample per task is a huge challenge, and different cues lead to significant differences in results.
Continuous prompts are to add a set of continuous vectors to the input text or model to represent prompts with generalization ability. There are two ways to add continuous prompts, one is to add directly before the text input [5], and the other is to add continuous vector representation prompts before the network or each layer of the network [6].
 Figure 11 Continuous prompts
Figure 11 Continuous prompts
5. Comparative Analysis
We compare the two methods of “pre-training + parameter fine-tuning” and “pre-training + hint learning”.
The most important difference between the two approaches is in the form of supporting downstream tasks [7]. The large model of “pre-training + parameter fine-tuning” in the figure below needs to adjust parameters for different tasks. “Pre-training + prompt learning” only needs to modify the input mode by designing prompt information so that it has the ability to complete downstream tasks. .
 Figure 12 “Pre-training + parameter fine-tuning” VS “Pre-training + hint learning”
Figure 12 “Pre-training + parameter fine-tuning” VS “Pre-training + hint learning”
Although “pre-training + hint learning” has significant advantages, there are fewer research results in related directions before 2020. This is because the previous model is small in scale and weak in versatility, which is not suitable for prompt learning and suitable for parameter fine-tuning. After 2020, the scale of the model has increased significantly, and the cost of fine-tuning has also increased. At the same time, it has strong versatility and is suitable for prompt learning.
 Figure 13 From “pre-training + parameter fine-tuning” to “pre-training + hint learning”
Figure 13 From “pre-training + parameter fine-tuning” to “pre-training + hint learning”
The blue line in the figure below is the Zero Shot performance of GPT-3 on 45 tasks. The average accuracy rate is about 30%, and the effect is still relatively weak. This shows that cue learning can trigger pre-trained large models to complete specific tasks, but a single external cue signal is difficult to maximize the ability of pre-trained large models to complete specific tasks with high quality.
 Figure 14 GPT-3 performance on 45 tasks
Figure 14 GPT-3 performance on 45 tasks
From cue learning to instruction learning
“Pre-training + parameter fine-tuning” fine-tunes the model parameters through the supervision data of specific tasks, which can maximize the ability of pre-trained large models to complete specific tasks, but faces problems such as data scarcity, disaster forgetting, resource waste, and weak versatility. “Pre-training + hint learning” has strong versatility, but its effect on specific tasks is relatively weak. Therefore, researchers consider better integrating the advantages of the two, so that the large model can better understand the execution intention of specific tasks, so there is a transition from prompt learning to instruction learning. The execution logic of “parameter fine-tuning”, “prompt learning” and “command learning” is as follows:
- Large model + parameter fine-tuning: Modify model parameters via task-related via-design cues Supervised data via several task-related via-prompts.
- Large model + hint learning: Modify model parameter information by designing hints to modify input patterns through hinted supervised data related to several tasks.
- Large Model + Instruction Learning [8][9]: Optimizing model parameters with several task-relevant supervised data augmented with hints.
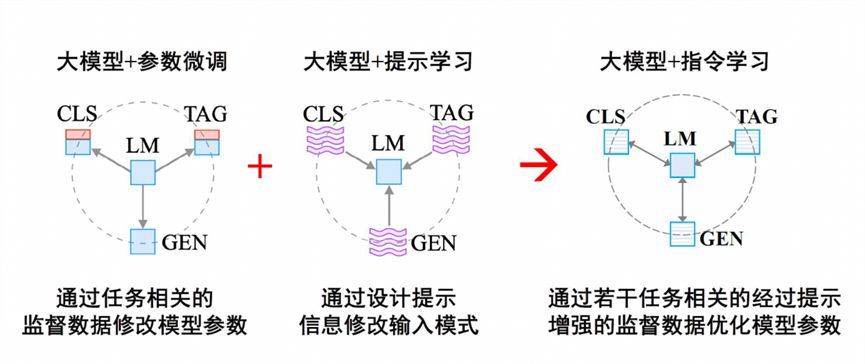 Figure 15 Large model + instruction learning
Figure 15 Large model + instruction learning
Let’s look at an example of prompt learning. Machine translation, question answering, and sentiment classification are still used as task scenarios. Originally, each task scenario corresponds to a model. Now, all tasks are transformed into language models. For example, when processing a translation task, insert the prompt information into the text to get “the Chinese translation of ‘I love China’ is”. Different samples can use different prompts to ensure certain differences. Then the labeled data of all tasks are merged together as a unified task to perform parameter fine-tuning. After all the data is trained, a new large model is obtained. The new large model can then use prompts to trigger the large model to complete specific capabilities. As a result, it can support different tasks and improve the performance of multi-task execution.
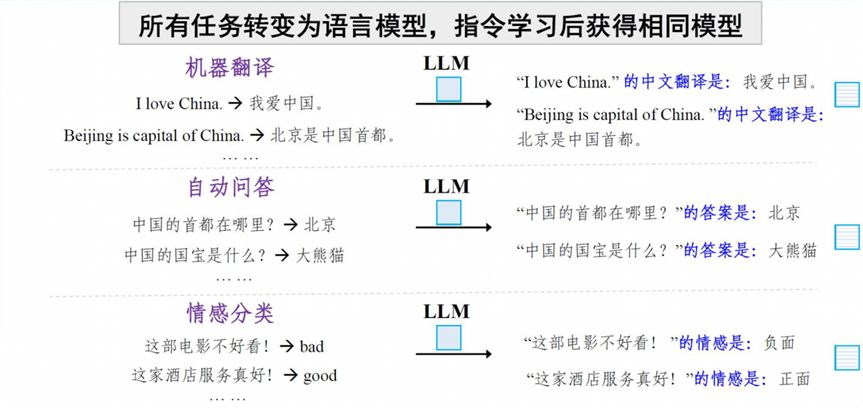
Figure 16 “Large model + instruction learning” adapts to downstream tasks
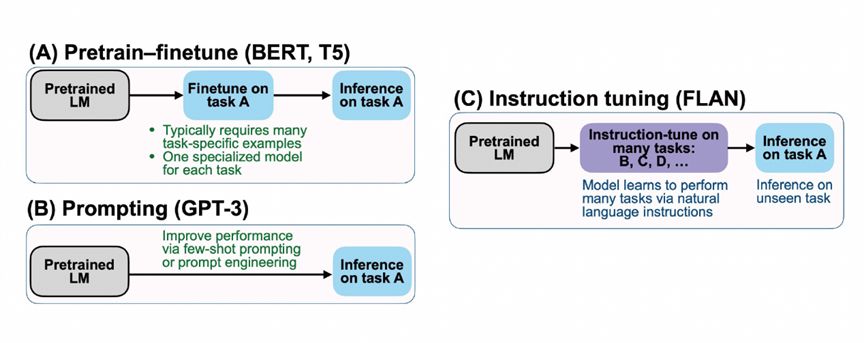 Figure 17 Google FLAN model
Figure 17 Google FLAN model
This is an example of FLAN proposed by Google at that time. The upper left corner is pre-training + fine-tuning, the lower left corner is a prompt, and the right is FLAN instruction learning, which is a combination of the former two. FLAN was fine-tuned on dozens of tasks and found to be predictive on unseen tasks as well. For example, after fine-tuning tasks such as common sense reasoning and translation, FLAN will find that the trained model will have a good prediction effect on natural language inference tasks. Therefore, FLAN has been trained on more than 40 tasks in 62 datasets. The tasks include understanding and generating two forms. The experimental results show that when the parameters reach more than 10 billion scale, the joint instruction learning of dozens of tasks can solve unknown tasks.
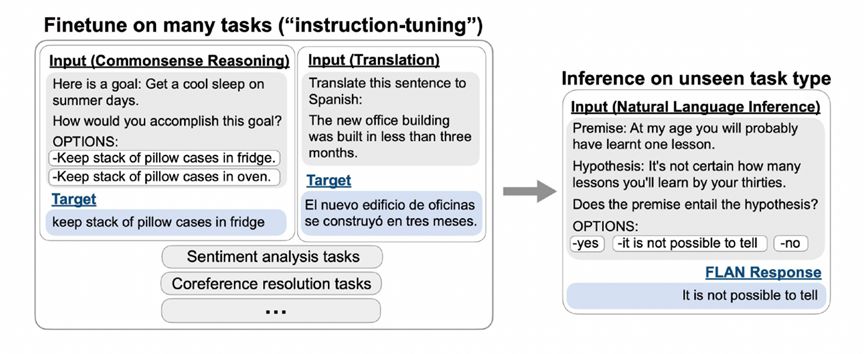 Figure 18 The predictive ability of unknown tasks exhibited by FLAN
Figure 18 The predictive ability of unknown tasks exhibited by FLAN
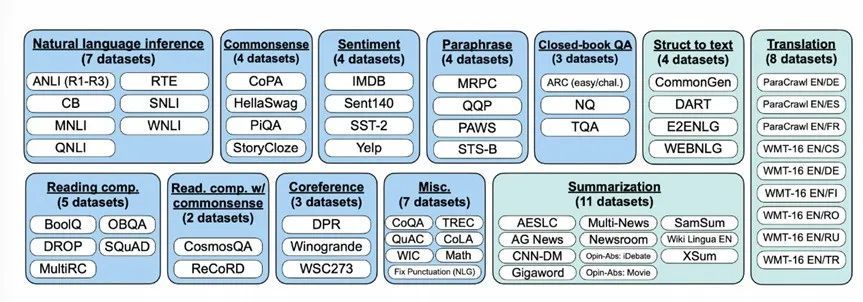 Figure 19 Text task dataset used by FLAN
Figure 19 Text task dataset used by FLAN
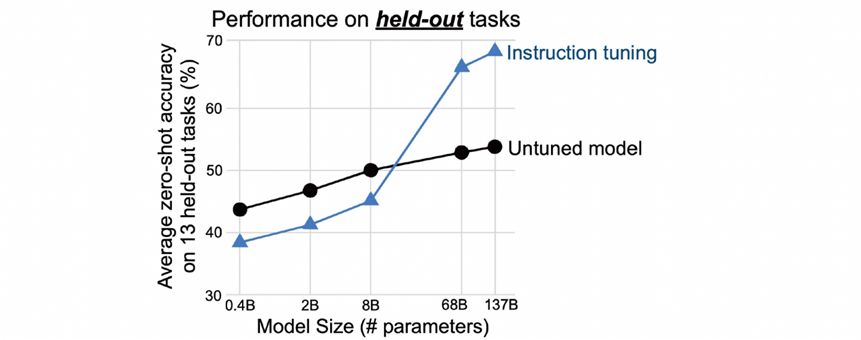 Figure 20 Tens of billions of parameters scale model multi-task joint learning can solve unknown tasks
Figure 20 Tens of billions of parameters scale model multi-task joint learning can solve unknown tasks
The important discovery of FLAN has played a guiding role in the follow-up work. On this basis, Instruct GPT, the predecessor of ChatGPT, collected API instructions, so that its instruction types are more abundant, and the coverage area is larger. Training on this basis triggers its general capabilities.
Related Exploration and Practice of Large Language Models
1. How to find the best prompt
As mentioned in the content of prompt learning above, the prompt language has a significant impact on the prediction effect. The following example shows that when ChatGPT processes the same text translation, it uses different prompt words (“what is the Chinese translation” and “how to say it in Chinese”), and the returned results are very different. At this time, the question of how to improve the effect of the model can be transformed into how to find the best prompts for different questions, and is there a way to automatically learn prompts.
 Figure 21 The influence of different prompts on the text translation results
Figure 21 The influence of different prompts on the text translation results
2. Sample-Level Hint Learning Method
To address the above issues, we propose a sample-level cue learning method [10] to learn the most appropriate cue for each sample. The implementation method is that when a new sample comes, the model will combine the input prompts and text, and search for the most relevant prompts according to the correlation, as the input of the language model. The advantage of this method is that it maximizes the uniqueness of different samples, and achieves better performance improvement than the same prompt, but the disadvantage is that it does not consider the commonality between samples, that is, it ignores the The fact that different samples actually belong to the same kind of task.
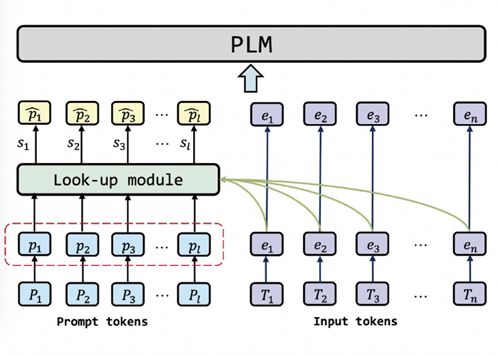
Figure 22 Sample-level hint learning method
3. Unified reminder learning method
Since the sample-level cue learning method only considers samples and does not take into account the commonality of tasks, we further propose a method for unified cue learning [11], which can simultaneously model task-level information and sample-level information. Its processing method is to learn a hint for each task, learn a hint for each sample in the task, and fuse the two types of hint information to obtain the best hint. The figure below shows the architecture of the unified prompt learning method. The gray part has constant parameters, and the blue part is a very small amount of parameters. One is the parameters from sample to sample level, and the other is that each task has corresponding parameters. Through this structural model, we can judge how much task-level information and how much sample-level information should be used for each sample, and finally learn the most appropriate hints for each sample.
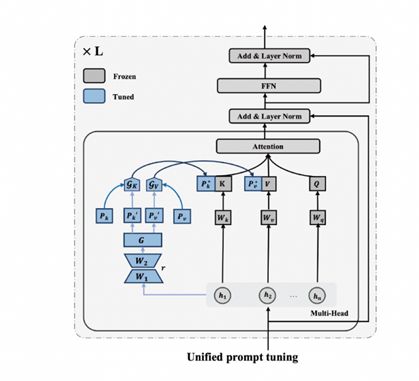
Figure 23 Unified prompt learning method
The advantage of the unified hint learning method is that it combines task information and sample information at the same time, and theoretically can obtain the best hint information. The disadvantage is that the task information needs to be known in advance, and further generalization is required. In contrast, ChatGPT is currently able to perceive the specific type of task even if it does not know what the requested task is, which has a great advantage. The follow-up research development direction can judge the information of the task through perception, and then learn the generalization related to the task and the sample on the basis of the known task information.
4. Experimental results
The experimental results verify that the unified hint learning method achieves the best average performance of few-shot learning on the SuperGLEU standard dataset. On the SuperGLEU dataset, it is found that the unified hint learning method is better than GPT-3 in contextual reasoning ability (the average task scores of single sentence tasks are 83.2 and 70.0, and the average scores of sentence pair related tasks are 72.0 and 49.8), which shows that It shows that learning hints are very effective in improving the effect of the model, and how to find the best hints is very critical.
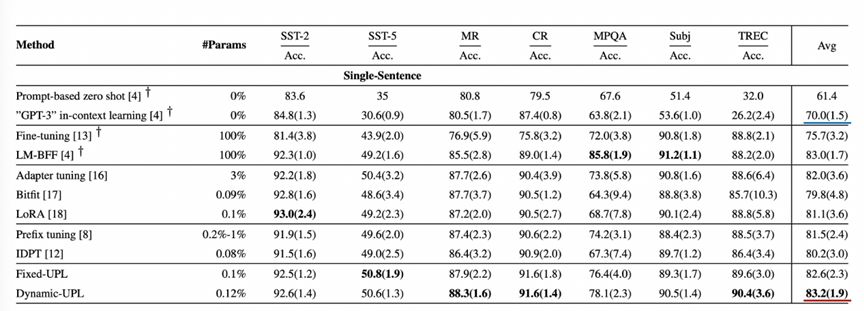
Figure 24 The effect of the unified hint learning method on the single-sentence task of the SuperGLEU standard dataset
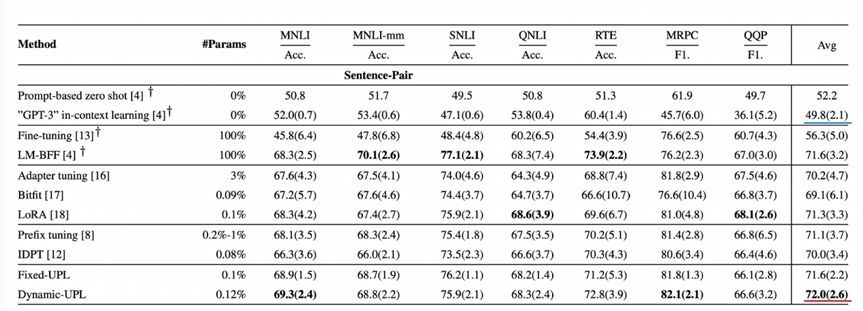 Figure 25 The effect of the unified hint learning method on the double-sentence task of the SuperGLEU standard dataset
Figure 25 The effect of the unified hint learning method on the double-sentence task of the SuperGLEU standard dataset
open question thinking
I wrote “Conjectures on Eight Technical Issues of ChatGPT” a month ago. Since then, I have been doing model exploration, sorting out some open questions to discuss with audience readers:
First, practice has found that the data not only determines the performance of the model, but also greatly affects the success or failure of the model training process. What are the reasons for this? Meta released several models last year, and they failed more than 20 times during the training process. Each time the data will affect the success of the data training.
Second, how does the emergence of capabilities happen? Why does it only manifest when the scale of parameters exceeds tens of billions? Or it’s not emergent, it’s just that the model size tests are not continuous enough.
Third, the data in Chinese and other languages accounted for very little, for example, less than 5%, but the Chinese performance of the model was very good? How did the ability transfer happen.
Fourth, whether the ability of the large model can be distilled to the small model.
Fifth, the general-purpose large model as a black box seems to have similarities with the human brain, whether it is possible to use the brain science research paradigm to study the large model in the future.
references
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[2] Wei J, Bosma M, Zhao VY, et al. Finetuned language models are zero-shot learners[J]. arXiv preprint arXiv:2109.01652, 2021.
[3] Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.
[4] Von Rueden L, Mayer S, Beckh K, et al. Informed Machine Learning–A taxonomy and survey of integrating prior knowledge into learning systems[J]. IEEE Transactions on Knowledge and Data Engineering, 2021, 35(1): 614-633.
[5] Lester B, Al-Rfou R, Constant N. The power of scale for parameter-efficient prompt tuning[J]. arXiv preprint arXiv:2104.08691, 2021.
[6] Li XL, Liang P. Prefix-tuning: Optimizing continuous prompts for generation[J]. arXiv preprint arXiv:2101.00190, 2021.
[7] Liu P, Yuan W, Fu J, et al. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): 1 -35.
[8] Wei J, Bosma M, Zhao VY, et al. Finetuned language models are zero-shot learners[J]. arXiv preprint arXiv:2109.01652, 2021.
[9] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.
[10] Jin F, Lu J, Zhang J, et al. Instance-aware prompt learning for language understanding and generation[J]. arXiv preprint arXiv:2201.07126, 2022.
[11] Jin F, Lu J, Zhang J, et al. Unified prompt learning makes pre-trained language models better few-shot learners. ICASSP 2023.
This article is reproduced from: https://www.52nlp.cn/%E4%B8%AD%E7%A7%91%E9%99%A2%E5%BC%A0%E5%AE%B6%E4%BF%8A% EF%BC%9Achatgpt%E4%B8%AD%E7%9A%84%E6%8F%90%E7%A4%BA%E4%B8%8E%E6%8C%87%E4%BB%A4%E5% AD%A6%E4%B9%A0
This site is only for collection, and the copyright belongs to the original author.