Original link: https://www.mghio.cn/post/fec34d85.html

foreword
Goroutines are the main concurrency primitive of the Go language. It looks very much like a thread, but it is cheap to create and manage compared to threads. Go efficiently schedules goroutines onto real threads at runtime to avoid wasting resources, so you can easily create large numbers of goroutines (e.g. one goroutine per request), and you can write simple, imperative blocking code . As a result, Go’s networking code tends to be more straightforward and easier to understand than equivalent code in other languages (as can be seen in the example code below).
For me, goroutines are a major feature that differentiates the Go language from other languages. That’s why people prefer Go to write code that requires concurrency. Before discussing more about goroutines below, let’s go through some history so you can understand why you want them.
Based on fork and thread
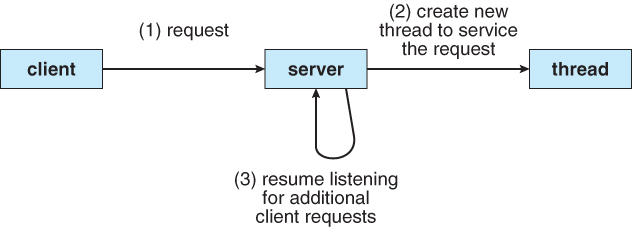
A high-performance server needs to handle requests from multiple clients simultaneously. There are many ways to design a server-side architecture to handle this. The easiest thing to think of is to have a main process call accept in a loop, and then call fork to create a child process that handles the request. This way is mentioned in this Beej’s Guide to Network Programming guide.
In network programming, fork is a great pattern because you can focus on the network rather than the server architecture. But it is difficult to write an efficient server according to this model, and no one should use this method in practice now.
Fork has many problems at the same time, the first one is the cost : the fork call on Linux looks fast, but it will mark all your memory as copy-on-write . Every write to a copy-on-write page causes a small page fault, which is a small delay that is hard to measure, and context switching between processes is expensive.
Another problem is scale : it is difficult to coordinate the use of shared resources (such as CPU, memory, database connections, etc.) among a large number of subprocesses. If traffic spikes, and too many processes are created, they will compete with each other for CPU. But if you limit the number of processes created, then when the CPU is idle, a large number of slow clients may block everyone’s normal use, and using a timeout mechanism will help (regardless of the server architecture, the timeout setting is necessary. ).
These problems can be alleviated to some extent by using threads instead of processes. Creating a thread is “cheaper” than creating a process because it shares memory and most other resources. Communication between threads is also relatively easy in a shared address space, using semaphores and other structures to manage shared resources. However, threads still have a significant cost. If you create a new thread for each connection, you will encounter to the extension problem . As with processes, you need to limit the number of running threads at this point to avoid severe CPU contention, and you need to time out slow requests. Creating a new thread still takes time, although this can be mitigated by using a thread pool to recycle threads between requests.
Whether you use processes or threads, you still have a difficult question: how many threads should you create? If you allowed an unlimited number of threads, the client might use up all of its memory and CPU while seeing a small spike in traffic. If you limit the maximum number of threads on your server, then a bunch of slow clients will clog up your server. While timeouts are helpful, it’s still hard to use your hardware resources efficiently.
event-driven
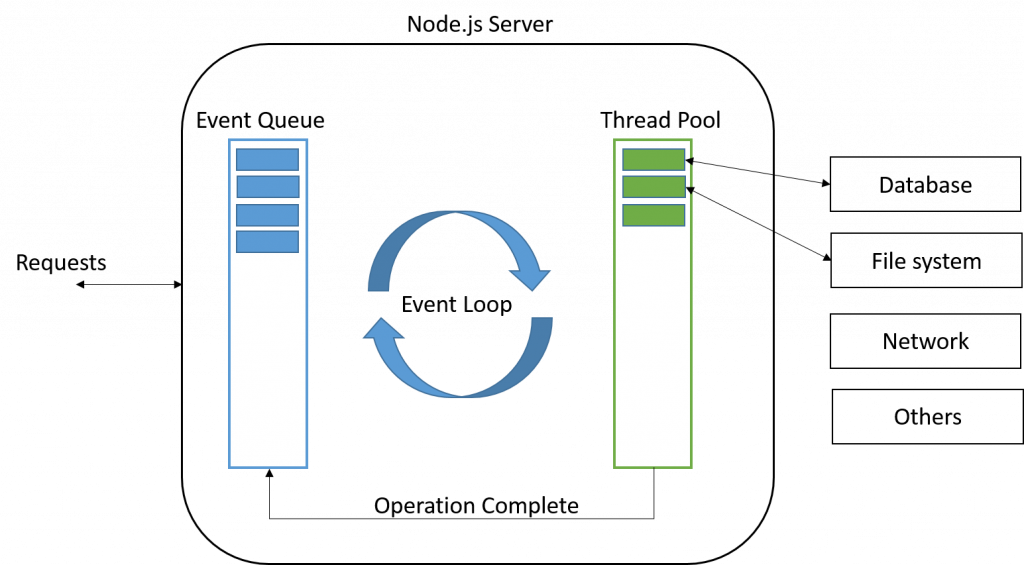
So since you can’t easily predict how many threads you’ll need, what happens when you try to decouple requests from threads? What if we had only one thread dedicated to application logic (or maybe a small, fixed number of threads), and then used asynchronous syscalls to handle all network traffic in the background? This is an event-driven server-side architecture.
The event-driven architectural pattern is designed around the select system call. Later mechanisms like poll have replaced select, but select is well known and they both serve the same concept and purpose here. select takes a list of file descriptors (usually sockets) and returns which ones are ready for reading and writing. If none of the file descriptors are ready, select blocks until at least one is .
1 |
# include <sys/select.h> |
In order to implement an event-driven server, you need to keep track of some state about a socket and each request blocked on the network. On the server there is a single main event loop that calls select to handle all blocked sockets. When select returns, the server knows which requests can be made, so for each request it invokes the stored state in the application logic. When the application needs to use the network again, it adds the socket back to the “blocking” pool along with the new state. The state here can be anything the application needs to resume what it was doing: a closure to call back, or a Promise.
Technically speaking, these can actually be implemented with one thread. Can’t talk about any specific implementation details here, but like JavaScript
Languages that lack threads like this follow this model very well. Node.js even describes itself as “an event-driven JavaScript runtime, designed to build scalable network applications.”
Event-driven servers typically make better use of CPU and memory than purely fork- or thread-based servers. You can spawn an application thread per core to process requests in parallel. Threads don’t compete with each other for CPU because the number of threads is equal to the number of cores . Threads are never idle when there are requests to make, very efficient. It’s so efficient that now everyone uses this approach to write server-side code.
In theory, this sounds good, but if you write application code like this, you will find that it is a nightmare. . . Exactly what kind of nightmare it is depends on the language and framework you use. In JavaScript, asynchronous functions usually return a Promise to which you attach callbacks. In Java gRPC, what you deal with is StreamObserver. If you’re not careful, you can end up with a lot of deeply nested “arrow code” functions. If you’re careful, you’ve separated functions from classes, confusing your control flow. Either way, you are in callback hell .
Here’s an example from an official Java gRPC tutorial :
1 |
public void routeChat () throws Exception { |
The above code is the official beginners tutorial, it is not a complete example, the sending code is synchronous, and the receiving code is asynchronous. In Java, you might be dealing with different asynchronous types for your HTTP server, gRPC, database and whatever, and you need adapters between all of them, which can quickly become a mess.
At the same time, it is dangerous to use locks here, and you need to be careful about holding locks across network calls. Locks and callbacks are also prone to mistakes. For example, if a synchronous method calls a function that returns a ListenableFuture and then attaches an inline callback, that callback also needs a synchronized block, even if it’s nested inside the parent method.
Goroutines
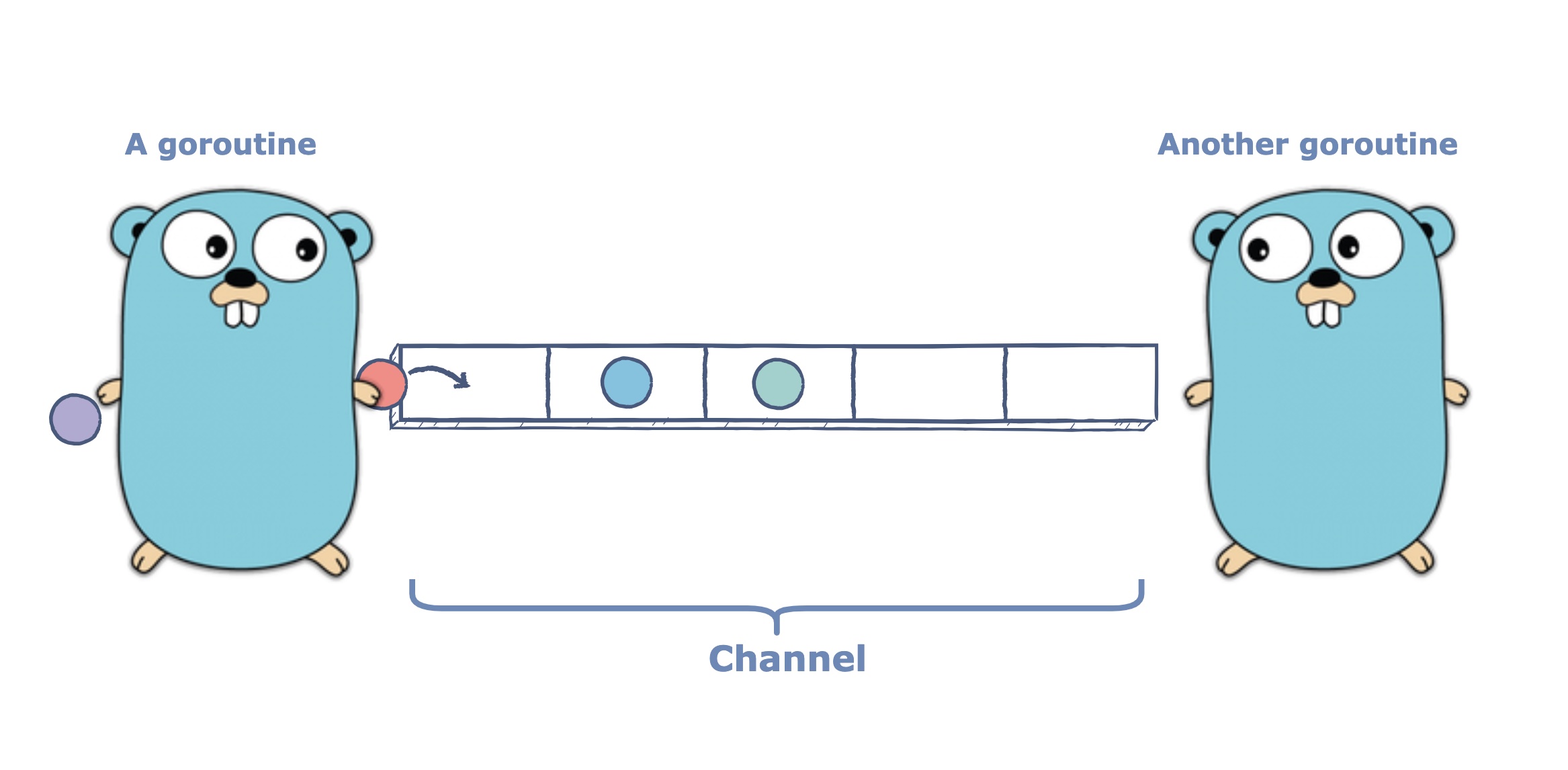
Finally we come to our protagonists – goroutines. It is the Go language version of threads. Like threads in other languages (eg Java), each gooutine has its own stack. Goroutines can execute in parallel with other goroutines. Unlike threads, a goroutine is very cheap to create: it is not bound to an OS thread, and its stack starts out very small (only 2K initially), but grows as needed. When you create a goroutine, you are actually allocating a closure and adding it to the queue at runtime.
Internally, Go’s runtime has a set of OS threads (typically one thread per core) that execute programs. When a thread is available and a goroutine is ready to run, the runtime schedules the goroutine onto the thread to execute application logic. If a running routine blocks on something like a mutex or channel, the runtime adds it to the set of blocked running goroutines, and then schedules the next ready running routine on the same OS thread.
This also applies to networking: when a threaded program sends or receives data on an unprepared socket, it hands off its OS thread to the scheduler. Does this sound familiar? Go’s scheduler is much like the main loop in an event-driven server. Apart from relying solely on select and focusing on file descriptors, the scheduler handles everything in the language that can block.
You no longer need to avoid blocking calls because the scheduler can efficiently utilize the CPU. Freedom to spawn many goroutines (can be one per request!), since they are cheap to create and don’t compete for CPU, you don’t need to worry about thread pool and executor services because there is actually one big thread at runtime pool.
In short, you can write simple blocking application code in a clean imperative style, just as if you were writing a thread-based server, but you retain all the efficiency advantages of an event-driven server, the best of both worlds. This kind of code composes well across frameworks. You don’t need this kind of adapter between streamobserver and ListenableFutures.
Let’s look at the same example from the official Go gRPC tutorial . You can find the control flow here easier to understand than in the Java example, because the sending and receiving code is synchronous . In both goroutines, we can call stream.Recv and stream.Send in a for loop. There is no need for callbacks, subclasses or executors anymore.
1 |
stream, err := client.RouteChat(context.Background()) |
virtual thread
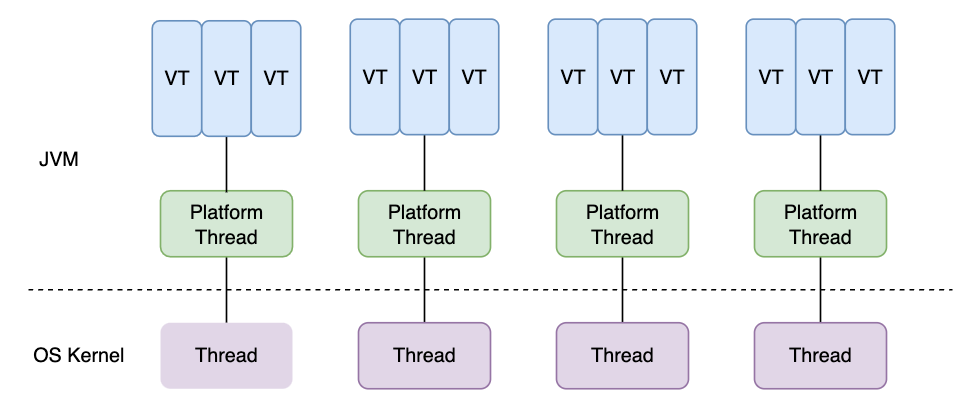
How ever you use the Java language, so far you’ve either had to spawn an unreasonable number of threads, or you’ve had to deal with Java-specific callback hell. Happily, virtual threads were added in JEP 444 , which looks a lot like goroutines in Go.
Creating virtual threads is cheap. The JVM schedules them on platform threads (real threads in the kernel). The number of platform threads is fixed, generally one platform thread per core. When a virtual thread performs a blocking operation, it releases its platform thread, the JVM
Might schedule another dummy thread onto it. Unlike gooutines, virtual thread scheduling is cooperative: a virtual thread does not obey the scheduler until it performs a blocking operation. This means that tight loops can hold threads indefinitely . It’s unclear if this is an implementation limitation or if there is a deeper problem. Go also had this problem before, and it wasn’t until 1.14 that fully preemptive scheduling was implemented (see GopherCon 2021 ).
Java’s virtual thread can now be previewed and is expected to become stable in JDK 21 (officially, it is expected to be released in September 2023). Haha, I am looking forward to deleting a large number of ListenableFutures by then. Whenever a new language or runtime feature is introduced, there will be a long migration transition period, and I personally think that the Java ecosystem is still too conservative in this regard.
This article is transferred from: https://www.mghio.cn/post/fec34d85.html
This site is only for collection, and the copyright belongs to the original author.