Original link: https://blog.besscroft.com/articles/2023/enstudy-design/
foreword
Recently, I am designing and developing the English learning project. Today I want to tell a simple story, a thought about the complex technical design behind the English learning software, and how I plan to practice it and make it work in a certain way.
to grope
I have used many English learning software, and the one I have used for the longest time is naturally Duolingo. You see, you have learned English for so long. If you are asked to make an English learning software, how would you design it (doge
Functional sorting
To sum it up in one sentence, it is to query word information and record the user’s learning status. Seems simple, right? Believe me, if someone asks you so much for you to realize, and tells you that it is very simple, you will definitely want to shoot him to death.
Just kidding haha, now let’s analyze the business in detail:
-
First of all, we have to let users choose which thesaurus to learn. Let’s take “English Vocabulary for Postgraduate Entrance Examination” as an example, with a total of 4533 words.
-
After the user selects a thesaurus, we can generate a summary of the user’s learning of the thesaurus, that is, which words the user has “learned”, how many have been learned in total, and so on.
-
Then the user acquires the words on the software to learn, and after the learning is completed, the data will be stored in the database. The warehousing operation here involves more points. For example, we need to record whether the word user has “learned”, that is to say, no matter whether the question is answered correctly or incorrectly, it is considered learned. Then there is the progress statistics of the words, how many in total, and how many have been learned. And record what the user did wrong to form a wrong question book.
Here it is necessary to explain to you why you need to record learning data. I believe that many friends should have heard of the Ebbinghaus forgetting curve , and we let users learn, and it is impossible to give a word for a request, which is not only inefficient, but also the server will not be able to stretch. The correct way is to generate a List. I believe that friends who have memorized words in Excel will have a deep understanding. Because the user has learned a certain word, it will definitely record the time when it is stored in the database. Combined with the user’s behavior and the wrong question book, the List can be generated according to some “memory algorithms”. Since this function is only a small part of the whole business, it will not be expanded here.
Through this initial UI sketch under development, we can understand that the above functions are mapped to the general appearance of the client.
database table design
After sorting out the business functions, first we need to design the database table. After consuming a few cups of coffee and scratching some hair, I designed the following database table structure (of course, adjustments will be made during the development iteration):
- The user active lexicon table is used to record the lexicon that the user is currently learning, the lexicon that the user has learned, and count the number of words learned.
|
|
- The user learning behavior table is used to record the words that the user has “learned” and the learning time.
|
|
- The user’s wrong question book is used to record the words that the user learns wrong and the number of times.
|
|
process
Now let’s take a look at how the whole process goes:
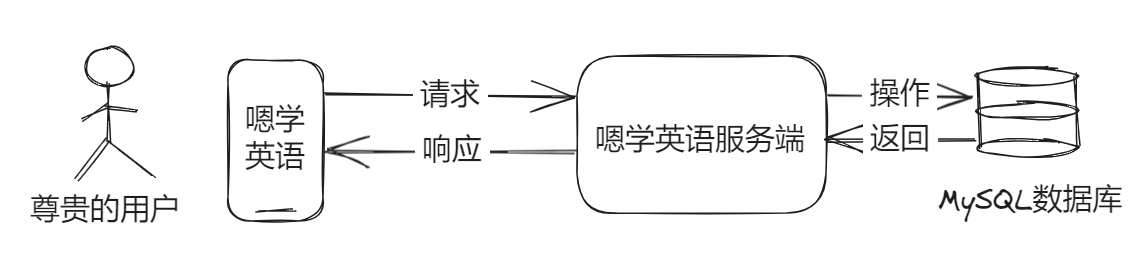
It’s a typical Spring Boot monolithic service, right? The user side operates, requests to the backend service, and then the backend service operates the database and returns. One thing to note is that the service itself is “stateless”, and all states are maintained in the database and distributed cache, otherwise it will not be able to expand comfortably.
The “stateless” here refers to the stateless authentication of the server (Authentication), which belongs to the discussion category of “session state”, so don’t confuse it. Because I write the user’s state into the distributed memory instead of the cache of the current service, there will be no state isolation due to the expansion of multiple instances.
So up to here, we have finished designing the core business.
Improve
Server Bottleneck Improvements
Since learning English is not an offline client mode, it is still very dependent on cloud services. It is impossible for us to say that developing a software can only be used by one or two people, and it will crash if there are too many people, right? So let’s make an assumption here that we have as many users as Duolingo (which can be used for stress test simulations). How should we adjust the architecture to support it?
First of all, let me talk about the entire technology stack and architecture of learning English at present, and then we will use this as a basis for thinking.
Frontend: Nuxt 3, Vue 3, TypeScript, Naive UI, TailwindCSS
Backend: Spring Boot 3, OpenJDK 17
Database and middleware: MySQL, MongoDB, Redis
CI/CD: GitHub Actions, Kubernetes
There are not so many cloud service resources that I can use for demonstration. Here I allocate 512 MB of memory for a single service for demonstration.
After we started stress testing, it was not difficult to find that a single service simply cannot withstand the simultaneous use of many “users”. Fortunately, when we started designing, we took the expansion issue into consideration. I deployed the service in K8S, and the service is stateless, so based on Service (service) and stateful replica set (StatefulSet) to complete orderly and elegant deployment and scaling, only need to add containers The number of group replicas will do.
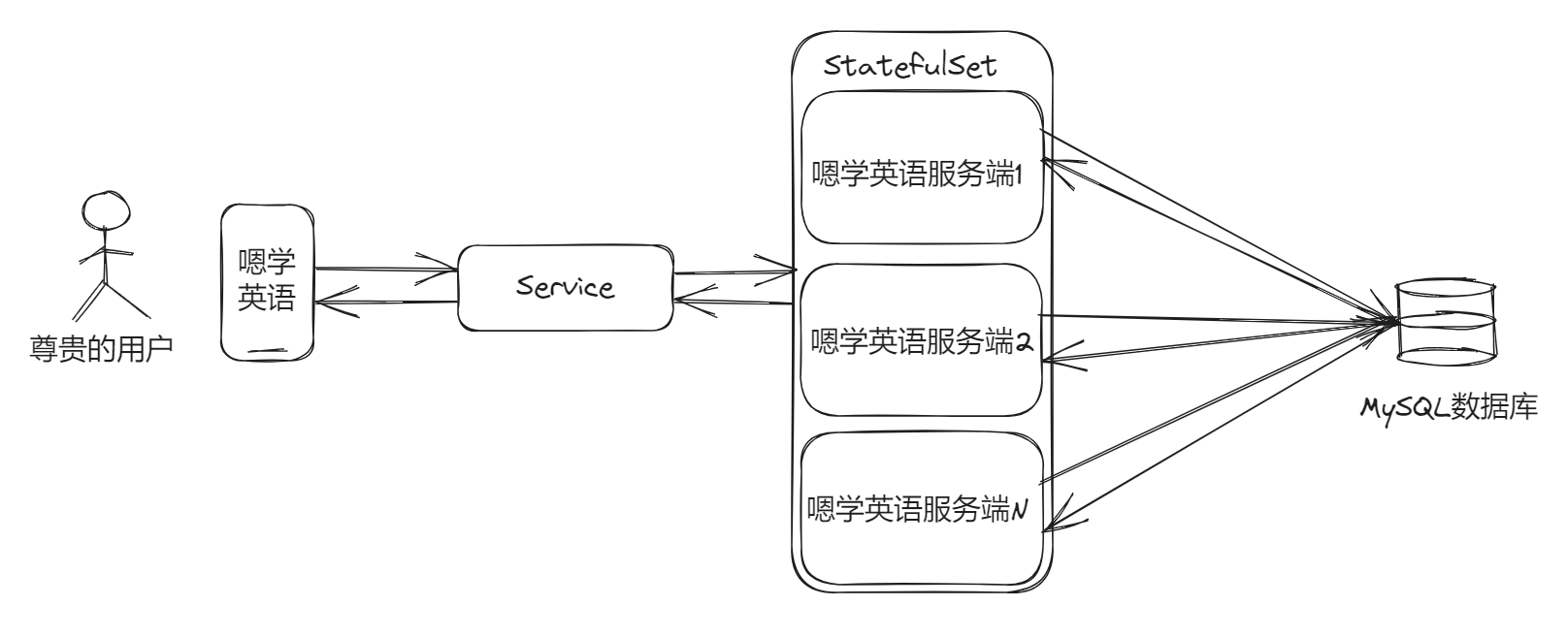
In this way, clients don’t need to care about which backend copy they call. Through rapid expansion, we can also accommodate more requests, and now we can support up to w users to use it at the same time.
Database Bottleneck Improvements
After stress testing for a period of time, we can find that the bottleneck is on the database side. The database CPU usage is high, the number of connections is too high (too many connections), wait timeout and other problems are all here.
We know that the maximum number of MySQL connections has an upper limit, but we can’t directly set the number to the upper limit. We need to set a relatively reasonable value according to the server’s CPU and memory size. I usually default to 210, and the maximum is 1000 (don’t ask me if I can make it bigger, I have to add money!!!).
We can’t directly change the size of the deployment copy of the database like a service. There are many factors to consider. After all, data is the most valuable thing! The solution for this scenario is to go to the cluster , a master instance (reading and writing, or multiple master instances) and multiple auxiliary instances (read-only), here is a picture in the MySQL document:
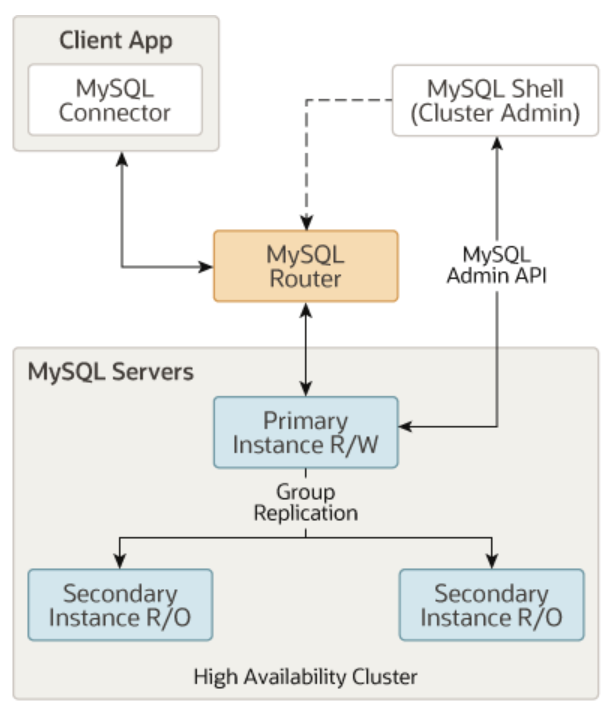
Reflected in the framework of learning English, it should be like this:
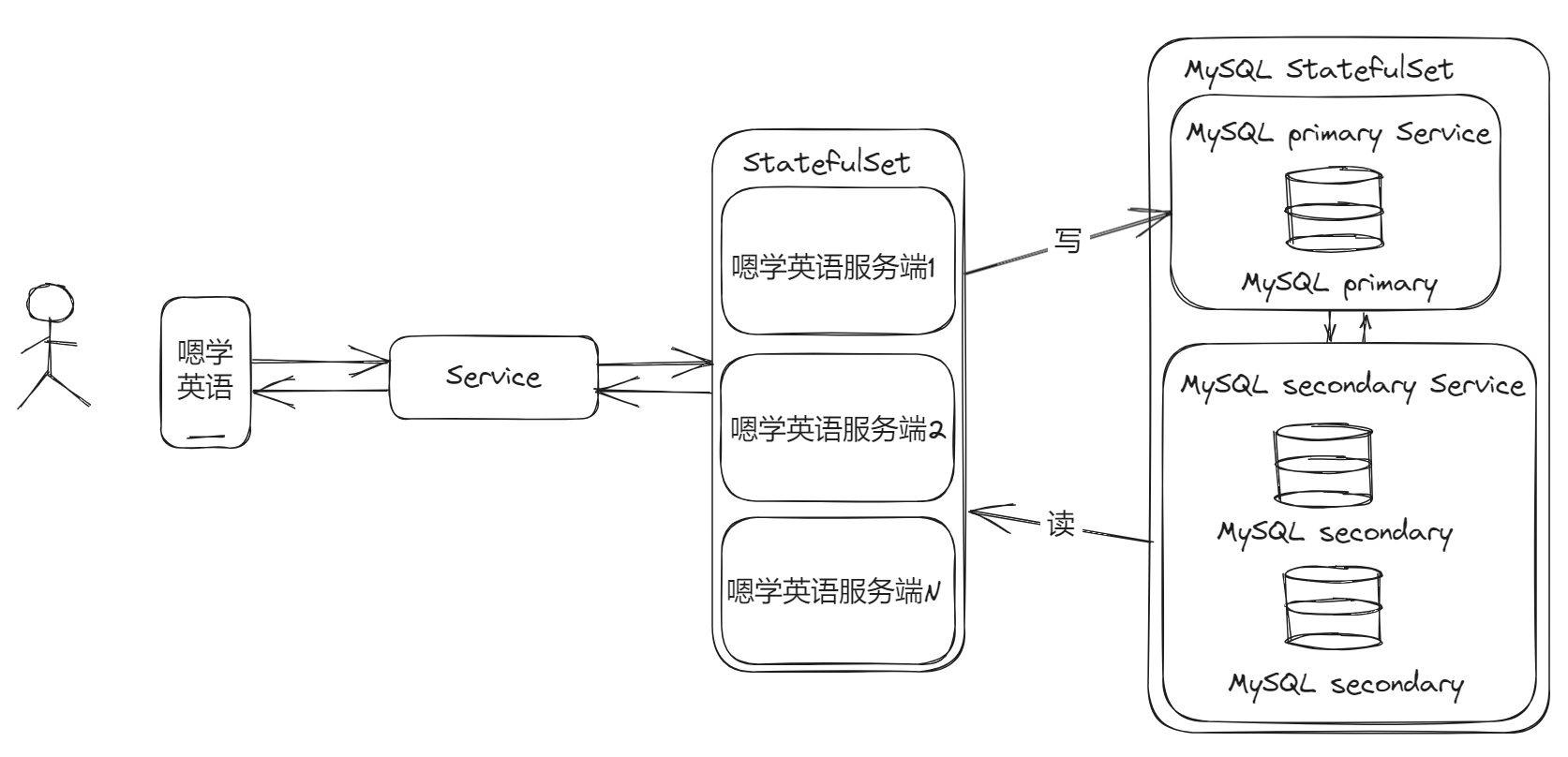
If you are deploying and learning MySQL cluster in K8S for the first time, you can try Bitnami’s MySQL Chart, it will be better to start with this!
In actual development, it is impossible to get on the cluster with one sentence. It is easy to say, and it is only suitable for bragging in interviews. As a developer, you still have to solve the problem from the code design level. If you think about it carefully, do word data, wrong question books and other data all read more and write less? Then we don’t need to go to the database to read every time, but to cache after reading, and update the cache after each update of the data, which can reduce the pressure on some databases.
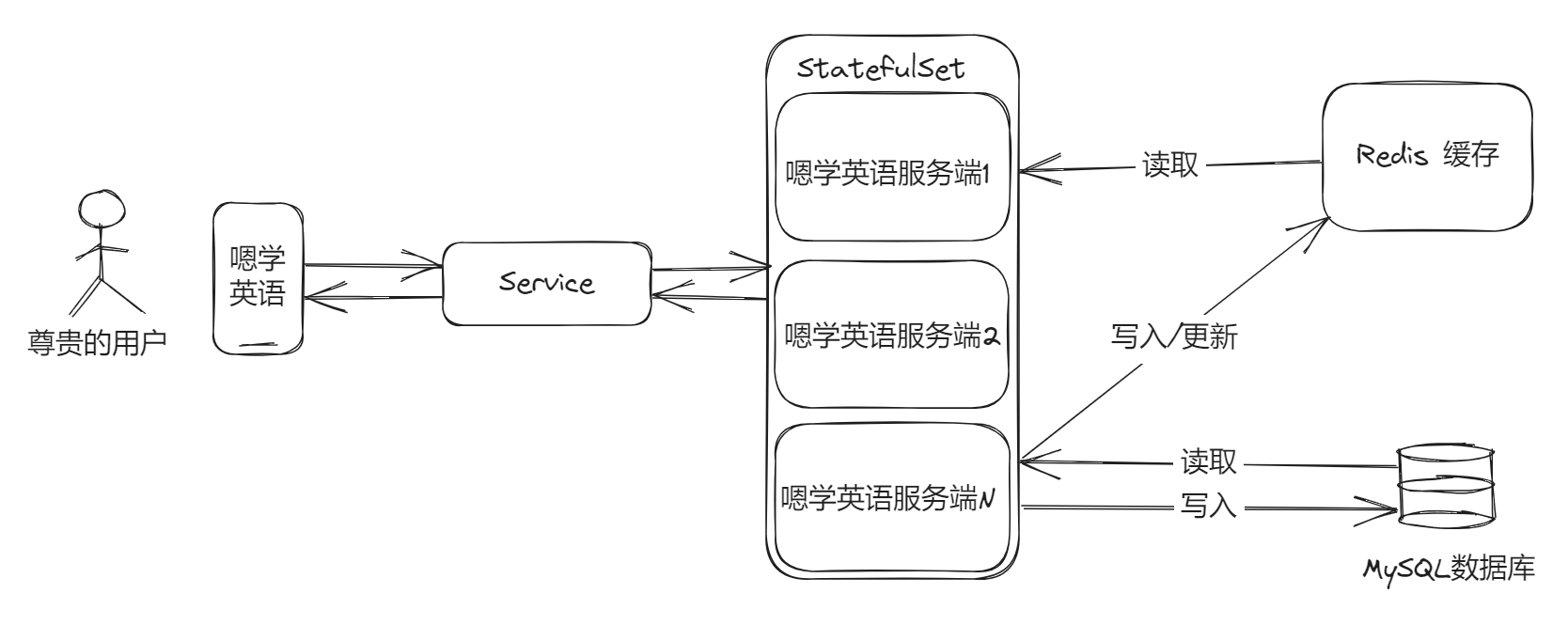
Number of connections resolved
This general micro-service scenario will be easier to do, either based on K8S micro-services, or Spring Cloud, because we used the Spring Boot monomer project in the early stage of learning English, if we use this solution, we need to carry out the architecture adjusted. But I think Duolingo is definitely not a single service, so I still want to talk about it.
Didn’t we expand a lot of services before, so suppose that for each service, we have allocated a database connection pool with a maximum of 50 connections. In theory, the more service copies there are, the more database connections will be occupied.
There is a famous saying, “All problems in computer science can be solved with another level of indirection”, supposedly said by David Wheeler . Introducing this idea, we can find that adding service copies is to ease the “same” operations on the database in the core business, so can we abstract these operations and encapsulate them into an “indirect layer”? Of course there is no problem!
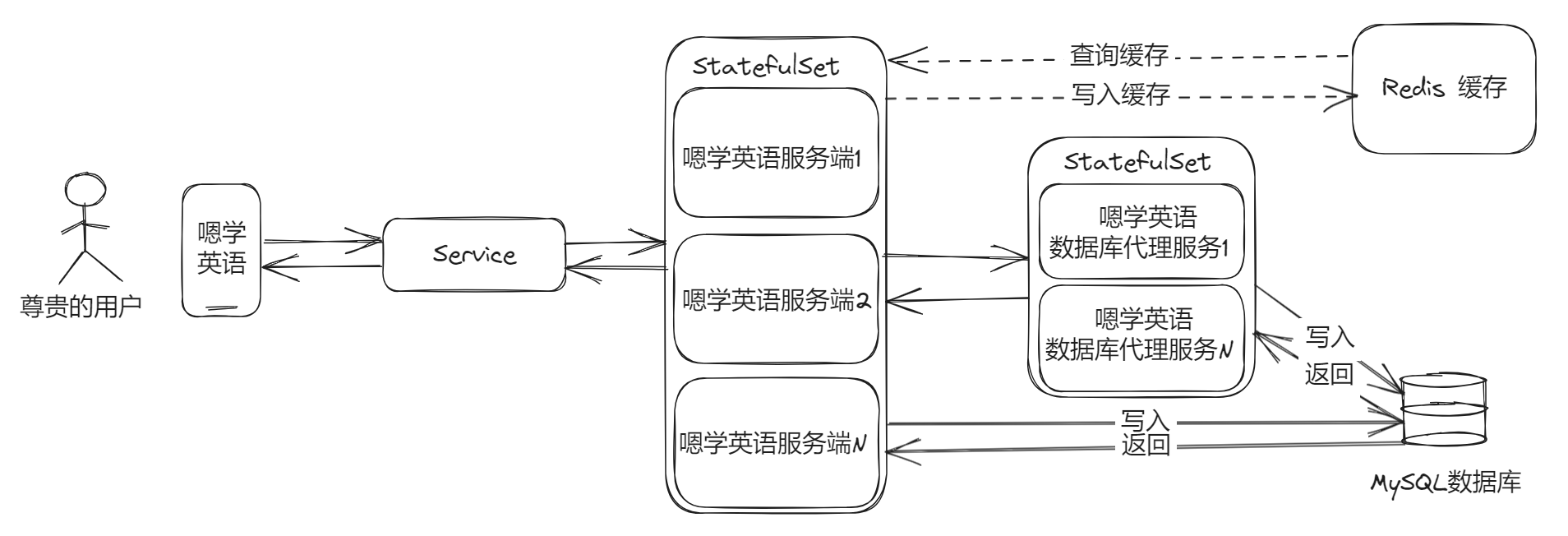
After joining the proxy service, this problem can be greatly alleviated. Note that this set is easier to do in microservices. If you do this in a single service, it will be relatively troublesome to maintain.
asynchronous
After solving the above problems, assuming that one day, learning English suddenly became popular, and all 100,000+ users came to try it out (we added stress testing threads to simulate), our server still crashed!
Although in most scenarios, each user does not operate much on the same piece of data in the database, there is no guarantee that deadlock or lock competition will occur. Our business is also directly stored in the warehouse after each user operation sends a request, and returns after the operation is completed. Although it is the first time to do it, we can analyze Duolingo to see if there are any ideas.
Every time Duolingo completes a unit test, there will be a “short-term” settlement animation. Sometimes even when you go to the personal profile page, the statistics and achievements you see are not refreshed. You may have to wait a while About 1~3 seconds. This kind of learning app has a high tolerance for users. With animation, the experience looks very good. Then, with a little buffer time in the middle, the back-end service can be “slowly” put into the warehouse, and the user’s perception will not be so obvious. It is only necessary to ensure that the data can be preserved to the greatest extent.
Here you can use the thread pool in the proxy service, or use the message queue, and let the proxy service consume it. In the architecture of learning English, I will choose to use RabbitMQ (I am the most familiar with the message queue, and I can choose other ones), the reason is also very simple: I need to be able to gracefully manage the increase of cluster copies of proxy services And reduce, if you can’t directly change the quantity, you don’t care about anything, and if you introduce a message queue, I will worry less.
The introduction of message queues not only reduces some load pressure for asynchronous writing, but also greatly reduces the probability of deadlock and lock competition. This problem is essentially caused by too many requests to operate this piece of data at the same time. We can avoid it by letting the requests enter the queue! After the introduction of the message queue, the proxy service has now become a “consumer node”, and we can still improve the “consumption capacity” through the thread pool or by adding copies.
In addition to the architectural level, we also need to pay more attention to the code level during development. We should avoid locking all row records in the table by full table scanning. Many small partners may not think so much when developing, but after the function is completed, I still suggest to take a look at the execution plan (EXPLAIN). Because sometimes you may not be able to see it just by looking at the SQL, and the execution plan of the SQL executed by different data volumes may also vary greatly. At the same time, Slowest queries should also be monitored. It is not the same thing if there is no sword and no sword is available.
at last
This is the process of thinking, designing and improving my core business of learning English. Of course, there are still many things that should be done, but in fact, the “black swan” incident really happened, and it is difficult to withstand it. of. In the process of continuing to develop and iterate later, I may also make a lot of adjustments. After the development is completed and the open source is released, there may be a big deviation from what is described in this article.
After all, there are still many things that have not been considered, such as what if the middleware is hung up? How do I “observe” (and bug track) each link? How to call the police if there is a problem online (of course our old friends Prometheus and Grafana)? How to query logs (ELK is too heavy, and it is troublesome to open every Pod)? Relying on K8S, I can build a learning English that satisfies these at a low cost, so that I can spend more time thinking at the code level.
Finally, thank you for being able to see this, and welcome to communicate with me if you have any ideas!
This article is transferred from: https://blog.besscroft.com/articles/2023/enstudy-design/
This site is only for collection, and the copyright belongs to the original author.