Original link: https://cdc.tencent.com/2023/04/17/%E4%B8%80%E7%AF%87%E4%B8%8D%E6%98%AF%E5%BE%88% E6%9E%AF%E7%87%A5%E7%9A%84chatgpt%E9%97%B2%E8%B0%88/

This is an article related to ChatGPT, which has three parts in total: First, let’s popularize the science of what GPT in ChatGPT is, then introduce the process from GPT3 to ChatGPT, and finally have some ChatGPT chats. If you don’t want to look at the technology, you can skip directly to the chat. In view of the fact that many excellent creators have made summaries and analyzes, this article will contain a lot of original papers and resource links, all of which are worth reading. Thanks again to these excellent creators.
What is GPT in ChatGPT?
A long time ago (as long as 1982), there was a very classic model in the deep learning model called RNN, namely Recurrent Neural Networks (circular neural network) [1] . The emergence of RNN is to better process sequence information. The value of the hidden layer of RNN is not only affected by the current input, but also depends on the value of the last hidden layer. For example: “I love you” three words, “love” is not only “love”, but also contains the semantic information of “I”. But for longer sequences or sentences, the mechanism of RNN will have the problem of gradient disappearance. Simply put, when the sentence is: “I love you China, I love your vigorous seedlings in spring, I love your golden fruits in autumn, I love you. I love your green pine temperament, I love your red plum character, and I love the sugar cane in your hometown, like milk nourishing my heart.” The last “heart” can no longer contain too much semantic information of the first “I” up. Then, the Attention mechanism first applied in computer vision was used in natural language processing. The idea of this mechanism is to focus on important information and ignore unimportant information (see Attention diagram [2] ). In 2017, Google researchers published “Attention Is All You Need” [3] , the Transformer model in this article is the cornerstone of GPT, the entire network structure is composed of the Attention mechanism [4] , and any sequence in the The distance between two positions is reduced to a constant, and the Transformer has good parallelism, which is in line with the existing GPU framework. It must be mentioned here: Transformer has set up a “position encoding” (position encoding) mechanism to add position information to sequence data, so that the model can learn “order”. The method is simple and ingenious: use sine and cosine functions to generate waveforms that change along the time axis, and then superimpose this waveform into the input of Transformer.
So what is the GPT model? It is a generative pre-training model (GPT, Generative Pre-Training), a model proposed by OpenAI researchers in 2018 [5] . GPT can actually be regarded as a modified model of the decoder part of the Transformer model (the red box is shown in the figure below) [6] .

GPT removes Transformer’s multi-head attention (Multi-head Attention), and then uses specific downstream tasks for fine-tuning (classification tasks, natural language reasoning, semantic similarity, question answering and common sense reasoning) when performing model output. Specifically, GPT adopts a classic neural network training strategy proposed by Hinton et al. in 2006: a two-stage training strategy of “pre-training + fine-tuning” [7] . In the pre-training phase, a generative language model is first trained based on a huge raw corpus; in the fine-tuning phase, the model is continued using labeled data (as shown in the figure below).
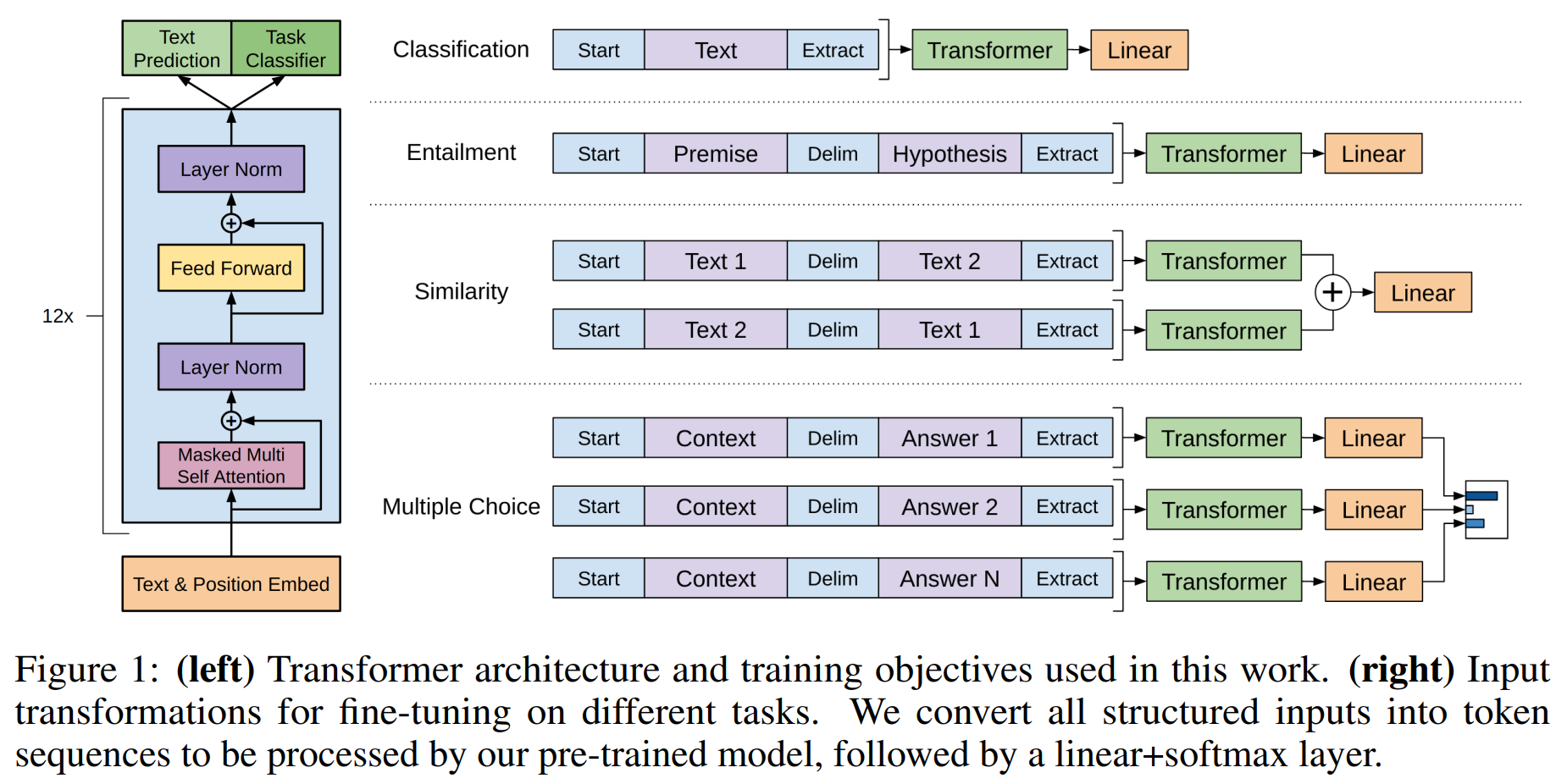
Such a generative model can give him a sequence of N words (also called Tokens) as input, and the output is a prediction of the word most likely to be placed at the end of the input sequence. for example:
After a while, the big bad wolf came, he wanted to break into the little rabbit’s –> home
When we want to get more than one word, we add the next word to the input sequence to get the next word (as shown in the figure below).

With this divergence, there are actually many tasks that GPT can perform, such as: text generation, code generation, question and answer, etc. If you want to involve other types of data, it is not impossible, such as image generation, video generation, etc. Who would Aren’t they high-dimensional vectors?
From GPT3 to ChatGPT
Costly GPT3
Since the GPT model was proposed, OpenAI has been continuously optimizing the model. The model structure of the GPT series adheres to the idea of continuously stacking Transformers, and completes the iterative update of the GPT series by continuously improving the scale and quality of the training corpus and increasing the number of network parameters [8] . Among them, the GPT3 model is the cornerstone of ChatGPT. This model has 175 billion parameters and uses 45TB of data for training. The training cost is as high as more than 12 million US dollars. There is a post on Zhihu discussing how much GPT3 spent [9] . I have to say that these models of OpenAI have been really rich . In the GPT3 article [10] , the author himself confessed (below): the experimental data in the experiment is somewhat problematic, but because the cost of training is too high, it is not appropriate to train again.
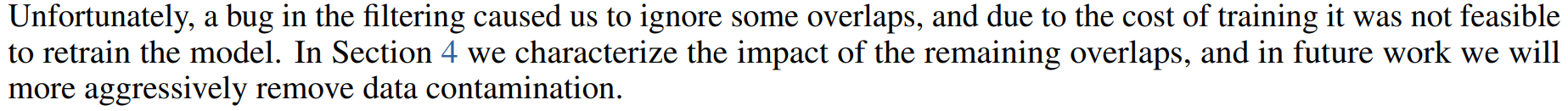
But it has to be said that the effect of GPT3 has achieved some results under the blessing of large corpus and large parameters, and has demonstrated three important capabilities [11] :
- Language generation: follow the prompt (prompt), and then generate a sentence that completes the prompt (completion). This is also the most common way humans interact with language models today.
- In-context learning: following several examples of a given task, and then generating solutions for new test cases. It is very important to note that although GPT3 is a language model, its paper hardly talks about “language modeling”. The authors put all their writing energy into the vision of contextual learning. The real focus of GPT3.
- World knowledge (world knowledge): including factual knowledge (factual knowledge) and common sense (commonsense).
However, what still needs to be kept in mind is that the essence of GPT3 is to learn a large amount of data through a large number of parameters, and then rely on the powerful fitting ability of the transformer to make the model converge. For this reason, the model distribution learned by GPT3 is also difficult to get rid of the distribution of the data set. For some tasks that are obviously not in this distribution or conflict with this distribution, GPT3 is still powerless. The disadvantages of GPT3 are [12] :
- For some questions with meaningless propositions, GPT3 will not judge whether the proposition is valid or not, but fit a meaningless answer;
- Due to the existence of 40TB of massive data, it is difficult to guarantee that the articles generated by GPT3 do not contain some very sensitive content, such as racial discrimination, sex discrimination, religious prejudice, etc.;
- Limited by the modeling capabilities of the transformer, GPT3 cannot guarantee the coherence of a long article or a book generated, and there is a problem of repeating the above in the following.
Even the CEO of OpenAI said that GPT3 will make stupid mistakes, and GPT3 is just a very early glimpse of the field of artificial intelligence (Sam Altman’s Twitter original words are pictured below).

But this is at least a glimpse. The impact of GPT3 on the AI field is far-reaching. It has injected a booster into the AI field and told major hardware manufacturers to work hard. As long as the computing power is strong enough, there is still an upper limit for improvement in AI performance. However, due to its high computing cost, it has also triggered some monopoly discussions: small and medium-sized enterprises have no money to do it, and AI giants have formed a technological monopoly on algorithms that require high computing power. At that time, there was a question on Zhihu “How to evaluate the GPT-3 with 170 billion parameters?” [13] , Qiu Xipeng, a teacher from Fudan University, replied: Nvidia may become the biggest winner! . Mr. Qiu gave the opening paragraph of the famous article “The Bitter Lesson” (The Bitter Lesson [27] ) by Richard S. Sutton, a pioneer of machine learning and professor at the University of Alberta in March 2019. One of the sentences is “70 years of artificial The history of intelligence research tells us that general approaches to harnessing computing power are ultimately the most efficient ones.”

The road to ChatGPT
Again, thanks to the enthusiastic NLP compatriots for their various explanations on the Internet, some netizens sorted out the mental journey from the 2020 version of GPT-3 to the 2022 version of ChatGPT [11] , as shown in the figure below, and gave the evolution of different versions of the model very carefully. and difference.

It can be seen that when the GPT3 model was born, the OpenAI team used it in code generation [14] and InstructGPT, the first generation of ChatGPT based on instruction learning. Among them, Microsoft’s application market has provided relevant code generation services [15] . In fact, code generation is a very lucrative market. Given the high hourly salaries for programmers, saving even a few hours of coding time per month is enough to pay for a Codex subscription. But Codex still makes mistakes! OpenAI researchers warned in the paper: ” The safe use of code generation systems such as Codex requires human supervision and vigilance.” Besides InstructGPT, this is actually the initial model of ChatGPT, and then the model added the RLHF strategy, which is What, the full name is Reinforcement Learning from Human Feedback, which translates to reinforcement learning based on human feedback. Next, let’s review the technical route behind ChatGPT:
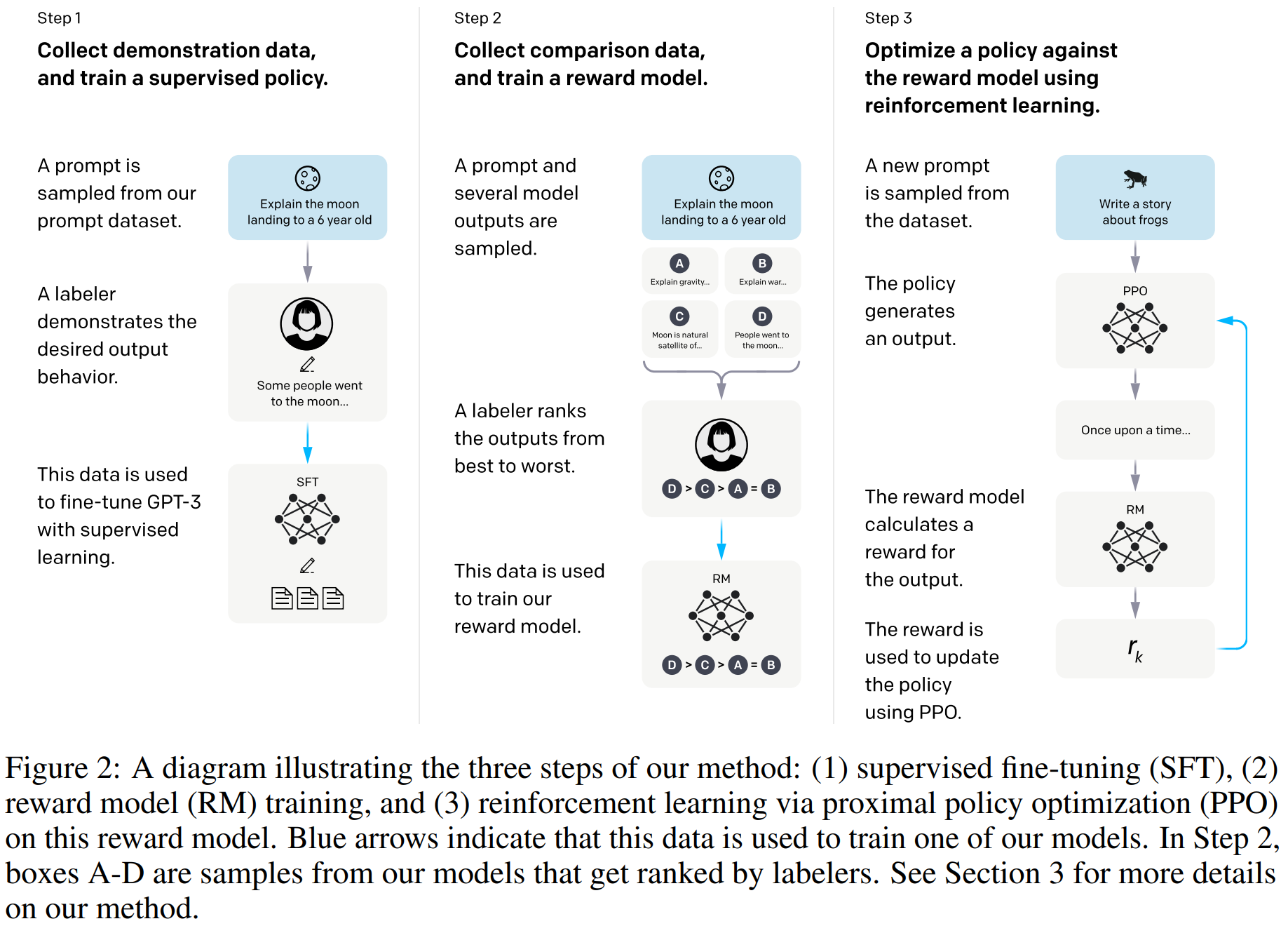
Step1: The engineering team designed a data set based on the Prompt training method, which contains a large number of prompt texts and details what the downstream tasks are. Give this training set to human beings to mark and record human answers, and use this data set to fine-tune GPT3 through Prompt.
At present, people play ChatGPT very much, but part of the reason for the effect of ChatGPT depends on your Prompt (prompt word), so what is Prompt? In fact, it is the sentence you asked ChatGPT, you can ask him what day of the week it is, you can also ask him who Newton is, and you can ask many questions. But how to ask and what to ask will get answers with different effects. At present, many netizens have summed up how to write Prompt instruction manual [16] , books are sold on the Amazon website, and there are even websites dedicated to trading Prompt [17] . Everyone is working really hard to make money.

Write Prompt well, and you will not be afraid to travel all over the world. According to the prompt writing principles summed up by enthusiastic netizens, it is necessary to follow these points as much as possible [16] :
- Be clear, avoid complexity or ambiguity, and if there are terms, they should be clearly defined.
- Specifically, the description language should be as specific as possible, not abstract or ambiguous.
- Focus and avoid questions that are too broad or open.
- Be concise and avoid unnecessary descriptions.
- Related, mainly refers to the theme related, and it is during the whole dialogue, don’t go over everything.
Step2: Let’s call the fine-tuned model GPT3-1. Use GPT3-1 to predict the first step of the data set task to get N results, and let the labeler mark the quality of each option and put the marked The dataset is used to train the Reward Model (RM).
In fact, this step is reinforcement learning based on human feedback, that is, targeted optimization through human feedback. If deep learning is learning representations, reinforcement learning is learning rules. To put it simply, in the past, we only output one result A for the input, and then we continued to optimize the result A; now, we output the results A, B, C, D for the input, and then I also told the model this A, B, C , D, which one is good, which one is not good, you have to learn the model carefully, and try to learn the good options instead of the bad ones (the goal of the reward model is to get high scores).
Step3: Use the PPO strategy to update the parameters, use GPT3-1 to predict the results of the data set again, and score through the reward model in the second step to calculate the reward (reward). Finally, this reward score is given to GPT3-1 through PPO for training.
In short, the third step is to put the reward result into the parameter update link of the model, and continuously fit it to get the final model. The full name of PPO [18] mentioned here is Proximal Policy Optimization, the proximal policy optimization algorithm. There are also many analysis on the Internet [19] , which is used for policy gradient descent. A chestnut that is often cited in machine learning is that if a person wants to go down the mountain, where to go, the downhill is stable and fast. There are three types of gradient descent algorithms: batch gradient descent, stochastic gradient descent, and mini-batch gradient descent. The PPO algorithm proposes that the objective function can be updated in small batches in multiple training steps, which solves the problem that the step size is difficult to determine in the policy gradient algorithm. If the step size is too small, the training time will be too long. If the step size is too large, useful information will be masked by noise (because each data has a large impact), or the performance will drop catastrophically, making it difficult to converge [20] . Speaking of the third step, many people who eat melons will now ask: Why is it OpenAI that has become popular, instead of the first-tier domestic manufacturers? My answer is: Take the PPO strategy (the algorithm used to update parameters) in ChatGPT as an example. This PPO was proposed by the OpenAI team in 2017. It is an improved version of the TRPO algorithm [21] proposed in 2015. The person behind the TRPO algorithm is John Schulman, a doctoral student at Berkeley, and others, including his mentor. His mentor is Pieter Abbeel, a great god in the field of reinforcement learning. Abbeel is an associate professor at Berkeley and a research scientist at OpenAI. One of the influential people. It has to be said that every step people take now is because of every step they took before.
ChatGPT Chat
Why ChatGPT is famous, but GPT3 is not?
First of all, back in 2019, the Google team proposed the Bert model [22] . It costs about $6,912 to train a Bert model and rent cloud computing power. The computing power required by GPT3 is more than 1,900 times that of Bert. In addition, under the same parameter scale, Bert The effect is better than GPT. The Bert model was used in my graduation thesis at that time. Bert really became the baseline of various experiments at that time. Wikipedia mentioned: A literature survey in 2020 concluded: “In a little more than a year, BERT has become a ubiquitous baseline in NLP experiments”, with over 150 research publications including analysis and improved models [23] . Bert wins because it is easy to get. I personally feel that GPT is not as popular as Bert, and Bert is mostly involved in all kinds of work in large factories. So why is ChatGPT out of the circle? I think a big reason is his way of getting out of the circle. Many times before, when he was engaged in artificial intelligence research, whenever he made breakthroughs, he published papers to explain how powerful his model was. Even if the API is released, there is still a certain threshold for using it. At most, you can brag about how powerful the model is on Twitter.

But this time ChatGPT is completely different. It directly released a dialog box for everyone to play, men, women and children can participate, and the effect is not bad, so it will become popular all of a sudden. For such a bold release, I have to mention “Tay who was killed in those years”. In 2016, an artificial intelligence chat robot Tay was released on Twitter, but within less than a day after opening a dialogue with users, It “becomes” a Hitler-loving, feminist-spoofing robot that ends up sparking controversy with inappropriate racist remarks. Therefore, what I want to introduce next is some achievements of ChatGPT in data annotation. They have strict and standardized labeling guidelines [24] , and they will never answer some questions that cannot be answered. So at present, if it is just a simple prompt to ask, ChatGPT can still avoid some bad questions. Compared with directly training with open corpus, this kind of model that costs more money but has a certain quality assurance of data can still be used for public fun. It is said that OpenAI hired 80 human labelers to generate 64,800 pieces of data to adjust the model, costing about one million.
After the nonsense ChatGPT was born
First of all, ChatGPT is not an algorithm, but more like a set of solutions, that is, an organic system that integrates multiple methods. The model traceability is basically built on the basis of previous research. In addition, it is very particular about data quality and diversity. Although the amount of data for ChatGPT reinforcement learning is not large, the data diversity and labeling system are exquisitely designed, allowing the data to play a powerful role. So of course ChatGPT still has a lot of issues in dispute at present, here are some voices intercepted (sorry for not being able to mark the source!):
- data problem
“ChatGPT is trained on public data, which is usually collected without consent, which will bring a series of responsibility attribution issues.” Regarding this point of view, many friends have paid attention to AIGC’s Legal and ethical risks that may be brought about by development. For example, when we use ChatGPT, data needs to enter and exit the country. The human server is not in China, and we have not been allowed to use it. For example [30] , in January 2023, the world-renowned photo provider Getty Images sued Stability AI, the developer of the popular artificial intelligence (AI) painting tool Stable Diffusion, claiming that it stole hundreds of million pictures. In addition, three artists have filed lawsuits against Stable AI and another AI painting tool Midjourney, as well as the artist portfolio platform DeviantArt, saying that these organizations obtained 5 billion pieces from the Internet “without the original author’s consent”. images to train its artificial intelligence, violating the rights of “millions of artists”.
“We do not allow AI to be listed as an author on our published papers, and using AI-generated text without proper citations may be considered plagiarism,” said the editor-in-chief of the Science series of journals
“The internal knowledge of the model is always cut off at a certain time. The model always needs the latest knowledge to answer the latest questions. The next big drawback of ChatGPT is that it cannot obtain Internet information in real time.” At this point, the chairman of Microsoft said : Bing and Edge+AI, a new way of searching begins.
- cost issue
“Customers have privatized deployment requirements, but these models are very large and require high resource requirements, and it is currently unlikely to achieve privatized deployment.”
“No boss can accept that it costs a few cents for an NPC to reply to a sentence, even if it is good.” As for this point of view, six scientists from Stanford and Google [29] have recently played with it. The researchers used GPT-3.5-Turbo builds a sandbox world where NPCs can engage in non-preset social interactions. For example, 12 NPCs were invited to a party, but five of them went, three of them didn’t because they had scheduling conflicts, and the remaining four didn’t show up because they didn’t want to. (Although it sounds strange that such an NPC, but to be honest, what our model learns is human corpus, and people are such pigeons)
But what I saw most touched me was this sentence: “In the short term, people may overestimate this thing, but in the long run, many people may underestimate this thing.” First of all, ChatGPT has come to this point today, It is accumulated on the basis of many important cornerstones. I believe that ChatGPT should also become a cornerstone, and more capabilities will be built on this basis. This is not a one-time success, but a glimpse of artificial intelligence. And the computing power (hardware), data (money, the ability to own data), and algorithms (some real scientific researchers) required behind are all indispensable. On February 20, the Natural Language Processing Laboratory of Fudan University released the news of China’s first “conversational large-scale language model MOSS”, which caused a sensation in the technology circle, and a large number of visits once caused the server to overload. On the morning of the 21st, the MOSS R&D team apologized for the “bad experience” through an open letter, expressing their willingness to open source and share relevant experience, code, and model parameters after MOSS completes the preliminary verification. MOSS was developed by Professor Qiu Xipeng’s team. It feels like an example of “having real scientific researchers + no hardware support and engineering capabilities”.
Looking at the recent past, someone asked: What impact does ChatGPT have on the direction of technology development in the multimodal field? That must be: rolled up! On March 6, Google released the “generalist” model PaLM-E. As a multimodal embodied VLM, it can not only understand images, but also understand and generate language, and execute various complex robot instructions without retraining. It also exhibits strong emergent capabilities (models have unpredictable behavior). Then it didn’t take long, Microsoft started to pull OpenAI, and N made a big splash. Last Tuesday, OpenAI and Microsoft released GPT4 [25] , which also focuses on multimodality. The experimental effect is better than PaLM, and it can perform a lot of tasks. Comparable to human level. In the simulated bar exam, GPT4 achieved good results in the top 10%. For the SAT test questions of the US college entrance examination, GPT-4 also scored 710 points in reading and writing, and 700 points in mathematics (out of 800).

The engineering of the entire GPT4 model is participated by teams such as pre-training, vision, long text, reinforcement learning and alignment, evaluation and analysis, and deployment. At the same time, OpenAI also thanks Microsoft for its cooperation, especially Microsoft Azure for supporting the model in terms of infrastructure design and management. Training, and the cooperation between the Microsoft Bing team and the Microsoft security team in security deployment (see the official account article explanation [26] for details). As a result, when I turned my head again, the Bing browser immediately used the model. I have to say that maybe this will be a fatal blow to Google. Recall that Google laid off more than 12,000 people in early 2023, and there are many senior open source leaders. Knowing that the most popular artificial intelligence machine learning frameworks such as PyTorch, TensorFlow, and Rasa are all open source projects, but at that time let the best and brightest open source experts leave, and there is some drama at the moment. But to be honest, people’s GPT4 paper also said : Our model is still not completely reliable (it will fantasize some facts by itself, and reasoning errors, the word hallucinate is wonderful!) , you should be careful when using language model output, especially in high-level risk context and requires exact protocols (e.g. human review, additional context, etc.).

So everyone, it’s better to wake up moderately first. As a result, last Thursday, Microsoft came with the family bucket that had been opened by GPT4, which caused everyone, I think at least most people couldn’t wake up for a while, GPT4 is too high. Microsoft CEO Nadella said that today is a milestone, which means that the way we interact with computers has entered a new stage. From then on, the way we work will change forever and start a new round of productivity explosion. To be honest, the model is still the same model, that is, the application scenarios and methods have changed, and in a landing environment such as office software, at least people’s requirements are clear. Compared with the open ChatGPT, the effect of Family Bucket may be better. Recently, people who eat melons are anxious about whether they will be replaced by artificial intelligence. LeCun, one of the deep learning giants, is anxious: Calm down, it’s still early.

Looking back at the week in mid-March, it was simply a week of burning big models (dog head):
On March 13, Stanford released the LLaMA model: https://github.com/tatsu-lab/stanford_alpaca
On March 14, Tsinghua released the ChatGLM-6B model: https://github.com/THUDM/ChatGLM-6B
On March 14, OpenAI released the GPT4 model: https://openai.com/product/gpt-4
On March 14, Google gave PaLM API: https://blog.google/technology/ai/ai-developers-google-cloud-workspace/
On March 15th, PyTorch2.0 was released: https://pytorch.org/blog/pytorch-2.0-release/
On March 16, Microsoft released Microsoft 365 Copilot: https://blogs.microsoft.com/blog/2023/03/16/introducing-microsoft-365-copilot-your-copilot-for-work/
On March 16, Baidu released Wenxin Yiyan: https://yiyan.baidu.com/welcome
Large language model combing
Then, all the way to mid-April, all the big language models were completely unblocked. For this reason, many netizens and researchers have sorted out the current large language models. For example, the article “A Survey of Large Language Models” [28] submitted at the end of March 2023 gives the data that has been published in the public since 2019. The model that appeared in front of you (as shown in the figure below). This is a very good article, sorting out the training data types of different large language models, the process of data processing, and the details of building the model (such as activation functions, standardized measures, parameter quantities, optimization settings, etc.).

There are also many projects on GitHub that have made a summary, such as: https://github.com/Hannibal046/Awesome-LLM , in addition to the link to the paper, this project also gives some access resources such as API, and also gives a lot of instruction manuals, There are also some perspectives on the course. Among them, I saw a link on Zhihu [31] , the author said that there are three points behind the ChatGPT technology:
- In-depth information revolution: Search engines have always been the mainstay before, and users need to perform secondary processing or processing on the information presented. The information presented by the large language model can meet the needs of users, or gradually reach the needs of users through interaction. requirements, but there are still issues of information reliability.
- The relationship between man and machine will change: This can be understood as the form of interaction between man and machine will change, such as direct interaction through human language.
- The ability of machines to generate content has been greatly enhanced: Judging from the current various family buckets, it seems that people’s work efficiency will be greatly improved. Some boring work such as text and pictures can be done by machines.
Finally, I changed [32] with someone else’s words: in the era when Bert was rampant, TextCNN still existed. In the era of large language models, we can also find things to do.
This article is reproduced from: https://cdc.tencent.com/2023/04/17/%E4%B8%80%E7%AF%87%E4%B8%8D%E6%98%AF%E5%BE%88% E6%9E%AF%E7%87%A5%E7%9A%84chatgpt%E9%97%B2%E8%B0%88/
This site is only for collection, and the copyright belongs to the original author.