Original link: https://www.msra.cn/zh-cn/news/features/acl-2022
Editor’s note: As an international top academic conference in the field of natural language processing, ACL attracts a large number of scholars to submit manuscripts and participate in the conference every year. This year’s ACL conference will be held from May 22 to May 27. It is worth noting that this is also the first attempt after the ACL Conference adopted the ACL Rolling Review mechanism. In this conference, many papers of Microsoft Research Asia were selected. This article selects 6 of them for a brief introduction. The topics of the papers cover: encoder-decoder framework, natural language generation, knowledge neurons, extractive text Abstracts, pretrained language models, zero-shot neural machine translation, and more. Interested readers are welcome to read the original paper.
SpeechT5: A jointly pretrained encoder-decoder framework for speech and text

Paper link: https://ift.tt/kQKwg8u
Encoder-decoder frameworks are widely used in natural language processing and speech processing, such as end-to-end neural machine translation models and speech recognition models. Inspired by the successful application of T5 (Text-To-Text Transfer Transformer) on pre-trained models for natural language processing, this paper proposes a joint framework SpeechT5 that unifies speech modality and text modality, which explores the use of self-supervised speech and Encoder-Decoder Pretraining Methods for Text Representation Learning.
SpeechT5 contains a shared encoder-decoder network and corresponding modality pre-processing/post-processing network, which attempts to translate different speech processing tasks into speech/text-to-speech/text problems through an encoder-decoder framework. Leveraging large-scale unlabeled speech and text data, SpeechT5 unifies pre-training to learn representations for both modalities to improve the ability to model speech and text. To align text and speech information into a unified semantic space, this paper proposes a cross-modal vector quantization method that randomly mixes speech and text vectors and latent quantization vectors as a Semantic interface. The researchers evaluated the proposed SpeechT5 model on a variety of different speech processing tasks, including automatic speech recognition, speech synthesis, speech translation, speech conversion, speech enhancement, and speaker recognition, all showing the effectiveness and superiority of the model sex.
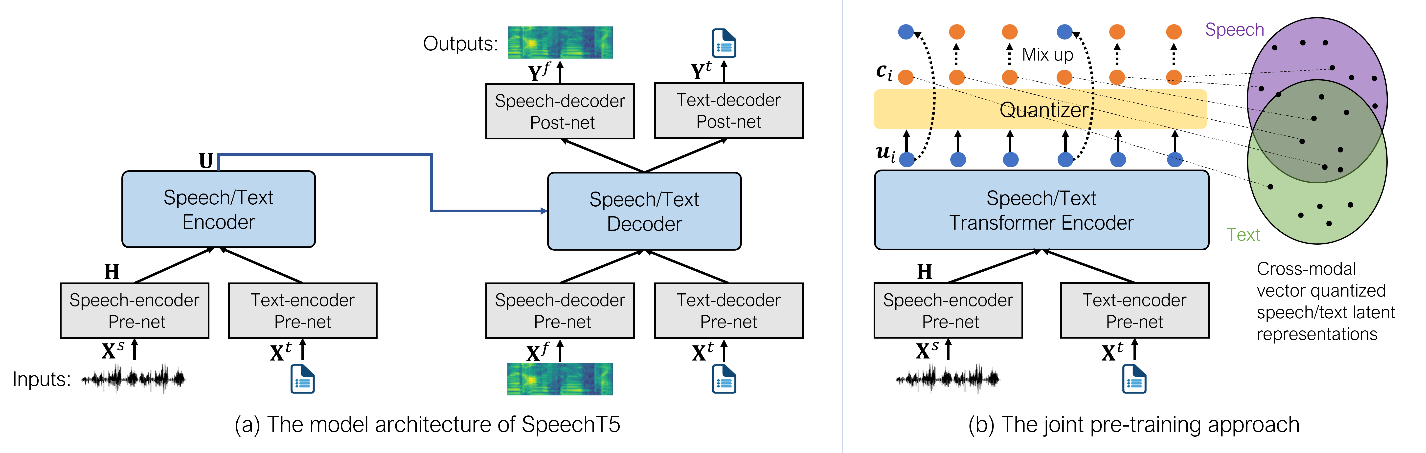
Figure 1: (a) is the SpeechT5 model architecture, which contains an encoder-decoder module and six modality-specific pre-/post-processing networks. (b) is the joint pre-training method, which builds a bridge between speech and text by sharing latent quantization vectors between different modalities.
Controllable Natural Language Generation Using Contrastive Prefixes

Paper link: https://ift.tt/OidVvb6
To guide the generation of large pretrained language models, previous work has mainly focused on fine-tuning language models directly or leveraging attribute classification models to guide generation. Prefix-tuning (Li and Liang, 2021) proposes to replace fine-tuning on downstream generative tasks by training a prefix (a small-scale continuous vector). Inspired by this, the researchers propose a novel lightweight framework for controlling GPT2 generation in this paper. The framework utilizes a set of prefixes to guide the generation of natural language text, each prefix corresponding to a controlled attribute.
Compared to using attribute classification models or generative discriminators, using prefixes to achieve controllability has the following advantages: First, it introduces fewer additional parameters (about 0.2%-2% of GPT2 parameters in experiments). Second, using prefixes can make inference speed comparable to the original GPT2 model. Unlike Prefix-tuning, where each prefix is trained independently, the researchers at Microsoft Research Asia believe that attributes are correlated (such as positive and negative sentiments are opposed to each other), and learn this relationship during training Will help improve the control effect of the prefix. Therefore, in this framework, researchers consider the relationship between prefixes and train multiple prefixes simultaneously. This paper proposes a new supervised training method and a new unsupervised training method to achieve single-attribute control, and the combination of these two methods can achieve multi-attribute control. Experimental results on single-attribute control tasks (emotion control, detoxification, topic control) show that the researchers’ proposed method can guide generated texts with target attributes while maintaining high linguistic quality. While experimental results on multi-attribute control tasks (emotional and topic control) show that prefixes trained with this method can successfully control both attributes simultaneously.
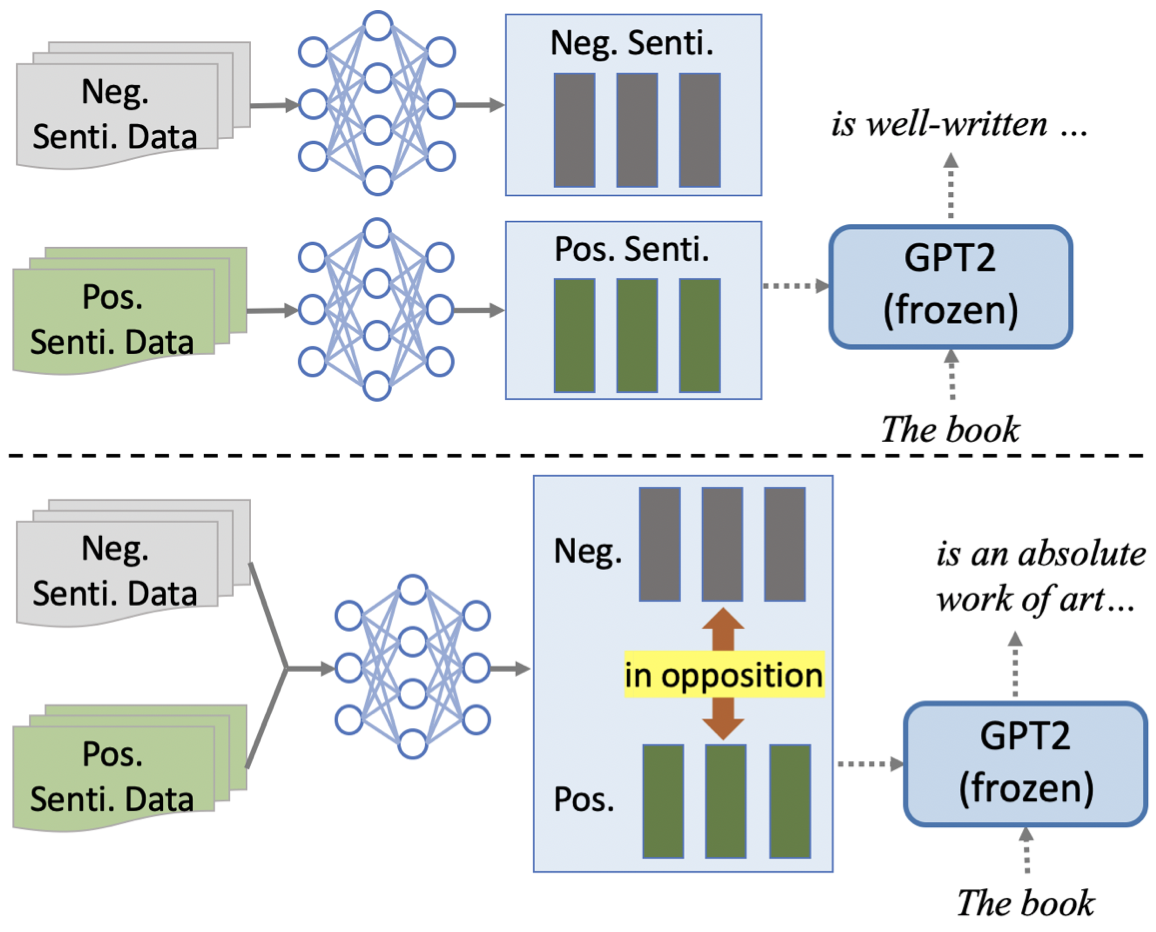
Figure 2: Comparison of Prefix-tuning (top) and our method (bottom) on emotion control tasks. Solid arrows represent the training process and dashed arrows represent the generation process. In the framework proposed in this paper, training can be supervised, semi-supervised, or unsupervised.
Knowledge Neurons in Pretrained Transformers

Paper link: https://ift.tt/05LyHqN
In recent years, large-scale pre-trained language models have been shown to have better ability to recall knowledge exposed in pre-trained corpora. But existing knowledge probe works, such as LAMA, only focus on evaluating the overall accuracy of knowledge predictions. This paper attempts to conduct a more in-depth study of pre-trained language models, by introducing the concept of knowledge neurons, to explore how factual knowledge is stored in the model.
First, as shown in Figure 3, the researchers compared the FFN module in Transformer to the key-value memory module. Specifically, the first linear layer in FFN can be seen as a series of keys, while the second linear layer can be seen as a series of corresponding values. A latent vector first calculates the activation value of a series of interneurons by inner product with the keys in the first linear layer, and then uses this activation value as a weight to perform a weighted summation of the values in the second linear layer . The researchers hypothesized that knowledge neurons reside within these interneurons.
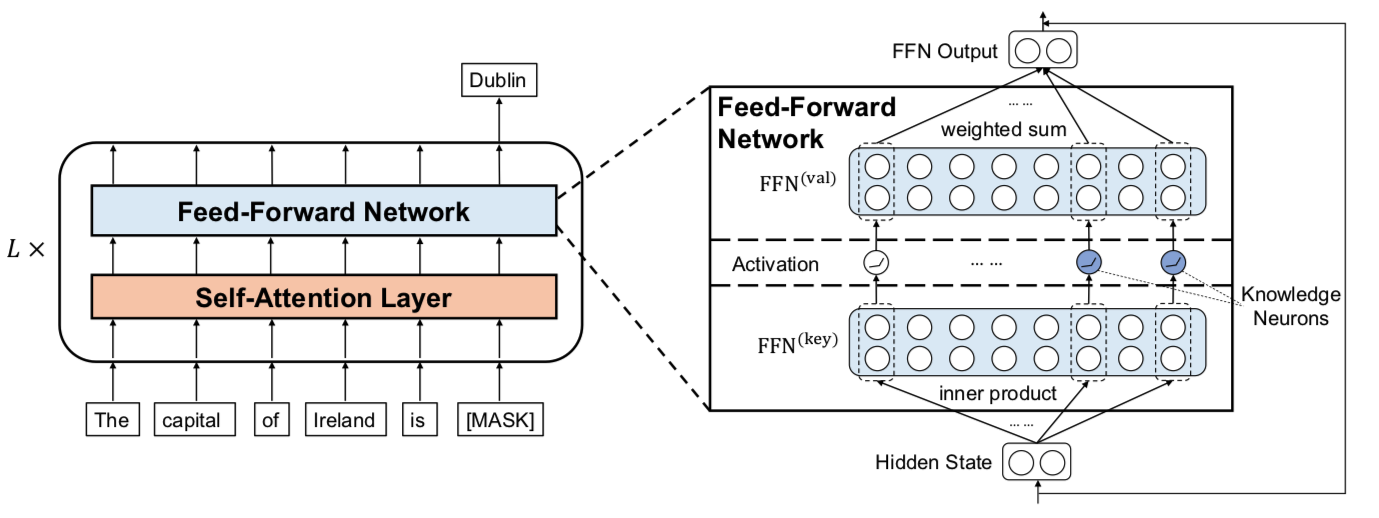
Figure 3: Researchers have compared FFN modules to key-value memory modules in which knowledge neurons reside
Based on the above analogies and assumptions, the researchers propose a set of methods for detecting knowledge neurons. Based on the task of filling in the blanks with knowledge, researchers first use the knowledge attribution algorithm to find the neurons that are most important to the final knowledge expression, and then go through a knowledge neuron refining step to further extract the neurons that are most relevant to the knowledge expression.
The researchers verified the relationship between knowledge neurons and knowledge expression through experiments: in the positive direction, the researchers verified that the activation value of knowledge neurons can directly affect the expression of factual knowledge; in the reverse direction, the researchers verified the knowledge neural network. Meta is more easily activated by texts that express knowledge. In addition, based on knowledge neurons, this paper also proposes two preliminary knowledge editing methods. By modifying the parameters in the FFN corresponding to the knowledge neurons, a piece of knowledge in the pre-training model can be updated to a certain extent, or a piece of knowledge in the pre-training model can be updated to a certain extent. remove a whole class of knowledge from .
Zero-Sample Multilingual Extractive Summarization Based on Neural Label Search

Paper link: https://ift.tt/tDXOwjG
Extractive text summarization has achieved good performance in English, mainly thanks to large-scale pre-trained language models and rich annotated corpora. But for other small languages, it is currently difficult to obtain large-scale annotation data. Therefore, the research content of this paper is multilingual extractive text summarization based on Zero-Shot. The specific method is to use the extractive text summarization model pre-trained in English to directly extract summaries in other low-resource languages. Aiming at the problem of monolingual label bias in multilingual Zero-Shot, this paper proposes a multilingual label (Multilingual Label) labeling algorithm and a neural label search model NLSSum.
Multilingual labels are labels constructed by unsupervised methods such as machine translation and bilingual dictionary replacement. word substitution to construct. Labels constructed in this way can incorporate more cross-lingual information into the labels.

Figure 4: Multilingual extractive summary label construction. a is the set of labels obtained in English, and b, c, and d are the sets of labels obtained by performing machine translation (MT) and bilingual dictionary replacement (WR) on the English training set.
NLSSum assigns different weights to different tag sets in multilingual tags through neural search, and finally obtains the weighted average tag of each sentence. This paper uses this final label to train an extractive summarization model on the English dataset (see Figure 5). Among them, the label score of each sentence comprehensively considers the results of the sentence-level weight predictor T_α and the label set-level weight predictor T_β. Compared with monolingual labels, there is more cross-lingual semantic and grammatical information in multilingual labels, so the NLSSum model greatly surpasses the scores of the baseline models on all language datasets of the dataset MLSUM, even surpassing the unused scores A supervised approach (Pointer-Generator) for pretrained models.

Figure 5: Multilingual Neural Label Search Summarization Model
In this paper, the researchers further studied the distribution of important information between different languages through visual analysis. It can be found that the distribution of important information in English language is relatively high, and the distribution of important information in other languages is relatively scattered. An important reason why language tags can improve model performance.
NoiseyTune: Adding a little noise can help you fine-tune your pretrained language model better

Paper link: https://ift.tt/TPxfjIC
Pre-trained language models are one of the hottest technologies in the field of natural language processing in recent years. How to effectively fine-tune the pre-trained language model in downstream tasks is the key to its success. Many existing methods directly leverage data from downstream tasks to fine-tune pre-trained language models, as shown in Figure 6(a). However, researchers believe that language models also run the risk of overfitting pretrained tasks and data. Since there is usually a gap between pre-training tasks and downstream tasks, it is difficult for existing fine-tuning methods to quickly transfer from the pre-training space to the downstream task space, especially when the training data for the downstream tasks is sparse. In response to this problem, researchers at Microsoft Research Asia have proposed a simple and effective solution, which is to perturb the pretrained language model by adding a small amount of noise before fine-tuning, named NoiseyTune. Its paradigm is shown in Figure 6(b).

Figure 6: Comparison of the standard language model fine-tuning approach and the approach proposed in this paper
The researchers believe that adding a small amount of noise to the PLM can help the model “explore” more of the underlying feature space, thereby alleviating the problem of overfitting to the pretraining task and data. In order to better preserve the knowledge of the language model, the researchers proposed a method of adding uniform noise according to the variance of the parameter matrix. This method can add noise of appropriate intensity according to the characteristics of different types of parameters. The formula is as follows. where the hyperparameter λ controls the strength of the added noise.

The researchers conducted experiments on the English GLUE dataset and the multilingual XTREME dataset. The results show that NoiseyTune can effectively improve different types of language models, especially for relatively small datasets.
In addition, the researchers further explored the effect of adding different noises on NoiseyTune, and found that adding noises with a uniform global distribution often detrimental to the performance of the model, and adding them according to the degree of deviation of the parameter matrix is more effective. Also, adding evenly distributed noise to the model works better than Gaussian noise, probably due to its lack of hard range constraints.
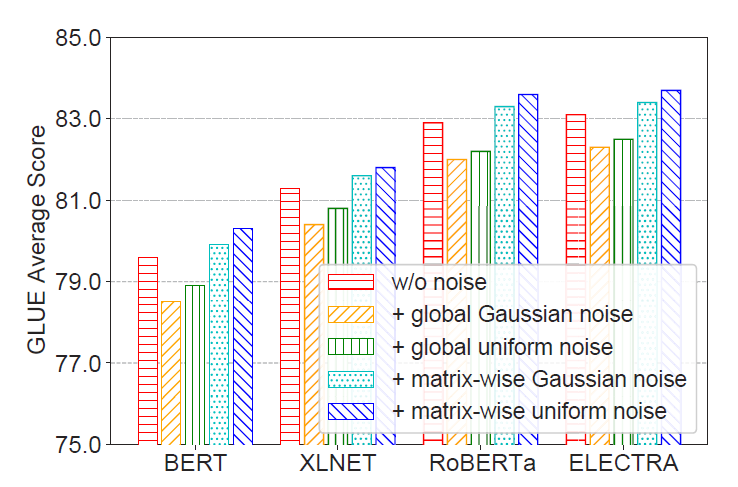
Figure 7: Effects of different noise types on NoiseyTune
Cross-language transfer for zero-shot neural machine translation

Paper link: https://ift.tt/J4MSq5t
This paper demonstrates that in zero-shot neural network machine translation, both appropriate multilingual pre-training and multilingual fine-tuning methods are crucial to improve the ability of cross-language transfer. Based on this motivation, the researchers proposed SixT+, a powerful multilingual neural machine translation model that uses only parallel corpora in six languages for training, but can support translation in 100 languages at the same time.
SixT+ uses XLM-R large to initialize the decoder embedding and the entire encoder, and then train the encoder and decoder using a simple two-stage training strategy. SixT+ has achieved good results in many translation directions, significantly outperforming CRISS and m2m-100, two powerful multilingual neural machine translation systems, with average gains of 7.2 and 5.0 BLEU, respectively.
In addition, SixT+ is also a good pretrained model that can be further fine-tuned for other unsupervised tasks. Experimental results demonstrate that SixT+ outperforms the average BLEU of state-of-the-art unsupervised machine translation models by more than 1.2 on the translation of two languages, Slovenian and Nepali. SixT+ can also be applied to zero-shot cross-language summarization, and its average performance is significantly higher than mBART-ft, with an average improvement of 12.3 ROUGE-L. The researchers also conducted a detailed analysis of SixT+ to understand the key components of SixT+, including the necessity of multilingual parallel data, position-separated encoders, and the ability of their encoders to transfer across languages.

Figure 8: The two-stage training framework proposed by the researchers uses the multilingual pretrained model XLM-R to build a cross-lingual generative model. The blue ice cubes in the figure represent initialization and freezing with XLM-R, while the red flames represent random initialization or initialization from the first stage.
This article is reprinted from: https://www.msra.cn/zh-cn/news/features/acl-2022
This site is for inclusion only, and the copyright belongs to the original author.