Original link: https://oldj.net/article/2022/06/05/tech-of-this-blog-2022/
Since I built this blog in 2010, I have tossed with its technical solutions many times, especially in recent years, it has basically become an experimental platform for me to learn and practice Web technology, whenever I decide to learn a new I’m testing on this blogging system whenever possible.
Below are some technical details of the current blog.
system structure
At present, the system architecture of this blog is shown in the following figure:
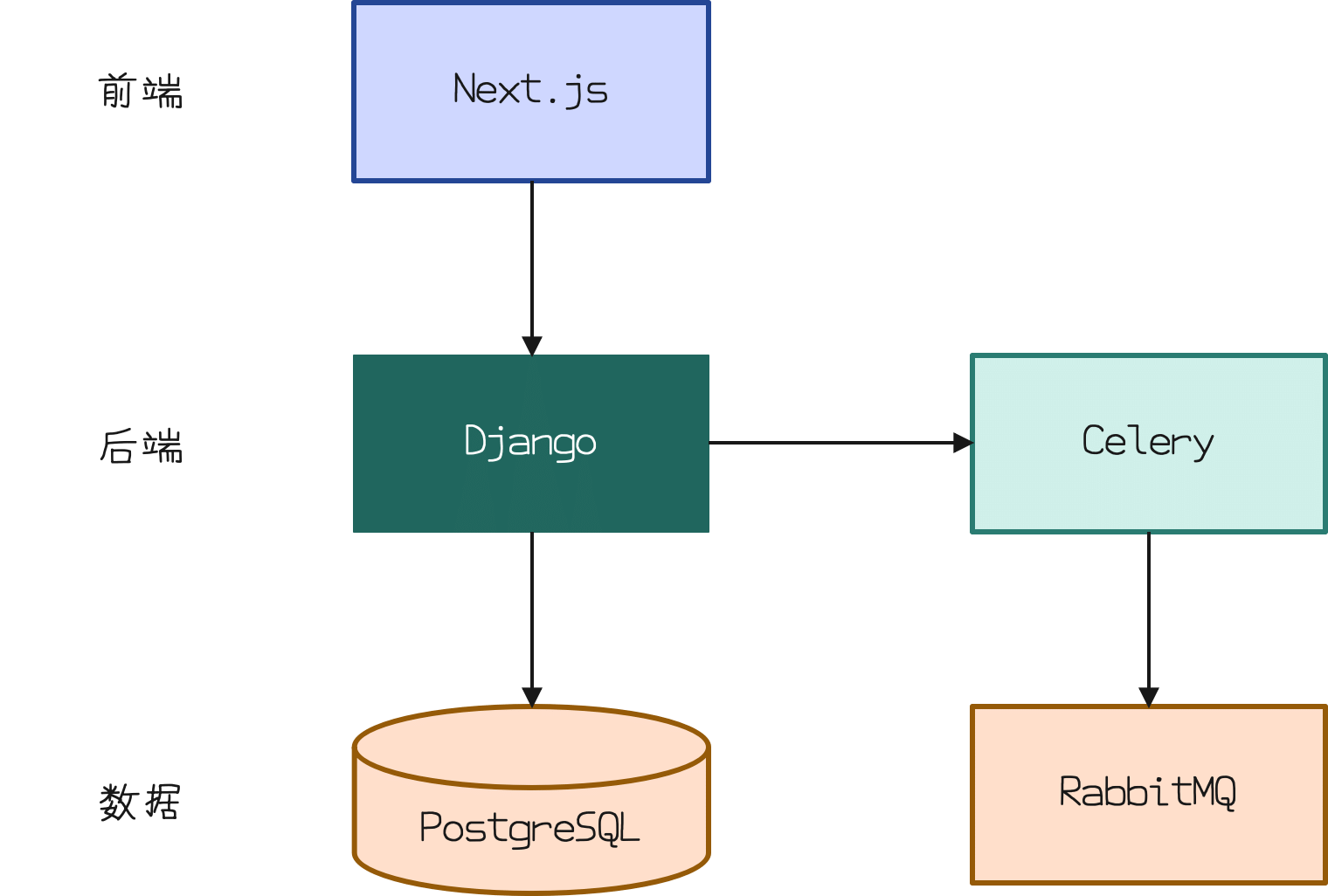
Blog System Architecture
The system is deployed using Docker and runs on K3s.
As you can see, Django is used in the background, and Next.js is used in the foreground to render the page. Currently, I’m mostly using Django as a Headless CMS system, ditching its templating system entirely, and generating all HTML output with Next.js.
Why use Next.js
Why not just use Django to generate HTML content? Mainly with the development of the Web, especially the front-end technology, I found that using React/Vue and other technologies to generate front-end pages is more flexible and easier to maintain. Of course, if you use React/Vue to generate pages directly, it will not be very friendly to search engines. Therefore, technologies such as Next.js that support server-side rendering are natural choices.
After using Next.js, the responsibilities between the front-end and the back-end are more clear, the back-end only needs to provide API, and all page rendering parts are done by the front-end.
Why use Django
There are several reasons to use Django:
- Comes with ORM and database model migration
- Built-in management background
- There are mature task queue tools such as Celery
- Support for custom command line commands
One of them is not uncommon at present. For example, Prisma of Node.js is a powerful ORM framework with data model migration. However, Django still has an advantage here, that is, its ORM and framework integration is very high, and it is smoother to write. Of course, on this point, everyone sees different opinions, and the wise see wisdom. Maybe some people prefer to use a third-party ORM to combine themselves, because then More controllable in details.
Regarding the second point, the self-contained management background, Django’s background is not very good, but it is basically enough. All kinds of operations you want can be realized, but some operations may be more troublesome. Its main disadvantage is that the view is implemented based on the data model (table). If you want to implement some complex views such as cross-table queries, it may be difficult to do so. Of course, if the requirements are not high, then you can use the Django management background, which will save you a lot of development time.
At present, in the field of Node.js, there are also some popular Headless CMS, such as strapi , PayloadCMS , etc. These solutions also provide a management background and look more modern. If you focus on the JavaScript technology stack, you can try these solutions.
Regarding the task queue of point 3, it is mainly to facilitate the execution of some asynchronous tasks. For example, when a user leaves a message for me or submits a new comment, the blog system will send me a notification email. In order not to affect the user experience, I want to do this operation asynchronously to avoid blocking page loading. Having said that, the combination of Celery + RabbitMQ is a popular solution.
Of course, the Node.js framework naturally supports asynchronous tasks, so if you only want to send email notifications and other scenarios, in fact, you can directly use Node.js’s asynchrony without using Celery and other solutions. But consider some complex scenarios, such as an operation is not to send an email to the administrator alone, but to a group of people (for example, when a popular article has a new reply, it needs to be notified by email to everyone who has subscribed or responded to this article users of the article), or to update a large amount of data asynchronously in batches, how to ensure that these operations can be performed correctly, and that it will not suddenly increase the server load too much in a short period of time? This is where message queues like RabbitMQ come in.
Regarding the custom command in point 4, it is mainly necessary to perform some time-consuming operations temporarily or periodically. It is obviously more convenient to perform these operations on the command line. For example, in Django, if you want to temporarily perform some queries or tasks, you can Enter the interactive console with python manage.py shell , or execute custom commands like this:
python manage.py my_custom_command
In this console or command line, you can fully access each model defined in the Django project, and naturally you can also manipulate the corresponding data through these models. For a real site project, it may often need to do some data sorting work, such as clearing some useless old data, performing some data statistics, etc. If you can call custom commands through the command line, executing these tasks will undoubtedly Much more convenient.
summary
The technical solution of this blog has gone through a lot of tossing, and as an experimental field, it is expected that it will experience more tossing in the future. 
Currently it uses a combination of Django (backend) + Next.js (frontend), where Django only provides API, similar to Headless CMS.
Django is an excellent framework that has been in development for 16 years and is very stable and powerful enough for most website building needs.
This article is reprinted from: https://oldj.net/article/2022/06/05/tech-of-this-blog-2022/
This site is for inclusion only, and the copyright belongs to the original author.