Original link: https://shyrz.me/cyberclip-39-10000-hour-rules-fallacy/


Issue 39 of Issue 23 07 29
Hello everyone. Thank you for your support!
The “False Promise of the 10,000-hour Rule” in this issue explains the fallacy of the “10,000-hour rule” that has prevailed for many years, and puts forward the view that comprehensive talents are more competitive in complex fields; recently, seven leading AI Companies have made promises about AI technology at the White House, and the selection “What AI giants are making promises at the White House” details the content of these eight promises and explains what this will mean.
Hope to be enlightened.

Stream Your Ideas to the Top
IdeaChat →
IdeaChat is a conversational app powered by artificial intelligence to help you realize your next big idea.
Sign up for IdeaChat and get 100 free credits for trial. IdeaChat supports WeChat or Alipay payment, which provides a stable way for domestic users to use ChatGPT. If you want to use it for a long time, please consider purchasing the service according to your own situation.
(Click the link above to subscribe or use the promo code SHYRZ when paying to enjoy a 20% discount, and I can get a certain percentage of rebates from it)

The false promise of the 10,000-hour rule
→ Original link : The false promise of the 10,000 hour rule — Anne-Laure Le Cunff / NessLabs / 2023-06-28
Our culture honors experts. Whether they’re athletes, chefs or musicians, some of the most famous celebrities are considered masters of what they do and we admire the lengths they put in to hone their skills. They practice the same skill over and over again, making it feel like an instinct.
In 2008, Malcolm Gladwell published his best-selling book, Outliers , which explored why some seemingly extraordinary people achieve more than others. The book refers to a study of violin students at a German conservatory. The book reads: “Many traits once considered talent-related are actually the result of at least 10 years of intensive practice.” Malcolm calls it the “10,000-hour rule.” Any subject, as long as you practice 10,000 hours, you will master it.
Ripe doesn’t necessarily make perfect
First, the study wasn’t about studying a subject for a specific amount of time, it was about deliberate practice. It is a systematic, purposeful practice to improve performance with a specific goal that requires focused attention rather than mechanical repetition.
What’s more, the study’s lead researcher himself doesn’t seem to agree with the magic 10,000-hour rule.
“He misunderstood that everyone actually spent at least 10,000 hours practicing, so they somehow passed this magic line (…) They were very good, promising students, probably on their own peak in their field, but they still have a long way to go when it comes to research.” – Anders Ericsson, psychologist and researcher, Florida State University ( source )
Finally, and perhaps the biggest problem with the 10,000-hour rule, there is absolutely no evidence in research that anyone can become an expert in any field with 10,000 hours of practice, even deliberate practice. To prove this, the researchers had to take a random sample of people who practiced for 10,000 hours and see if the results were statistically significant.
All studies show that the “best” violinists spend more time in deliberate practice than the “good” violinists. It’s fun, but by no means a guarantee of professionalism.
In fact, a Princeton study showed that practice, on average, only explains 12% of the variance in performance across domains. in particular:
- Sports 18%
- Music 21%
- Games 26%
As Frans Johansson explains in his book The Click Moment , in structurally stable fields such as chess, classical music or tennis, deliberate and repetitive The practice is better because the rules in these fields never change. But when it comes to entrepreneurship and other creative fields, the rules are changing all the time, making deliberate practice less useful.
So, if familiarity does not necessarily make perfect, how do we master new skills?
breadth over depth
The learning strategy used to teach students in traditional schools is to focus on one skill before moving on to the next, which is called blocking . But there’s a better way: interleaving , or practicing multiple skills at the same time.
Studies have shown that randomizing information keeps the brain alert and helps store information in long-term memory. That means the next time you want to learn a new subject, a change might pay off for the better. For example, some coding development mixed with some UX design is better than long coding sessions.
Not only will you learn better and faster, but it may also make you more successful in the long run. In his book, Range , David J. Epstein shows that generalists, rather than specialists, are more likely to succeed in complex fields.
The diagram below is based on an ancient Greek proverb: “The fox knows many things, but the hedgehog knows one important thing.”
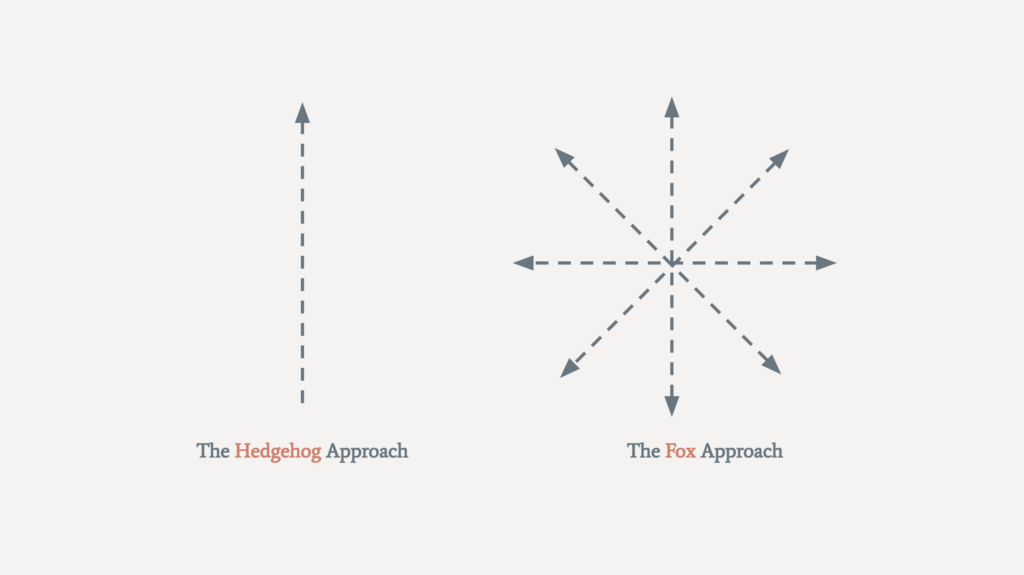
Being too specialized can even be detrimental. In Expert Political Judgment, Philip E. Tetlock shares an experiment in which political and economic experts were asked to make predictions. It turns out that 15 percent of outcomes that experts thought were impossible did happen anyway, while a quarter of outcomes that were almost certain were never predicted.
Interestingly, the more experience and qualifications these experts have, the wilder their predictions become. In contrast, those participants who had broader expertise and were not restricted to a specific area of ”expertise” were more successful in their predictions.
Having the ability to discover new patterns and generate ideas across domains is extremely valuable. Such superpowers rarely come with deep expertise in a unique field at the expense of knowledge in other fields.
So forget about the 10,000-hour rule. Forget about years of thinking stuck in one area of expertise. It might work for a very small number of people, but there’s no evidence that it’s the best strategy. The next time you feel like you want to learn something new that isn’t quite relevant to your current “domain expertise”, do it, it’s that simple.
What AI giants are promising at the White House
7 leading AI companies made 8 promises about how they will use their technology, what did they promise?
→ Original link : How Do the White House’s AI Commitments Stack Up? — Kevin Roose / New York Times / 2023-07-22
This week, the White House stated that it had received “voluntary commitments” from seven leading AI companies to manage the risks posed by AI.
Any agreement between these companies, including Amazon, Anthropic, Google, Inflection, Meta, Microsoft, and OpenAI, would be a step forward. Some of them are competitors, with subtle but important differences in how they approach AI research and development.
Meta, for example, was so eager to get its AI models into the hands of developers that it open-sourced many of its models , making their code publicly available for all to use. Other labs, like Anthropic, have taken a more cautious approach , releasing their technology in a more limited fashion.
But what exactly do these promises mean? Without the backing of legal force, will these commitments have a significant impact on how AI companies operate?
Given the potential stakes in AI regulation, the details matter. So let’s take a closer look at what was agreed here and assess its potential impact.
Commitment 1: Companies commit to conducting internal and external safety testing of AI systems before releasing them
Each of these AI companies has conducted safety tests on its models before they are released—often referred to as “red-teaming.” In a way, this is not a new commitment. It’s a vague promise. It did not detail what kind of testing would be required, or who would do it.
In a statement, the White House said the testing of the AI models “will be conducted in part by independent experts” and will focus on AI risks, “artificial intelligence risks such as biosecurity and cybersecurity, and their broader societal implications.”
It’s a good idea to have AI companies publicly commit to continuing this kind of testing, and to encourage more transparency in the testing process. There are also some types of AI risks—such as the danger that AI could be used to develop biological weapons—that government and military officials may be better placed to assess than companies.
I would like to see the AI industry agree on a standard set of safety tests, such as the Alignment Research Center’s “autonomous replication” tests on pre-release models from OpenAI and Anthropic. I’d also like to see the federal government fund these kinds of tests, since they can be expensive and require engineers with significant technical expertise. Currently, many security tests are funded and overseen by corporations, which raises the question of obvious conflicts of interest.
Commitment 2: Companies commit to sharing information on managing AI risks across industry and with government, civil society and academia
This promise is also somewhat vague. Some of these companies have published information about their AI models in academic papers or corporate blog posts. These include OpenAI and Anthropic, and in a document titled “System Cards,” they also disclose the steps they are taking to make these models more secure.
But they also sometimes withhold information, citing security concerns. When OpenAI released its latest AI model, GPT-4, this year, it broke industry convention by choosing not to disclose how much data it trained on, or how large the model was (a metric known as “parameters”) . The companies said they declined to release the information due to competition and safety concerns. It also happens to be the type of data that tech companies are reluctant to share with competitors.
With these new commitments, will AI companies be forced to disclose this kind of information? What if doing so risks accelerating the AI arms race?
I suspect that the White House’s goal is not to compel companies to disclose their parameter quantities, but to encourage mutual exchange of information about the risks their models pose (or do not pose).
But even this information sharing can be risky. If Google’s AI team prevented a new model from being used to design a deadly biological weapon during pre-release testing, should it share that information outside of Google? Is there a risk that this will give bad actors an idea of how to use a less guarded model to accomplish the same thing?
Commitment 3: Company pledges to invest in cybersecurity and insider threat protection measures to protect proprietary and unpublished model weights
This question is relatively simple and not controversial in my conversations with AI insiders. “Model Weights” is a technical term for the mathematical instructions that give an AI model its ability to function. If you’re a spy for a foreign government (or a rival company) who wants to build your own version of ChatGPT or another AI product, it’s these weights that you want to steal. This is where AI companies have a vested interest in tight control.
The problem of model weight leakage is well known. For example, the weights for Meta’s original LLaMA language model were leaked on 4chan and other sites just days after the model’s public release. Given the risk of more leaks—and the potential interest of other countries in stealing the technology from U.S. companies—requiring AI companies to invest more in their own security seems like an obvious choice.

Listening to Biden’s speech are Amazon’s Adam Selipsky, OpenAI’s Greg Brockman, Meta’s Nick Clegg, Inflection’s Mustafa Suleyman, Anthropic’s Dario Amodei, Google’s Kent Walker and Microsoft’s Brad Smith / Anna Moneymaker / Getty Images
Commitment 4: The company commits to facilitating the discovery and reporting of vulnerabilities in its AI systems by third parties
I’m not quite sure what this means. Every AI company discovers vulnerabilities in a model after it’s released, usually because users try to exploit the model for bad behavior or bypass the model’s defenses in ways the company didn’t expect (a technique known as “jailbreaking”). way of doing).
The White House pledge called on companies to create “robust reporting mechanisms” for the vulnerabilities, but it’s unclear what that means. An in-app feedback button, similar to the ones Facebook and Twitter users use to report offending posts? A bug bounty program, like the one OpenAI launched this year , that rewards users who find bugs in their systems? or some other way? We need to wait for more details.
Commitment 5: The company commits to developing robust technical mechanisms to ensure users are aware that content is generated by AI, such as watermarking systems
It’s an interesting idea, but leaves a lot of room for interpretation. So far, AI companies have struggled to design tools that allow people to tell whether they are viewing AI-generated content. While there are good technical reasons, it becomes a real problem when people are able to pass off AI-generated creations as their own (ask any high school teacher). And many of the tools currently advertised as being able to accurately detect AI output don’t actually have any reliability .
I’m not optimistic that this problem will be fully resolved. But I’m glad there are companies committing to the effort.
Commitment 6: Companies commit to publicly reporting on the capabilities, limitations, and areas of appropriate and inappropriate use of their AI systems
It’s another plausible-sounding promise with a lot of wiggle room. How often does the company need to report on the capabilities and limitations of its systems? How detailed does this information need to be? Given that many companies building AI systems are surprised by their systems’ capabilities after the fact, can they really describe them accurately up front?
Commitment 7: Companies commit to prioritizing research on possible societal risks of AI, including avoiding harmful bias and discrimination and protecting privacy
“Priority research” is a vague promise. Still, I believe this commitment will be welcomed by many in the AI ethics field, who want AI companies to prioritize preventing short-term harms like bias and discrimination, rather than fearing the end of the world, as AI safety folks do.
If you’re confused about the difference between “AI ethics” and “AI safety,” you just need to know that there are two rival factions in the AI research community. Each faction believes the type the other is trying to prevent is wrong.
Commitment 8: The company is committed to developing and deploying advanced AI systems to help address society’s grand challenges
I think few would argue that advanced AI should not be used to solve society’s greatest challenges. I have absolutely no problem with the White House citing cancer prevention and climate change mitigation as two areas they want AI companies to focus their efforts on.
What complicates this goal somewhat, however, is that in AI research, something that initially seems unimportant often has a more important impact. Some of the techniques involved in DeepMind’s AlphaGo project — an AI system trained to play the game of Go — turned out to be useful in predicting the three-dimensional structure of proteins, a seminal discovery that spurred fundamental scientific research .
Overall, the agreements the White House has struck with AI companies appear to be more symbolic than substantive. There are no enforcement mechanisms to ensure companies comply, and many of these promises are precautions that AI companies have already taken.
Still, it’s a reasonable first step. Agreeing to abide by the rules shows that AI companies have learned from the failures of early tech companies that waited until they got in trouble before engaging with governments. In Washington, at least when it comes to tech regulation, early engagement pays off.

 Society : How many people raise the banner of so-called progress and drive backwards for women’s rights
Society : How many people raise the banner of so-called progress and drive backwards for women’s rights  Business : 2003-2023, what waves have Chinese brands experienced? Part 1 | Part 2
Business : 2003-2023, what waves have Chinese brands experienced? Part 1 | Part 2
According to the data from the China Government Network, in 2003, the total retail sales of consumer goods reached 4.5842 billion yuan, the Engel coefficient of urban residents was 37.1%, and the Engel coefficient of rural residents was 45.6%. The Engel coefficient of urban residents and the Engel coefficient of rural residents dropped to 29.5% and 33.0% respectively. As consumption potential continues to be taken over, China’s consumer industry has undergone structural changes many times, and brands have emerged or disappeared accordingly, forming a unique rhythm of Chinese business. Podcast : Traffic Monsters
Podcast : Traffic Monsters
A high school student chose to “die” alone away from the world, but was pushed by the traffic to “rebirth” in full view.- Society : China’s game accompanying industry: fragile interpersonal bonds, emotional needs, a window for loneliness and ambiguity
The dissociation of interpersonal relationships, the interweaving of desire and loneliness  Entertainment : [SPOILER] The explosive “Barbie”: pleases women, but offends men?
Entertainment : [SPOILER] The explosive “Barbie”: pleases women, but offends men?

 If you like CyberClip and want to help me run it better:
If you like CyberClip and want to help me run it better:
- Forward to a friend or social network
- See the Advertise page Contact me to advertise
- Give me appreciation in Aifafa or WeChat, welcome to note title, email
- Click below with
 Marked promotion links, I can receive a meager sponsorship for every valid click of yours
Marked promotion links, I can receive a meager sponsorship for every valid click of yours - In case you have a need, pass the following with
 Marked promotion link registration fee, I will be able to get a certain percentage (marked) rebate from your payment. Please do what you can and consume rationally.
Marked promotion link registration fee, I will be able to get a certain percentage (marked) rebate from your payment. Please do what you can and consume rationally.
 Thank your for your support!
Thank your for your support!


Was this email forwarded by a friend or seen on a social platform? If you think it’s not bad, welcome to subscribe !
If you are interested in advertising on CyberClip, please see our Advertise page and get in touch with me.
CyberClip is a cyber clipping that selects valuable content on the Internet. Every two weeks, it covers new anecdotes, hot issues, cutting-edge technology and other things about life and the future.
 Thank you for reading, welcome to reply, and praise Shi Qi.
Thank you for reading, welcome to reply, and praise Shi Qi.
 Past content | Discussion group | Personal blog
Past content | Discussion group | Personal blog

This article is transferred from: https://shyrz.me/cyberclip-39-10000-hour-rules-fallacy/
This site is only for collection, and the copyright belongs to the original author.