Content source: ChatGPT and large model seminars
Sharing Guest: Dr. Chen Yunwen, Chairman and CEO of Daguan Data
Sharing topic: “Exploring the vertical training technology and application of large language models”
Reprinted from CSDN manuscript
This article is organized from the “ChatGPT and Large-Scale Symposium” on March 11. Dr. Chen Yunwen, chairman and CEO of Daguan Data, shared on “Exploring the Vertical Training Technology and Application of Large Language Models”, and will introduce Daguan Data’s use of large language models. Exploration and thinking in application.
The main content of this sharing is divided into 6 parts, namely:
- Exploration of parameter scale and data scale
- Vertical Domain Adaptation Pre-training
- Fine-tuning Technology Exploration
- Tip Engineering and Vertical Optimization
- Model Training Acceleration Ideas
- Vertical Performance Enhancements for Model Functions
In the process of exploring the application of large language models, the team’s thinking is listed into four points:
- On the whole, although the larger the parameter scale of the model, the better, but a more cost-effective parameter scale scheme can be explored
- Although more training data is better, more efficient and targeted data extraction methods can be explored for vertical scenarios
- In order to strengthen the effect in the vertical direction, some good ideas can be explored in model pre-training and fine-tuning techniques
- For product applications that are more suitable for vertical scenarios, explore model enhancements and product innovations in directions such as prompts

Chen Yunwen, chairman and CEO of Daguan Data, Ph.D. from Fudan University, computer technology expert, member of International Computing Machinery (ACM) and Institute of Electrical and Electronics Engineers (IEEE)
Exploration of parameter scale and data scale
1. Scaling Laws As we all know, the computing power of the large model is amazing. In 2020, from OpenAI’s research on language models, it can be seen that the effect of language models and the amount of parameters, data, and calculations basically follow a smooth power law—Scaling Laws. As the number of parameters (Parameters) of the model, the amount of data involved in training (Tokens) and the amount of calculations accumulated during the training process (FLOPS) increase exponentially, the Loss of the model on the test set decreases linearly, which means that the model The better the effect.
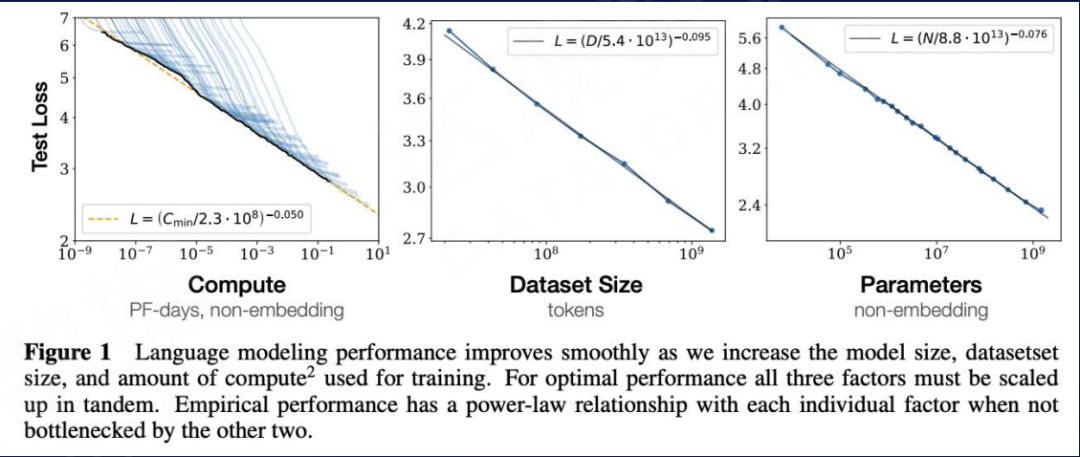 Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv:2001.08361, 2020.
Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv:2001.08361, 2020.
As shown in the figure below, the increase in parameter scale can play a more critical role in the process of increasing the amount of computation. When the amount of calculation is given and the parameter scale is small, the contribution of increasing the amount of model parameters to the model effect is far better than increasing the amount of data and the number of training steps. This also serves as the theoretical basis for the subsequent launch of GPT-3 (175B) and other 100-billion-level models.
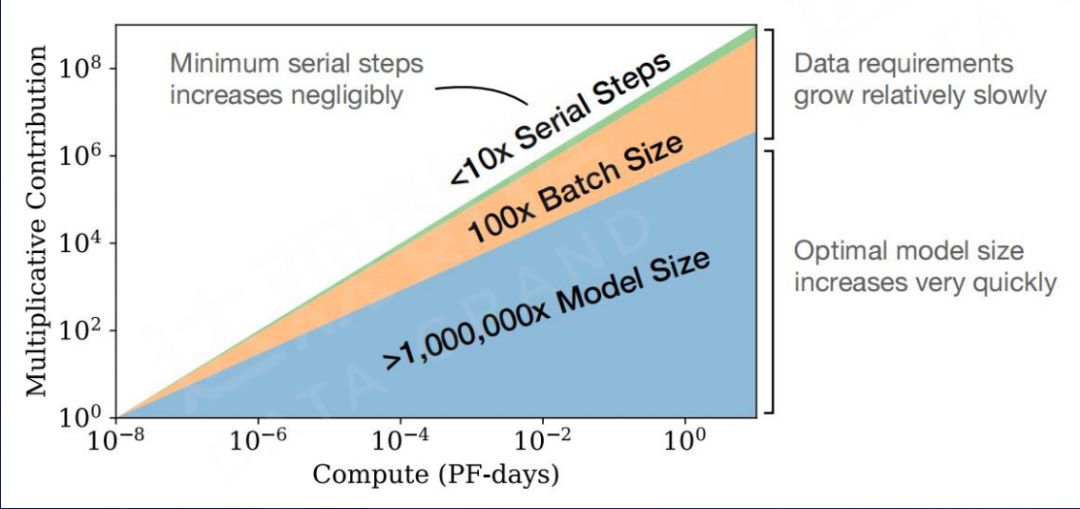
Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv:2001.08361, 2020.
2. Compute-Optimal In 2022, DeepMind made further analysis in ScalingLaw. The research has verified through quantitative experiments that the size of the language model training data should be scaled up in proportion to the size of the model parameters. It can be seen that, under the condition that the total amount of calculation remains unchanged, the effect of model training has an optimal balance point between the amount of parameters and the amount of training data. Good compromise.
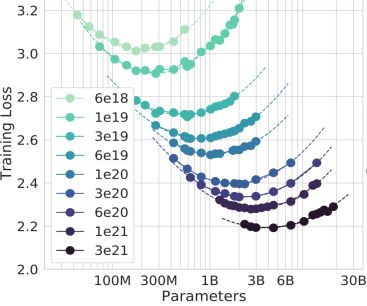
Hoffmann J, Borgeaud S, Mensch A, et al. Training compute-optimal large language models[J]. arXiv preprint arXiv:2203.15556, 2022.
Further research shows that, in such a large-scale parameter as GPT-3(175B), if these three calculation methods are used for fitting, it will be found that GPT-3 has not been fully trained.
Therefore, we need to consider the huge cost of a huge model with hundreds of billions of parameters when it is actually applied in the vertical field, so as to avoid the waste of parameters.
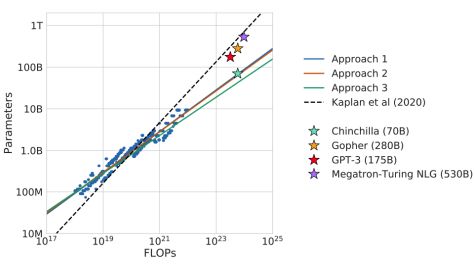
Hoffmann J, Borgeaud S, Mensch A, et al. Training compute-optimal large language models[J]. arXiv preprint arXiv:2203.15556, 2022.
3. Open and Efficient

Touvron H, Lavril T, Izacard G, et al. LLaMA: Open and Efficient Foundation Language Models[J]. arXiv preprint arXiv:2302.13971, 2023.
Inspired by DeepMind’s theory, Meta launched the 10 billion model LLaMA in 2023. After training data of 1.4 trillion Tokens (nearly 4.7 times that of GPT-3), the effect in many downstream experimental tasks is significantly better than that of GPT3’s 100 billion scale. parameter. Therefore, even if your parameter scale may not be that large, you can still see the effect by increasing the amount of training tokens.
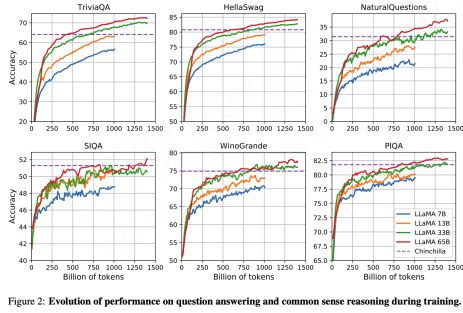
Touvron H, Lavril T, Izacard G, et al. LLaMA: Open and Efficient Foundation Language Models[J]. arXiv preprint arXiv:2302.13971, 2023.
During the training process, whether it is a small model of 65B, 33B, 17B, or even 7B, after the training data is close to more than one trillion Tokens, the effect of downstream tasks is still improving, which means that the potential of these parameters can be trained with more Tokens Inspired further. Therefore, it can be speculated that the potential of the 10 billion model still needs to be further explored, especially in the case of limited computing resources, there is room for optimization with higher cost performance.
4. There is a bottleneck in data scale: open data is about to be exhausted

Villalobos P, Sevilla J, Heim L, et al. Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning[J]. arXiv preprint arXiv:2211.04325, 2022.
When we do model training with a larger parameter scale, the data has gradually begun to show that it is not enough. The above figure is a speculation based on the historical data growth rate and data usage rate. Some studies predict that the data resources available on the Internet are likely to be exhausted.
- According to the current development speed, high-quality language data may be exhausted by 2026;
- Low-quality language data (such as daily chat, etc.) will be exhausted by 2025;
- Multimodal data (such as visual images) will be exhausted by 2060;
5. Research on pre-training datasets for general large-scale models The scale of pre-training data for large-scale language models continues to increase, but even if open data is used, few teams disclose the datasets used and the detailed information they contain. Through the few “Datasheet for Datasets” information provided by the Pile dataset, we can see that high-quality corpus data such as Wiki encyclopedias, books, and academic journals play a key role.
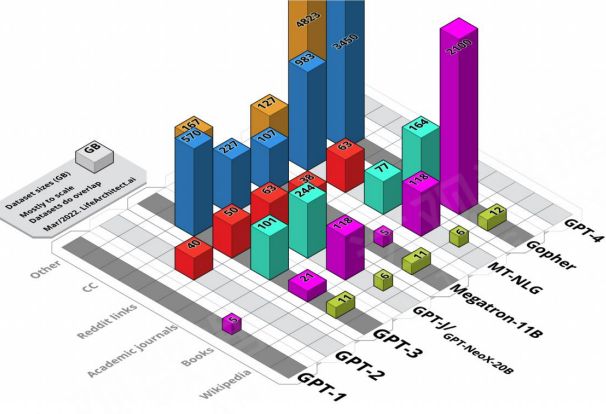
Large model pre-training data visualization
Alan D. Thompson. What’s in my AI? A Comprehensive Analysis of Datasets used to Train GPT-1, GPT-2, GPT-3, GPT-NeoX-20B, Megatron-11B, MT-NLG, and Gopher. https:/ /ift.tt/aOQEhpR.2022
6. Analysis of data diversity in general pre-training 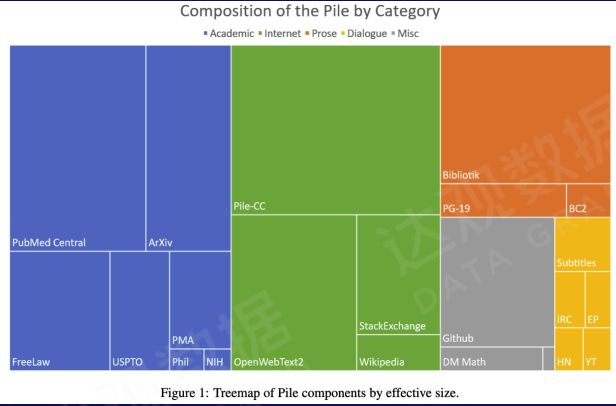
Composition of The Pile v1 dataset (800GB)
Gao L, Biderman S, Black S, et al. The pile: An 800gb dataset of diverse text for language modeling[J]. arXiv preprint arXiv:2101.00027, 2020.
In the general pre-training process, different types of text represent different capabilities. For example, the green text is training general knowledge. Like academic texts (blue), including some publications (orange), etc., one part is to train knowledge in professional fields, and the other part is to train some emotional storytelling and creative literary and artistic creation abilities. The dialogue text (yellow) is small in size, but it is very helpful to improve the dialogue ability. In addition, there are codes and math problems for training COT capabilities. The scale of these data is uneven, but the diversity of data plays a very important role in improving the comprehensive performance of large language models.
7. Multilingualism and ability transfer
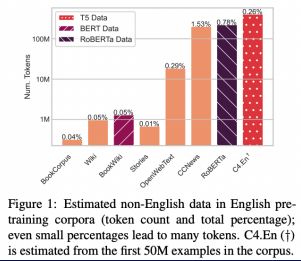
Blevins T, Zettlemoyer L. Language Contamination Helps Explains the Cross-lingual Capabilities of English Pretrained Models[C]//Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022: 3563-3574.
Today we see that multilingual data training and ability transfer are very controversial. Studies have shown that even if less than 0.1% of other languages are mixed in large-scale monolingual (English) pre-training, the model will have significant cross-lingual capabilities. There are some commonalities between languages, and the underlying knowledge and cognitive ability are cross-lingual, so mixed training can play a certain role in strengthening.

The number and proportion of other language tokens in a single language
Blevins T, Zettlemoyer L. Language Contamination Helps Explains the Cross-lingual Capabilities of English Pretrained Models[C]//Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022: 3563-3574.
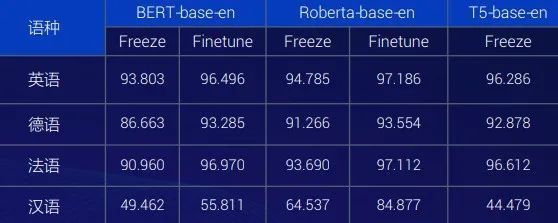
Performance of part-of-speech tagging tasks in other languages under monolingual
Blevins T, Zettlemoyer L. Language Contamination Helps Explains the Cross-lingual Capabilities of English Pretrained Models[C]//Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022: 3563-3574.
The closer the languages are, the more obvious the ability transfer effect is. As shown in the figure above, although the proportion of Chinese corpus is very low, the effect is good. Therefore, in the construction of training corpus and corpus collection, corpus of different languages influence each other.
8. Choose the most suitable training data
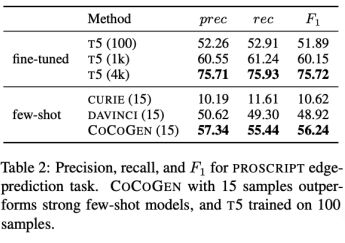
Madaan A, Zhou S, Alon U, et al. Language models of code are few-shot commonsense learners[J]. arXiv preprint arXiv:2210.07128, 2022.
Experiments on complex tasks such as event and graph reasoning show that code training significantly enhances the commonsense reasoning ability of large models, and can achieve significantly better results than the fine-turned T5 model with only a limited amount of code training.
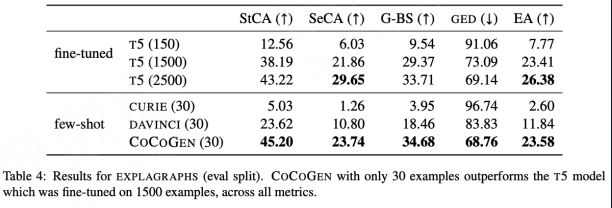
Madaan A, Zhou S, Alon U, et al. Language models of code are few-shot commonsense learners[J]. arXiv preprint arXiv:2210.07128, 2022.
The correct training data has an important effect on improving certain capabilities, and “prescribing the right medicine” is key, and there may be room for optimization in vertical field tasks in the future.
9. Explore pre-trained data filtering and purification methods 
There are two types of model data purification methods that are commonly used now. One is the one above, which uses traditional text classification technology and uses high-quality text as a positive sample set. Some of them include a large number of spam ads on the Internet or low Data such as quality reviews are used as negative samples. After marking, it is sent to the classifier for classification, and then high-quality text is extracted. This is a conventional method, but it relies heavily on text classification, data labeling, etc., which is time-consuming and labor-intensive.

Xie SM, Santurkar S, Ma T, et al. Data Selection for Language Models via Importance Resampling[J]. arXiv preprint arXiv:2302.03169, 2023.
The other is the data purification method based on importance sampling. We artificially select some high-quality data that we recognize in the target sample set, perform a KL reduction on this high-quality data, and perform corresponding distribution calculations. The closer the obtained set of target samples is, the higher the importance is. This method is relatively easier to purify high-quality corpus for model training.
Vertical Domain Adaptation Pre-training
Explore three ideas for pre-training large models in the vertical field:
- First use large-scale general corpus for pre-training, and then use small-scale domain corpus for secondary training
- Direct large-scale domain corpus pre-training
- Simultaneous training with general corpus ratio and mixed domain corpus
1. Exploration route 1: Adaptive pre-training starts with large-scale general corpus pre-training, and then pre-trains with small-scale domain corpus.
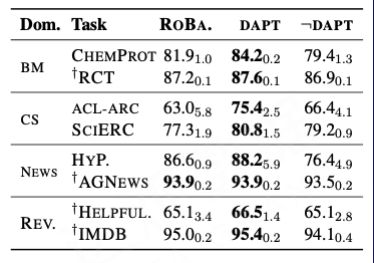
Gururangan S, Marasović A, Swayamdipta S, et al. Don’t stop pretraining: Adapt language models to domains and tasks[J]. arXiv preprint arXiv:2004.10964, 2020.
There are two different processing methods here. One is domain adaptive pre-training, called “DAPT”. After DAPT, the effect of the general model is improved in domain tasks, but the effect of the domain model after DAPT is better than that of the general model in other fields. The model is poor.
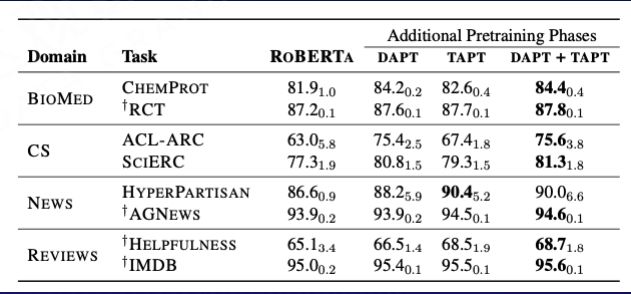
Gururangan S, Marasović A, Swayamdipta S, et al. Don’t stop pretraining: Adapt language models to domains and tasks[J]. arXiv preprint arXiv:2004.10964, 2020.
The other is called task-adaptive pre-training, which is trained on the data set of the task, called “TAPT”.
TAPT is also better than the generic model, with DAPT+TAPT performing best.
2. Pre -finetuning Pre-finetuning technology is also a method that can be tried in route one. In the process of pre-fine-tuning, the losses of different tasks are scaled and then accumulated, and no data sampling is performed on the pre-fine-tuning work, and the effect of maintaining its natural distribution is the best.
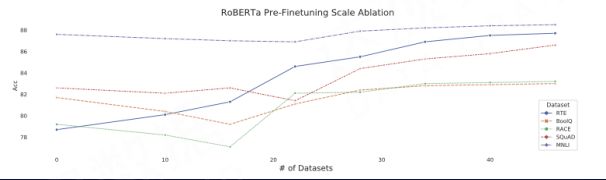
Aghajanyan A, Gupta A, Shrivastava A, et al. Muppet: Massive multi-task representations with pre-finetuning[J]. arXiv preprint arXiv:2101.11038, 2021.
As shown in the figure, the multi-task data set performs Pre-Finetuning on it. The more different task sets, the better the final pre-finetuning model will be.
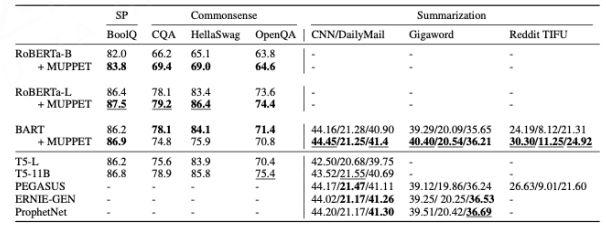
Aghajanyan A, Gupta A, Shrivastava A, et al. Muppet: Massive multi-task representations with pre-finetuning[J]. arXiv preprint arXiv:2101.11038, 2021.
The effect of the pre-fine-tuning model is better than that of the original model, and it has achieved good results on the above several classic large language models.
3. Ability comparison
“Codex comments tend to reproduce similar biases to GPT-3, albeit with less diversity in the outputs.” “When the model is used to produce comments in an out-of-distribution fashion, it tends to act like GPT-3.”
——OpenAI
《Evaluating large language models trained on code》
Chen M, Tworek J, Jun H, et al. Evaluating large language models trained on code[J]. arXiv preprint arXiv:2107.03374, 2021.
OpenAI has a paper that mentioned that small-scale corpus pre-training has no negative impact on the ability to generate general text. When it comes to text generation that has nothing to do with the Code field, there is not much difference between the generation of Codex and the generation of GPT-3, which is reflected in the fact that there are many co-occurring words between the two, and the difference is that GPT-3 expresses more diversity. From this, it is conjectured that the large model after pre-training of the small-scale domain corpus is stronger than the general large model in its own domain, and its performance in general generation is equivalent to that of the general large model. This is something we should explore in the future.
4. Exploration route 2: Effect analysis Directly carry out large-scale domain corpus pre-training work.
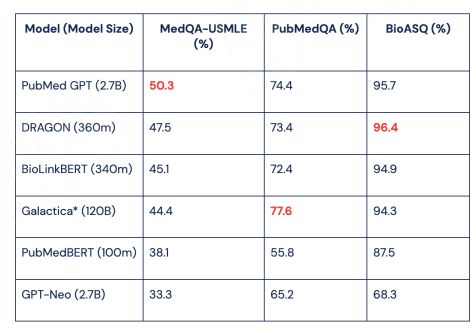
BioMedLM: a Domain-Specific Large Language Model for Biomedical Text (https://ift.tt/xVFcXot)
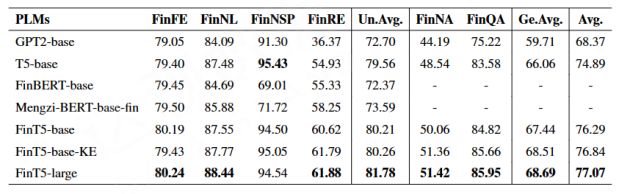
A representative model for the medical domain PubMedGPT 2.7 B. One is the BBT-FinT5 model in the financial field. Their parameter scale is not large, but these special training with data in vertical fields, its effect is significantly improved compared to small models with a smaller parameter scale. In addition, compared with the general and large-scale Finetune of the same scale, the effect of large-scale models in vertical fields is still leading.
Therefore, Route 2 is a very cost-effective solution. The scale of parameters it uses is not large, but the effect in the vertical field is good. At the same time, the large-scale model in the vertical domain uses much less resources than the general-purpose large-scale model, and is close to the effect of the super-large-scale model in the vertical domain. This method also opens up some room for us to experiment.
5. Knowledge enhancement Knowledge enhancement is the enhancement of knowledge in the professional field, which can better explore the route. Second, it can improve its professional model training effect.

Lu D, Liang J, Xu Y, et al. BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark[J]. arXiv preprint arXiv:2302.09432, 2023.
In this knowledge triple (head, relation, tail), a part of the content is made into a mask for pre-training.
Lu D, Liang J, Xu Y, et al. BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark[J]. arXiv preprint arXiv:2302.09432, 2023.
The effect of large domain models with knowledge enhancement technology on domain tasks is better than that of small domain models and general large models. So this may be a middle road worth exploring. It is an intermediate model whose vertical field is slightly smaller than the large model but larger than the small model.
6. Exploration route 3: mix corpus in proportion and pre-train at the same time
Common corpus ratio mixed domain corpus pre-training at the same time. There is currently no research report on this, but we made some guesses:
- Data scale: general corpus + domain corpus > 100 billion tokens
- Data ratio: The proportion of the domain corpus to the total corpus should be significantly higher than the natural proportion of the domain in the general corpus, and the proportion of the domain corpus to the total corpus should be significantly higher than the maximum value of the natural proportion of each domain in the general corpus (significantly higher meaning: likely to be at least 1 order of magnitude higher)
- Model size: > 10B
- Guarantee the heterogeneity of data in the training batch, making the loss drop more stable during the training process
- Knowledge Enhancement Technology
- fine-tuning field increase
Fine-tuning Technology Exploration
1. Incremental fine-tuning We have made some explorations on fine-tuning technology, the goal is to reduce the cost of fine-tuning large models, and at the same time be able to introduce knowledge in some professional fields more efficiently.
Experimental comparison with fine-tuning
Ding N, Qin Y, Yang G, et al. Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models[J]. arXiv preprint arXiv:2203.06904, 2022.
The results show that the gap between delta tunig and fine tuning is not insurmountable, demonstrating the potential of efficient parameter adaptation for large-scale applications. The figure above lists the incremental fine-tuning techniques proposed by different researchers, such as adding a layer of adapter modules between PLM layers, and adjusting PLM by updating pre-inserted parameters, etc. These are local adjustments to the model parameters, and these theoretical knowledge can be added without affecting the large-scale application potential of the entire model.
2. Multitasking tips/command fine-tuning
Muennighoff N, Wang T, Sutawika L, et al. Crosslingual generalization through multitask finetuning[J]. arXiv preprint arXiv:2211.01786, 2022.
The goal of instruction fine-tuning is to improve the zero-shot reasoning ability of language models in multi-task. The fine-tuned language model has strong zero-task generalization ability.

Muennighoff N, Wang T, Sutawika L, et al. Crosslingual generalization through multitask finetuning[J]. arXiv preprint arXiv:2211.01786, 2022.
The picture above is one of the research results. For models such as BLOOMZ, Flan-T5, and mT0, the effect has been improved by using multi-task prompt fine-tuning or instruction fine-tuning technology.
3. Fine-tuning of COT (Chain-of-Thought)
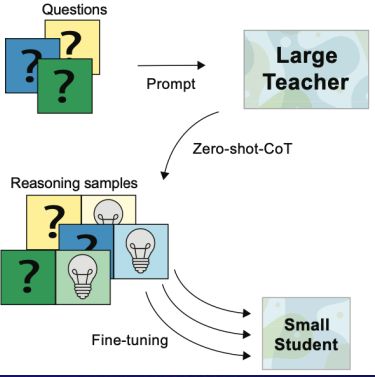
Magister LC, Mallinson J, Adamek J, et al. Teaching small language models to reason[J]. arXiv preprint arXiv:2212.08410, 2022.
Ho N, Schmid L, Yun S Y. Large Language Models Are Reasoning Teachers[J]. arXiv preprint arXiv:2212.10071, 2022.
Fu Y, Peng H, Ou L, et al. Specializing Smaller Language Models towards Multi-Step Reasoning[J]. arXiv preprint arXiv:2301.12726, 2023.
The fine-tuning of COT is also a very good technology. The text (questions + prompt) is input to the large model, and the large model is used to output the correct text containing the chain of thought as the label. Then use the data pair (reasoning samples) composed of the above data to directly fine-tune the small model. Make the small language model acquire the ability of thinking chain.
Prompt Vertical Optimization
1. Prompt Engineering (Prompt Engineering) In the field of large models, Prompt is a new research field. Whether Prompt can be used well will play an important role in making excellent products in the vertical field in the future. We have also done some thinking in this regard, and believe that Prompt Engineering in the vertical field will have many innovative points when it launches products in the vertical field in the future. In terms of innovation engineering in the vertical field, our general idea is to let the model complete the specified tasks in the vertical field, and put forward clear requirements in the prompt, so that the professional tasks in the vertical field can be turned into the expected output of the model.
In this process, productization is very important. Today’s so-called command prompt project is often a large paragraph of text, but it is described in different ways. Therefore, tasks in complex vertical fields in the future may require extremely rich prompt information, including various facts, data, requirements, etc., and there are progressive multi-step tasks, so it is worth exploring a productization solution to generate prompts.
2. Two ideas of prompting engineering Now we are trying two ideas, one is productization. Productization is to invite experts in the vertical field to design products for generating prompts for each vertical task. Experts write a large number of different prompts, and after evaluating or outputting good prompts, segment them into fragments to form corresponding products. , which will play a very good role in future AIGC tasks. The other is the idea of automation, which automatically optimizes Prompt by borrowing external tools, or through automated process methods and training methods.
Automatic Prompt Engineer (APE)
Zhou Y, Muresanu AI, Han Z, et al. Large language models are human-level prompt engineers[J]. arXiv preprint arXiv:2211.01910, 2022.

Directional Stimulus Prompting (DSP)
Li Z, Peng B, He P, et al. Guiding Large Language Models via Directional Stimulus Prompting[J]. arXiv preprint arXiv:2302.11520, 2023.
There are two different technical routes here, one is called APE technology, and the other is called DSP technology. Their basic idea is to add a large language model to the prompt process. In addition, we can train a small LLM, which can effectively prompt Prompt, and can be innovated and applied in many vertical fields in the future.
Model Training Acceleration Ideas
Generally speaking, there are roughly two ideas for model acceleration in our industry, one is distributed parallelism, and the other is video memory optimization.
1. There are four common techniques for distributed parallel work :
1. Data Parallelism (Data Parallelism): store a copy of the neural network on different CPUs, and use a larger batch size to train the model to improve parallelism.
2. Model parallelism (Tensor Parallelism): Solve the problem that the model cannot fit on one GPU.
3. Pipeline Parallelism (Pipeline Parallelism): Efficient use of its resources among multiple GPUs.
4. Hybrid Parallelism: These parallel tasks can better make full use of the parallel computing capabilities of the GPU to increase the speed of model iteration acceleration.
2. Video memory optimization Of course, there are also good video memory optimization solutions, such as mixed precision training, reducing the video memory usage caused by activation in the middle of deep learning training, reducing the resource usage of loading models into video memory, and introducing CPU by removing redundant parameters. And memory, etc., can solve the problem of slow model calculation or large models that cannot run due to insufficient video memory capacity.
Vertical Performance Enhancements for Model Functions
There are many defects in large language models, such as factual errors and key data errors, and complex reasoning tasks in vertical fields. Based on this, we are also trying some different ideas. For example, in terms of reasoning ability, we are also trying to decompose complex tasks into multiple simple tasks and introduce other models to solve them; in terms of tools, there are some ALM outputs. Contains a specific token, activates the call rule; in terms of behavior, uses some tools to affect the virtual and real world.
1. Using CoT to enhance the complex reasoning ability of the model We conduct enhanced training on the original model through CoT, which can effectively improve its Few-Shot or Zero-Shot ability.
The accuracy of the model on the GSM8K dataset can be significantly enhanced by CoT
Mialon G, Dessì R, Lomeli M, et al. Augmented Language Models: a Survey[J]. arXiv preprint arXiv:2302.07842, 2023.
2. Using other models There are many demands for long document generation in the commercial field. For long document generation work, other models and technologies can be introduced and superimposed on the current large language model to improve its long text generation efficiency.
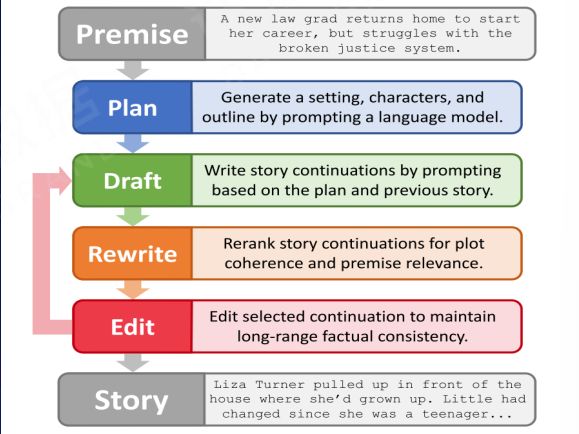
Yang K, Peng N, Tian Y, et al. Re3: Generating longer stories with recursive reprompting and revision[J]. arXiv preprint arXiv:2210.06774, 2022.
From top to bottom, when the computer plans and collaborates to generate content for a long document, we let the corresponding other models do a generation, introduce the classification model, judge the context and relevance of the generated paragraphs, and concatenate the results of other models In the current model, iterative and sequential loop calls can be made, which can break through the shortcomings of the current large language model in extremely long texts and improve its writing efficiency.
3. Use vertical knowledge base 
Izacard G, Lewis P, Lomeli M, et al. Few-shot learning with retrieval augmented language models[J]. arXiv preprint arXiv:2208.03299, 2022.
The above figure is the result of some algorithm research using the corresponding external corpus. It can be seen that if the small model uses the mode of external corpus and special corpus, it can be comparable to the large model in some tasks. Moreover, the application scenarios are extensive, and the interaction between language models and knowledge graphs has also been explored in actual implementation.
4. Use search engines 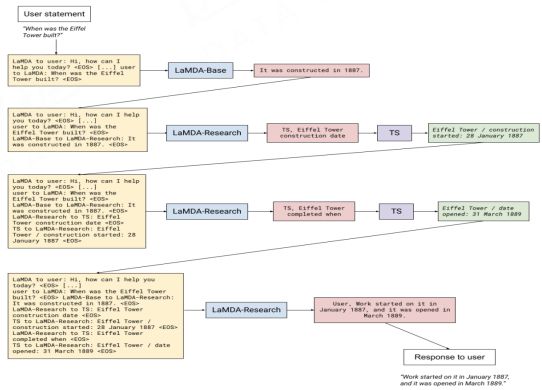
Thoppilan R, De Freitas D, Hall J, et al. Lamda: Language models for dialog applications[J]. arXiv preprint arXiv:2201.08239, 2022.
In the traditional sense, the knowledge of search engines is severely limited by the realization of corpora, so if we use specific token activation or prompts to generate query languages, request search engine results, and integrate them into the training and output of the current model, it is possible It is very good to make up for the many information lags caused by the untimely update of the corpus. In particular, providing factual documents based on search engines and using external search engines to supplement relevant corpus resources can enhance the interpretability of answering questions and align with users’ habits.
5. Content Conversion 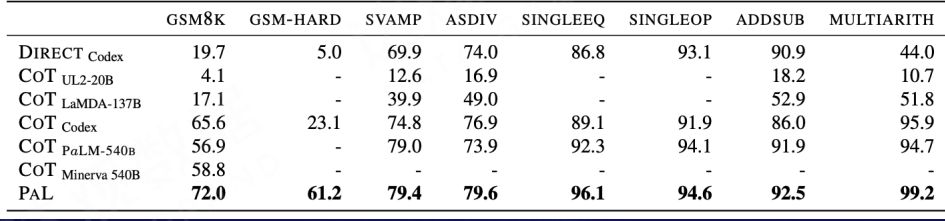
Gao L, Madaan A, Zhou S, et al. PAL: Program-aided Language Models[J]. arXiv preprint arXiv:2211.10435, 2022.
We found that in operations involving the field of mathematics, today’s language models often make mistakes because they do not have a substantial understanding of the meaning behind mathematical operations. Therefore, we can use CoT to decompose a complex problem into several simple problems and generate executable code, and then use the code interpreter to obtain the final result to assist the language model to solve complex reasoning problems.
Summarize
Daguan Data’s exploration of language models in vertical fields hopes to inspire everyone in the development and implementation of LLM. Daguan is currently developing the “Cao Zhi Model”, and hopes to empower every industry in the future. Although the computing power of the large language model is very large, there are still many problems in the model that we need to overcome. We believe that “as long as we find the road, we are not afraid of how long the road is.”
About the Author
Chen Yunwen, chairman and CEO of Daguan Data, Ph.D. in computer science from Fudan University, computer technology expert, 2021 China Youth Entrepreneurship Award, China May 4th Youth Medal, winner of Shanghai Top Ten Youth Science and Technology Outstanding Contribution Award; International Computing Machinery (ACM), Senior member of the Institute of Electrical and Electronics Engineers (IEEE), China Computer Federation (CCF), and China Association for Artificial Intelligence (CAAI); the first batch of winners of senior professional titles in artificial intelligence in Shanghai. He has nearly 100 national technical invention patents in the field of artificial intelligence. He is an off-campus graduate tutor hired by Fudan University, Shanghai University of Finance and Economics, and Shanghai International Studies University. He has published dozens of high-level scientific research papers in top international academic journals and conferences such as IEEE Transactions and SIGKDD. Achievement paper; served as chief data officer of Shanda Literature, senior director of Tencent Literature, and R&D engineer of Baidu’s core technology.
This article is reproduced from: https://www.52nlp.cn/%E8%BE%BE%E8%A7%82%E6%95%B0%E6%8D%AE%E9%99%88%E8%BF%90% E6%96%87%EF%BC%9A%E6%8E%A2%E7%B4%A2%E5%A4%A7%E8%AF%AD%E8%A8%80%E6%A8%A1%E5% 9E%8B%EF%BC%8C%E5%AF%B9%E7%97%87%E4%B8%8B%E8%8D%AF
This site is only for collection, and the copyright belongs to the original author.