The first part of the book is about single-machine data systems, and the second part is about multi-machine data systems.
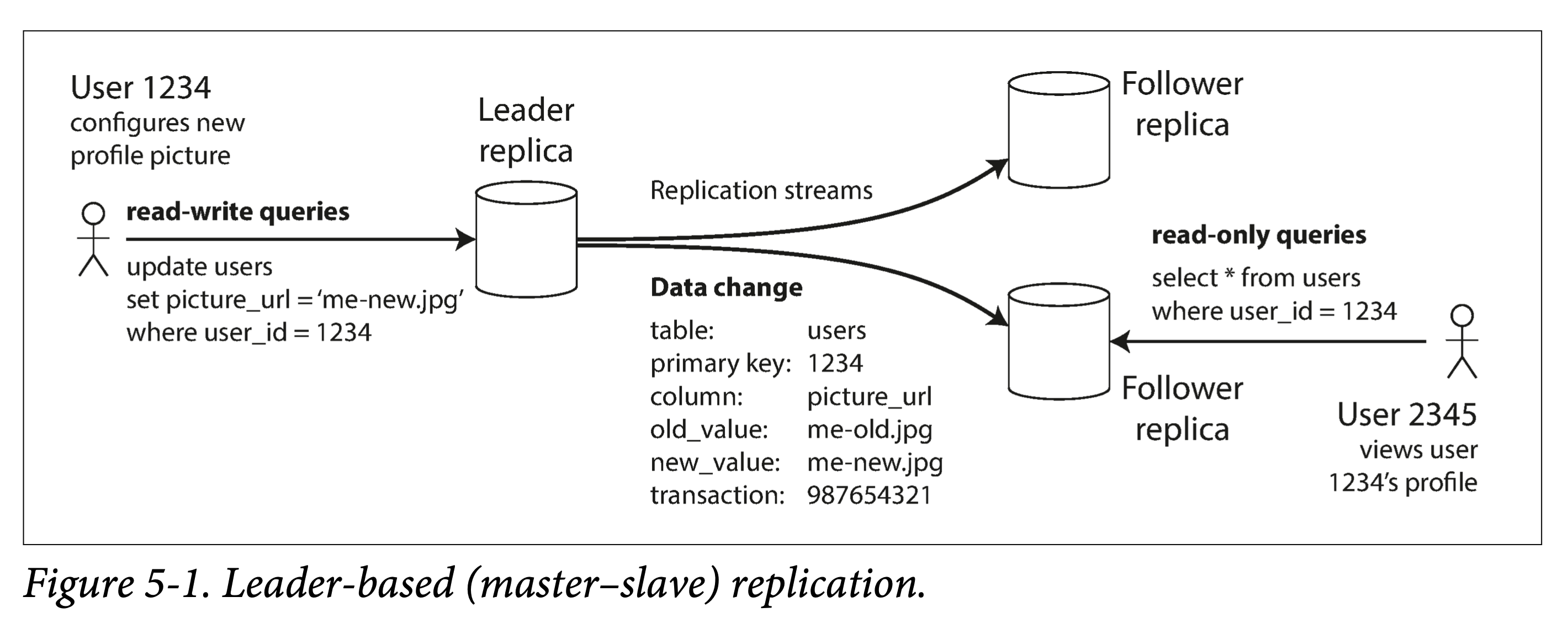
Redundancy (Replication) refers to copying multiple copies of the same data and placing them on multiple machines interconnected through the network. The benefits are:
- Lower Latency : You can be geographically close to users in different regions at the same time.
- Improve availability : When part of the system fails, it can still provide services normally.
- Improve read throughput : Smoothly scale the machines available for queries.
This chapter assumes that all data in our data system can be stored in one machine, so this chapter only needs to consider the issue of multi-machine redundancy. What if the data exceeds the stand-alone scale? That’s what the next chapter deals with.
This article is reprinted from https://www.qtmuniao.com/2022/10/17/ddia-reading-chapter5/
This site is for inclusion only, and the copyright belongs to the original author.