Original link: https://www.kawabangga.com/posts/5289
In the operation and maintenance system, I think that the Alert light is not enough. Every Alert sent needs to be processed and resolved.
The monitoring system we are designing now is as follows:
- Vmalert is a component of alert rule evaluation. Simply put, it continuously queries the data in the TSDB database. If it finds that the conditions of the alert rule are met, it sends a request to the alertmanager;
- Alertmanager will route the Alert to the correct recipient. If the same alert is triggered by multiple instances, it will also aggregate them into one alert and only send one. In addition, there are functions such as Mute, high-level alert suppressing low-level alert, conditions for judging whether the alert is restored, and so on.
- Alert reaction is a system I wrote that complements the missing part of the open source monitoring system: the processing of alerts. This system was shared at a PromCon . All alerts of Alertmanager will be sent to Alert reaction at the same time, this system is a common receiver for Alertmanager. After receiving the alert it will record it in its own database.
The functions that the Alert reaction system can provide include:
- Count all triggered alerts, trigger frequency, emergency events, resolution events, etc. These statistics can help us optimize the conditions for alert triggering and make alerting more efficient;
- Ensure that all alerts are handled by someone, and design a sign-in mechanism, alerts must be ACKed by someone, if there is no ACK, other people will be paged after a while;
- It has the function of collaborative processing and records the processing flow. For example, you can mark alert on the Alert reaction, create work orders, comments, etc. with one click, and update messages will be sent according to the routing strategy of the original alert at all times. For example, if Alertmanager sends an alert to three groups, subsequent updates to this alert will continue to be notified to these three groups;
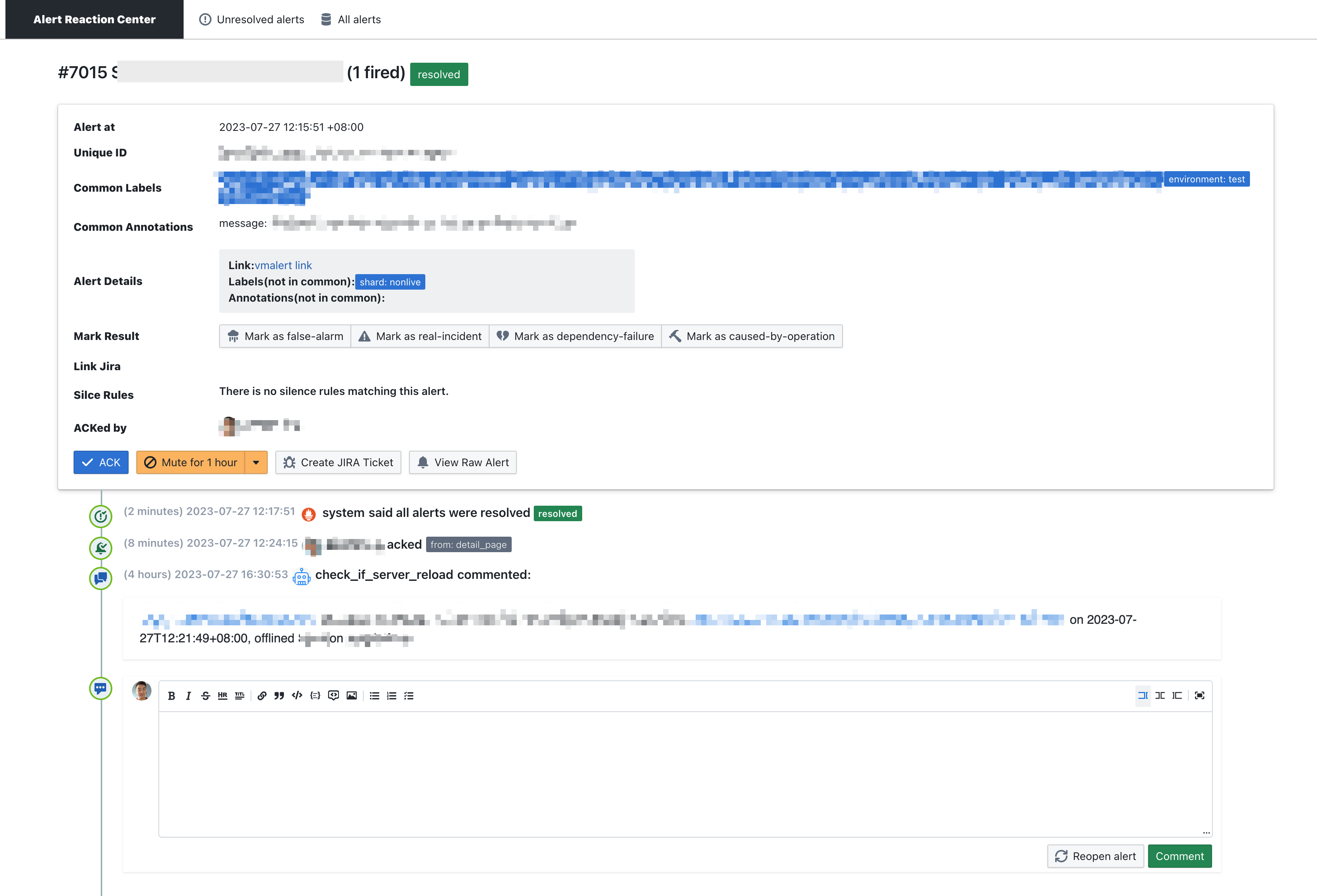 The details page of one of the alerts
The details page of one of the alerts
Recently, I found that this is not enough. Many alerts require manual processing, or require more complex judgment conditions, and such alert rules cannot be expressed only with metrics. For example, when A occurs, it is necessary to check B and C. If there is no problem with B and C, it is considered that there is a problem with A. If there is a problem with one of them, we think it is not A’s problem.
That is, we need to use code to customize the Alert rule, or we need to use code to process the alert that occurs. I recently wrote such a framework.
The principle of the framework is very simple: when the Alert Reaction system receives an alert from the Alertmanager, it puts the alert into a task queue. The queue I choose is rq based on Redis as a broker.
There are essentially two task queues:
- The first one is called polyclinic (this is called a general hospital in Singapore, or a family outpatient clinic. If people need to see a doctor, they first go to consult a general practitioner here), polyclinic will receive all alerts, and then match registered diagnostic procedures (doctor, doctor ), if it matches, a new task queue will be generated and put into the doctor queue
- Doctor queue is the queue that actually executes the diagnostic program. no logic, just run user defined function
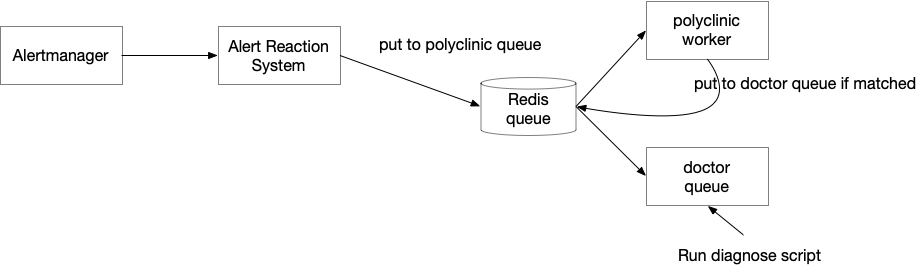 alert processing flow
alert processing flow
For users, if they want to use scripts to handle alerts, they only need to define two things:
- What alerts can my script handle
- How to deal with it (ie code logic)
The goal of my design is to allow users to write less code and go online quickly enough. Because this coding scenario requires constant debugging and optimization to handle various alert scenarios.
I designed a decorator, the user only needs to write a function to use a decorator:
@diagnose({"alertname": "disk_full", job="nginx"}, timeout="30s")
def disk_clean(alert, alert_id):
# do something with other systems
post_comment(alert_id, "I am groot!")
Among them, the first parameter of diagnose decorator is how to match alert, which is the same match logic as PromQL , but only supports equals match, not regular expressions, not, etc., because the input parameter of the user function carries the original text of the alert, so if If you want to do a more complex match, you can implement it in your own code, if you don’t match, just return in the code. post_comment is a function of the SDK included in the framework, which can reply comments to the Alert Reaction system.
This simple implementation poses many problems.
The first problem is how to load the user’s code. According to Python’s import mechanism , if the script file has never been imported, it will not be loaded back into the Python interpreter. One method is to import it all in __init__ , but in this way, every time you add a new diagnostic script, you need to remember to modify import , otherwise, if you forget, it will be more difficult to debug why my script is not running; another The first method is what I am using now. When the worker starts, it scans all the directories of user scripts for import. It also doesn’t feel very elegant and I haven’t found any other good way to do it.
The second issue is how to distinguish between different diagnostic procedures. For example, all kinds of bots comment on the alert, how do you know who sent which comment. In order to reduce the need for users to set a field, the function name is directly used here. The implementation of this decorator is as follows:
def diagnose(match_alert_labels=None, enable=True, timeout="60s"):
"""
Args:
match_alert_labels: dict, {"label": "value"}, currnetly only support
equals match, `{}` will match all alerts.
enable: default to True. this field is used to keep the code but
disable the function.
timeout: int or string, timeout specifies the maximum runtime of the
job before it's interrupted and marked as failed. Its default unit
is seconds and it can be an integer or a string representing an
integer(eg 2, '2'). Furthermore, it can be a string with specify
unit including hour, minute, second (eg '1h', '3m', '5s').
see: https://python-rq.org/docs/jobs/
"""
matchers = match_alert_labels
def real_decorator(func):
def real_func(*args, **kwargs):
threadlocal.current_doctor_name = func.__name__
logger.info("Now doctor %s take a look...", threadlocal.current_doctor_name)
return func(*args, **kwargs)
is_debug = os.getenv("DIAGNOSE_DEBUG") == "1"
# for debugging, there is no job queue, so we need to run the `real_func`
# but for debugging, there is job queue, and worker's function is actually replaced with `real_func`
if is_debug:
doctor = Doctor(matchers, real_func, timeout)
else:
doctor = Doctor(matchers, func, timeout)
if enable:
polyclinic. take_office(doctor)
return real_func
return real_decorator
I choose to store it in threadlocal, and then when it is used, such as in post_comment , just take it out from threadlocal. There are several benefits:
- When the user calls
post_comment, the user does not need to pass any parameters, and the threadlocal is taken out in thepost_commentto know who wants to post a comment; - In a multi-threaded environment, such as multiple workers executing at the same time, each can get the correct name;
From the above code, we can see that there is a debug related logic, which is very interesting and not an easy-to-understand problem. At the beginning, I want to allow users to use this framework to debug easily, providing several functions:
- You can perform diagnostic tests on the constructed alert, generate the alert yourself and store it locally, and then you can test your own program with one command;
- You can directly test the alert on the line, just one command
But there is a problem. From the above architecture description, we can see that this alert needs to be diagnosed, after passing through many systems, and there is also a job queue. Users can skip these steps for local testing and just run the diagnostic program directly.
So why is this code needed?
if is_debug:
doctor = Doctor(matchers, real_func, timeout)
else:
doctor = Doctor(matchers, func, timeout)
The difference here is whether the function we put in the queue is the decorated function real_func or the original func . The debug environment has not passed the job queue, and the production environment has passed the job queue.
If there is a job queue, there is a serialization process in the middle. We put the task into the queue, and actually store this string in Redis. If it is a decorated function, rq will describe the function sequence as follows:
decorator.diagnose.<locals>.real_decorator.<locals>.real_func
When the worker gets it, it is wrong to deserialize it. Because the decorator has finished running when the worker runs, there is no context for the decorator.
If the enqueue is the original function, then the worker takes it out, but actually runs the decorated function, because when the worker runs, the decorator has already run, so the original function is actually the function after the decorator is run. (It’s a bit convoluted, note that when this code is running, it is the initialization phase of the decorator)
When debugging, there is no job queue, so there is no serialization and deserialization. If we enqueue func , then the actual running is func, because there is no worker in this scene, and no one evaluates all the decorators before running. the actual code. If it is func, no threadlocal code is injected, and an error will be reported when threadlocal is obtained later.
Except for this one place, which is relatively convoluted, the others are more intuitive. It is also easier for other people to write, the key is that local testing is very convenient.
Postscript, when I was in Ant Financial, I also participated in a similar project. It is very emotional to recall.
There are many teams involved in this project: the boss envisions that all alerts will be found within 1 minute, automatically located, and automatically restored. Divide into three groups to accomplish this goal. We want to connect with the messages sent by the monitoring system, connect with the business department (our users), the cost of connecting is unimaginably high, the API has no documentation, the data format is messy, and the monitoring data returned by a system called sunfire is a json , the value of one of the fields is string, but it is a string in the form of json. After decoding, there is another field in the form of string in json. I call it json in json in json. If it is not deserialized, you can see They are all \\\\\\"\\\\"\\" and other N-level nested translation symbols, and the meaning is all about guesswork. If our project wants to achieve results, one of the keys is to make it big, so we pulled it Many people participated in our project, forcing users to come to this diagnostic platform (it was called Zhongtai at that time) to write rules. However, the platform design is poor, users will not use it, the trigger chain is very long, and the testing cost is very high. The testing method is in Calling people from other groups on Tintin to trigger it is very inefficient.
For this reason, a retreat project was organized, as well as a swearing-in meeting, which was made into a sports-style project. In fact, the first group assigned thousands of alerts indiscriminately, and sent them all the time when there was nothing to do. Every time a fault occurred, several alerts could always be found. It can be said that our discovery rate is 100%. For positioning, because the alarm configuration is garbage, my work is relatively easy to do, and the performance is not bad. It is more difficult to do self-healing.
A few days ago, my colleagues jokingly called Ant’s project an “annual package” project, meaning that the project basically only lasts for one year. The project I worked on at that time really disappeared after a year.
related articles:
This article is transferred from: https://www.kawabangga.com/posts/5289
This site is only for collection, and the copyright belongs to the original author.