Original link: https://www.msra.cn/zh-cn/news/features/text-based-speech-editing
Editor’s note: Today’s videos published on various social networking platforms are loved by the public for their convenient shooting, real-time sharing, and interactive communication. Video has profoundly influenced and changed the way people observe the world, record their lives and express their emotions. However, many video or audio editing software on the market today have rich functions in order to meet the needs of users, but the operation is very complicated. Many simple editing tasks still need to determine the cutting time point frame by frame in the software. For videos with voice as the main background sound, such as online meeting recordings, presentation videos, vlogs, etc., if we can directly edit the voice content in the audio and video in the form of editing text, the audio and video editing can be automatically completed according to the text, Then it will greatly reduce the difficulty of editing audio and video, and improve the efficiency of creators. To this end, researchers at Microsoft Research Asia have developed a text-based speech editing system. This article will detail the text-based speech editing system and the speech synthesis and filler word detection techniques developed by the researchers.
Whether it is presentation videos, teaching videos, conference recordings or vlogs that record life clips, in many practical application scenarios, people often need to re-record voice (video) or edit voice (video). Because there are often a lot of pauses and blurred, unintelligible words, or redundant content in the filmed material. However, due to the characteristics of the sound, we have no way to modify the words on the basis of the recording, and we can only work on the editing frame by frame, so the editing work of the sound is cumbersome and full of challenges. If you have a text-based voice editing system, you can edit the voice (video) by directly editing the text corresponding to the voice, then ordinary users can also become a creative editor and make a complicated audio and video clear. , Natural and professional.
There are already some similar products or related research work on the market, but they all have some limitations: some research work can synthesize speech that matches the context based on the text, but it must be the timbre learned in the model training process; Synthesize customized sounds, such as the user’s own timbre, but the user needs to prepare at least 10 minutes of sound, upload the sound, and then wait for 2-24 hours. After the sound is trained in the background, the software can synthesize customized sound. sound. These limitations undoubtedly bring great inconvenience to the practical use of text-based speech editing. To this end, researchers at Microsoft Research Asia have developed a text-based speech editing system to solve these technical difficulties.
Technical Difficulties
In voice-based audio and video, the content of the voice and the text have a one-to-one correspondence in time. The researchers found that if the text-based speech editing system can directly edit the text, and then automatically complete the speech editing according to the corresponding relationship between the speech and the text, it is necessary to focus on the following technical points:
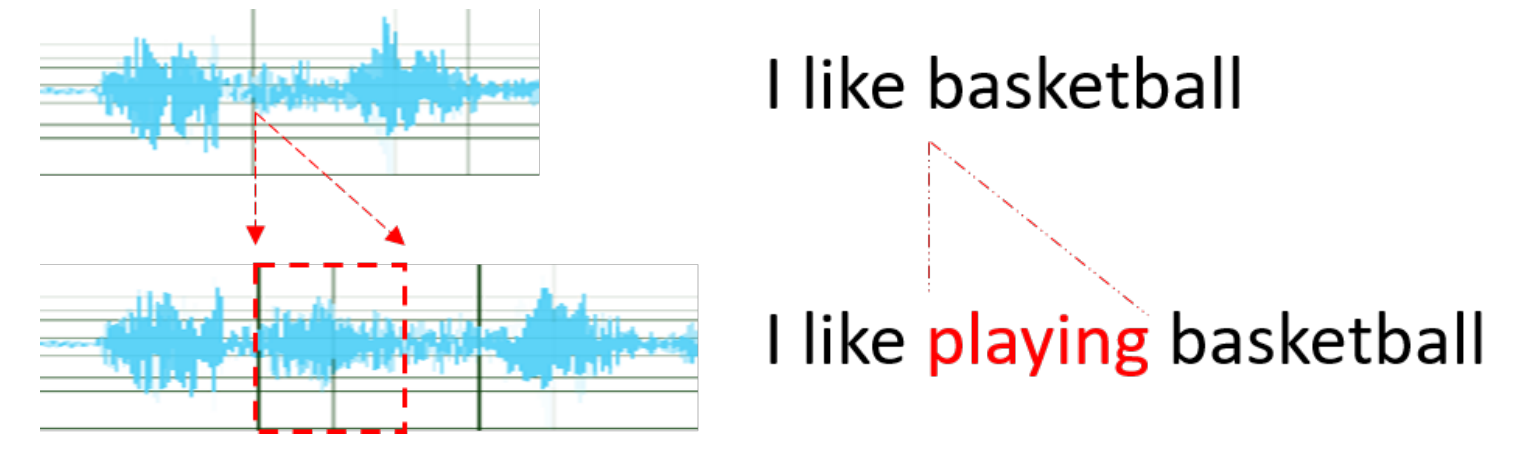
Figure 1: Correspondence between speech and text
1. Automatic speech recognition: If the speech is not read according to the existing script, there is no text information, and ASR (Automatic Speech Recognition) is required to recognize the text. The existing ASR system has been able to accurately recognize the speech, but is limited by the Training data, some ASR systems cannot fully detect filler words in speech.
2. Speech and text alignment: A speech-to-text alignment (forced alignment) module is needed in the research to provide accurate text and speech alignment results, so that the time stamp of the text to be edited in the speech can be pinpointed. This is a very basic but important technical point, and a traditional research problem, generally used for linguistic research or pronunciation assessment or to provide aligned training data for TTS (Speech Synthesis). Existing forced alignment methods can almost meet these needs, but for text-based speech editing, more accurate alignment is required. The existing alignment methods are still not perfect under the error level of tens of milliseconds, and once there is an error of tens of milliseconds, such as cutting the speech more or less by tens of milliseconds, the human hearing will be easy to detect. to and discomfort.
3. Speech synthesis: When inserting or modifying text, a speech synthesis module is required to generate new sounds. The biggest challenge of speech synthesis is naturalness and fluency, which is especially important for text-based speech editing, because if only a part of the speech is modified, the slightest incoherence can be very noticeable. And the researchers expect that when using speech editing technology, they can edit at will without having to prepare enough speech data to fine-tune the model. Therefore a zero-shot context-aware TTS is essential.
4. Filler word detection: The filler word detection module can automatically detect the filler words in the speech, and the user can choose to manually delete some or all of them automatically. As mentioned above, some ASR systems cannot detect all filler words, so there is no way to edit the speech by removing filler words from the text at this time. Whether some words are filler words may depend on the context. For example, “you know” is a commonly used filler word in English, but it is not a filler word in the sentence “Do you know him?” language model to make judgments.
Text-Based Speech Editing System
The researchers first called the ASR service on Microsoft’s cloud computing platform Azure to convert the uploaded speech file into text, and at the same time called the self-developed filler word detection model, and merged the filler word detection results with the ASR recognition results. Then the text can be edited – for the deletion operation, the system will delete the corresponding speech segment according to the alignment result; for the insertion operation, the system will call the speech synthesis model to synthesize the speech to be inserted and insert it into the original speech. Here are a few examples of text-based speech editing done through the above methods:
Modify the text sample
Original text: understand for the question and answer benchmark we’re also the first reach human parity
Revised text: understand for the question and answer benchmark we’re also the second reach human parity
Original voice:
Modified voice:
Insert text sample
Original text: The song of the wretched
Modified text: The famous song of the wretched
Original voice:
Modified voice:
delete text samples
Original text: some have accepted it as a miracle without physical explanation
Revised text: some have accepted it without physical explanation
Original voice:
Modified voice:
Filler detection and removal of examples
Original text: We can edit your speech uh by just editing. You know, its transcript.
Revised text: We can edit your speech by just editing its transcript.
Original voice:
Modified voice:
Key technical point 1 of text-based speech editing system: speech synthesis
A speech synthesis model for speech editing needs to do three things: zero-shot, natural, and smooth. Naturally, it can be refined into two requirements: to generate a timbre similar to the target speaker, and to have a sufficiently high sound quality. After continuous exploration, researchers at Microsoft Research Asia achieved the above goals, developed a zero-sample context-aware TTS model RetrieverTTS, and published the paper “RetrieverTTS: Modeling Decomposed Factors for Text- Based Speech Insertion” (for details of the paper, please see: https://ift.tt/EnXGPZC).
Design ideas
Different from the existing methods that regard the speech insertion task as text-speech modal fusion [3, 5], as shown in Figure 2, researchers first decouple speech into text, prosody (pitch, Volume, duration), timbre, and style, and then perform controllable editing operations on each element, and finally synthesize the four parts into the inserted voice. In a nutshell, “decoupling first, then editing”.
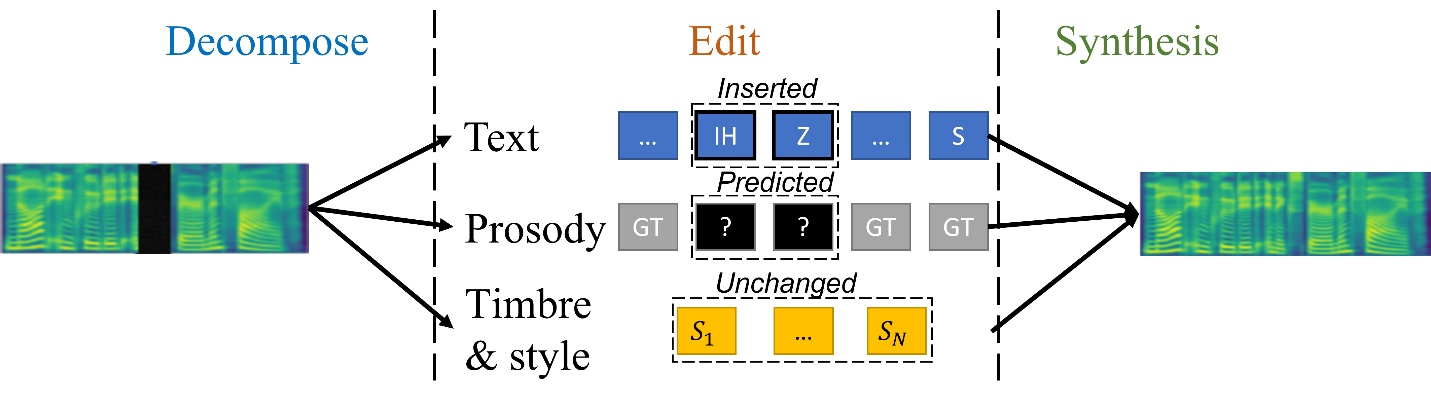
Figure 2: Design Ideas for Speech Synthesis
However, the operations on the four elements are different when performing the insert operation: the text can directly use the text edited by the user; for prosody, the unedited part does not need to be changed, and the part of the inserted word needs to be determined by the model according to the context. Predicted; two elements of timbre and style remain the same since the speaker has not changed. Text and rhythm are different in different moments of a sentence, while timbre and style do not change in a sentence or even several consecutive sentences, so the former is a local element, while the latter is a global element.
Model Architecture
The researchers used Fastpitch[1] as the backbone network for speech synthesis. In order to accurately adapt to the timbre of any speaker in a zero-sample manner, the decoupling between global elements and local elements should be accurate enough, and the representation of global elements should be sufficiently complete and generalized to any speaker. In the paper “Retriever: Learning Content-Style Representation as a Token-Level Bipartite Graph” [2] published at ICLR 2022, the researchers have solved this problem to a large extent, and in the zero-shot speech style transfer task State-of-the-art performance is achieved. Here, the researchers introduced the global feature modeling approach in “Retriever” to the speech insertion task.
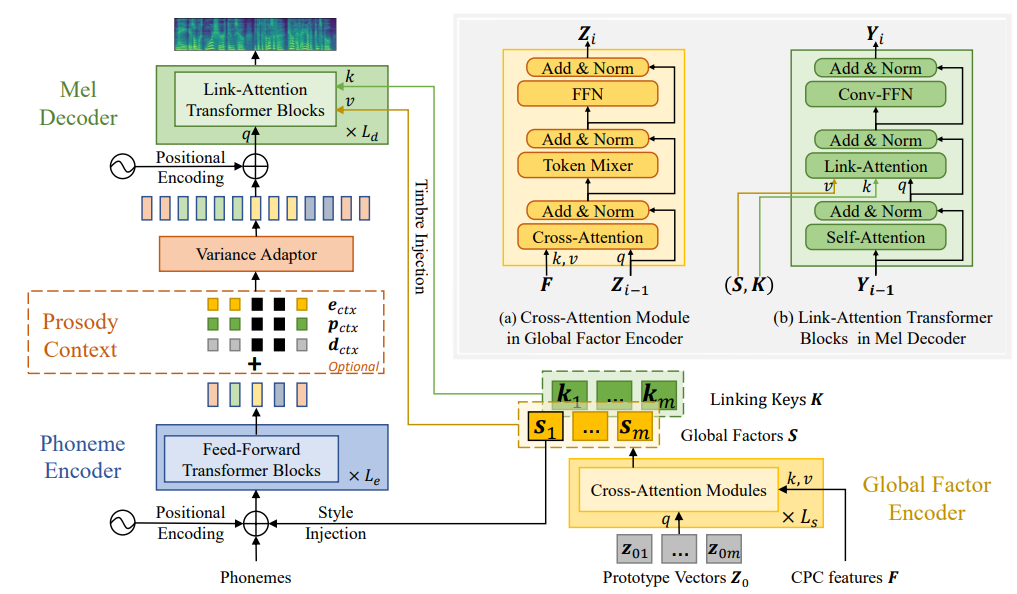
Figure 3: Speech synthesis model architecture
Experimental results
As shown in Table 1, the speech insertion effect of RetrieverTTS is not sensitive to insertion length. For speakers not seen in training, the naturalness of speech remains at a high level even if the inserted speech is longer than two seconds or even generates a full sentence (long insert, full generation). When inserting less than 6 words (short insert, mid insert), it even achieves a naturalness score similar to that of a live recording.

Table 1: Robustness test of speech synthesis to different insertion lengths
In the ablation experiments in Table 2, the researchers removed the adversarial training (- adv), the prosody smoothing task (- prosody-smooth), and Retriever’s global feature modeling method (- retriever), respectively, and found significant performance degradation. . In the test samples of the three experiments, the researchers found the problems of poor sound quality, incoherent rhythm and dissimilar timbre respectively. This verifies that the three aspects of the RetrieverTTS design have achieved the original intention of the design.

Table 2: Speech synthesis ablation experiments
In Table 3, the researchers compared with other methods, and found that the method based on modal fusion [3] performed worse in speech naturalness in the case of inserting longer speech, while other zero-sample speaker adaptive speech synthesis (zero-shot speaker adaptive TTS) [4] has a big gap with the method of RetrieverTTS in terms of timbre similarity. The above comparison shows the superiority of the RetrieverTTS method.

Table 3: Comparison of speech synthesis systems
Key technical point 2 of text-based speech editing system: filler word detection
Many ASR models cannot detect filler words completely due to the limitation of training data, so a separate module is needed to detect filler words. In fact, speech-based filler word detection technology is a special case of speech keyword detection, so researchers regard speech keyword detection as an object detection problem rather than a speech classification problem. Inspired by target detection methods in computer vision [6], researchers proposed a keyword detection method named AF-KWS (anchor free detector for continuous speech keyword spotting).
In the AF-KWS method, the researchers obtained the position of each type of keyword in continuous speech by predicting a keyword heat map, and then used two prediction modules to predict the length of the keyword and correct the keyword position respectively. The position offset of the error. Different from the target detection algorithm in computer vision [6][7][8], researchers introduced a “unknown” category, which represents other words that are not target keywords, this design combines “unknown” with the background in the speech Separating noisy and quiet segments can significantly improve the accuracy of keyword detection. The paper “An Anchor-Free Detector for Continuous Speech Keyword Spotting” of this method has been accepted by InterSpeech 2022 (for more paper details, please check: https://ift.tt/6HhLtXB).
Algorithmic Framework
As shown in Figure 4, for the input speech, the researchers first extracted the STFT spectrogram of the speech, and then used ResNet[9] to further extract features, and then input the features into three prediction modules, which were used to predict the heat map of keywords, The length of the keyword and the keyword position offset. During the training phase, the heatmap is centered on the position of the keyword, and the position of the keyword is expanded using a Gaussian kernel function. In the prediction stage, the researchers take the peak point of the predicted heat map as the predicted keyword position, then extract the predicted results of the keyword length and offset of the corresponding position, and calculate the final keyword position and category.
Figure 4: AF-KWS algorithm framework
Experimental results
The researchers selected two advanced keyword detection models [10][11] for comparison. In the experimental setting of continuous speech keyword detection, the average accuracy of the AF-KWS model far exceeds that of the comparable running speed. other models.

Table 4: Comparison of filler word detection performance
In order to verify that the improvement of the AF-KWS method is not because the backbone is more powerful, the researchers replaced the three prediction modules with one classification module (AF-KWS-cls) and found that the model performance dropped significantly. To verify the effectiveness of the introduced “unknown” category, the researchers removed this category (w/o unknown) and found that the model performance also dropped significantly.
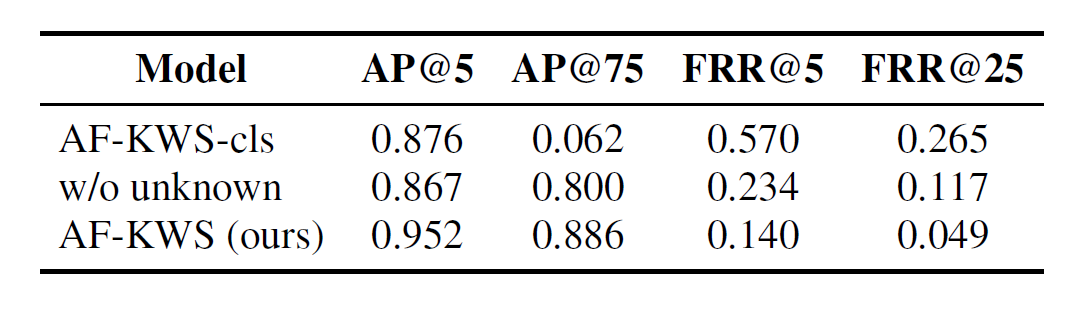
Table 5: Filler word detection ablation experiments
Keyword detection model for filler word detection
Since filler words can also be regarded as a special kind of keywords, researchers made a speech filler word detection dataset based on the SwitchBoard dataset [12], and retrained the keyword detection model on this dataset. On real test data, the AF-KWS method achieves almost the same performance as the best methods on the market. According to the characteristics of filler words, such as filler words generally contain fewer syllables and are more likely to be confused with words of specific categories, researchers will continue to improve the model.
future outlook
Although the existing technology and the speech editing system in this paper have already realized some functions of text-based speech editing, there are still many researches that need to be continuously explored, including: developing rich text formats, decoupling speech, and precisely controlling speech Severity, tone of voice, and mood; develop more accurate speech-to-text alignment algorithms; model background noise or background music in TTS so that synthesized speech contains matching background noise or background music; develop multimodality combining speech and text filler word detection detection algorithms; etc.
references:
[1] A. Lancucki, “Fastpitch: Parallel text-to-speech with pitch prediction,” in ICASSP, 2021.
[2] Y. Dacheng, R. Xuanchi, L. Chong, W. Yuwang, X. Zhiwei, and Z. Wenjun, “Retriever: Learning content-style representation as a token-level bipartite graph,” in ICLR, 2022.
[3] C. Tang, C. Luo, Z. Zhao, D. Yin, Y. Zhao, and W. Zeng, “Zero-shot text-to-speech for text-based insertion in audio narration,” in Interspeech, 2021.
[4] D. Min, DB Lee, E. Yang, and SJ Hwang, “Meta-stylespeech : Multi-speaker adaptive text-to-speech generation,” in ICML, 2021.
[5] Z. Borsos, M. Sharifi, and M. Tagliasacchi, “Speechpainter: Textconditioned speech inpainting,” arXiv preprint arXiv:2202.07273, 2022.
[6] X. Zhou, D. Wang, and P. Kr¨ahenb¨uhl, “Objects as points,” arXiv preprint arXiv:1904.07850, 2019.
[7] C. Zhu, Y. He, and M. Savvides, “Feature selective anchor-free module for single-shot object detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 840–849.
[8] T. Kong, F. Sun, H. Liu, Y. Jiang, L. Li, and J. Shi, “Foveabox: Beyound anchor-based object detection,” IEEE Transactions on Image Processing, vol. 29, pp . 7389–7398, 2020.
[9] B. Xiao, H. Wu, and Y. Wei, “Simple baselines for human pose estimation and tracking,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 466–481.
[10] O. Rybakov, N. Kononenko, N. Subrahmanya, M. Visontai, and S. Laurenzo, “Streaming keyword spotting on mobile devices,” Proc. Interspeech 2020, pp. 2277–2281, 2020.
[11] S. Majumdar and B. Ginsburg, “Matchboxnet: 1d time-channel separable convolutional neural network architecture for speech commands recognition,” Proc. Interspeech 2020, pp. 3356–3360, 2020.
[12] John J Godfrey, Edward C Holliman, and Jane Mc-Daniel, “Switchboard: Telephone speech corpus for research and development,” in Acoustics, Speech, and Signal Processing, 1992. ICASSP-92., 1992 IEEE International Conference on . IEEE, 1992, vol. 1, pp. 517–520.
This article is reprinted from: https://www.msra.cn/zh-cn/news/features/text-based-speech-editing
This site is for inclusion only, and the copyright belongs to the original author.