
At present, artificial intelligence technology is extremely popular in the world, but there is a phenomenon of “big thunder and little rain”. On the one hand, with the continuous development of deep learning technology in recent years, the continuous improvement of computing power, the popularization of deeper and more complex networks, and the end-to-end characteristics of deep learning, it seems that artificial intelligence is the end-to-end annotation, constantly By doing data cleaning, adding labeled data, and deepening model parameters, computers can work like humans. On the other hand, artificial intelligence often fails in practical application scenarios. It is often heard that there are “only artificial intelligence, but no intelligence”, “as many artificial intelligence as there is as much intelligence”. Therefore, the implementation of many artificial intelligence technologies cannot be separated from human experience at this stage.
The implementation of artificial intelligence requires artificial intelligence. The core here is to make a reasonable design based on the characteristics of the scene and the algorithm , rather than focusing on more standardized annotations or designing a more in-depth algorithm network. Daguan is ToB’s natural language processing (NLP) company, which mainly deals with automatic processing of office documents. In recent years, many NLP projects have been successfully implemented in industries such as finance, government affairs, and manufacturing.
NLP is also known as the crown jewel of artificial intelligence. It is not easy to implement AI, especially NLP. Processing office documents through machines is far more complicated than finding pictures with cats from a pile of pictures. Because there is often a lack of a large number of training corpora for machines to process office documents, the specific problems that need to be dealt with vary widely between different industries, and manual workers need professional training or even several years of work experience to handle them properly. This article mainly combines the practical experience of philosophical implementation, and discusses the essential “artificial” required for computer “intelligence” when specific NLP projects are implemented.
“Artificial” simplifies complexity and dismantles complex problems
One of the main reasons why artificial intelligence is difficult to implement is that the problems to be dealt with are too complex . If you only rely on the self-learning of the algorithm model, it will be difficult to learn the corresponding knowledge and make correct decisions. well. But if we can manually disassemble the responsible problem and decompose it into multiple simple problems, then each simple problem may be solved by the model . But how to disassemble? To what extent can the model be disassembled? The philosophical experience is: when faced with an NLP problem, humans can immediately reflect the result after reading it. Such a problem model is what we define as a “simple problem”, which can be solved by machines. The following takes the scenario of contract document extraction as an example to help you understand.
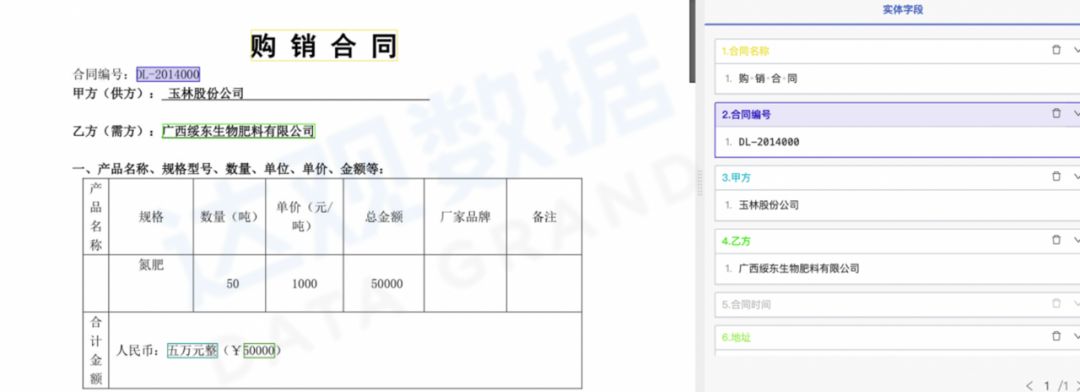
Suppose we need to build a model to extract the field information of Party A, Party B, breach of contract and other fields from the contract in PDF format, and see how the machine disassembles step by step:
First look at the input data of the machine. The PDF format only specifies where each character or line should be on the screen. These elements themselves do not have any semantic information. From the computer’s point of view, this document actually only has simple information such as characters and their positions, and no one looks at the rendering. Alignment, size, importance, and more for a good PDF file. If the text and coordinates are input into the model in an end-to-end manner, and the model learns the document structure by itself, the required fields can theoretically be extracted. At first glance, this approach may sound like a try, but the actual effect is very poor. Because people see a bunch of words and coordinates, and hope to determine the extracted fields, it is very complicated in itself, so we need to disassemble it further.

The document parsing model is responsible for parsing the PDF protocol, and structuring the document through a certain algorithm, that is, converting it into text streams such as chapters, tables, and paragraphs, and then inputting them into the field extraction model. Are these two models simple enough to work?
In most documents, which is a text block, which is a table, and which is a picture, people can instantly judge. And the text block is divided into chapters, titles, paragraphs, especially some document paragraphs do not have obvious spaces at the beginning, that person still needs to read carefully, and sometimes analyze the context to analyze it. So we continue to disassemble document parsing into element recognition model and paragraph recognition model.

For field extraction, some fields are relatively simple, such as Party A and Party B, the results can be seen by the human eye, and it is not a problem to extract these fields directly through the model; some fields are slightly more complicated, such as the total contract amount sometimes in the text , Sometimes it is in the table, and people need to react to get the information when looking at it, so the field can be extracted and then disassembled. A special table extraction model is required in the table. If it is a wireless table, people often need to match the dotted line when looking at it, so the model identified by the wireless table can also be removed. In text extraction, some fields are long texts. For example, in terms of breach of contract, when people are looking for the start and end of the extraction, they often find the beginning and end of the extraction through the context, while the short field is more concerned with the extraction itself and the content of the context. By analyzing the complexity of each step, it can be further disassembled into the following structure.
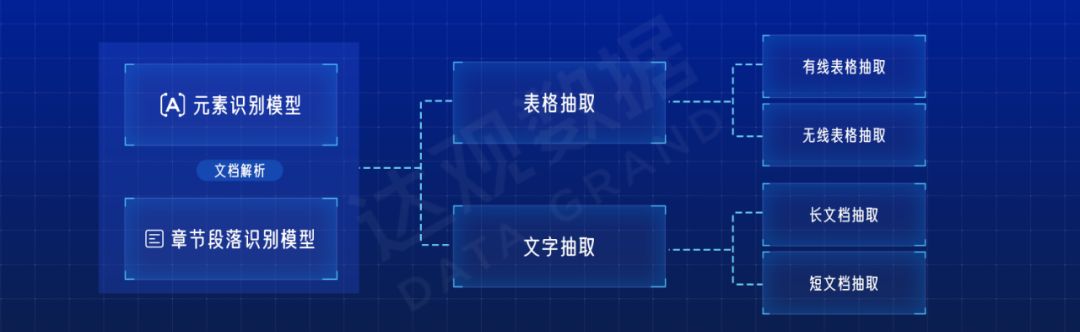
This is a common model for document extraction, but in actual use, it may be dismantled according to the specific data situation and the characteristics of the analysis fields. For example, some fields may be in certain fixed chapters or paragraphs, and there is a lot of interference in training and prediction with global text, then we can add another field chapter prediction model to locate the chapter where the field is located. For another example, the text of the fields extracted from the rental contract is relatively simple selective text, which is also difficult for the model. Often in the text of a sales contract:
If a return is required, use B for a return refund:
- cannot be returned
- Can be returned, 20% compensation will be charged
- Can be returned, charge 50% compensation
Such text needs to be split into two models, one is a model for extracting options, and the other is a model for extracting selection lists.
“Artificial” model selection and optimization
Model selection also requires “manual” experience, which needs to be selected and processed in combination with the scale of labeled data, data characteristics, and model difficulty. For example, in the chapter prediction model mentioned above, if the chapter title features are obvious, it can be classified directly by keywords or machine learning models. Consider a bert-based deep learning algorithm. As far as our philosophical experience is concerned, if different models use the exact same data, the difference in effect after tuning is within 5%. If the scene can better use a pre-trained model, such as bert, the effect can be improved by 10%- 15%.
After the model is selected, some features can be added to further reduce the difficulty of the model and improve the accuracy. In vertical field document processing, business dictionary is a common method. The business dictionary includes proper nouns, as well as the characteristics of important key information of the field. For example, we want to extract the party B of the contract. For company procurement, many of them have a supplier base, or the name of the party B who signed the contract with them before can be obtained. The dictionary of this name may not be complete, so it can’t be matched only by this, but it is very useful to input this “party B proper noun” into the model as a reference feature. The feature of the important key information of the field refers to the very critical context of the extracted field. For example, to extract the field of “Party A”, although there are many kinds of words, such as Party A is xxx, Party A: xxx, Party A is the undertaker of this time, etc., but basically there are several “Party A”. Keywords, so if these proper nouns are also added to the model, the accuracy will often be improved a lot. The following is an example of the use of important words (proper nouns or business words).

Suppose “commissioner” and “committee” are important words. A word vector needs to be generated for each word of “the FCC recently officially approved Apple’s 5G communications trials”. The method here is to encode each word through 2-gram, 3-gram, 4-gram and 5-gram into 8 bits. Each gram has 2 bits to indicate whether the above is an important word and whether the following is not. is an important word. Taking the word “Wei” as an example, the encoding method is:
- 2-gram is “Information Committee” and “Committee”, “Information Committee” is not the core word, and “Commissioner” is the core word, so the code is “01”
- 3-gram is “Communication Committee” and “Committee”, “Communication Committee” is not the core word, and “Committee” is the core word, so the code is “01”
- 4-gram, that is, “State Communications Commission” and “Committee Most” are not core words, so the code is “00”
- 5-gram, that is, “Federal Communications Commission” and “Commission recently” are not core words, so the code is “00”
Other industry knowledge can also generate word vectors in a similar fashion. Splicing all industry vectors with the original word vectors as the input of the model, so that the model can directly obtain industry experience and have better results.
“Artificially” builds a knowledge graph
Some text problems are very business-oriented and difficult to disassemble, or the business logic is too complex, making it difficult for machines to learn the corresponding knowledge. Academician Zhang cymbal, dean of the Institute of Artificial Intelligence of Tsinghua University, mentioned in a speech that “human intelligence cannot be learned through simple big data learning, so what should we do? It’s very simple, add knowledge to make it reason Ability, the ability to make decisions, so that emergencies can be solved.” In practice, Optimistic uses knowledge graphs to solve such complex problems.
The concept of knowledge graph was formally proposed by Google in 2012. It is a semantic network knowledge base that stores, uses, and displays existing knowledge in the form of a structured Multi-Relational Graph. By fusing multiple entity-relationship triples, a multi-relationship graph containing multiple different entity nodes and various types of relationship edges is formed, that is, a knowledge graph. There are also many challenges in the implementation of knowledge graphs. The workload of building and maintaining knowledge graphs is very large, and many projects eventually fail because the construction process is too complicated. The knowledge graph needs to be properly designed and used, as well as “artificial” experience. There are many successful landing cases of Daguan assisting intelligent manufacturing through knowledge graphs. Let’s talk about some of the experience in the following combined with practical application scenarios.
During the manufacturing process, there are many failures, such as the phone overheating and the inability to tighten the screws. Failure to solve them quickly will affect the production process. Before encountering such problems, we can only consult experienced “experts”, but there are always situations where experts cannot be found or experts are not necessarily available. We hope that this problem can be solved through NLP and knowledge graph technology.
Through research on the data inside, Daguan found that to find the answers to these questions often involves a lot of documents, such as product manuals, fault manuals and so on. Some questions are easy to answer, while others may require some complex reasoning to get an answer, or even not necessarily find an answer. Faced with this problem, we design a manufacturing failure map.
In order to solve the problem of the high cost of construction by expert input, on the one hand, the failure map schema we designed is only related to the failure itself, and other knowledge in the generation process is not included in the product scope, thus reducing the workload of generating maps. On the other hand, when we construct the map, we combine artificial intelligence with intelligence . Relevant attribute data is extracted from related documents, such as product manuals, fault maintenance manuals, failure analysis documents, etc., and then entered into the map after manual review. Compared with the pure manual generation of maps, this kind of human-machine combination can greatly reduce the workload. The extraction of map data mainly adopts the methods based on pipeline extraction and joint extraction.
Pipeline extraction is to use NER technology to first extract entities and attributes, and then use classification methods to classify and judge the entities. The advantage of this method is high flexibility, different types of entities can be extracted by different models, and the classification algorithm of relation extraction can also be optimized and adjusted in combination with actual data. The disadvantage is that error propagation may occur, and the relationship behind the entity error is affirmative is wrong, and ignores possible connections within entity attribute extraction and relation extraction.
The method based on joint extraction is to extract entities, attributes and relationships at the same time. For the entity pair extracted from the entity, find the smallest dependency syntax tree that can cover the entity pair in the dependency syntax tree corresponding to the current sentence, and generate the vector representation corresponding to the subtree based on TreeLSTM. TreeLSTM vector for relation classification.
Some knowledge can be extracted from existing documents, but if some documents are missing or very difficult to extract, experts will manually enter it, thus constructing a knowledge graph for failure. With this graph, the knowledge of the computer is formed.
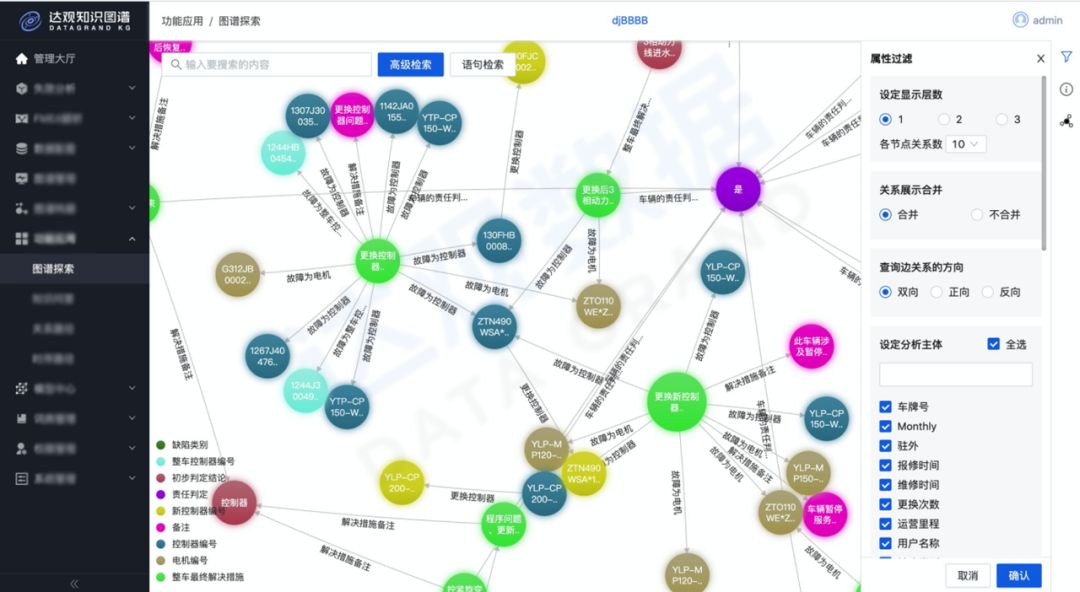
Failure diagram example
Based on the knowledge endowed by the graph, enterprises can use knowledge graph-based question answering (KBQA) to solve the problems actually encountered in production, which we call “attribution analysis”. Graph-based question and answer needs to be able to understand the real intentions of various queries, especially the query may be wrongly typed, and the expression may be irregular, and it needs to be able to correspond to the graph to get the correct answer. It is also necessary to disassemble the problem and decompose it into a model that can be solved one by one.
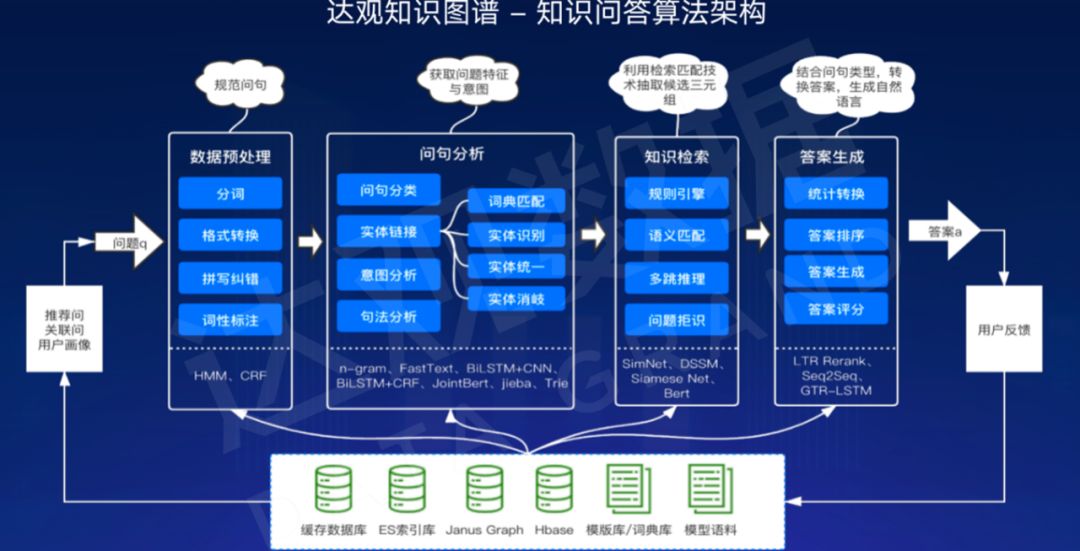
KBQA processing flow
Generally speaking, KBQA is divided into four stages: data preprocessing, question analysis, knowledge retrieval, and answer generation.
- Data preprocessing refers to the basic NLP processing of query, including word segmentation, format conversion, normalization, error correction and other processes. The difference between this and the data preprocessing in traditional search is that error correction can often be combined with various names in the map for error correction, and multiple error correction results can be retained, and then combined with other information in the later process to determine whether Error correction is required, or the result of error correction.
- The core of question analysis is to identify the intent of the query and perform entity linking. Intent recognition refers to what the user’s query is about, such as asking for a solution or a reason. Entity linking is to map certain strings of question text to corresponding entities in the knowledge base. Entity linking is one of the core problems of question answering systems, because if entity linking is wrong, the subsequent results will be very irrelevant. The difficulty here is that the name of the user query is not exactly the same as the name of the entity in the graph. So we will also add fuzzy search and synonyms to solve this problem.
- For knowledge retrieval, it is necessary to select subgraphs related to the query from the graph and sort them. Since the question may require the graph to obtain the answer through multiple hops, there may be multiple entity nodes returned in this step.
- Answer generation, on the one hand, is to find the most suitable one according to the returned results, and generate possible text answers through NLG technology based on the information of the question and the graph.
“Manual” for scene selection and product form design
For artificial intelligence products or solutions, generally everyone is discussing how to improve the technology and how to optimize the effect. For many AI projects that Daguan has implemented in the past few years, scene selection and product form design are actually very critical aspects of implementation. From the perspective of landing, the essential requirement is to hope that the expected work can be completed faster and with high quality, not a model with much accuracy. And the high quality here, the landing requirements in office document processing are often 100% accurate. The current algorithms are basically not 100% accurate, and the algorithm itself does not know what is wrong. This is also the biggest challenge for AI landing. Because when all data needs to be reviewed, the need for “fast” is greatly reduced. How to “quick” review requires a lot of work on scene selection and product form.
01Comparison data
Using third-party data or rules for verification, you can quickly find AI mistakes. For example, in the scenario of document comparison between an electronic contract and a picture contract, the OCR error can be quickly found by comparing the OCR error, and the manual can quickly check it.

Document comparison product kh
02Business relationship
Some of the elements identified in the document have business relationships, and whether the identification is correct can be verified through the relationship of the fields. For example, the value of the sum in the figure below should be the result of the calculation of the values in the above list. If the formula for the sum of the identified results is incorrect, it is likely that there is a problem with the identification of which element in the middle. If the formula for the sum of the identified results is correct, the basic identification itself is also correct.
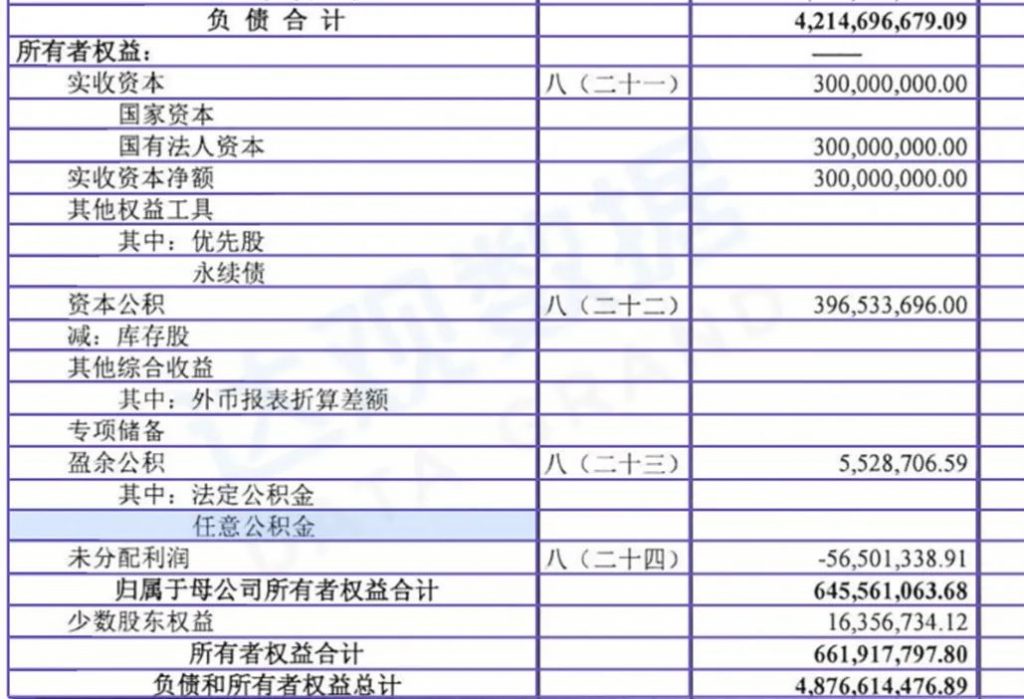
Linkages in Financial Documents
03Efficient audit
The product interaction in the manual review process is very important, and it is necessary to conduct a reasonable interaction design for the more time-consuming links combined with the review process of specific business scenarios. The review process mainly consists of two actions: “find” and “revise”. By highlighting the extraction results, clicking on the field to jump and other functions, Optimistic helps the reviewers to quickly “find” the extraction results and context, through functions such as selection and shortcut keys. Speed up time for manual “revisions”.
Manual review of product interactions
The implementation of artificial intelligence is a very challenging task. It not only needs to overcome technical difficulties and continuously improve the accuracy of the algorithm, but also needs to understand the business and the scene, so as to choose the appropriate scene, build a reasonable algorithm process, design convenient product interaction, The value of these “artificial” is exerted, and the improvement of computing power and models can be promoted in the way of human-machine collaboration, so as to truly realize “artificial intelligence”.
This article is transferred from: https://www.52nlp.cn/%E6%8E%A2%E7%B4%A2%E4%BA%BA%E6%9C%BA%E6%B7%B1%E5%BA%A6% E8%9E%8D%E5%90%88%E7%9A%84%E9%AB%98%E5%8F%AF%E7%94%A8%E6%80%A7%E4%BA%BA%E5% B7%A5%E6%99%BA%E8%83%BD%E5%BA%94%E7%94%A8
This site is for inclusion only, and the copyright belongs to the original author.