Original link: https://controlnet.space/2023/06/08/reading/representation-learning/
Representation Learning (Representation Learning) is a concept in deep learning. By pre-training a feature extractor, the original data is converted into meaningful low-dimensional features, and downstream tasks are trained based on these features, thereby reducing the need for data and computing. capacity needs. This article will introduce the basic concepts of representation learning, as well as the latest developments based on Masked Autoencoder [1] .
The democratization problem of deep learning
In the past few years, deep learning has achieved remarkable achievements in various fields. However, the success of deep learning relies heavily on a large amount of labeled data, which is often expensive to acquire. For example, for the field of computer vision, the labeling cost of the ImageNet dataset [2] is as high as $2 million. Therefore, how to use a small amount of labeled data to train a high-performance model is a very meaningful research direction. When evaluating whether a deep learning model is easy to use, two aspects are generally compared. One is performance, such as the accuracy of classification tasks, PSNR in generation tasks, SSIM, etc. Another aspect is the efficiency of operation, including the time of training and prediction, and the size of the model.
However, taking GPT-3 as an example, its parameters are as high as 175 billion, and the training time is as long as 355 GPU years (V100). The data set contains 499 billion tokens, and it cost almost 4.6 million US dollars [3] . For most people in academia and start-ups, such a model can only be accessed through API at most, and it is impossible to use it through training and fine-tuning by yourself. This is the democratization of deep learning. Only a few people can enjoy the benefits of deep learning. Therefore, how to reduce the model size and training time while ensuring performance is a very meaningful research direction.
feature extraction
Intuitively, the dimensionality of data can be reduced by extracting meaningful features, making model training easier, including reducing the demand for data and reducing the size of the model. Here are a few common feature extraction methods in different modalities.
vision
- Pretrained model on ImageNet [2] , extracting the output of the penultimate layer as features
- Load the pre-trained model through the
torchvisionlibrary -
model_ft = models.resnet18(pretrained=True)
- Load the pre-trained model through the
- OpenFace [4]
- An open source toolkit for face analysis based on deep learning
- Extract facial features using pretrained models
- Optical Flow

Fig. 1. Optical flow. Adapted from [7]
audio
- Mel Spectrogram
- Represents the energy distribution of an audio signal at different frequencies
- Calculate the result by Fourier transforming the audio signal, then filtering the spectrum, and finally performing the inverse Fourier transform
- Convert the original 1D audio signal into a 2D mel spectrogram
- Mel Frequency Cepstral Coefficients (MFCC)
- Features extracted from mel-spectrogram
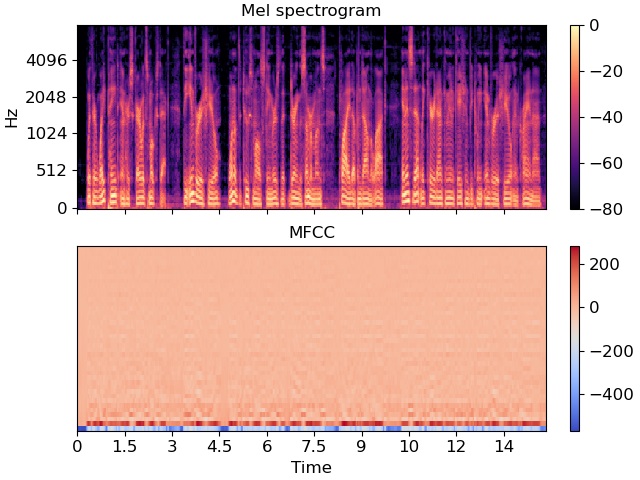
Fig. 2. Mel spectrogram and MFCC. Adapted from [8]
- DeepSpeech [9]
- A deep learning pre-trained model for speech recognition that can extract audio features
text
- TF-IDF
- Compute text features by counting the frequency of words in a document
- Word2Vec [10]
- Convert words into low-dimensional vectors by pre-training a neural network
- as the picture shows.
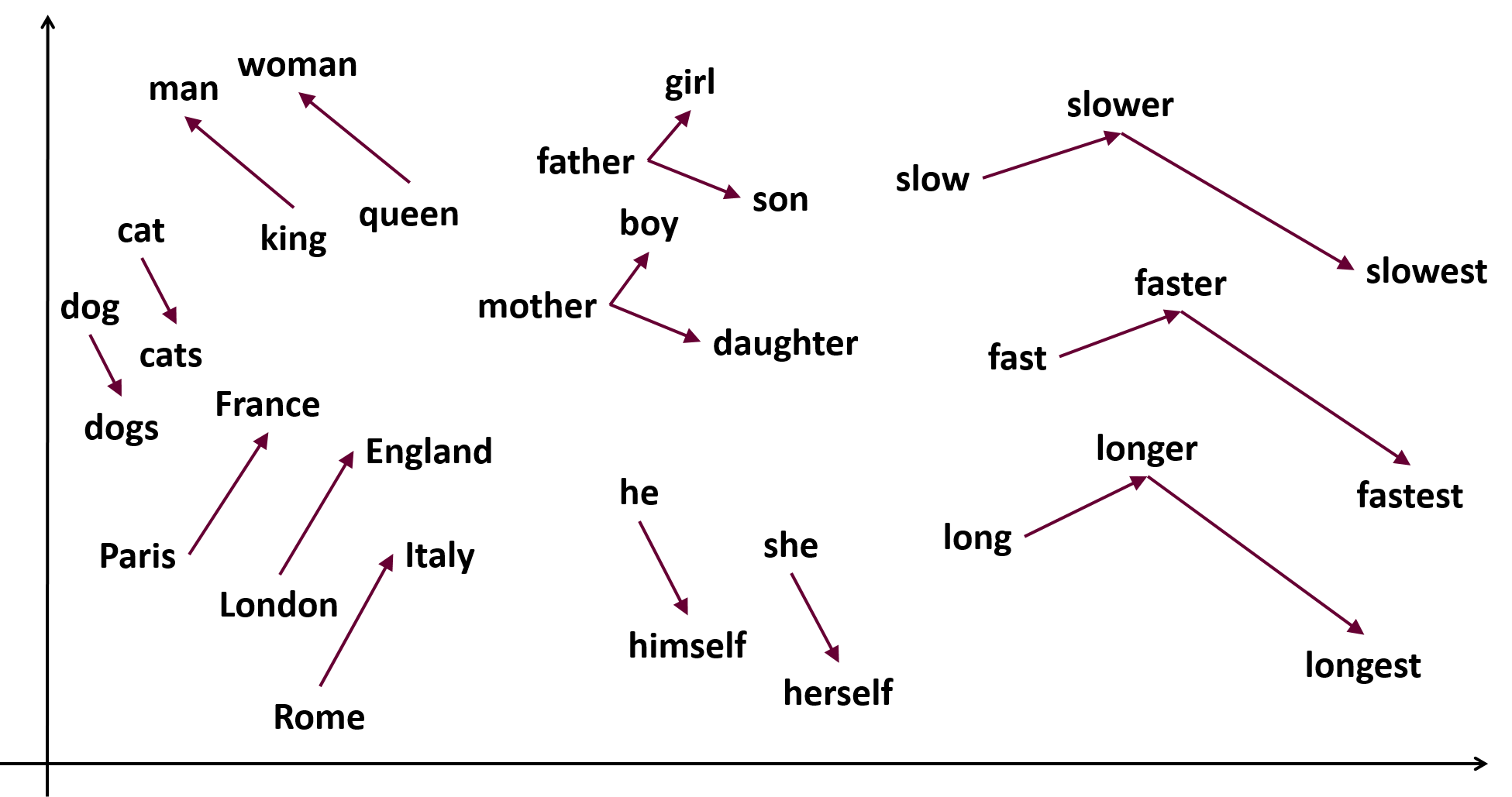
Fig. 3. Word2Vec. Adapted from [10]
representation learning
If all the feature types just mentioned are divided into categories, they can be roughly divided into two categories.
- One is the features extracted by pre-training models, such as pre-training models on ImageNet, OpenFace, DeepSpeech, BERT, etc.
- The other type is features extracted by traditional methods, such as optical flow, Mel Spectrogram, TF-IDF, etc.
AI godfather Yosha Bengio mentioned at the first ICLR meeting
Learning representations of the data that make it easier to extract useful information when building classifiers or other predictors. [13]
Then the meaning of representation learning is to make it easier to extract useful information when building classifiers or other predictors by learning the representation of data. In other words, it is necessary to find a way to get a better feature extractor.
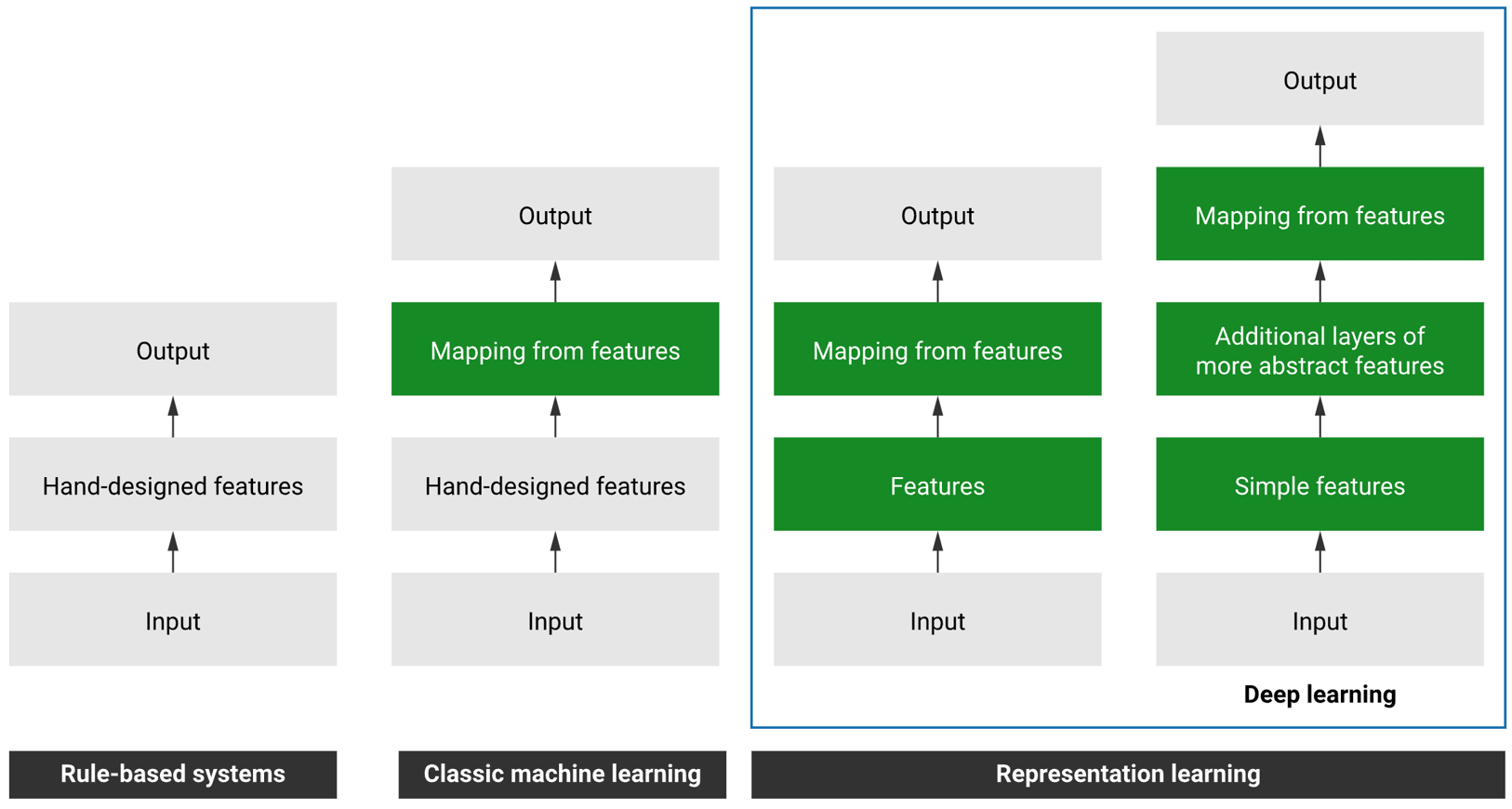
Fig. 4. Development of intelligent systems
As shown in the figure above, the development of intelligent systems has gone through four stages.
- The first is a rule-based system.
- Developers manually write code to implement system functions, such as classification or prediction.
- The second is traditional machine learning.
- Developers need to manually extract features, and then train traditional machine learning models based on these features, from feature mapping to labels.
- The third and fourth are representational learning.
- By training the model, developers let the middle part of the model learn the representation of the data, and then make predictions based on these representations.
- The latest fourth one allows the model to learn a higher-level representation by deepening the number of model layers, thereby improving the performance of the model.
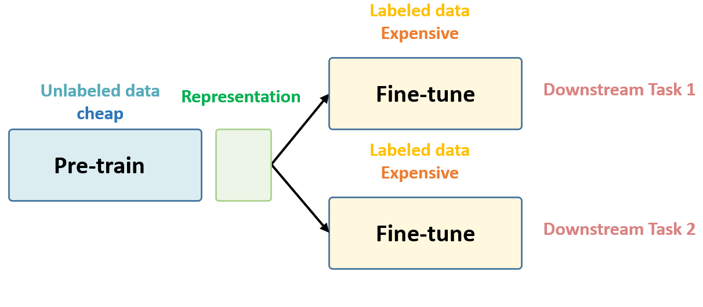
Fig. 5. Architecture for representation learning
Because labeled data sets are expensive and difficult to obtain, when we train models, we generally do not use labeled data sets directly from scratch. Instead, we first train the model parameters from scratch using an unlabeled dataset to a reasonable level. This part, we call pretraining (pretraining).
In the pre-training phase, model parameters are trained from scratch using an unlabeled dataset to a reasonable level. Once the parameters are trained to a suitable level, we can use the labeled dataset to fine-tune the model for a specific downstream task. At this stage, we don’t need a lot of labeled data, because the parameters have been trained to a good level in the first stage.
The first stage does not involve any specific task, just pre-training with a bunch of unlabeled data. We call it “in a task-agnostic way”. The second stage is to fine-tune the model using task-relevant labeled data. We call it “in a task-specific way”.
Masked Autoencoder
After understanding the concept of representation learning, here is a popular cutting-edge model in the field, Masked Autoencoder (MAE) [1] .
introduce
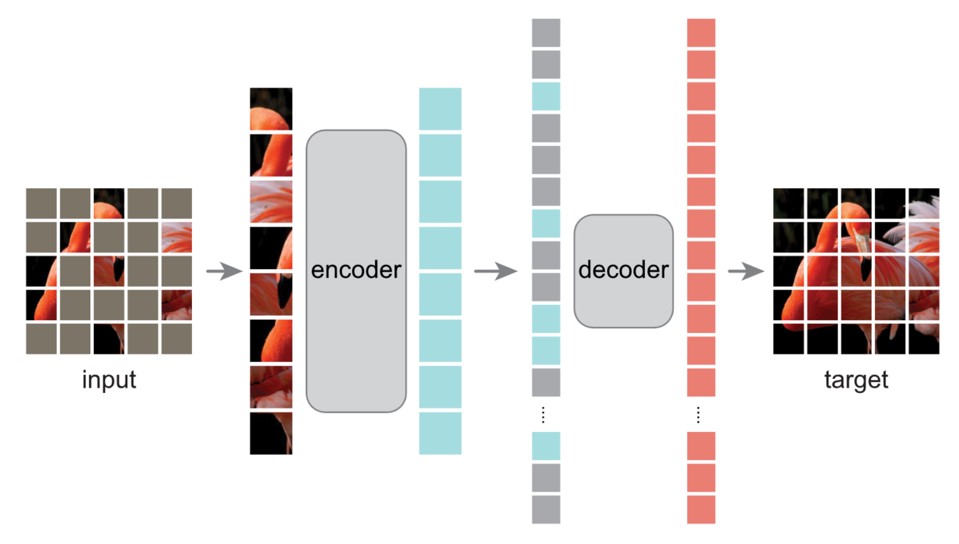
Fig. 6. Introduction of Masked Autoencoder. Adapted from [1]
As shown in the figure, the main concept of MAE is to mask random blocks of the input image and reconstruct them. It is based on two ideas.
First, the researchers propose an encoder-decoder architecture in which an encoder operates on only a subset of visible blocks of an image. A simple decoder can then reconstruct the original image from the latent representation of the visible parts.
Second, the researchers found that if they masked out a large portion of the input image, say about 75%, it could actually yield important and meaningful self-supervised tasks. By combining these two designs, we can efficiently train large models, speeding up training by a factor of 3 or more while improving accuracy.
Some model structural details:
- Use ViT as the encoder, tokenize the input image and process it into token
- The structure of the encoder is larger than that of the decoder
- Reconstruction loss is computed across hidden tokens instead of across all tokens
Experimental results
The experimental results on ImageNet are shown in the figure below:
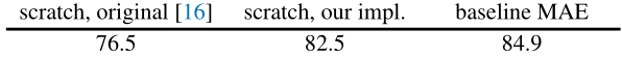
Fig. 7. Experimental results of MAE on ImageNet. Adapted from [1]
Here “scratch, original” represents the results obtained from the original ViT paper [14] .
“scratch, our impl” refers to the same ViT structure, but with the author’s own parameters. Mainly because of higher weight decay.
“Baseline MAE” refers to the result of fine-tuning starting from the pre-trained MAE model.
It can be seen here that compared with training from scratch, using MAE for pre-training can improve the accuracy by about 2%.
In order to better choose the ratio of coverage, the author conducted some experiments, as shown in the following figure: 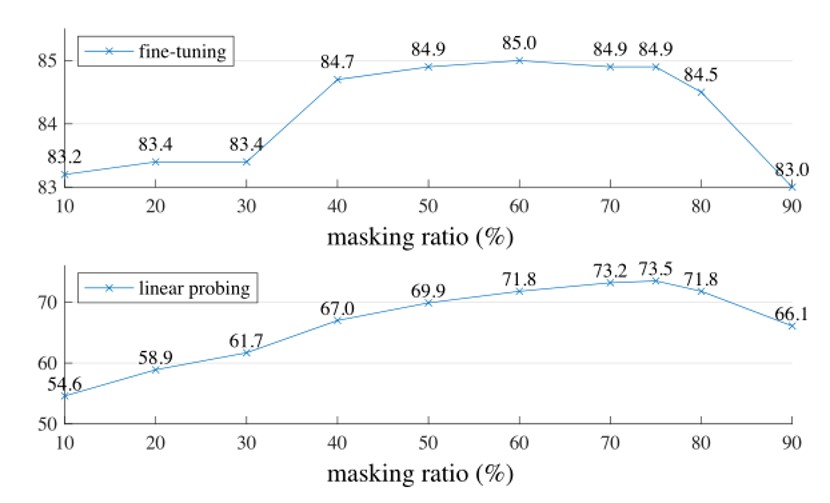
Fig. 8. Experimental results of MAE under different coverage ratios. Adapted from [1]
The above picture is under finetune, that is, the encoder and classifier are trained at the same time. The picture below is under linear-probing, that is, only the classifier is trained.
It can be seen that when the coverage ratio is too high or too low, the accuracy rate will drop. The best effect can be achieved at a coverage ratio of about 75%.
In addition to the ratio of coverage, how to choose the area to cover is also a problem. The author conducted some experiments, as shown in the figure below: 
Fig. 9. Visualization of different masking strategies for MAE. Adapted from [1] 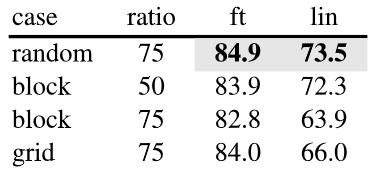
Fig. 10. Experimental results of different masking strategies for MAE. Adapted from [1]
Among them, random is completely random coverage, block is to select a box area to cover, and grid is to cover regularly in a grid.
As can be seen from the results, random is the best.
extended to video
Now that MAE can be used on images, can we extend it to video? The answer is yes. We can think of video as a series of images, and then use MAE for pre-training.
Last year, NeurIPS 2022 had a spotlight job called VideoMAE [15] , which extended MAE to video. 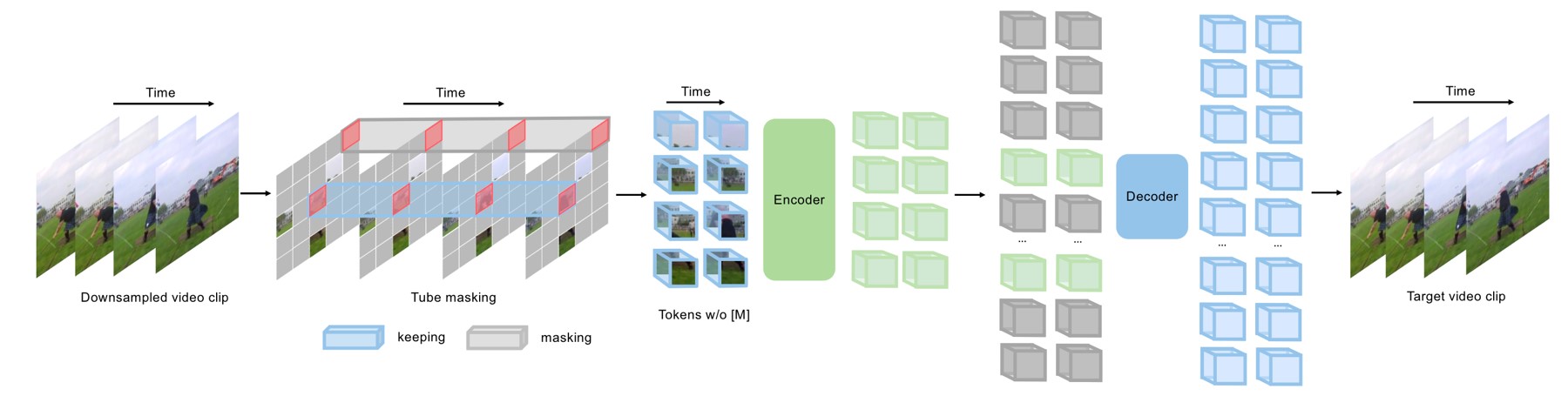
Fig. 11. Structure of VideoMAE. Adapted from [15]
As shown in the figure above, the overall structure has not changed much, and pre-training is still performed by covering. The main change is the use of 3D cubes instead of 2D patches as tokens.
Experimental results
The author conducted experiments on Something-Something-V2 [16] , as shown in the figure below: 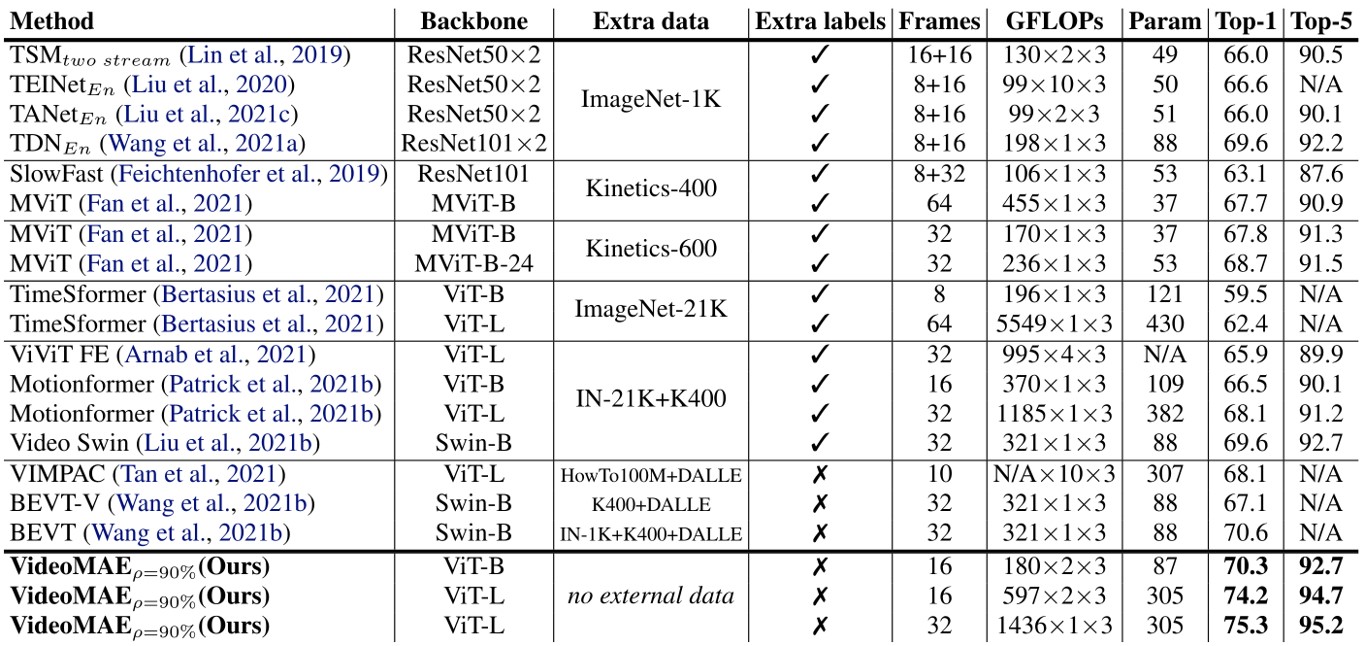
Fig. 12. Experimental results of VideoMAE on Something-Something-V2. Adapted from [15]
It can be seen that the effect is still good. The author mentioned in the article that in order to train this model, they used 64 V100s.
They also discussed the best masking method, thinking that tube masking is the best, that is, masking in the spatial dimension and keeping the same in the time dimension.
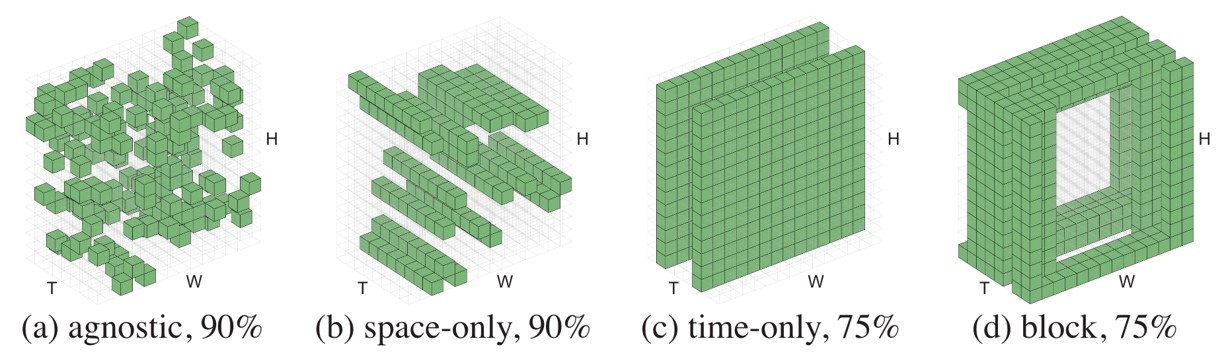
Fig. 13. Visualization of different masking strategies. Adapted from [17]
Interestingly, another paper MAE-ST [17] , also published at NeurIPS 2022, also extends MAE to video. And the method and structure are very similar, but they think that the best masking method is random masking.
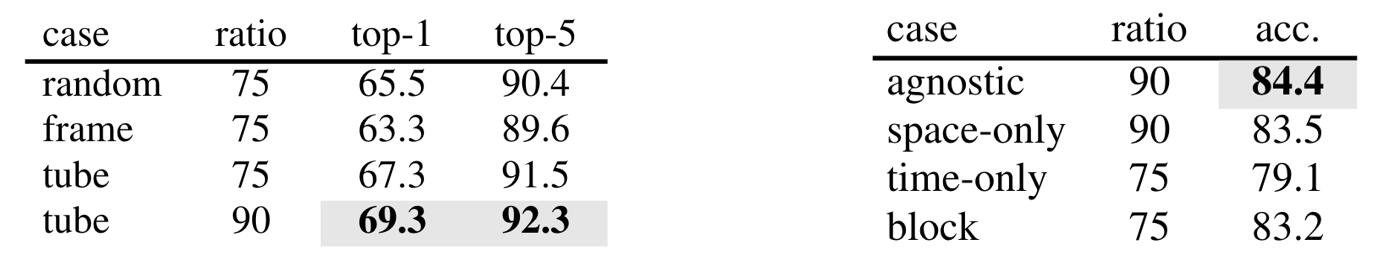
Fig. 14. The experimental results of two papers on different masking strategies, the left is from VideoMAE, and the right is MAE-ST. Adapted from [15] [17]
The author of VideoMAE believes that the use of tube masking can avoid the leakage of information in the time dimension. This leak causes the encoder to see information that would otherwise be masked, causing performance to suffer. The authors of MAE-ST believe that purely random masking can prevent the model from biasing the information, thereby improving performance.
I personally think that the data set used by VideoMAE is smaller than that used by MAE-ST, so it may be that the difference in the size of the data set leads to different conclusions.
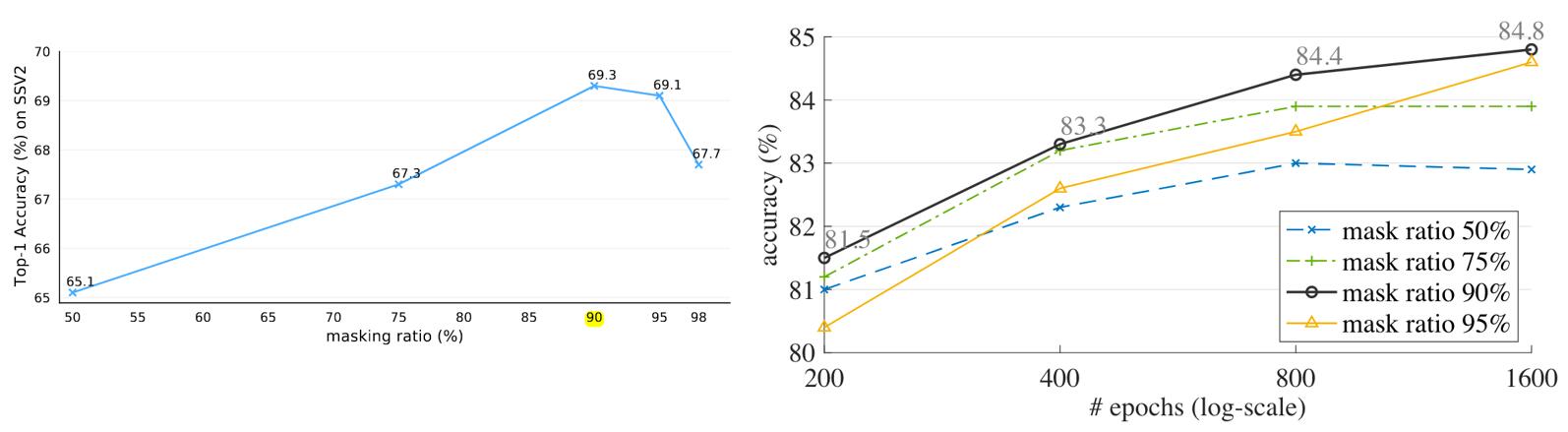
Fig. 15. The experimental results of two papers under different coverage ratios, the left is from VideoMAE, and the right is MAE-ST. Adapted from [15] [17]
Regarding the proportion of coverage, both papers believe that 90% is the best.
Summarize
This paper discusses the importance of representation learning in deep learning, and introduces MAE as a relatively cutting-edge representation learning method. The core idea of MAE is to let the model learn more information by covering, and later the community extended it to the video field. By using these pre-trained models, ordinary developers can also use less data and computing resources to migrate these models to their own tasks to achieve better results.
references
- [1] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked Autoencoders Are Scalable Vision Learners,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16000–16009.
- [2] A. Krizhevsky, I. Sutskever, and G. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Neural Information Processing Systems, vol. 25, pp. 1097–1105, Jan. 2012, doi: 10.1145/3065386 .
- [3] S. Negi, “GPT-3: A new step towards general Artificial Intelligence,” Medium, Oct. 20, 2020. https://ift.tt/qvGcg2W
- [4] T. Baltrušaitis, P. Robinson, and L.-P. Morency, “OpenFace: An open source facial behavior analysis toolkit,” in 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA: IEEE, Mar. 2016, pp. 1–10. doi: 10.1109/WACV.2016.7477553.
- [5] BD Lucas and T. Kanade, “An iterative image registration technique with an application to stereo vision,” in Proceedings of the 7th international joint conference on Artificial intelligence, in IJCAI’81, vol. 2. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., Aug. 1981, pp. 674–679.
- [6] S. Zhao, L. Zhao, Z. Zhang, E. Zhou, and D. Metaxas, “Global Matching With Overlapping Attention for Optical Flow Estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2022, pp. 17592–17601.
- [7] A. Ranjan, DT Hoffmann, D. Tzionas, S. Tang, J. Romero, and MJ Black, “Learning Multi-human Optical Flow,” Int J Comput Vis, vol. 128, no. 4, pp. 873–890, Apr. 2020, doi: 10.1007/s11263-019-01279-w.
- [8] “librosa.feature.mfcc — librosa 0.8.0 documentation,” librosa.org, 2023. https://ift.tt/KgsHJ2t
- [9] A. Hannun et al., “Deep Speech: Scaling up end-to-end speech recognition.” arXiv, Dec. 19, 2014. doi: 10.48550/arXiv.1412.5567.
- [10] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient Estimation of Word Representations in Vector Space,” in 1st International Conference on Learning Representations, ICLR 2013, Workshop Track Proceedings, Y. Bengio and Y. LeCun, Eds., Scottsdale, Arizona, USA, 2013. doi: 10.48550/arXiv.1301.3781.
- [11] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota: Association for Computational Linguistics, Jun. 2019, pp. 4171–4186. doi: 10.18653/v1/N19- 1423.
- [12] ”
 Transformers,” huggingface.co, 2023. https://ift.tt/uwOqhRE
Transformers,” huggingface.co, 2023. https://ift.tt/uwOqhRE - [13] Y. Bengio, A. Courville, and P. Vincent, “Representation Learning: A Review and New Perspectives,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, Aug. 2013, doi: 10.1109/TPAMI.2013.50.
- [14] A. Dosovitskiy et al., “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale,” in International Conference on Learning Representations, 2021.
- [15] Z. Tong, Y. Song, J. Wang, and L. Wang, “VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training,” in Advances in Neural Information Processing Systems, Oct. 2022.
- [16] R. Goyal et al., “The ‘Something Something’ Video Database for Learning and Evaluating Visual Common Sense,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5842–5850.
- [17] C. Feichtenhofer, haoqi fan, Y. Li, and K. He, “Masked autoencoders as spatiotemporal learners,” in Advances in neural information processing systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave , K. Cho, and A. Oh, Eds., Curran Associates, Inc., 2022, pp. 35946–35958.
This article is transferred from: https://controlnet.space/2023/06/08/reading/representation-learning/
This site is only for collection, and the copyright belongs to the original author.