Original link: https://www.ifanr.com/app/1546210
This morning, a leaked document from Google circulated on the SemiAnalysis blog, claiming that open source AI will defeat Google and OpenAI and win the final victory. The view that “we don’t have a moat, and neither does OpenAI”, has aroused heated discussions.
According to Bloomberg, the article, written by Luke Sernau, a senior software engineer at Google, was shared thousands of times after it was released internally at Google in early April.

Google, which calls itself AI-first, has been experiencing setbacks in recent months.
In February, Google Bard made a public demonstration error, and its market value evaporated by hundreds of billions. In March, Workspace, which integrated AI into the office scene, was released, but Copilot, which integrated GPT-4, stole the limelight.
In the process of catching up with the trend, Google has always been cautious and failed to seize the opportunity.
Behind this, Google CEO Pichai tends to be incremental rather than radically improved products. Some executives did not listen to his dispatch, perhaps because the power was not in Pichai’s hands at all.
Today, although Google co-founder Larry Page has been less involved in Google’s internal affairs, he is still a member of Alphabet’s board of directors, controls the company through special stocks, and has participated in many internal AI strategy meetings in recent months. .
Each of the problems facing Google is difficult:
- The CEO keeps a low profile, and co-founder Larry Page controls the company through equity;
- The caution of “developing products but not releasing them” has caused Google to lose the opportunity many times;
- A more visual and interactive Internet that threatens Google Search;
- The market performance of various AI products is not good.
Amidst internal and external troubles, Google has been shrouded in a corporate culture similar to an academic or government institution, full of bureaucracy, and its top management is always risk-averse.
We integrated and translated the full text. For Google, open source may not be the last straw that breaks the camel’s back, but its life-saving straw.
Extraction of core information
- Neither Google nor OpenAI will win the competition, the winner will be open source AI
- Open source AI has caught up with the strength of ChatGPT with extremely low-cost high-speed iteration
- Data quality is far more important than data quantity
- The result of competing with open source AI is inevitable failure
- Google needs the open source community more than the open source community needs Google
Google doesn’t have a moat, and neither does OpenAI
We’ve been watching what OpenAI is doing, who will hit the next milestone? What’s next?
But I have to admit that neither we nor OpenAI have won this competition. While we are competing, third-party forces have gained an advantage .
I’m talking about the open source community. Simply put, they are outrunning us. What we consider to be “big problems” has been solved and put into use today. To give a few examples:
- LLM on mobile: People can run base models at 5 tokens per second on Pixel 6;
- Scalable Personal AI: You can fine-tune a personalized AI overnight on your laptop;
- Responsible release: This problem is not “solved”, but “removed”. The Internet is full of artistic models without limits, and language models are coming;
- Multimodal: The current multimodal ScienceQA SOTA can be trained in one hour.
While our model still has an edge in terms of quality, the gap is closing at an alarming rate . The open source model is faster, more customizable, more private, and more performant. They did something with $10 million and 13 billion parameters that we couldn’t do with $10 million and 540 billion parameters. And they’re done in weeks, not months. This means to us:
We have no secret weapon. Our best bet is to learn from and collaborate with others outside of Google, and enabling third-party integrations should be a priority .
People won’t pay for a restricted model when there are free, unlimited alternatives, and we should be thinking about where our real value lies.
Huge models are slowing us down. In the long run, the best models are those that can be iterated quickly. Now that we know what is possible with less than 20 billion parameters, we should focus more on small variants.
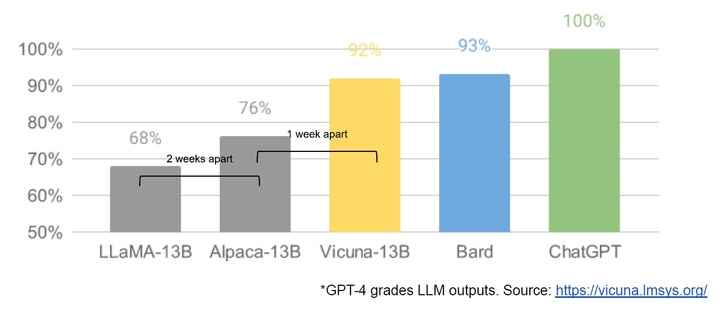
The Open Source Community Welcomes LLaMA
In early March of this year, for the first time, the open source community got a really powerful base model, LLaMA from Meta. It has no instruction or dialogue tuning, and no reinforcement learning human feedback (RLHF), but the community immediately recognized the importance of LLaMA.
Then, a huge wave of innovation followed, with only a few days between each major development (see timeline at end of article for details). A month later, there are variants of instruction tuning, quantization, quality improvements, human evals, multimodality, RLHF, etc., many of which are interdependent of.
Best of all, they’ve solved the problem of scale so that anyone can participate, and many new ideas come from ordinary people. The threshold for experimentation and training is lowered from a large institution to one person, one night, or a powerful laptop .
LLM’s Stable Diffusion Moment
In many ways, this shouldn’t come as a surprise to anyone. The current renaissance of open source LLMs is closely followed by the renaissance of image generation. This similarity has not been overlooked by the community, with many dubbing it the “Stable Diffusion Moment” of LLM.
In both cases, low-cost public participation was achieved because a fine-tuning mechanism called Low rank adaptation (LoRA) greatly reduced costs, combined with major breakthroughs in scale (Latent Diffusion for image synthesis, Chinchilla of LLM). In both cases, the open source community quickly outnumbered the large players.
These contributions played a key role in the field of image generation, and set Stable Diffusion on a different path from Dall-E. Having an open source model leads to product integration, marketing, user interface and innovation, which didn’t happen with Dall-E.
This effect is very obvious: in terms of impact, compared with OpenAI’s solution, Stable Diffusion quickly dominates, making the former gradually less and less important .
Whether the same happens with LLM remains to be seen, but the basic structural elements are the same.

Google shouldn’t have missed
The success of recent innovations in the open source community directly addresses problems we are still struggling with. Focusing on their work can help us avoid reinventing the wheel.
LoRA is a powerful technology that we should pay attention to .
LoRA works by representing model updates as low-rank factorizations, reducing the size of the update matrix by a factor of thousands. This greatly reduces the cost and time of model fine-tuning. Personalizing a language model in a few hours on consumer-grade hardware is a big deal, especially for visions that involve integrating new, diverse knowledge in near real-time.
It’s a technology that’s underappreciated within Google, even though it directly impacts some of our most ambitious projects.
Training the model from scratch is not as good as LoRA
The reason LoRA works is that its fine-tuning is stackable.
For example, improvements like instruction tweaks can be applied directly and then leveraged when other contributors add dialogue, reasoning, or tool usage. While individual fine-tuning is low-rank, their sum is not, resulting in a full-rank update.
This means that, as new and better datasets and tasks become available, models can be kept updated cheaply without having to incur the cost of full-scale operation.
In contrast, training huge models from scratch discards not only pre-training, but also the iterative updates that have already been made, and in an open-source world, these improvements can quickly take over, making full retraining prohibitively expensive.
We should seriously consider whether a new application or idea really requires a completely new model to implement. If the change of the model architecture makes the trained model weights unable to be directly applied, then we should actively adopt the distillation technique to preserve the capabilities brought by the previously trained model weights as much as possible.
Note: The outcome of model training is the model weights file; distillation is a method for simplifying large models.
Iterate quickly to make small models better than large ones
LoRA updates are very cheap (~$100) for the most popular model sizes. This means that almost anyone can generate and distribute a model.
Training times of less than a day are the norm, and at this rate the cumulative effect of all these fine-tuning quickly makes up for the starting size disadvantage. In fact, from an engineer’s perspective, these models improve much faster than our largest models, and the best models are already essentially indistinguishable from ChatGPT . Focusing on maintaining some of the largest models on the planet can actually put us at a disadvantage.

Data quality is more important than data size
Many projects save time by training on small, highly curated datasets.
This shows that the law of data expansion has some flexibility. These datasets exist along the lines of Data Doesn’t Do What You Think, and they are fast becoming the standard way of training outside of Google.
These datasets are built using synthetic methods (eg, filtering the best responses from existing models) and obtained from other projects, neither of which is dominated at Google. Fortunately, these high-quality datasets are open source, so they are freely available.
Competing with open source is bound to fail
Recent developments have direct, immediate implications for our business strategy. Who would choose to use restricted and paid Google products when there is a free, high-quality, unlimited alternative?
And we shouldn’t expect to be able to catch up. The modern Internet relies on open source, and open source has important advantages that we cannot replicate .

Google needs open source more than being needed by open source
It is difficult for us to ensure the confidentiality of technical secrets. Once Google researchers leave for other companies, we should assume that other companies have all the information we know. And, as long as someone leaves, the problem cannot be resolved.
Sustaining a technological competitive advantage is more difficult today, and research institutions around the world are learning from each other to explore the solution space in a breadth-first manner far beyond our own capabilities. We can try to hang on to secrets but dilute their value by innovating outside, or we can try to learn from each other.
Individuals are less constrained by licenses than companies
Many innovations are based on the Meta leakage model. While this will certainly change as the true open source model gets better, the point is they don’t have to wait.
Legal protections for “personal use” and the practical difficulty of prosecuting individuals mean that when these technologies are hot, everyone has access to them.
Being your own customer means understanding use cases
When looking through the models people have created using the field of image generation, you can see a lot of ideas popping up, from animation generators to HDR landscapes. These models are used and created by people deeply immersed in their particular sub-genre, giving them a depth of knowledge and empathy that we can’t match.
Owning the Ecosystem: Making Open Source Work for Google
Paradoxically, the only winner in all of this is Meta. Because the leaked model is theirs, they’re effectively getting a lot of free labor around the world. Since most open source innovations happen on top of their architecture, there’s nothing stopping them from incorporating it directly into their products.
The value of owning an ecosystem is self-evident. Google itself has successfully used this paradigm in its open source products such as Chrome and Android. By owning the platform on which innovation happens, Google solidifies itself as a thought leader and direction provider, earning the ability to shape ideas beyond itself.
The more tightly we control our models, the more people will be interested in open source alternatives. Both Google and OpenAI tend to adopt a defensive release model in order to maintain tight control over how the models are used. But this control is illusory, and anyone who wants to use LLM for unauthorized purposes will choose a freely available model.
Google should establish itself as a leader in the open source community and lead the community through cooperation.
This might mean taking uneasy steps like publishing model weights for small ULM variants. This necessarily means giving up some control over our model. But such compromises are inevitable. We cannot hope to drive innovation and control it at the same time.

Where is the future of OpenAI?
These discussions about open source may feel unfair because OpenAI’s current policy is closed. If they don’t share, why should we? But the truth is, we’ve shared everything with them through a steady churn of senior researchers. Secrecy means nothing until we stop this drain.
Ultimately, OpenAI doesn’t matter. They have made the same mistakes we have made in their stance with open source, and their ability to maintain an advantage must be called into question. Unless they change their stance, open source alternatives will eventually replace and surpass them.
At least in this regard, we can take the lead.
This article has attracted widespread attention on social platforms such as Twitter, and the views of professor Alex Dimakis from the University of Texas have been recognized by many people:
- I agree that open source AI is winning, which is good for the world and a competitive ecosystem. Although it has not been done in the LLM field, we have defeated OpenAI Clip with Open Clip, and Stable Diffusion is indeed better than the closed model;
- You don’t need a huge model, high-quality data is more important, and the alpaca model behind the API further weakens the moat;
- Starting from a well-founded model and Parameter Efficient Fine-Tuning (PEFT) algorithm, such as Lora can run well in a day, the door of algorithm innovation is finally opened;
- Universities and open source communities should organize more curated datasets for training base models and building communities like Stable Diffusion did.
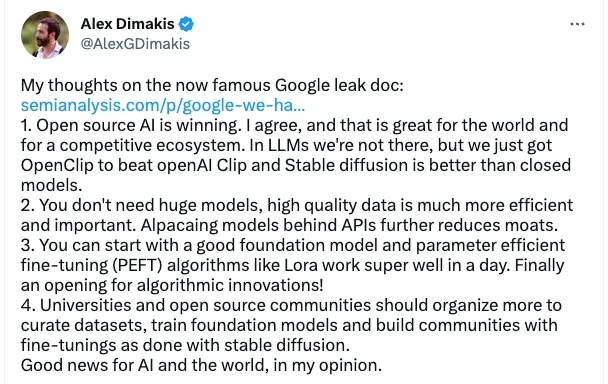
But at the same time, many people are skeptical about the capabilities of open source AI, saying that it still has a certain distance from ChatGPT.
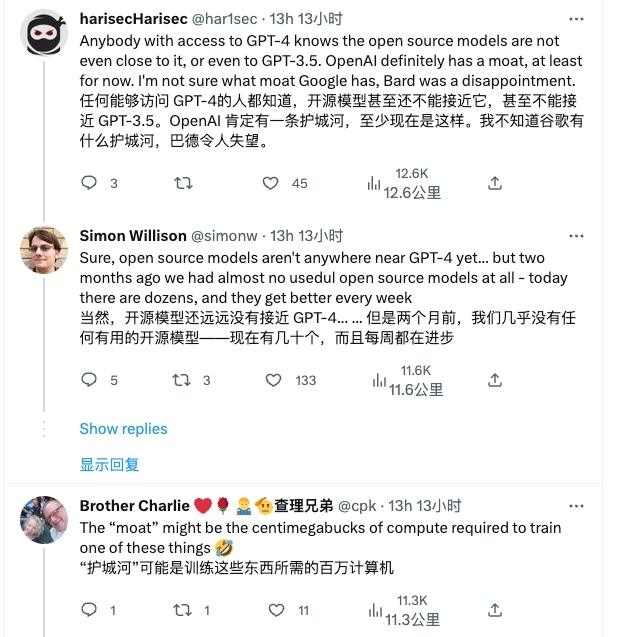
But in any case, open source AI lowers the threshold for everyone to participate in research, and we also expect Google to seize the opportunity and “take the lead.”
*Original link: https://ift.tt/rnj8cID
*Pictures are from Bing Image Creator
This article is transferred from: https://www.ifanr.com/app/1546210
This site is only for collection, and the copyright belongs to the original author.