Editor’s note: ICLR (International Conference on Learning Representations) is one of the internationally recognized top conferences in the field of deep learning. papers were published at the conference. This year’s ICLR Congress will be held online from April 25-29. A total of 1095 papers were accepted in this conference, and the acceptance rate of papers was 32.3%. Today, we have selected six of them for a brief introduction. The keywords of the research topics include time series, policy optimization, decoupled representation learning, sampling methods, reinforcement learning, etc. Interested readers are welcome to read the original text of the paper and learn about the cutting-edge progress in the field of deep learning!
Deep Unrolling Learning for Periodic Time Series

Paper link: https://ift.tt/uyPaXwo
Periodic time series are ubiquitous in electric power, transportation, environment, medical and other fields, but it is difficult to accurately capture the evolution law of these time series signals. On the one hand, it is because the observed time series signals often have various and complex dependencies on the implicit periodic laws, and on the other hand, these implicit periodic laws are usually composed of periodic patterns of different frequencies and amplitudes. . However, existing deep time series forecasting models either ignore the modeling of periodicity or rely on some simple assumptions (additive periodicity, multiplicative periodicity, etc.), resulting in unsatisfactory performance in the corresponding forecasting tasks.
After thinking deeply about these research difficulties, researchers at Microsoft Research Asia proposed a new set of deep expansion learning framework DEPTS for the forecasting problem of periodic time series. The framework can both characterize diverse periodic components and capture complex periodic dependencies.
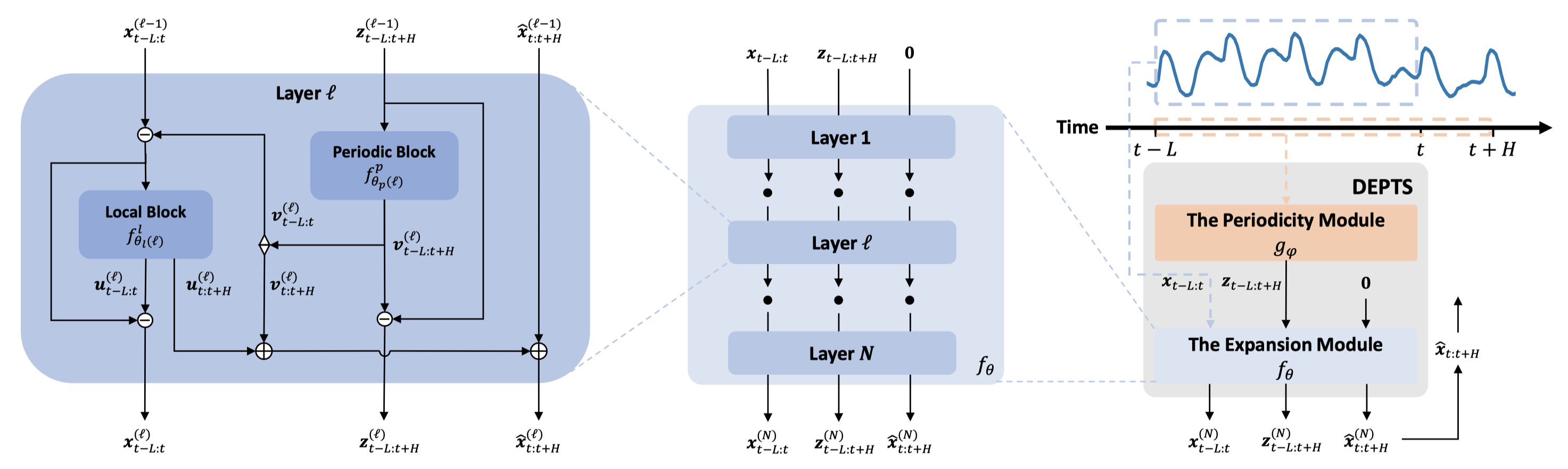
Figure 1: DEPTS Framework Diagram
As shown in Figure 1, DEPTS mainly includes two modules: The Periodicity Module and The Expansion Module. First, the period module is responsible for modeling the global period of the entire time series, accepting the global time as input and inferring the implicit periodic state as output. In order to effectively characterize the composite period of many different modes, a set of parameterized periodic functions (such as cosine series) are used to construct periodic modules and corresponding transformations (such as discrete cosine transform) are used for efficient parameter initialization.
Then, based on an observed time-series signal and its corresponding implicit period state, the unrolling module is responsible for capturing the complex dependencies between the observed signal and the implicit period and making predictions. Here, the researchers extend the classical idea of deep residual learning to develop a deep unrolled learning architecture. In this architecture, researchers perform layer-by-layer dependency expansion on the input time series and its implicit period and derive the corresponding forecast components. In each layer, a parameterized periodic neural network determines the focused periodic component of this layer, and expands the retrospective and predictive components of the observed signal. Before moving on to the next layer, the researchers subtracted the periodic and look-back components generated in this layer, thereby encouraging subsequent neural network layers to focus on periodic dependencies that have not yet been unfolded. Stacking N layers in this way constitutes a (deep) expansion module.
The researchers conducted experimental validations on both generated data and extensive real data, clearly revealing the shortcomings of existing methods in periodic time series forecasting, and strongly confirming the superiority of the DEPTS framework. It is worth noting that in some data with strong cyclical patterns, DEPTS can improve by up to 20% compared to the existing best solutions.
In addition, DEPTS is inherently interpretable due to the explicit modeling of periodicity and the provision of component expansions of predicted values in terms of both global periodicity and local fluctuations.
In the model-based policy optimization algorithm, the gradient information of the model is important

Paper link: https://ift.tt/3vXUxSf
Model-based reinforcement learning methods provide an efficient mechanism for obtaining optimal policies by interacting with the learned environment. In this paper, the researchers investigate problems where model learning does not match model usage. Specifically, in order to obtain the update direction of the current policy, an effective method is to use the differentiability of the model to calculate the derivative of the model. However, the commonly used methods now simply regard the learning of the model as a supervised learning task, and use the prediction error of the model to guide the learning of the model, but ignore the gradient error of the model. In short, model-based reinforcement learning algorithms often require accurate model gradients, but only reduce the prediction error during the learning phase, so there is a problem of inconsistent goals.
In this paper, the researchers first theoretically proved that the gradient error of the model is crucial for policy optimization. Since the deviation of the policy gradient is affected not only by the model prediction error but also by the model gradient error, these errors will ultimately affect the convergence rate of the policy optimization process.
Next, the paper proposes a dual-model approach to simultaneously control the prediction and gradient errors of the model. The researchers designed two different models and assigned them different roles during the learning and use phases of the models. In the model learning phase, the researchers designed a feasible method to calculate the gradient error and use it to guide the learning of the gradient model. In the model use stage, researchers first use the prediction model to obtain the predicted trajectory, and then use the gradient model to calculate the model gradient. Combining the above methods, this paper proposes a policy optimization algorithm based on directional derivative projection (DDPPO). Finally, the experimental results on a series of continuous control benchmark tasks demonstrate that the algorithm proposed in the paper indeed has higher sample efficiency.

Figure 2: (a) Inconsistencies in model learning and use. (b) Schematic diagram of the DDPPO algorithm. The DDPPO algorithm constructs the prediction model and the gradient model respectively. The DDPPO algorithm uses different loss functions to train the two models separately and use them appropriately in policy optimization.
RecurD Recursive Decoupled Network

Paper link: https://ift.tt/YQjoFRe
Recent advances in machine learning have shown that the learning ability of decoupled representations is beneficial for models to achieve efficient data utilization. Among them, BETA-VAE and its variants are the most widely used class of methods in decoupled representation learning. This type of work introduces a variety of different inductive biases as regularization terms and applies them directly to the latent variable space, aiming to balance the relationship between the informativeness of decoupled representations and their independence constraints. However, the feature space of deep models has a natural compositional structure, that is, each complex feature is a composition of original features. Simply applying a decoupling regularizer to the latent variable space cannot effectively propagate the constraints of the decoupled representation in the combined feature space.
This paper aims to solve the problem of decoupled representation learning by combining the characteristics of the combined feature space. First, the paper defines the properties of decoupled representations from the perspective of information theory, thereby introducing a new learning objective including three basic properties: adequacy, minimum adequacy, and decoupling. The theoretical analysis shows that the learning objective proposed in this paper is the general form of BETA-VAE and its several variants. Next, we extend the proposed learning objective to combinatorial feature spaces to cover disentangled representation learning problems in combinatorial feature spaces, including combinatorial minimum adequacy and combinatorial decoupling.
Based on the combined decoupling learning objective, this paper proposes a corresponding recursive disentanglement network (RecurD), which recursively propagates the decoupling inductive bias to guide the disentanglement in the combined feature space of the model network. learning process. Through feedforward networks, recursive propagation of strong inductive biases is a sufficient condition for decoupled representation learning. Experiments show that RecurD achieves better decoupled representation learning than BETA-VAE and its variants. Moreover, in downstream classification tasks, RecurD also shows a certain ability to effectively utilize data.

Figure 3: RecurD network structure
Sampling method based on mirror Stein operator

Paper link: https://ift.tt/MOSaBTG
Some machine learning and scientific computing problems, such as Bayesian inference, boil down to using a set of samples to represent a distribution for which only the unnormalized density function is known. Different from the classic Markov chain Monte Carlo method, the Stein variational gradient descent (SVGD) method developed in recent years has better sample efficiency, But sampling distributions over confined spaces (Θ in the figure) or sampling distributions with distorted shapes is still laborious.
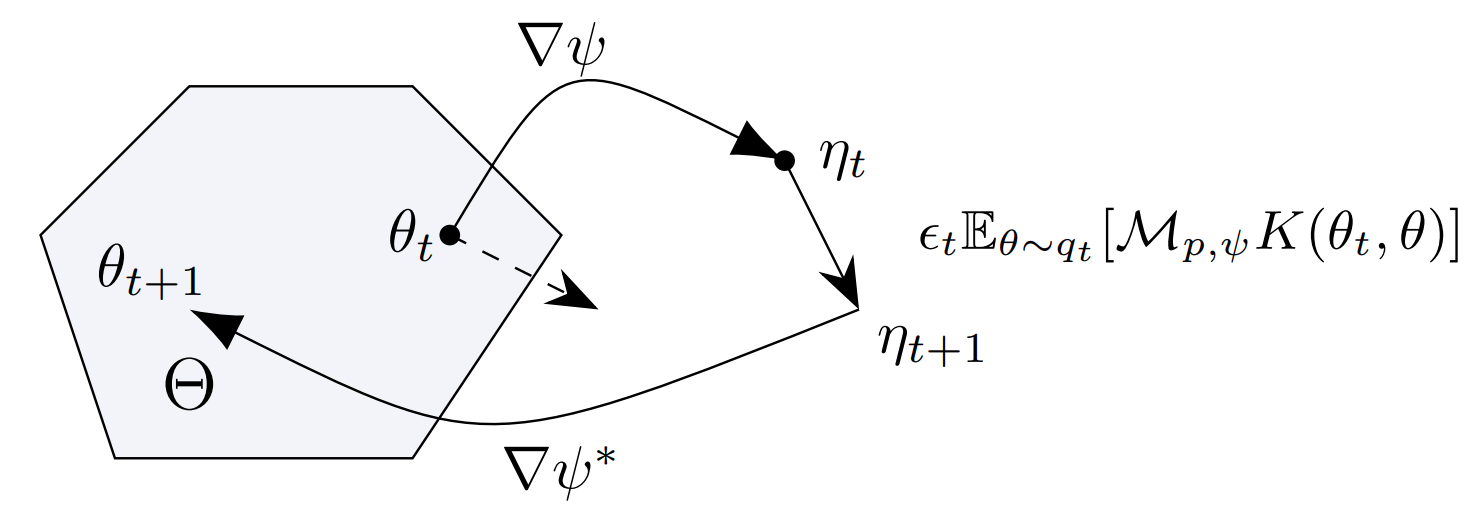
Figure 4: The original sample space \Theta and its mirror image space
In this paper, the researchers derived and designed a series of mirrored Stein operators and their corresponding mirrored SVGD methods by drawing on the idea of mirrored descent in the optimization field. The mirror space obtained by mirror mapping of the original space (∇ψ in the figure) is unlimited and can reflect the distributed geometric information, so these methods systematically solve the above problems.
Specifically, the principle of SVGD is to use the update direction that maximizes the KL divergence reduction rate between the sample distribution and the target distribution to update the sample, so that the sample distribution continues to approach the target distribution, and this reduction rate and update direction are both. is given by the Stein operator. Therefore, the paper first deduces the Stein operator in the mirror space (M_(p,ψ) in the figure) and the update direction of the sample (in the figure E_(θ∼q_t ) [M_(p,ψ) K(θ_t,θ )]).
The researchers then designed three kernel functions (kernel function, K in the figure) required to calculate the update direction, which can be classified as gradient descent for the peak of the target distribution in the mirror space and the original space in the case of a single sample, and the original one. Natural gradient descent in space. The paper also derives the convergence guarantee of the proposed method. Experiments show that the proposed method has better convergence speed and accuracy than the original SVGD.
Deploying Efficient Reinforcement Learning: Theoretical Lower Bounds and Optimal Algorithms

Paper link: https://ift.tt/qWGTReO
The learning process of traditional (online) reinforcement learning (RL) can be summarized as a two-part cycle: one is to learn a policy based on the collected data; the other is to deploy the policy into the environment to interact and obtain new The data is used for subsequent learning. The goal of reinforcement learning is to complete the exploration of the environment in such a loop and improve the strategy until it is optimal.
However, in some practical applications, the process of deploying a strategy will be very cumbersome, and relatively speaking, after deploying a new strategy, the data collection process is very fast. For example, in a recommendation system, a strategy is a recommendation scheme, and a good strategy can accurately push the content that users need. Considering the user experience, a company usually conducts internal tests for a long time to check the performance before launching a new recommendation strategy. Due to the huge user base, a large amount of user feedback data can often be collected within a short period of time after deployment. Follow-up policy learning. In such applications, researchers prefer to choose algorithms that can learn good policies with only a small number of deployments (deployment complexity).
But there is still a gap between existing reinforcement learning algorithms and theories and the above real needs. In this paper, the researchers try to fill this gap. The researchers first provided a more rigorous definition of deployment-efficient RL from a theoretical point of view. Then, using the episodic linear MDP as a specific setting, the researchers studied how the optimal algorithm can perform (lower bound), and proposed an algorithm design scheme that can achieve the optimal deployment complexity (optimality).
Among them, in the lower bound part, the researchers contributed the construction and related proofs of the theoretical lower bound; in the upper bound part, the researchers proposed a “layer-by-layer advancement” exploration strategy (as shown in Figure 5), and contributed a covariance-based exploration strategy A new algorithmic framework for matrix estimation, as well as some technical innovations. The researchers’ conclusions also reveal the significant effect of deploying strategies with randomness in reducing deployment complexity, which is often overlooked in previous work.
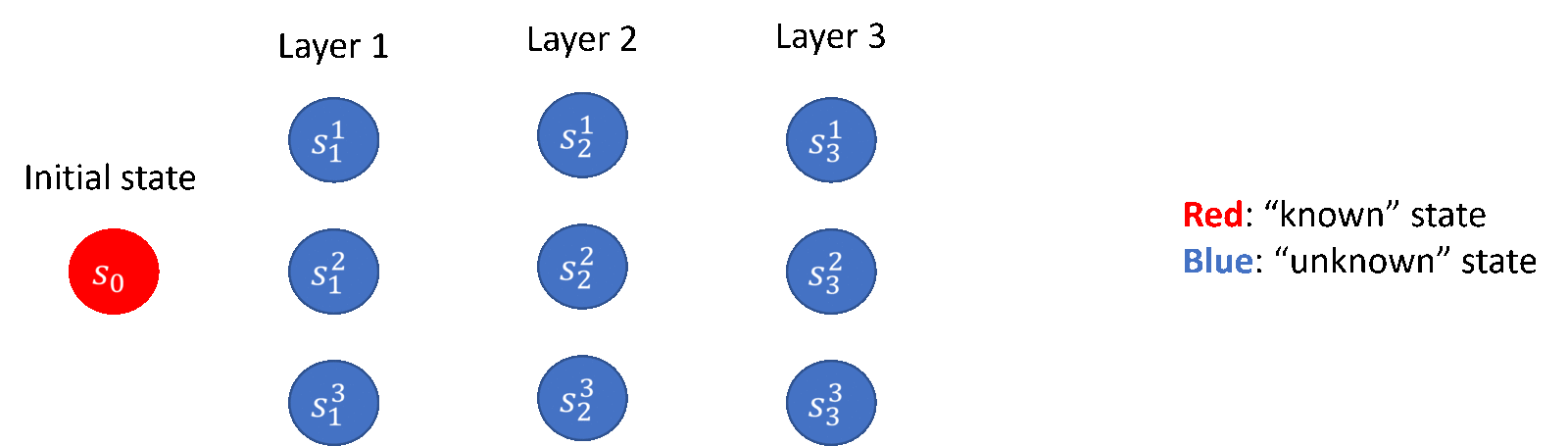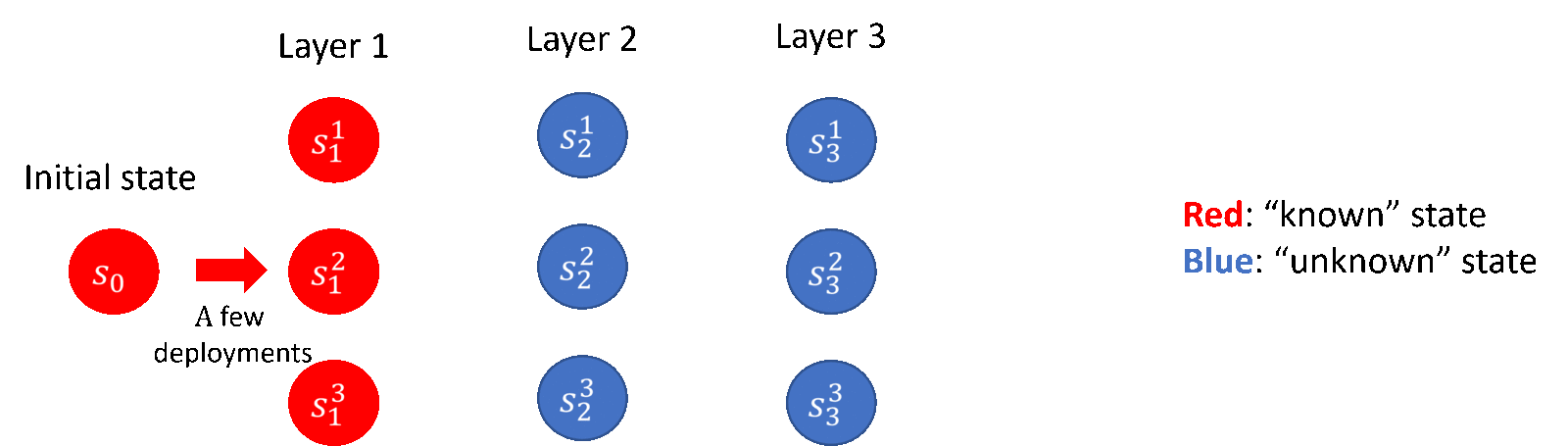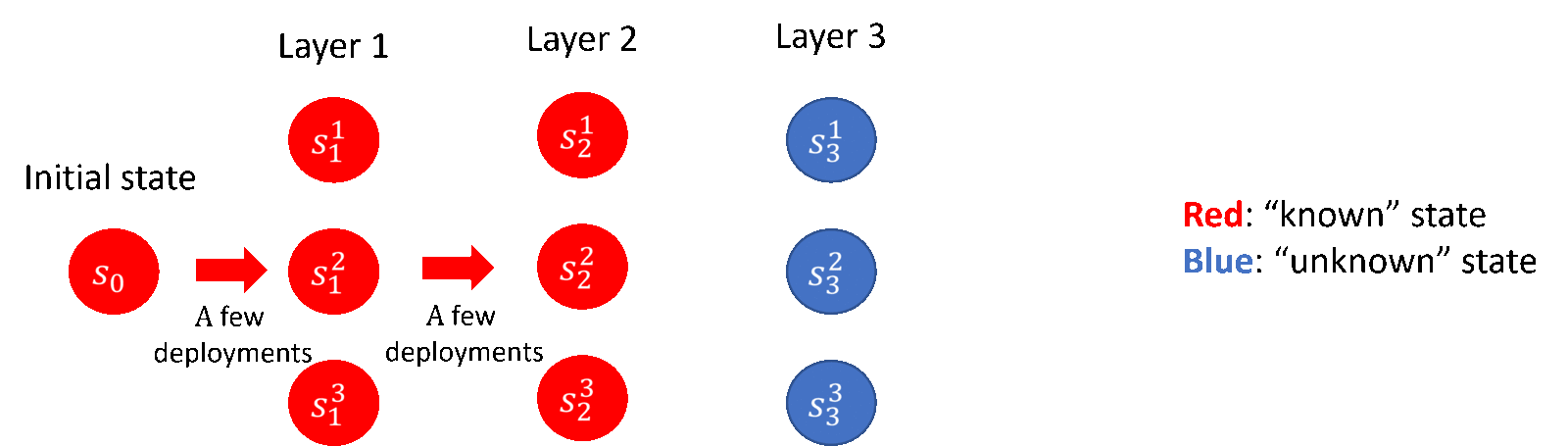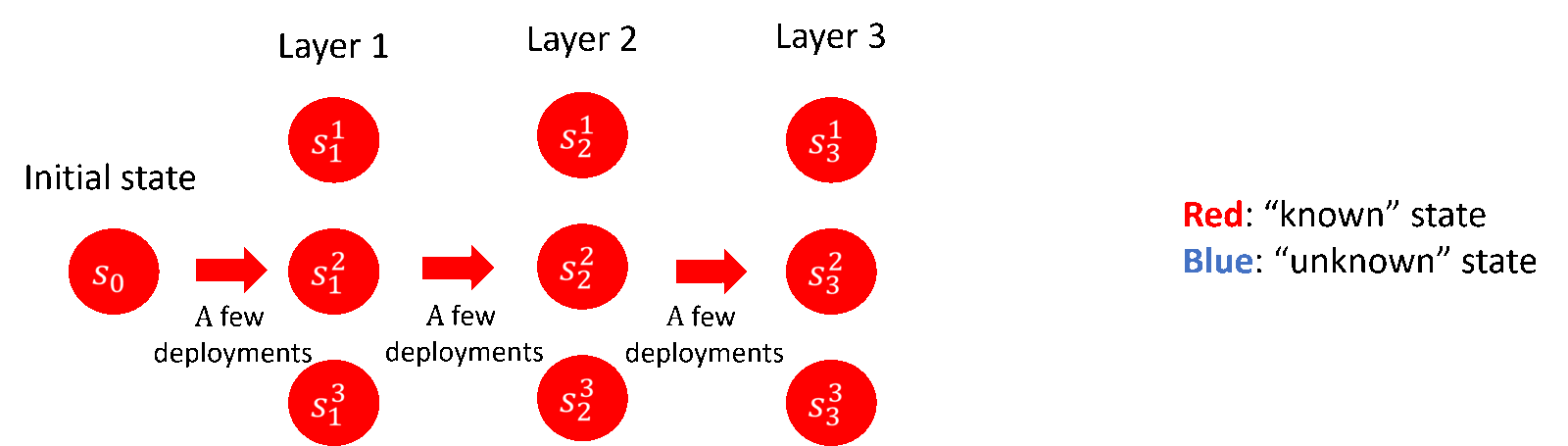
Figure 5: The exploration strategy of “advance layer by layer” (taking the 3-layer discrete Markov decision process as an example)
Variational Prophet Guidance in Reinforcement Learning

Paper link: https://ift.tt/BfJnktH
GitHub link: https://ift.tt/jBA9gUc
Deep Reinforcement Learning (DRL) has recently been successful in a variety of decision-making problems, however there is an important aspect that has not been fully explored – how to use oracle observation (information not visible during decision-making, but known after the fact) to aid training . For example, human poker masters will review replays of the game after a game, where they can analyze their opponents’ hands, helping them better reflect on whether their own decisions based on executor observation during the game could be improved . Such a problem is called oracle guiding.
In this work, researchers study the problem of oracle guiding based on Bayesian theory. This paper proposes a new objective function for reinforcement learning based on variational Bayes to utilize oracle observation to aid in training. The main contribution of this work is to propose a general reinforcement learning framework called Variational Latent Oracle Guiding (VLOG). VLOG has many excellent properties, such as good and robust performance on various tasks, and VLOG can be combined with any value-based DRL algorithm.
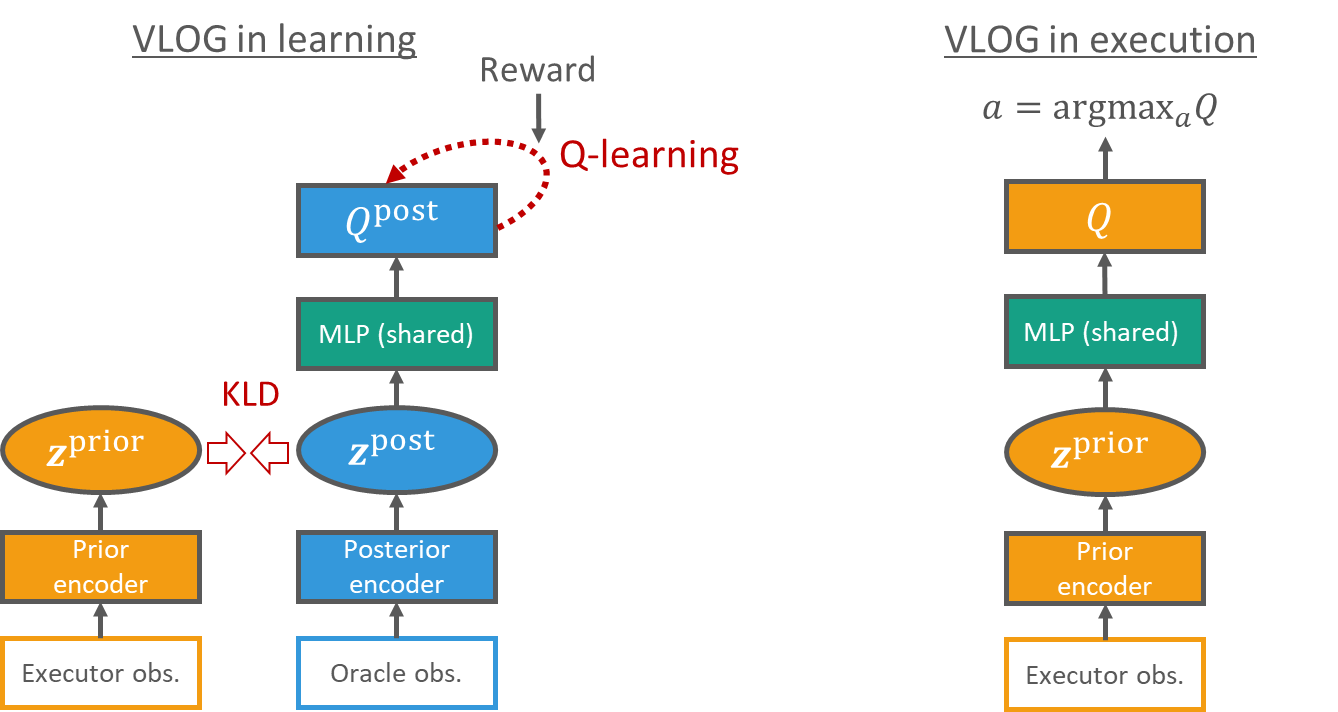
Figure 6: Model diagram of VLOG during training and use (using Q-learning as an example). Left: During training (knowing the oracle observation), executor observation and oracle observation are used to estimate the prior and posterior distributions of a Bayesian latent variable z, respectively. The entire model is trained by optimizing the VLOG variational lower bound (the reinforcement learning objective function of the posterior model minus the KL divergence between the posterior and prior distributions of z). Right: When used, decisions are made based on visible information.
The researchers experimented with VLOG on various tasks, including a maze, a simplified version of Atari Games, and Mahjong. The experiments cover different situations of online and offline reinforcement learning, and both verify the good performance of VLOG. In addition, the researchers also open-sourced the Mahjong reinforcement learning environment and the corresponding offline reinforcement learning data set used in the paper as a standardized test environment for future research on oracle guiding problems and complex decision-making environments.
This article is reprinted from: https://www.msra.cn/zh-cn/news/features/iclr-2022
This site is for inclusion only, and the copyright belongs to the original author.