Original link: https://www.insidentally.com/articles/000031/
When I was reading the U-Net paper recently, I saw the code for building a network model from scratch on the Internet. The code is indirect enough and the structure is relatively complete, so record the learning results.
The focus of this paper is on how to implement the code. The details in the U-Net paper are not covered, and the discussion on the paper can be moved.
Links to learning resources are at the end of the article.
U-net model
First of all, there is a simple understanding of the model:
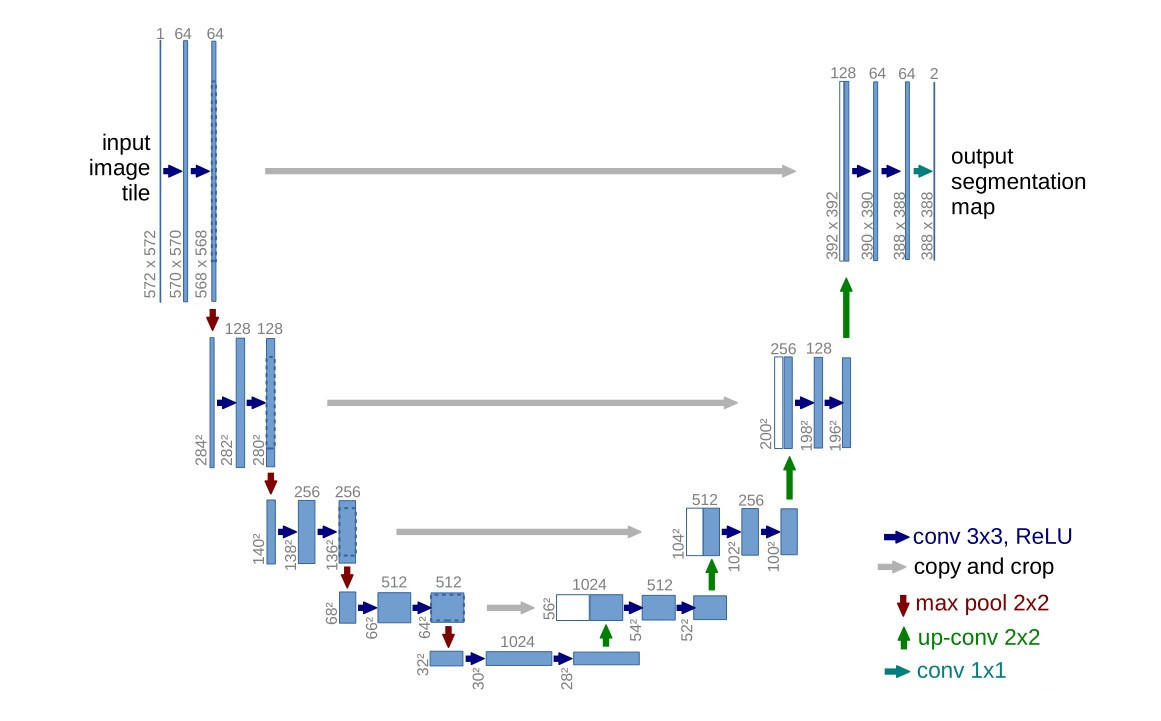
U-net model
For the construction of the U-net model, the main thing is the implementation of the convolution layer and the transposed convolution (down-sampling and up-sampling), and how to realize the connection of the mirror corresponding parts. Readers are requested to understand the U-net model and keep in mind the number of channels at each step.
Code
According to the common problem-solving steps in industry or competitions, it mainly includes data set acquisition, model construction, model training (selection of loss function, model optimization), and verification of training results. Therefore, the code will be interpreted from these aspects in the following.
Data set acquisition
Dataset URL: Carvana Image Masking Challenge | Kaggle
Baidu website link: https://pan.baidu.com/s/1bhKCyd226__fDhWbYLGPJQ Extraction code: 4t3y
Among them, readers are required to first use the data from the training set as a validation set according to their own needs.
read data set
1 |
import os |
1 |
class CarvanaDataset ( Dataset ): |
For the convenience of subsequent operations, directly inherit the Dataset, and then return the image and the corresponding mask.
os.listdir(path) returns the files (folders) under the specified path. In the above code, returns the list corresponding to the entire training set images.
os.path.join() This operation directly obtains the storage path corresponding to each image
image.open().convert(), this function converts the image according to the specified mode, such as RGB image, or grayscale image. (I haven’t found the specific official explanation yet, if there is an explanation on the official website, please enlighten me)
mask[mask==255.0] = 1.0 to facilitate the calculation of the subsequent sigmoid() function? (doubtful)
Model building
First observe the construction of the U-net model. Before the pool layer, there will always be two convolutions to increase the number of channels of the original image. So first create the class DoubleConv.
1 |
import torch |
Next, observe the U-net model. It is very elegant because of its symmetry, and the processing of each step is very regular. It is because of such a law that we can write code without being so cumbersome and repetitive. Convolution-pooling-convolution-pooling.
1 |
class UNET (nn.Module): |
In the above code, the entire u-Net model is divided into a convolutional layer (downsampling), a transposed convolutional layer (upsampling), a pooling layer, a bottleneck layer, and a final convolutional layer.
For the downsampling stage, use ModelList(), then determine the input and output channels of each convolution, and then use a loop structure.
1 |
features=[ 64 , 128 , 256 , 512 ] |
1 |
def forward ( self,x ): |
In the forward propagation, it should be noted that each layer of U-net has a skip-connnection
skip-connections=[] , save the convolved x to a list and connect it when upsampling
skip_connections=skip_connections[::-1], the order of saving is opposite to the order of use, so it needs to be reversed
concat_skip=torch.cat((skip_connection, x),dim=1) to connect the two
some practical operations
I think when we write code, why the code structure looks messy, mainly because we have not been able to integrate every function and operation. Here is a specific example.
1 |
def save_checkpoint ( state,filename= 'my_checkpoint.pth.tar' ): |
function to save the trained model
torch.save() official website torch.save() annotation
1 |
def load_checkpoint ( checkpoint, model ): |
Load the model, you can retrain the model that was not trained last time
1 |
def get_loader ( |
Common functions for loading data, among which CarvanaDataset is customized, or Dataset() can be used directly
Parameters in the DataLoader() function:
pin_memory ( bool , optional ) – If True , the data loader will copy Tensors into CUDA pinned memory before returning them. If your data elements are a custom type, or your collate_fn returns a batch that is a custom type, see the example below.
Train the model
Determination of hyperparameters:
1 |
LEARNING_RATE = 1e-4 |
Training function train_fn()
1 |
def train_fn ( loader, model, optimizer, loss_fn, scaler ): |
loop = tqdm(loader) is simply understood as a fast and scalable python progress bar
loop.set_postfix() sets the output content of the progress bar
Specifically about the use of tqdm, I have not studied in depth
In the above code, it should be noted that the code for forward propagation and back propagation is different from the common code, because this code introduces mixed precision training, please refer to it for details.
resource link
Source code: https://github.com/aladdinpersson/Machine-Learning-Collection
Video source: https://www.youtube.com/watch?v=IHq1t7NxS8k
Bilibili: [CV tutorial] From scratch: Pytorch image segmentation tutorial and U-NET_bilibili_bilibili
some thoughts
In the video, you can clearly understand how to build a model from scratch, how to run it, and how to implement some additional functions in the process of use, which is of great benefit to a novice like me.
And there are many other projects on the main GitHub page of up, basically starting from scratch. You can try to participate in the kaggle competition step by step in the future.
If you have friends who are just getting started with deep learning, you can also exchange and learn together.
This article is reprinted from: https://www.insidentally.com/articles/000031/
This site is for inclusion only, and the copyright belongs to the original author.