Author | Li Mei
Editor | Chen Caixian
Machine translation is a new tool for human beings to remove language barriers and rebuild the Tower of Babel. However, among the more than 7,000 known languages in the world, many low-resource languages have not received enough attention, especially nearly half of the languages do not have a standard written system, which is a major obstacle to building machine translation tools, so Currently AI translation is mainly focused on written language.
Meta has been working on the goal of “No Language Left Behind” when it comes to using AI to drive natural language translation.
For example, Hokkien, one of the Chinese dialects , now has its own machine translation system, so Hokkien speakers can have barrier-free conversations with English speakers.
This is the first AI-powered unwritten, speech-to-speech translation system open sourced by Meta . Listen to the conversation between Peng-Jen Chen, a researcher at Meta AI, and Xiao Zha, who is in charge of this work. Chen was born in Taiwan, China.
Video at: https://ift.tt/FmaWSfK
The system can translate Hokkien speech into English speech and vice versa. Readers who can speak Hokkien can check it out. Is the translation effect quite good?
The open-source translation system is understood to be part of Meta’s Universal Speech Translation (UST) project, which is working to develop new artificial intelligence methods to help enable real-time speech-to-speech translation in all existing languages. At present, Meta has open sourced the translation model and evaluation dataset. The research papers are as follows:
 Paper address: https://ift.tt/Eoktbyu
Paper address: https://ift.tt/Eoktbyu
1
Overcoming training data challenges
Hokkien, one of the Chinese dialects, is a low-resource language with no standard writing system and relatively few human English-to-Hokkien translators, making it more difficult to collect and label training data for the model.

Legend: Number of Hokkien speakers
To this end, the research team from Meta AI adopted a special release scheme, using Mandarin Chinese (a high-resource language) as an intermediate language to construct pseudo-labels and human translations. They first translated the English (or Hokkien) speech into Mandarin text, then translated it into Hokkien (or English) and added it to the training data. This approach greatly improves model performance by leveraging data from similar high-resource languages.
Speech mining is another approach to training data generation. Using a pre-trained speech encoder, Hokkien speech embeddings can be encoded into the same semantic space as other languages, so Hokkien has no written form and does not pose a problem. Hokkien speech can be aligned with English speech and text with similar semantic embeddings, and then English speech is synthesized from the text, resulting in parallel Hokkien and English speech.

Legend: Speech translation model without human annotation
2
New Modeling Approach: Speech-to-Speech
Many speech translation systems rely on transcription or speech-to-text systems. However, the form of Hokkien dialect is mainly spoken, and it lacks a standard written writing system and cannot be transcribed into text. So, what Meta builds is a speech -to-speech translation system.
The researchers used speech-to-unit (S2UT) translation to translate the input speech directly into a series of acoustic units, a path previously pioneered by Meta. Then, waveforms are generated from these acoustic units . In addition, the researchers also adopted UnitY as a dual-pass decoding mechanism, where the first-pass decoder generates the text in the relevant language (i.e., Mandarin Chinese), and the second-pass decoder creates the unit.
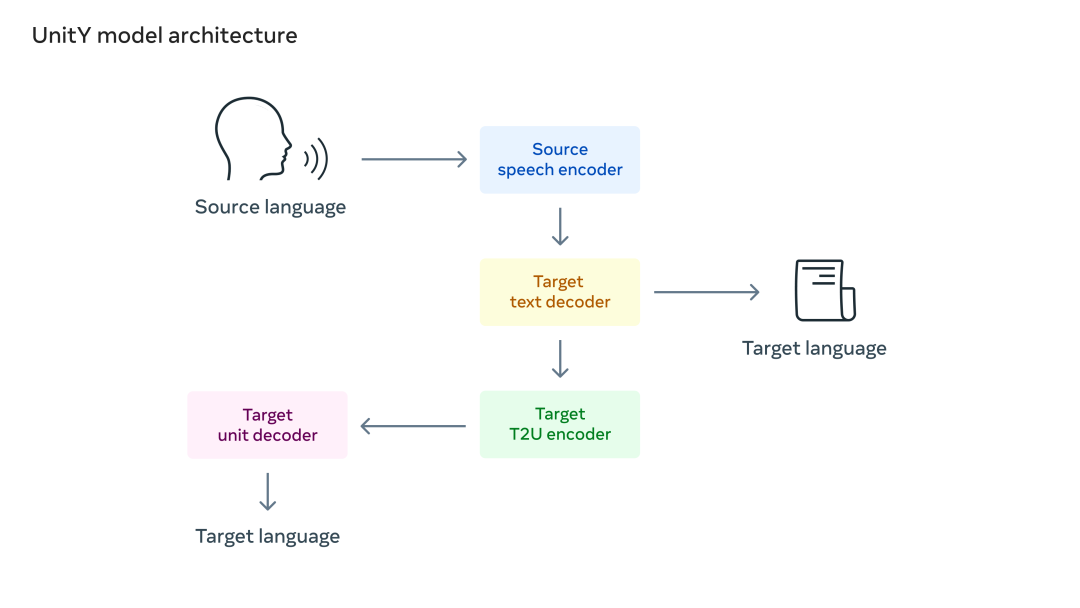
Legend: UnitY Model Architecture
3
New Accuracy Evaluation System
The evaluation tool for speech translation systems is usually the ASR-BLEU metric, which first transcribes the translated speech into text using automatic speech recognition (ASR), and then calculates the BLEU score by comparing the transcribed text with the human-translated text.
But the difficulty in evaluating the Hokkien phonetic translation system is that it does not have a standard written text system. So, to automate the assessment, the researchers developed a system that transcribes Hokkien speech into a standardized phonetic symbol called Tâi-lô. This allows BLEU scores to be calculated at the syllable level to compare the translation quality of different methods.
In addition to developing this method for evaluating Hokkien-English phonetic translation, the researchers also created the first Hokkien-English bidirectional speech-to-speech translation benchmark dataset based on Taiwanese Across Taiwan, a Hokkien corpus. The benchmark dataset will be open-sourced to facilitate more researchers working on Hokkien speech translation.
4
More than Hokkien
The techniques used in this work can be further extended to many other written and non-written languages.
To this end, Meta has also released SpeechMatrix, a large speech-to-speech translation corpus that uses Meta’s innovative data mining technology, LASER, to mine data from real speeches recorded by the European Parliament. The database contains phonetic alignments for 136 language pairs with a total of 418,000 hours of speech. The mined data and models are free, and researchers can create their own speech-to-speech translation (S2ST) systems.

Legend: Speech-to-speech paired data obtained from LASER mining
Meta’s research progress in unsupervised speech recognition (wav2vec-U) and unsupervised machine translation (mBART) also provides support for spoken language translation work. For example, unsupervised domain adaptation techniques for pre-training speech models improve the performance of downstream unsupervised speech recognition, especially for low-resource languages, and can build high-quality speech-to-speech translation models without any manual annotations .
The model is still in progress and currently can only translate one complete sentence at a time, but this is a step towards enabling simultaneous interpretation between languages in the future.
According to Peng-Jen Chen, a researcher at Meta AI, the Hokkien translation system is actually part of his personal wish. He grew up in Taiwan, China, and speaks Mandarin, but his father is not good at Mandarin, and he hopes his father can communicate smoothly with everyone in Hokkien. This is also one of the meanings of AI for human beings.
Reference link: https://ift.tt/jvLmFfz
For more content , click below to follow: Scan the code to add AI technology review WeChat account, contribute & join the group:

Leifeng.com
This article is reprinted from: https://www.leiphone.com/category/academic/9iLOYrrmt6YpwNEX.html
This site is for inclusion only, and the copyright belongs to the original author.