Original link: https://www.kingname.info/2022/05/22/find-discount/
I believe that many students who are crawlers will crawl the e-commerce website once a day, and then monitor whether the price of the product is reduced. If you only monitor one product, it is very easy to judge whether the price is reduced, but if you want to find all the products with reduced price on this website, it is very troublesome.
As shown in the figure below, it is the product data of the US e-commerce Walmart:

Each product will be climbed once a day, with a total of 61w+ pieces of data. There are N products whose prices have been reduced, and now we need to find out these products whose prices have been reduced.
There are hundreds of thousands of products. If you find the ID of each product separately, and then use the ID to find the data of this product every day, and finally check whether the price has dropped, the workload will be very large and the speed will be very slow.
Pandas uses SIMB technology internally to optimize parallel computing. We need to try our best to complete this task without using for loops.
For the sake of simplicity, let’s assume that the price reduction means that today’s price is lower than yesterday’s price, regardless of the first price increase and then the price decrease.
To fix this, we need to use DataFrame’s pct_change() method. It’s like reduce , given a series of data, it calculates the percentage of the change in the data – the change of the second relative to the first, the third relative to the second, the fourth The change of the piece of data relative to the third piece of data.
First we sort the data using the date field to make sure the prices are sorted by time. Then group the id of the products, so that you can get the daily price of each product. Then use pct_change() on the price field:
1 |
df2[ 'pct' ] = df2.sort_values([ 'date' , 'id' ]).groupby([ 'id' ]).price.pct_change() |
The operation effect is shown in the following figure:
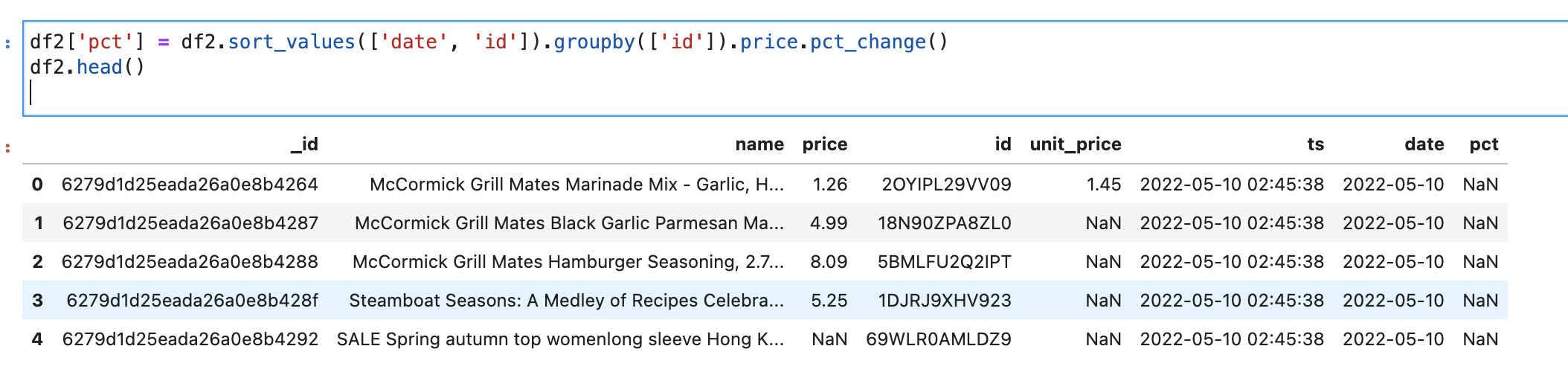
The rightmost pct field in the figure is NaN, because this is the first data of these products, so it is always NaN.
We filter out products with pct less than 0 today (2022-05-16):

These are discounted items. We can filter a product at random to check:
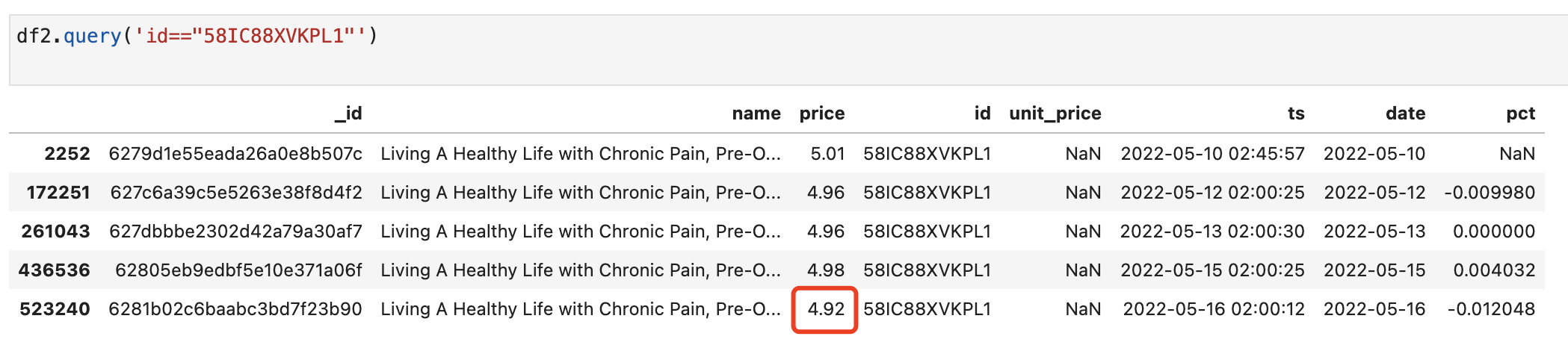
Using pct_change() is very fast, and 60w data is almost second. Much faster than a for loop.
This article is reprinted from: https://www.kingname.info/2022/05/22/find-discount/
This site is for inclusion only, and the copyright belongs to the original author.