Original link: https://www.kingname.info/2023/07/19/crawl-by-sitemap/
I recently encountered a need to grab all the documents on Docusaurus . As shown below:
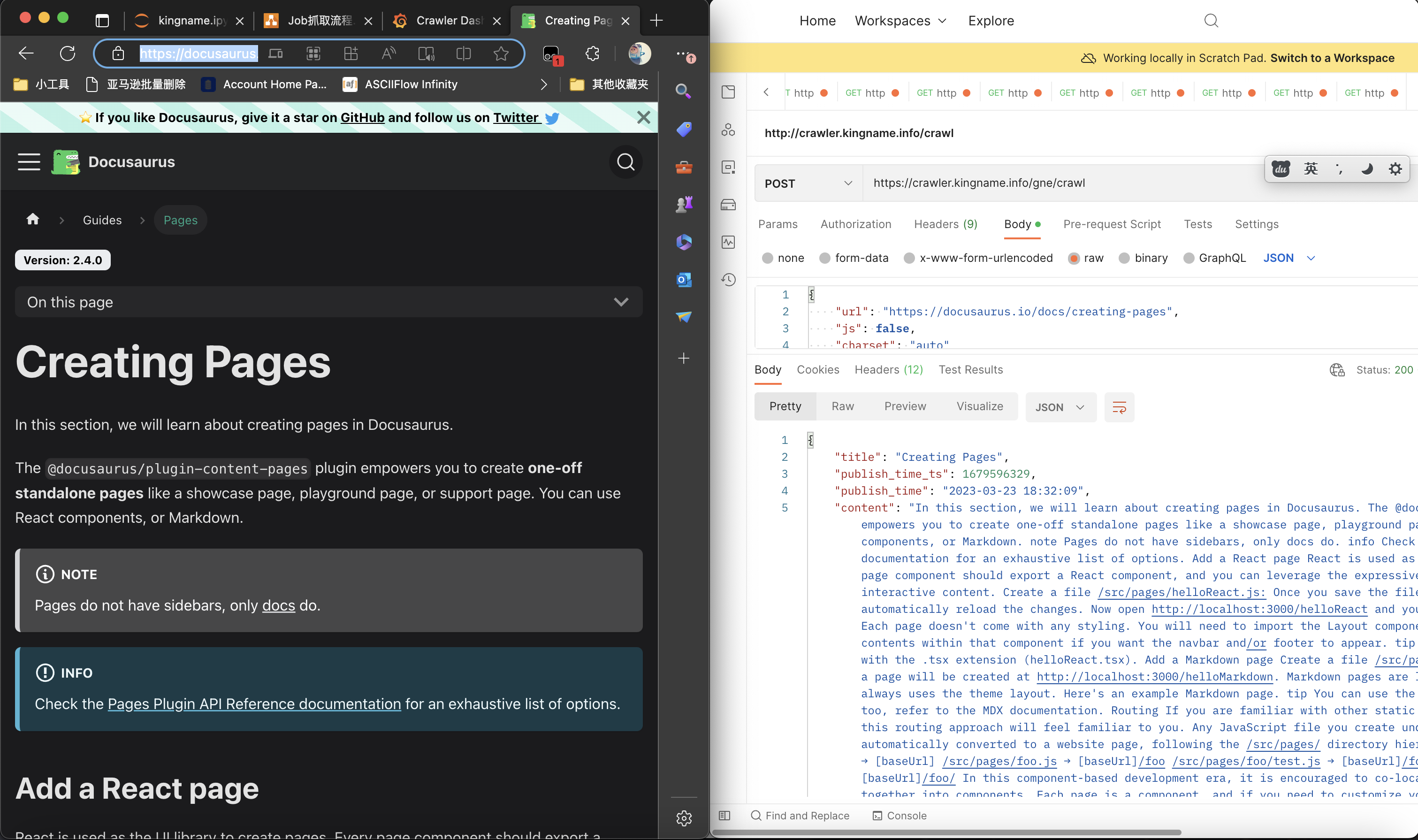
It is very simple to capture the text of the document. Using GNE Advanced Edition, as long as there is a URL, it can be directly captured, as shown in the following figure:
But the question now is, how do I get the URL of each document?
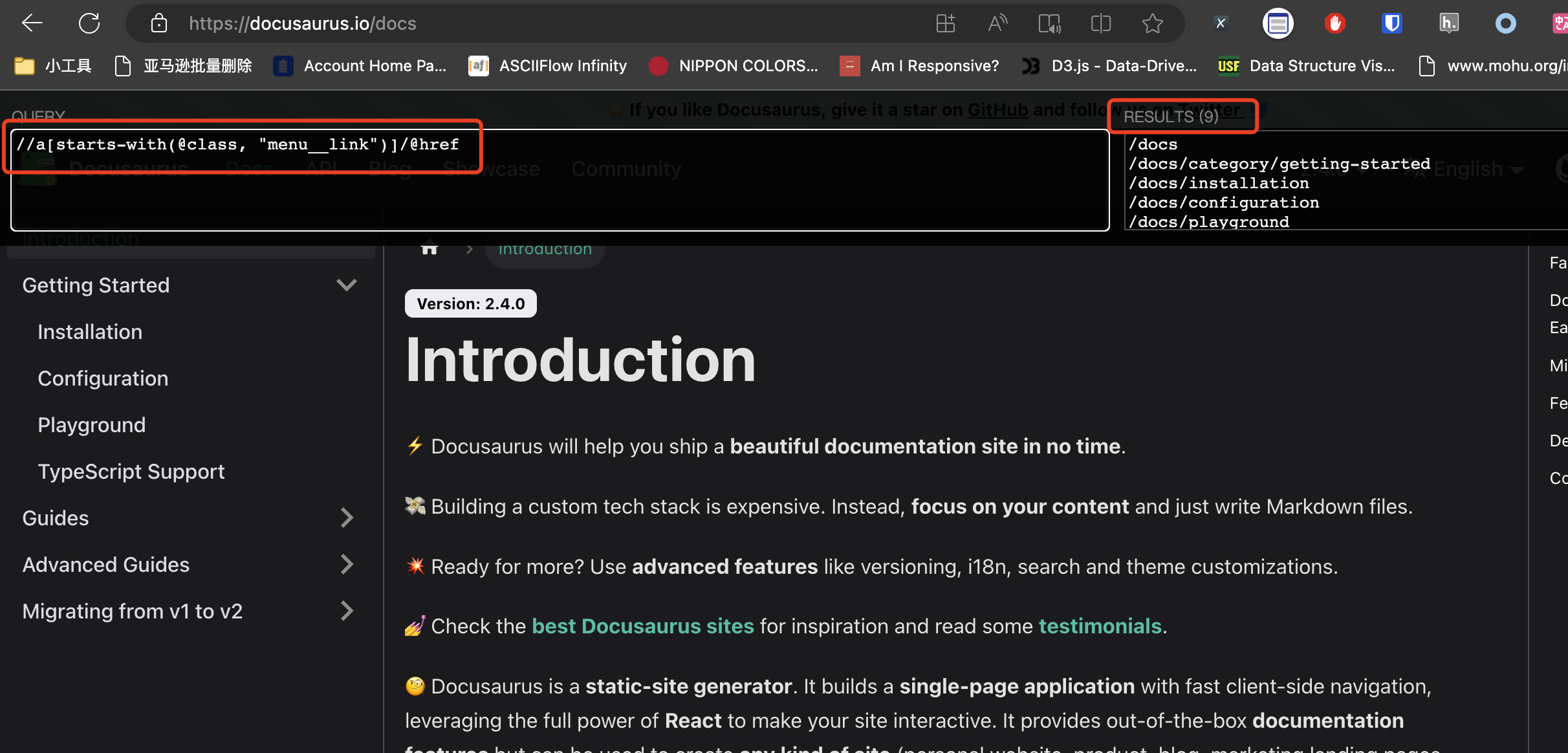
Docusaurus is a documentation framework whose pages and directories are rendered in real-time with JavaScript. When we do not expand its directory, XPath can only extract the link to the current headline, as shown in the image below:
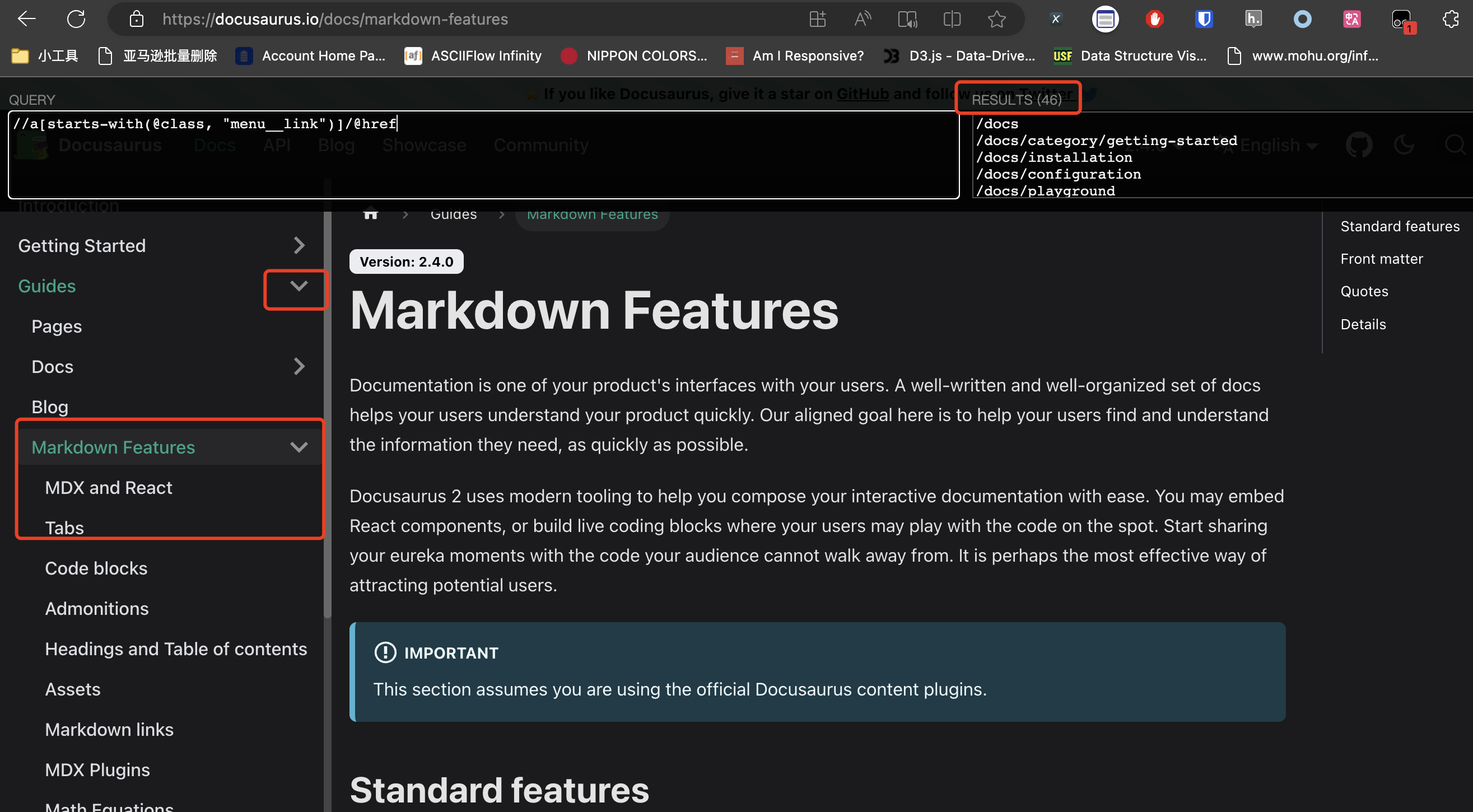
When we click on a certain title and let the subtitle appear, the data that XPath can extract will change accordingly, as shown in the following figure:
In this case, the crawler scheme we often use will encounter obstacles:
- Directly use Requests to get the source code – there is no URL for each directory in the source code
- Using Selenium – Executing XPath directly gets incomplete. You need to control Selenium to click on each small arrow in order to get all URLs using XPath.
At this time, some students will start to use Charles to catch the Ajax request of the website. Then you will find that the URL of each item in the directory is in a js file:
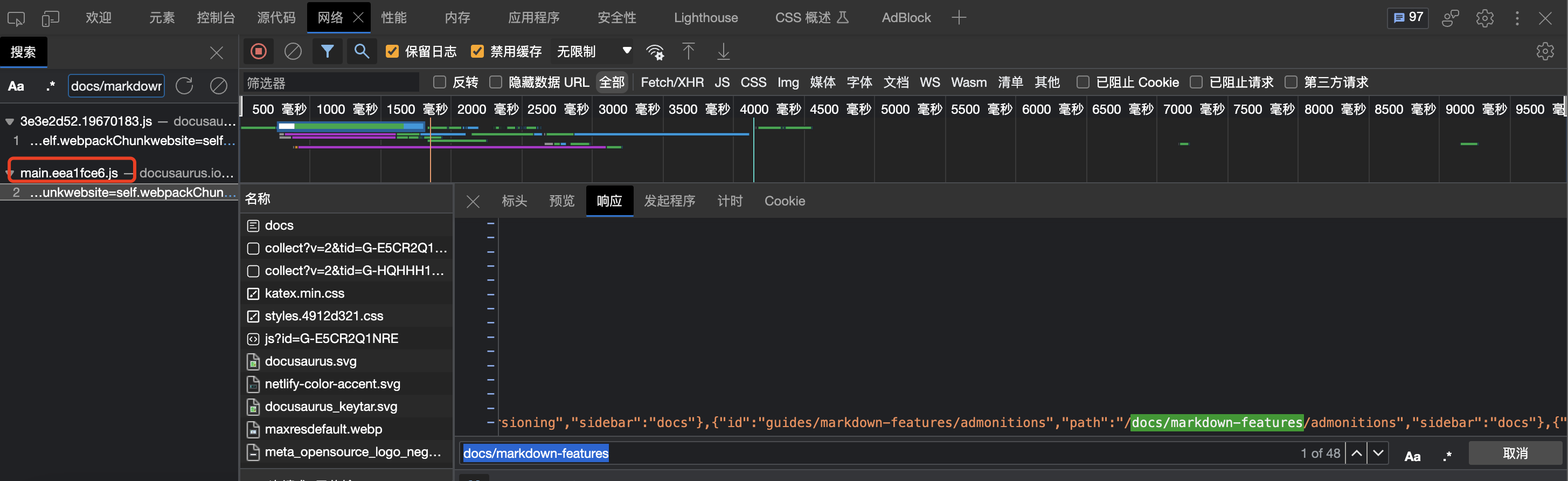
Docusaurus is relatively simple. You download this js file, use regular expressions to extract the JSON strings where all the URLs are located, and you can get all the URLs of the document directory page.
But interested students can try this website again: Uniswap Docs . Its URL is scattered in many JS files, which is very troublesome to parse.
How to quickly get all the URLs of the catalog page when encountering such a website? In fact, you don’t need to use any advanced tools to solve it.
For Docusaurus , we only need to add /sitemap.xml after its domain name, and then search for keywords /docs/ to find all document URLs, as shown in the following figure:
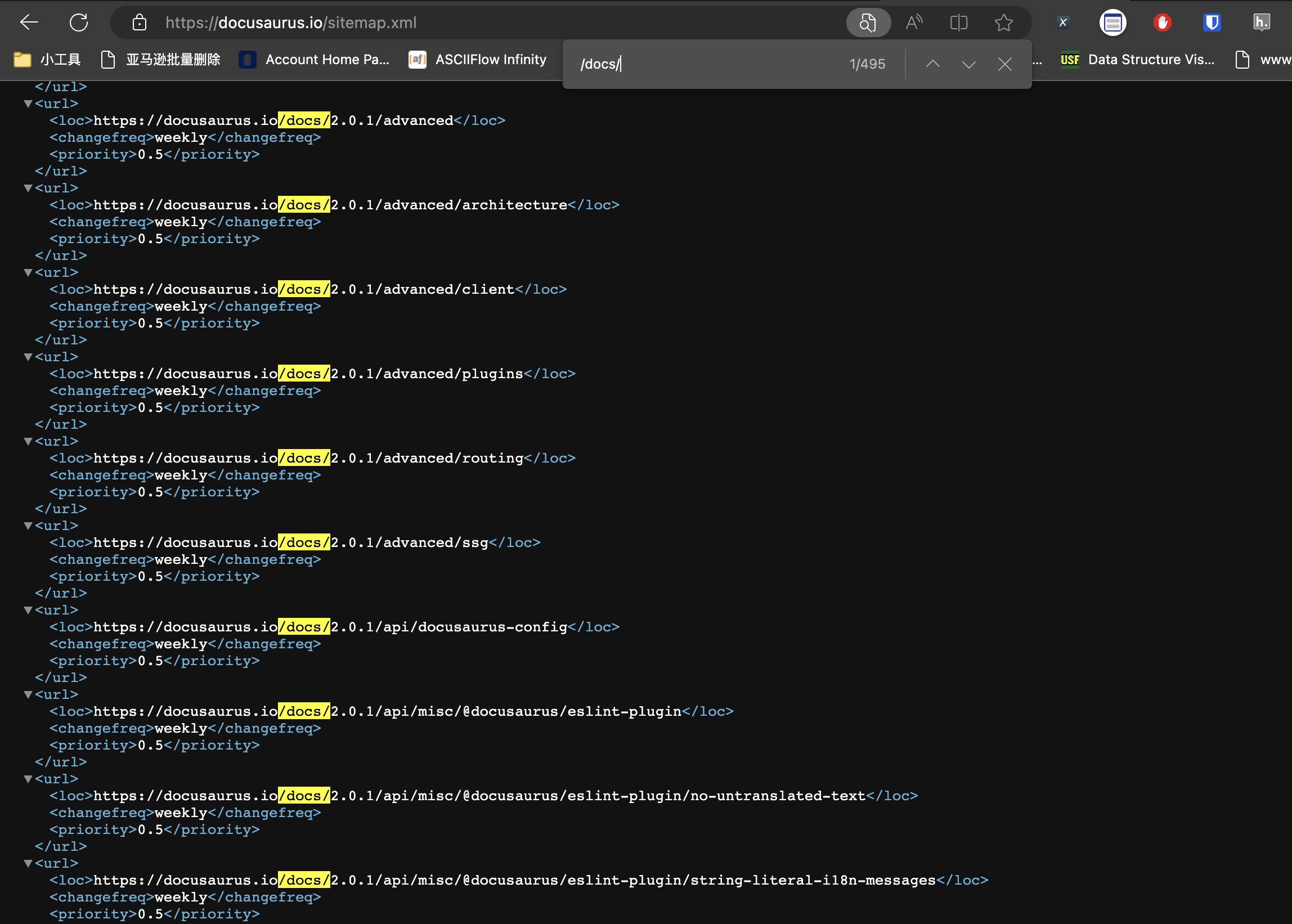
Since Docusaurus is a framework for generating documents, theoretically all documents generated using Docusaurus can obtain the URLs of all document pages through this method.
Similarly, for the Uniswap Docs website, add /sitemap.xml after the domain name, and then search for the keyword /concepts to find the URLs of all document pages, as shown in the following figure:
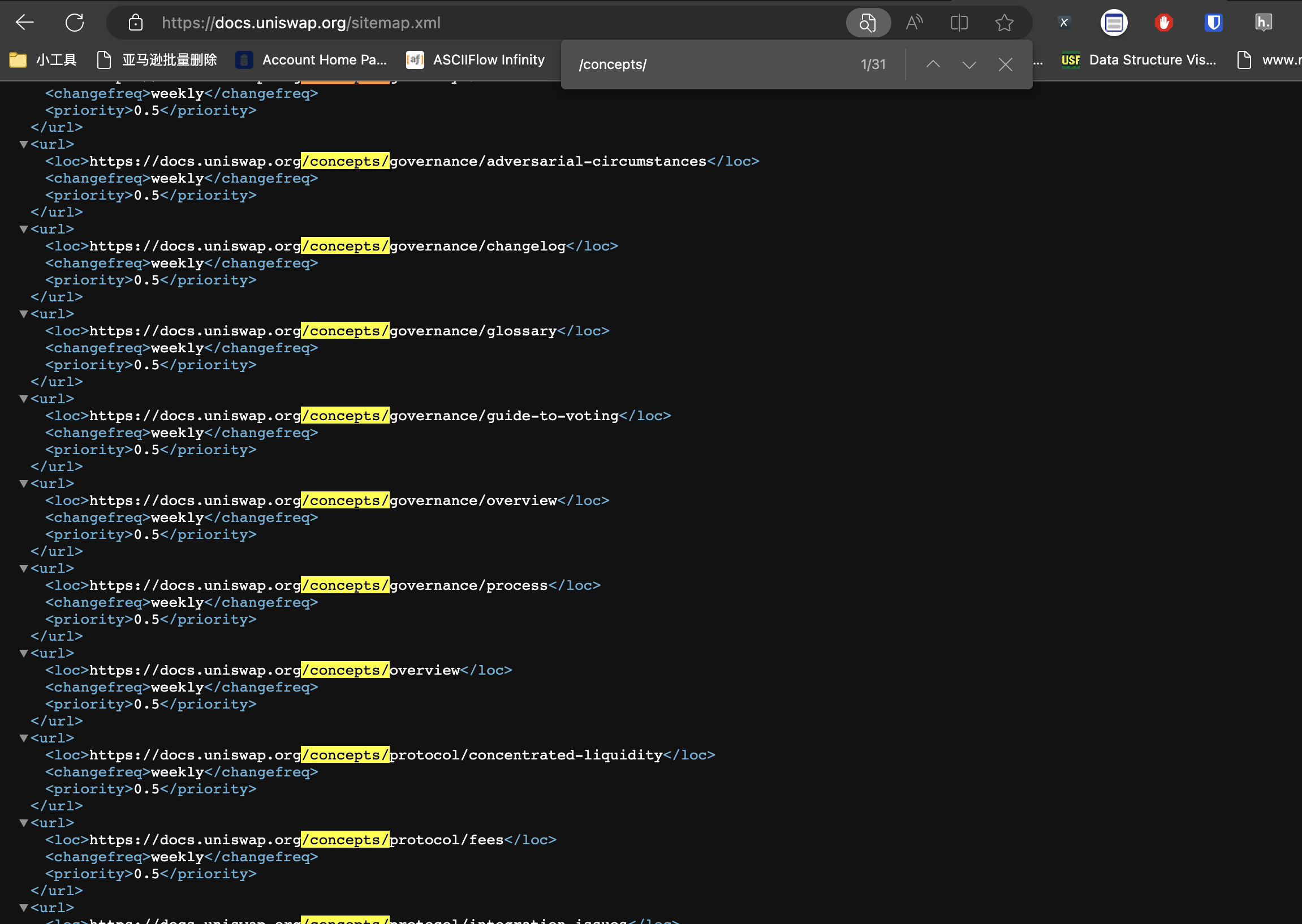
These two examples are to tell everyone that when you get a crawler task, don’t write XPath or capture packets as soon as you come up. Study the website first, sometimes you can reduce a lot of unnecessary workload.
This article is transferred from: https://www.kingname.info/2023/07/19/crawl-by-sitemap/
This site is only for collection, and the copyright belongs to the original author.