Original link: https://www.msra.cn/zh-cn/news/features/osdi-2022
Editor’s note: OSDI (Operating Systems Design and Implementation) is one of the top academic conferences in the field of computer systems, bringing together the forward-looking thinking of computer scientists around the world. The 16th OSDI will be held from July 11th to 13th, 2022. A total of 253 papers were submitted for this conference, 49 papers were accepted, and the acceptance rate was 19.4%. In this article, we will share 3 papers of Microsoft Research Asia included in OSDI 2022, hoping to help you understand the cutting-edge trends in the field of computer systems. Interested readers are welcome to read the original paper.
Roller: Fast and Efficient Deep Learning Operator Compiler

Paper link: https://ift.tt/L8goKdZ
Code address: https://ift.tt/8uvX54q
As the size of the model continues to grow, so does the demand for computing power in deep learning. Currently, deep learning hardware accelerators (such as GPU, TPU, etc.) mainly rely on operator acceleration libraries to support deep learning applications. However, with the emergence of new models and new hardware types, the industry has higher requirements for developing new operators quickly and efficiently. Tensor Compiler, as a new approach, provides the ability to automatically compile operators into corresponding accelerator kernel codes.
Currently, operators of deep learning models are usually implemented as multiple loop nested computations. In order to further improve the performance of this kind of operator program, researchers usually need to adjust the realized multi-loop calculation such as loop unrolling, merging, blocking, cache usage, and changing the degree of parallelism. This is essentially a combinatorial optimization problem, and the search space is huge, so mainstream operator compilers often have to use machine learning methods to find a better program implementation in this huge search space. This kind of search process often requires thousands or even tens of thousands of steps of exploration, so it often takes hours or even days to compile a model. This kind of problem is especially serious on new hardware and computationally intensive operators. Therefore, the current mainstream machine learning-based operator program optimization methods greatly affect the deployment efficiency of deep learning in practical scenarios. This situation is expected to worsen with the rapid growth in the size of deep learning models in recent years.
After compiling, optimizing and analyzing the performance of a large number of operators used in deep learning computing, Microsoft Research Asia, together with the University of Toronto and many other universities, found an interesting phenomenon: although there are thousands of optimization options for each operator However, the configuration of the program that can achieve the maximum performance is often matched with the hardware parameters, so that the hardware resources can be more fully utilized. Based on such observations, the researchers proposed a new operator compiler, Roller. In order to better match the hardware parameters, Roller modeled the calculation process of the operator as a “data processing pipeline” based on data blocks (tile), that is, data blocks of different sizes are moved from the multi-level memory structure to the computing core for processing and then processed one by one. level write back. In order to maximize the throughput of the entire pipeline, Roller requires that the settings of the data blocks in each stage must fully match the hardware parameter settings, such as the access width of the memory, the parallelism of the computing core, and so on. Such constraints not only ensure that the computing program can fully utilize the maximum performance of the hardware at each stage of the entire pipeline, but also simplifies the performance modeling of the operator program and greatly reduces the search space, thereby avoiding the need for practical applications. Numerous trials and performance measurements are time-consuming on hardware accelerators. Therefore, such a “white box” kernel program construction method can substantially reduce the operator compilation time.
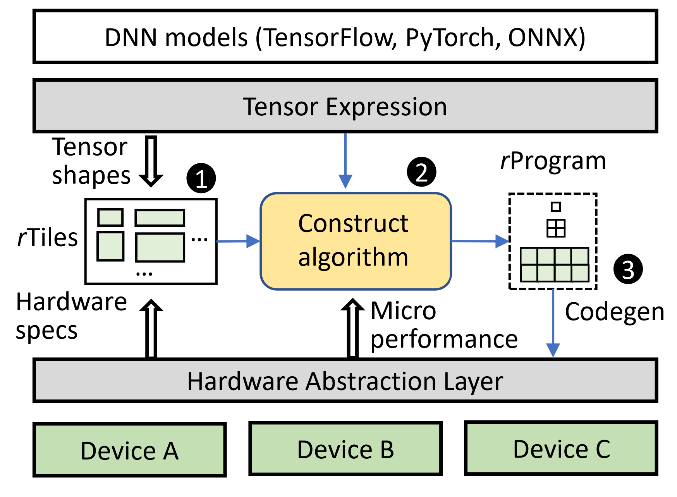
Figure 1: Architecture of the Roller Compiler
More importantly, the entire design of Roller is built on a common set of hardware abstractions, which can be well adapted to a variety of mainstream accelerator devices. Through experimental evaluations on NVIDIA GPUs, AMD GPUs, and Graphcore IPUs, researchers found that Roller’s compilation method can generate Similar performance, or even better kernel code. For example, after researchers compiled more than 100 operators commonly used in different types of models, 59.7% and 73.1% of the kernel codes generated by Roller were better than the operator libraries of NVIDIA and AMD, respectively. 54.6% and 58.8% of the codes outperform TVM or Ansor to generate programs on both GPUs. It is worth noting that the compilation time of Roller’s operators has also been reduced from the hour level to the second level, and the compilation time has been reduced by three orders of magnitude!
Researchers believe that systems like Roller can provide hardware accelerators with more efficient and fast software ecosystem support. For new hardware manufacturers lacking mature operator libraries, Roller also provides an opportunity to quickly generate operator libraries, thereby gaining an opportunity to catch up with leading hardware manufacturers at a faster rate. Roller’s “white-box” compilation approach also opens up new opportunities for rapid optimization and deployment of deep learning models for specific hardware. Microsoft Research Asia is further improving the deep learning model compilation stack based on Roller, and conducting more research on model optimization, scene deployment and new hardware support.
RESIN: A holistic approach to dealing with memory leaks in cloud services

Paper link: https://ift.tt/7rzEkQJ
The infrastructure of cloud computing contains many complex software components and therefore suffers from the problem of memory leaks. In cloud services, once a process leaks memory, a large number of machines deployed by it will run out of memory and innocent processes will be killed, which will eventually lead to performance degradation, crash and restart of virtual machines for a large number of users, which will seriously affect the user experience and may cause significant economic losses to users.
However, in cloud systems, the problem of memory leaks is difficult to deal with, and existing solutions are either inaccurate or incur high overhead. The reason is that, on the one hand, many memory leaks are triggered slowly in rare cases, so it is easy to evade testing and detection during development and deployment; on the other hand, after memory leaks are detected, related problems are difficult Offline reproducibility, which makes it difficult for developers to find the root cause of the leak. In order to solve the above problems, Microsoft Research Asia, together with the Microsoft Azure team and researchers from Hopkins University, proposed a holistic solution to deal with memory leaks in cloud services, RESIN.
RESIN takes a centralized approach, requiring no access to the component’s source code, nor extensive instrumentation or recompilation. RESIN uses a Monitor Agent for each host that collects memory usage data by leveraging underlying operating system capabilities, so it supports all components including the Kernel. The collected data is then loaded into a remote service for further data analysis, minimizing the overhead of the host. By aggregating data from different hosts, RESIN can run more sophisticated analyses to catch complex leaks. For the memory leak problem, RESIN is multi-level decomposition and processing. It first performs lightweight leak detection and triggers deeper dynamic checks when confirmation and diagnostics are required. This Divide-and-Conquer approach enables RESIN to simultaneously achieve low overhead, high accuracy, and scalability.
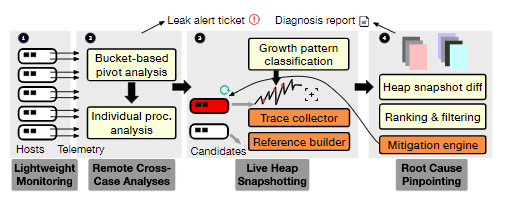
Figure 2: Workflow of the RESIN system
At present, RESIN has been running in Microsoft Azure for 3 years and has the advantages of high accuracy and low overhead. Virtual machine restarts due to insufficient memory are effectively reduced by a factor of 41.
SparTA: A sparse compilation framework for deep learning models based on tensor sparsity properties

Paper link: https://ift.tt/TWD3aF6
Project code address: https://ift.tt/4qtXhya
The address of the code to reproduce the results of the paper: https://ift.tt/bZVDqWy
With the rapid development of deep learning, the scale of deep learning models has shown an exponential growth trend. A single model has trillions of parameters, which far exceeds the growth rate of the computing power of hardware accelerators. At the same time, due to the limitations of computing power and power consumption, end-side devices have almost strict requirements on the size and inference delay of deep learning models. Therefore, exploring the sparsity in the deep learning model and effectively accelerating the sparse model have become the key factors for the development and implementation of the deep learning model. However, there are still many deficiencies in the system support of sparse models, which hinders the exploration of sparse models.
These deficiencies are embodied in (i) Since it is very difficult to construct efficient codes for special model sparsity patterns, it usually requires the deep participation of system programmers, and deep learning researchers usually use proxy metrics in the process of model sparsity research (Proxy metrics, Such as FLOPs, bit width) to estimate the acceleration effect. However, the proxy indicators cannot accurately reflect the acceleration effect brought by model sparseness, and the predicted effect is sometimes far from the actual situation; (ii) most of the current sparse optimization work only focuses on a single operator, ignoring a sparse operator The possible joint impact of the sparse operator in the entire deep learning model can transmit the sparseness to other operators in the model; (iii) The current sparse optimization scheme for a specific model is difficult to reuse, and it is difficult to integrate with other operators. Related technologies are combined and transferred to other deep learning models. For example, it is difficult to directly transfer the optimization techniques performed on the pruned operator and the quantized operator to an operator that is both pruned and quantized.
To address the above-mentioned challenges in model sparsification, Microsoft Research Asia proposed SparTA, an end-to-end compilation framework for optimizing sparse deep learning models. SparTA takes the sparse attribute of tensors in deep learning models (generated by pruning and quantization) as the core abstraction TeSA (Tensor with Sparsity Attribute) in the entire compilation framework, and builds a full set of compilation optimization techniques for sparse models around TeSA.
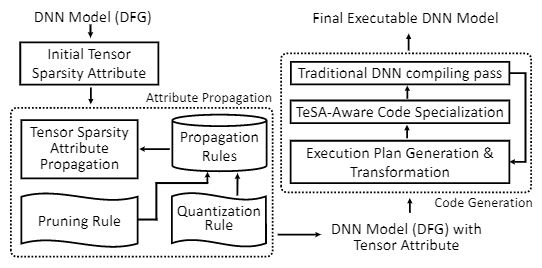
Figure 3: System Architecture of SparTA
When using SparTA, the user first uses TeSA to mark the sparsity pattern of some tensors in the deep learning model, and then optimizes the model end-to-end through the three core technologies proposed by SparTA: one is the tensor The propagation of the sparse attribute of the sparse attribute in the entire data flow graph is automatically completed by Tensor Algebra and Tensor Scrambling technology; the second is to optimize the transformation (Transformation) of the sparse operator, and transform it into a sparse style that is easier to accelerate and more computationally efficient. This transformation enables different optimization techniques to be organically combined; the third is to do code specialization for sparse tensors, hard-code the sparse style into the code of the operator, and delete the dead code (Dead Code), And use its proprietary hardware (like sparse tensor core) for a given accelerator specialization.
Through comprehensive testing, SparTA demonstrated an average speedup of 8.4 times compared to existing tools. SparTA can not only optimize dense models after sparseness, but can also be used to speed up large pretrained models that are designed with a specific sparsity pattern from the outset. In this regard, SparTA has been used to optimize the NUWA pretrained video generation model developed by Microsoft Research Asia. SparTA achieves more than 2x speedup for the 3DNA sparse attention mechanism proposed in the NUWA model. Microsoft Research Asia is currently reorganizing and optimizing the code of SparTA to improve ease of use, and will open source as soon as possible to promote the research and practicality of deep learning model sparsity.
This article is reprinted from: https://www.msra.cn/zh-cn/news/features/osdi-2022
This site is for inclusion only, and the copyright belongs to the original author.