Original link: https://jyzhu.top/Reading-3D-Photography-using-Context-aware-Layered-Depth-Inpainting/
Paper address: https://shihmengli.github.io/3D-Photo-Inpainting
Authors: Meng-Li Shih , Shih-Yang Su , Johannes Kopf , Jia-Bin Huang
Posted: CVPR2020
Link: https://github.com/vt-vl-lab/3d-photo-inpainting
Why:
The previous method of 3Dizing photos will fill the new pixel area that appears after the perspective changes with a very blurred background; this method mainly uses the inpainting method to improve the effect of new background generation.
 image-20221007084129382
image-20221007084129382
What:
- The task is 3D photography, the image is 3D, and a 2D + depth information RGB-D image is converted into a 3D style image.
- Photos taken by today’s multi-lens smartphones provide depth information. If not, other models can also be used to predict depth.
- Use layered depth image (Layered Depth Image) to represent the image: can explicitly represent the connectivity between pixels. Compared with ordinary 2D images, pixels can be divided into multiple layers to represent, and there can be overlapping pixels of different layers at the same coordinate.
- A learning-based inpainting method is proposed to fill the pixels in the overlapping area, so that the new background that appears when the perspective of the 3D image changes works well.
How:
It’s a very clear process:
-
The input is a single RGB-D image. D is depth. Generally, photos taken by multi-lens smartphones can provide depth information; if not, use other models to predict depth, such as MegaDepth, MiDas, and Kinect depth sensor
-
Convert the input image into a Layered Depth Image. Each pixel in the LDI saves color and depth information, as well as neighbor pixels in four directions: up, down, left, and right. There can be overlapping pixels of different depths at the same coordinate.
-
Image Preprocessing: Detecting Depth Disjoint Edges
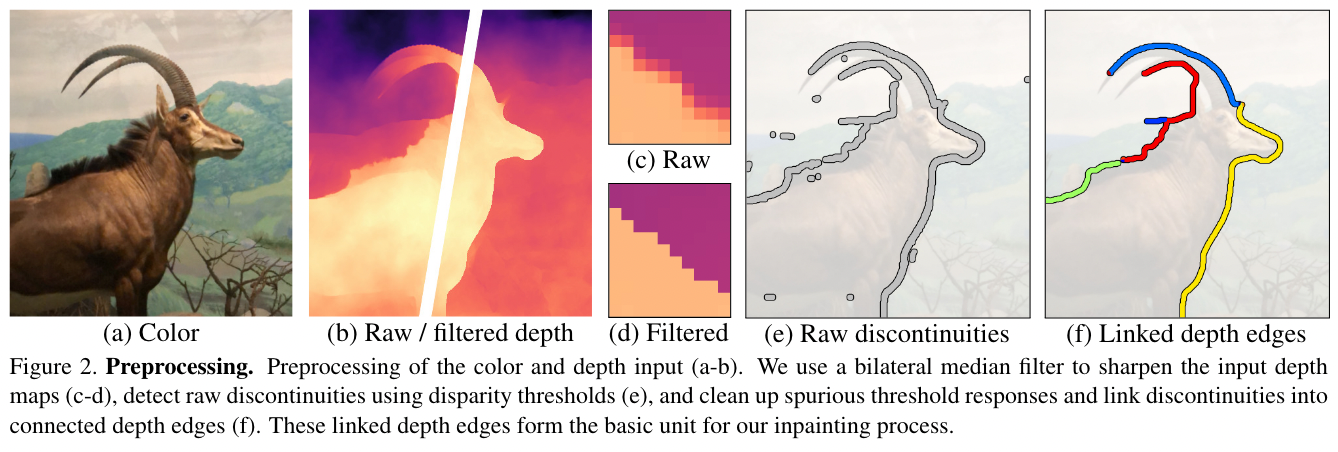 image-20221007090910332
image-20221007090910332Use filter to filter the depth edges sharper, then clean up some discontinuous edges, and finally divide different depth edges according to connectivity (as shown in Figure 2 (f), different colors represent different depth edges).
-
For each depth edge, cut the pixels in the LDI image, and expand some pixels in the background layer to generate the expanded area
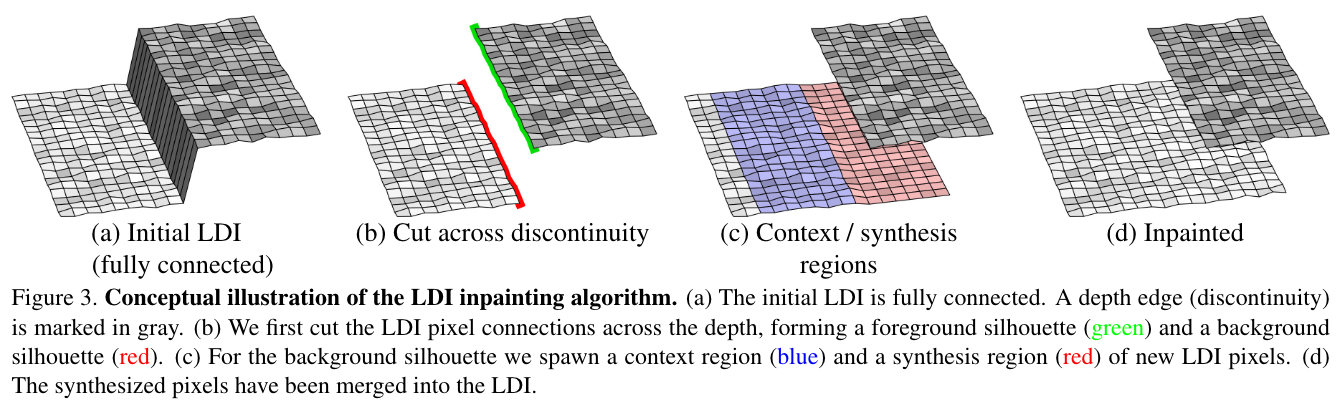 image-20221007091217942
image-20221007091217942-
Find a depth edge and cut the pixels of the two layers
-
For the background layer, the flood-fill like algorithm is used to iteratively select a certain known area as the context region, and expand a certain unknown area as the synthesis region
-
Generating the depth and color of an unknown synthesis region using a known context region: using a learning-based inpainting method
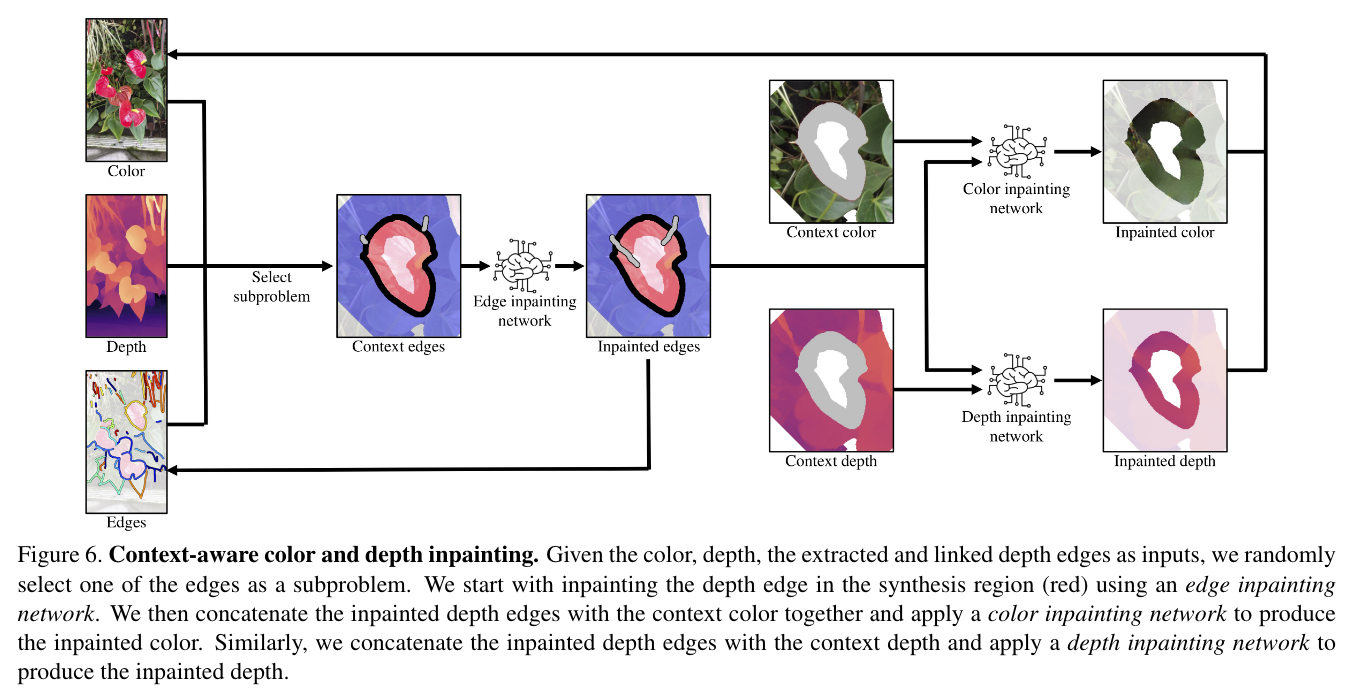 image-20221007091716266
image-20221007091716266In this method, the most important thing is to predict the depth edges before predicting the color and depth, and then add the edges information to better predict the color and depth.
-
Fusion of the generated pixels back to the LDI image
-
This article is reprinted from: https://jyzhu.top/Reading-3D-Photography-using-Context-aware-Layered-Depth-Inpainting/
This site is for inclusion only, and the copyright belongs to the original author.