
Welcome to the WeChat subscription number of “Sina Technology”: techsina
Text | Fish and Sheep Alex
Source: Qubit
The painter poked and poked on the canvas, forming the unique strokes of hand-painted works.
Which documentary do you think this is from?
No, No, No!
Every frame in the video is generated by AI.
Or you tell it to come to a “close-up of the brush on the canvas”, and it can directly complete the picture.
Not only can you create a brush out of nothing, but it is not impossible to drink water by pressing the horse’s head.
The same sentence “horses drink water”, this AI throws out this picture:

Good guy, this is the rhythm that you can really rely on one mouth to shoot videos in the future…
Yes, that sentence made the Text to Image of AI drawing become popular, and the researchers of Meta AI here have brought a super-evolution to the generation AI.
This time, I can really “make a video with my mouth”:
The AI is called Make-A-Video, and it directly generates ascension dynamics from the static generated by DALL·E and Stable Diffusion.
Give it a few words or a few lines of text, and you can generate video images that don’t actually exist in this world, and there are still many styles to master.
Not only the documentary style can be held, but the whole point of sci-fi effect is no problem.

Mixing the two styles, the picture of the robot dancing in Times Square doesn’t seem to be inconsistent.

Literary and fresh animation style, it seems that Make-A-Video has also grasped it.

After such a wave of operations, it really confused many netizens, and even the comments were simplified to three letters:
And the boss LeCun said meaningfully: What should come will always come.

After all, when it comes to generating a video in one sentence, many people in the industry felt that it was “coming soon”. It’s just that Meta’s move is really fast:
9 months sooner than I thought.
Some people even said: I have been a little unable to adapt to the evolution speed of AI…

Text-to-image generation model hyper-evolution
You might think Make-A-Video is a video version of DALL·E.
Actually, that’s about it

As mentioned earlier, Make-A-Video is a hyper-evolution of the text-to-image generation (T2I) model, because the first step in this AI work actually relies on text to generate images.
From the data point of view, it is the training data of static image generation models such as DALL·E, which is paired text-image data.
Although Make-A-Video finally generates video, it does not use paired text-video data for training, but still relies on text-image pair data to let AI learn to reproduce pictures according to text.
Video data is of course also involved, but mostly individual video clips are used to teach AI real-world movement patterns.
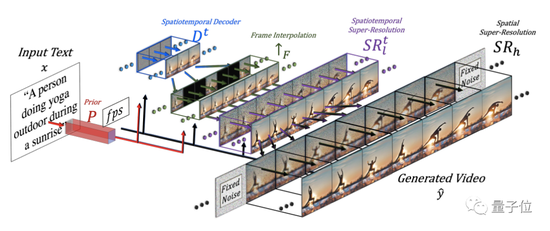
Specific to the model architecture, Make-A-Video is mainly composed of three parts:
-
Text image generation model P
-
Spatiotemporal convolutional layers and attention layers
-
Frame interpolation network to improve frame rate and two superdivision networks to improve image quality
The working process of the entire model is the sauce:
First, image embeddings are generated from the input text.
Then, the decoder Dt generates 16 frames of 64×64 RGB images.
The interpolation network ↑F interpolates the preliminary results to achieve the desired frame rate.
Next, the first super-resolution network will increase the resolution of the picture to 256 × 256. The second super-division network continues to optimize, further improving the picture quality to 768×768.
Based on this principle, Make-A-Video can not only generate video based on text, but also have the following capabilities.
Convert still image to video:

Generate a video based on the two pictures before and after:

Generate a new video based on the original video:

Refresh text video generation model SOTA
In fact, Meta’s Make-A-Video is not the first attempt at text-to-video (T2V).
For example, Tsinghua University and Zhiyuan launched their self-developed “one sentence generation video” AI: CogVideo earlier this year, and this is currently the only open source T2V model.
Earlier, GODIVA and Microsoft’s “Nuwa” also realized the generation of videos based on text descriptions.
This time around, though, Make-A-Video has significantly improved the build quality.
The experimental results on the MSR-VTT dataset show that Make-A-Video significantly refreshes SOTA in both FID (13.17) and CLIPSIM (0.3049) metrics.

In addition, the Meta AI team also used Imagen’s DrawBench for human subjective evaluation.
They invited testers to experience Make-A-Video for themselves and subjectively evaluate the logical correspondence between video and text.
The results show that Make-A-Video outperforms the other two methods in both quality and fidelity.

One More Thing
Interestingly, when Meta released the new AI, it also seemed to kick off the T2V model racing.
StabilityAI, the parent company of Stable Diffusion, couldn’t sit still. Founder and CEO Emad said:
We’re going to release a better model than Make-A-Video, the kind that everyone can use!
Just a few days ago, a related paper Phenaki appeared on the ICLR website.
The resulting effect is as follows:
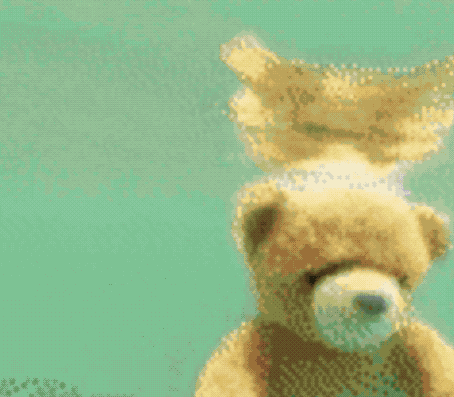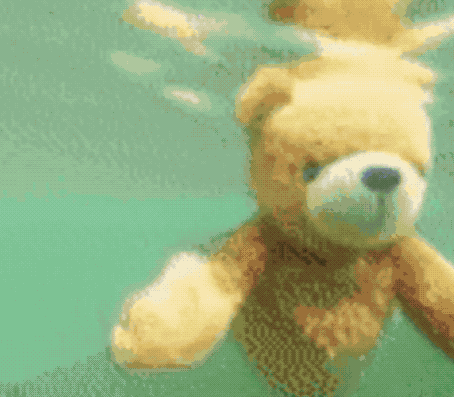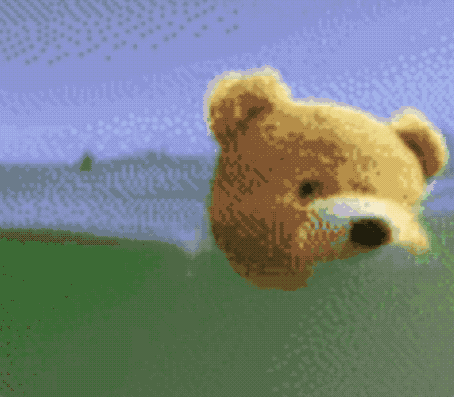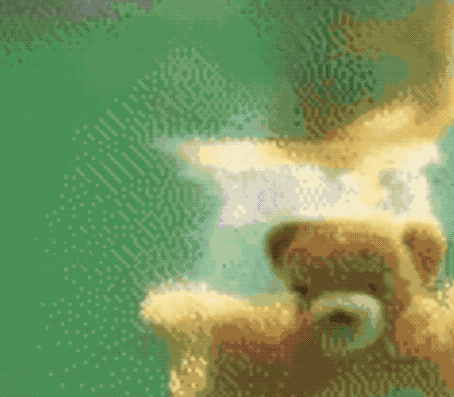
By the way, although Make-A-Video has not been released yet, Meta AI officials also said that they are going to launch a Demo so that everyone can actually experience it, and interested friends can squat~

(Disclaimer: This article only represents the author’s point of view and does not represent the position of Sina.com.)
This article is reproduced from: http://finance.sina.com.cn/tech/csj/2022-09-30/doc-imqqsmrp1078189.shtml
This site is for inclusion only, and the copyright belongs to the original author.