Original link: https://mazhuang.org/2023/08/27/cache-design/
When discussing interface performance issues with colleagues before, I heard him introduce a cache design idea. I think it is good, and I will make a record for future reference.
Scenes
Suppose you have an interface of the form:
GET /api?keys={key1,key2,key3,...}&types={1,2,3,...}
Among them, keys is a list of business primary keys, and types is the type of information you want to get.
Requesting this interface needs to return the business object list corresponding to the business primary key list, and the object needs to contain the specified type of information.
There are many possible values of the business primary key, on the order of tens of millions, and the value range of type is 1-10, which can be combined arbitrarily. Each type corresponds to 1-N tables in the database, indicating:
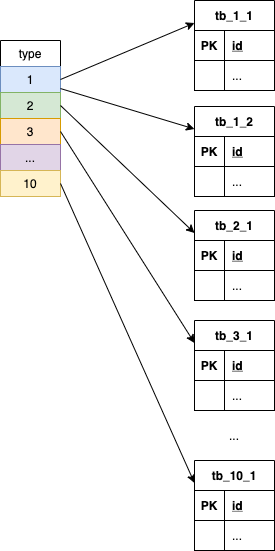
Now imagine that this interface has encountered a performance bottleneck and plans to add a Redis cache to improve the response speed. How should it be designed?
Design ideas
Option One:
The simplest and rude method is to directly use all the parameters of the request as the cache key, and the return content of the request is value.
Option II:
If you think about it for a while, you may think of the good idea I mentioned at the beginning of the article:
- Use
业务主键:表名is used as the cache key, and the record corresponding to the business primary key in the table name is used as the value; - When querying, first obtain all combinations such as
key1:tb_1_1andkey1:tb_1_2according to the query parameter keys and the table corresponding to types, and use the mget command of Redis to fetch all the information in the cache in batches, and the remaining ones that do not hit, Query the results in the database in batches and put them in the cache; - When the data of a certain table is updated, it is only necessary to refresh or invalidate the cache
涉及业务主键:该表名.
summary
When evaluating and choosing between the above two options, consider several aspects:
- Cache hit rate;
- The number of caches and the size of the occupied space;
- Is it convenient to refresh the cache;
After a little thought and calculation, you will find the advantage of option two in this scenario.
In addition, it is necessary to evaluate the granularity and level of the appropriate cache data according to the actual business scenario, such as the complexity of the business object, the ratio of the number of reads and writes, etc., which correspond to a certain level of combined business objects (the cache value corresponds to the storage + part Logic), or the most basic database table/field (storage belongs to storage, logic belongs to logic).
This article is transferred from: https://mazhuang.org/2023/08/27/cache-design/
This site is only for collection, and the copyright belongs to the original author.