Original link: https://codechina.org/2022/12/standford-cs224n-dl-nlp-1/
Course video address https://www.youtube.com/watch?v=rmVRLeJRkl4&list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ
What is NLP?
NLP is natural language processing , which basically solves the problem of how computers understand human language. Practical applications include text wins, text classification, machine translation, and even the recently popular ChatGPT and other requirements are all completed by NLP of.
Before and after the rise of deep learning, I have studied NLP more systematically. The more traditional Chinese NLP problems are the problems just now plus a word segmentation problem. I have done a search service before, word segmentation is a problem we are very concerned about.
When Word2vec became popular, I didn’t play NLP much.
Recently, I have become interested in re-learning NLP under deep learning, mainly caused by the fire of ChatGPT and its current level.
The first lesson mainly introduces the concept of Word Vectors.
What impressed me the most was a sentence quoted by the teacher, John Rupert Firth, he is a British linguist and the founder of the London School.
You shall know a word by the company it keeps.
John Rupert Firth 1957:11
This sentence means that to understand a word, you should see what other words it appears with. In other words, understanding a word depends on its context, the context in which it often appears.
In fact, traditional NLP also treats a word as a vector, but this is a sparse vector. For example, if I have 10,000 corpus, then we will buy a word and express it as a 10,000-dimensional vector. Whether the dimension is 0 or 1 depends on whether the word appears in the corpus.
For example, the following representation means that motel appears in the 11th corpus, and hotel appears in the 9th corpus.

This method actually solves many NLP problems under traditional thinking.
But the beginning of NLP under deep learning is to understand the meaning of a word with the words that appear before and after it, forming Word Vectors. Like John Rupert Firth said.
John Rupert Firth said this in 1957, but in recent years, Word Vectors and deep learning have really been able to turn this understanding into a computer data structure and something that can be calculated. This reminds me that we can have a lot of inspiration, but whether these things can contribute to mankind requires technology to reach a certain level to turn our inspiration into reality, or release huge energy, or simply tell us these fundamentals. Just wrong. It’s not enough to have these inspirations alone.
In addition, this sentence of John Rupert Firth, I think it is actually very close to the idea of learning a language that I advocate . You memorize words, and the explanation you memorize in a dictionary is actually a mechanical understanding of words. In fact, our understanding of most of the vocabulary of our mother tongue is understood in use and in the context of its use. Sometimes we may not know the exact meaning of a word in the dictionary, but because it often appears in a certain context, we can naturally gain an understanding of the word.
the code
The teacher provided the following Python code,
import numpy as np %matplotlib inline import matplotlib as plt plt.style.use('ggplot') from sklearn.decomposition import PCA import gensim.downloader as api from gensim.models import KeyedVectors model = api.load("glove-wiki-gigaword-100")
This code, uses Gensim(1). Gensim is not a deep learning cry, but it includes the implementation of word vector. The data uses Stanford’s own GloVe (2) word vector data.
After loading the model, you can use the model to observe and study the relationship between words. Relatively simple, we can see what is closely related to bread:
model.most_similar(["bread"] [('flour', 0.7654520869255066), ('baked', 0.7607272863388062), ('cake', 0.7605516910552979), ('loaf', 0.7457114458084106), ('toast', 0.7397798895835876), ('cheese', 0.7374635338783264), ('potato', 0.7367483973503113), ('butter', 0.7279618978500366), ('potatoes', 0.7085272669792175), ('pasta', 0.7071877717971802)]
These output words are flour – flour, baked – baked, cake – cake loaf – a loaf of bread, toast – toasted bread, cheese – cheese, potato – potato, butter – butter, potatoes – potato, pasta – noodles.
We can also see what is closely related to coffee:
model.most_similar(["coffee"] [('tea', 0.77326899766922), ('drinks', 0.7287518978118896), ('beer', 0.7253385186195374), ('cocoa', 0.7026591300964355), ('wine', 0.7002726793289185), ('drink', 0.6990923881530762), ('corn', 0.6825440526008606), ('sugar', 0.6775094270706177), ('bread', 0.6727856993675232), ('fruit', 0.667149007320404)]
However, because these are word vector word vectors, vectors can be manipulated, and adding and subtracting in space can get very interesting results. The example below is
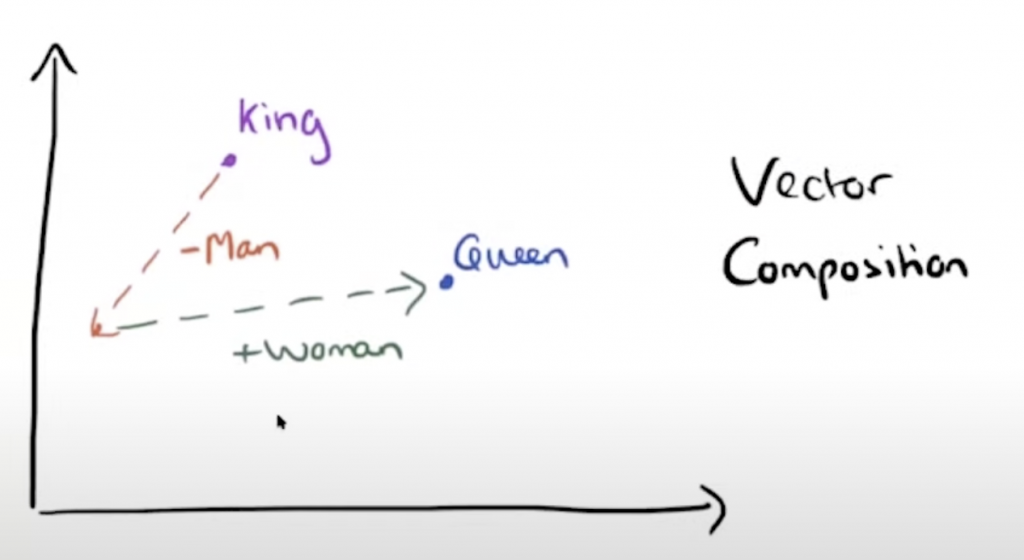
We know that the king’s vector is related to the man’s vector. If we subtract a man from the king’s vector to get a new starting point, and then add a woman, the result may be the result of guessen. code show as below:
model.most_similar(positive=["king","woman"],negative=["man"]) [('queen', 0.7698541283607483), ('monarch', 0.6843380331993103), ('throne', 0.6755736470222473), ('daughter', 0.6594556570053101), ('princess', 0.6520534157752991), ('prince', 0.6517034769058228), ('elizabeth', 0.6464518308639526), ('mother', 0.631171703338623), ('emperor', 0.6106470823287964), ('wife', 0.6098655462265015)]
Putting two words in the positive parameter of most_similar, king and woman is equal to the addition of these two vectors, and putting negative into man is equal to subtracting man from the result vector. As a result, the first one is the queen.
We can continue to do similar research or games, they are all fun.
model.most_similar(positive=["coffee","china"],negative=["usa"]) [('tea', 0.6365849375724792), ('fruit', 0.6253646016120911), ('chinese', 0.5799036622047424), ('food', 0.5783675312995911), ('grain', 0.577540397644043), ('vegetables', 0.5578237771987915), ('prices', 0.5492344498634338), ('fruits', 0.5417575836181641), ('export', 0.5401189923286438), ('vegetable', 0.5384897589683533)]
model.most_similar(positive=["king","china"],negative=["england"]) [('jiang', 0.6718781590461731), ('chinese', 0.657663106918335), ('wu', 0.6562906503677368), ('li', 0.6415701508522034), ('zhu', 0.6260422468185425), ('liu', 0.6097914576530457), ('beijing', 0.6078009605407715), ('qin', 0.6032587289810181), ('zemin', 0.6009712815284729), ('chen', 0.5993086099624634)]
model.most_similar(positive=["president","china"],negative=["usa"]) [('jiang', 0.7173388600349426), ('hu', 0.7164437770843506), ('government', 0.6859283447265625), ('jintao', 0.6816513538360596), ('zemin', 0.6663808822631836), ('chinese', 0.6555445194244385), ('chen', 0.6504189372062683), ('beijing', 0.6466312408447266), ('taiwan', 0.627478837966919), ('administration', 0.6196395754814148)]
Notes:
- Gensim is an open source Python library for Natural Language Processing (NLP). It provides tools for text similarity analysis, topic modeling, text transformation, and clustering. Gensim borrows from many effective NLP techniques, including Latent Semantic Analysis (LSA), Latent Dirichlet Allocation (LDA), and Random Projections (RP).
The goal of Gensim is to provide users with an easy-to-use tool to help users perform efficient NLP tasks on text data. Gensim uses a simple command line interface that allows users to easily process large text collections and implement complex NLP tasks with a small amount of code.
- GloVe (Global Vectors for Word Representation) is a technique for word embedding. It works by counting the number of co-occurrences of each word with other words in the corpus, and then mapping words to vectors (i.e. word embeddings) in a low-dimensional space by means of least squares.
The strength of GloVe is its ability to preserve the relationship between words, which makes it well suited for Natural Language Processing (NLP) tasks such as text classification, machine translation, etc. It is also relatively general, can be applied to multiple languages, and is computationally efficient. GloVe is a popular word embedding technique and has been widely used in the field of natural language processing. It can provide effective and more general word embeddings and is the first choice of many natural language processing systems.
Stanford CS224N-NLP study notes under deep learning (updated from time to time) first appeared on Tinyfool’s personal website .
This article is transferred from: https://codechina.org/2022/12/standford-cs224n-dl-nlp-1/
This site is only for collection, and the copyright belongs to the original author.