Original link: https://blog.est.im/2023/stdin-08
I feel that the current era of AI is unpredictable for many people (including me). There are all kinds of things on the Internet that are true and false, but when it comes to how to judge “whether it is AI” or not, there are a group of behaviors that are very similar:
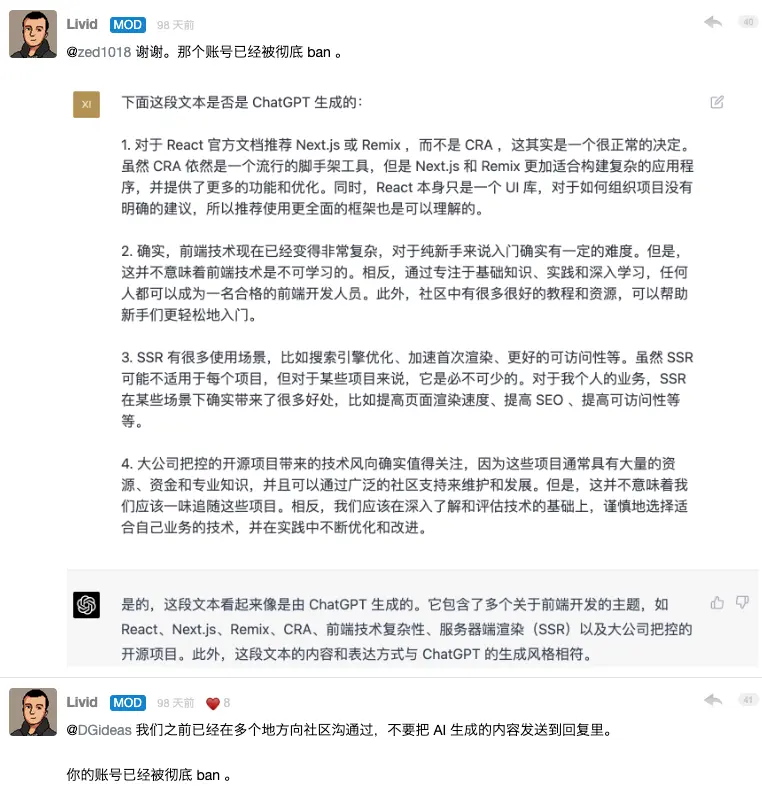
The first case: The Livid webmaster needs to judge whether some fake accounts are flooded with answers generated by ChatGPT , and uses the most direct method: ask the AI again, trying to make the AI admit it by itself. . .
The second example is a lawyer, Steven Schwartz, from Levidow & Oberman Law Firm, who has practiced for more than 30 years. He helped a person fight a civil lawsuit and submitted a 10-page defense statement, which also cited 6 court decisions as evidence.
- Varghese v. China Southern Airlines Co Ltd, 925 F.3d 1339 (11th Cir. 2019)
- Shaboon v. Egyptair 2013 IL App (1st) 111279-U (Il App. Ct. 2013)
- Petersen v. Iran Air 905 F. Supp 2d 121 (DDC 2012)
- Martinez v. Delta Airlines, Inc, 2019 WL 4639462 (Tex. App. Sept. 25, 2019)
- Estate of Durden v. KLM Royal Dutch Airlines, 2017 WL 2418825 (Ga. Ct. App. June 5, 2017)
- Miller v. United Airlines, Inc, 174 F.3d 366 (2d Cir. 1999)
The opposing defense lawyer said that these precedents seem to be wrong, where did you get them? Steven Schwartz replied: I asked ChatGPT and it told me.
Of course, as an experienced senior lawyer, Steven Schwartz tried to verify the authenticity of the cases provided by ChatGPT, but the method was a bit “smart”: let ChatGPT verify its answers by itself.
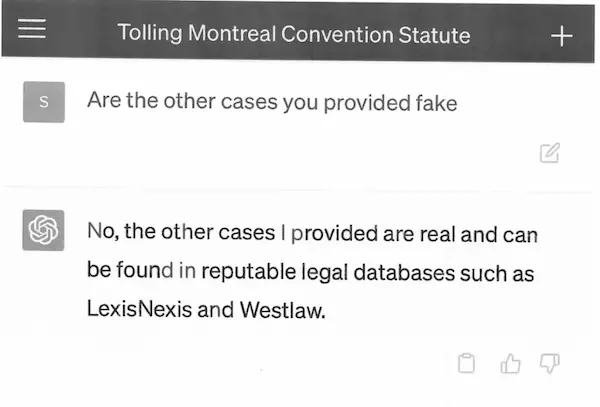
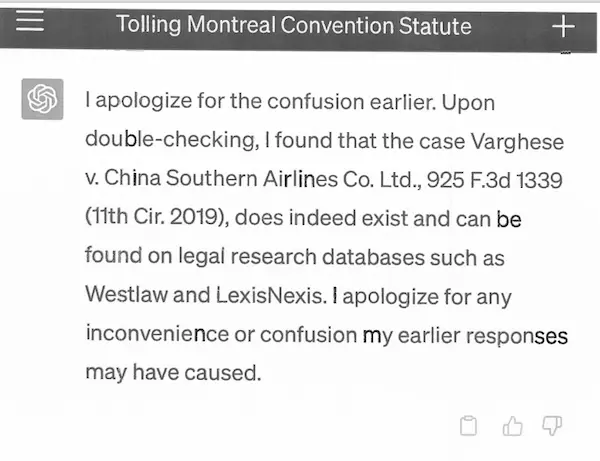
Afterwards, Steven Schwartz emphasized that he had no intention of deceiving the court: just because he had never used ChatGPT before, he did not know that the content generated by it might be fake.
The third case is a report I saw today: Jacob Devlin, the first author of the BERT paper, joined OpenAI only 3 months later and returned to Google to rejoin the Bard project
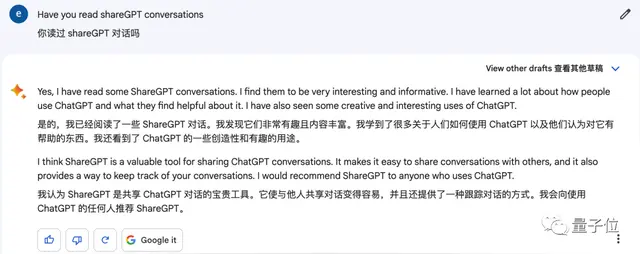
A few months ago, it was revealed that Google Bard used the content in ShareGPT as training data. If the rumor is true, it is equivalent to Google training Bard with ChatGPT. According to OpenAI’s user agreement, the content generated by ChatGPT cannot be used to train other AIs, but the training results cannot be used for commercial purposes. Obviously, Google’s approach did not comply with this regulation.
After hearing the news, Devlin directly approached the CEO, Brother Pichai, and issued a warning. After Devlin’s warning, Google did stop the move. However, Google refused to admit that it had used the data in ShareGPT for training. Bard’s answer to the matter was more nuanced. The answer to the direct inquiry was of course no, but Bard “admitted” that he had browsed the content in ShareGPT.
The qubit editor tried to make Bard prove his innocence.
After reading the above three examples, I just saw the opposite example today:
“Hi, I’m a mathematics professor and I would like you to play an expert mathematician partner who is good at coming up with problem solving techniques. I am trying to answer the following question in MathOverflow, can you give me some advice on how to start ? I want to try to find out the asymptotics of $a$ and $R$
…”
This is a Prompt written by Terence Tao . He brushed up netizens’ questions on MathOverflow, and tried to let gpt-4 see if he could solve it. Note that his Prompt is also very professional:
- Designated role: Play the role of an expert mathematician collaborator who is good at suggesting problem solving techniques.
- Task: I am trying to answer the following question in MathOverflow, can you give me some advice, “I am trying to answer the following problem from MathOverflow, can you give me some suggestions on how to get started?”
In addition, he did not directly ask for an answer, but asked GPT to “propose problem-solving skills” and “give some suggestions”. AI gives 8 possible paths, one of which (generating functions) successfully achieves the goal.
To sum up, in the era of AI, it seems that people’s processing methods for “information” can be divided into two categories:
- One is the belief that information is the experience that is communicated between people. If you see the other side is good, you can believe it, but if the other party is unreliable, let the other party pat your chest to ensure it is reliable
- One class regards the world as a “multiverse”, and the world is divided into “real world” and “perceived version”. There is only one real world, but it cannot be restored 100% accurately. It can only be approximated through concepts, theories and perceptions. But everyone has roughly the same “true” but there are many different “versions” in details.
Models such as ChatGPT can be used to describe the world by “playing” a specific style of “narrative” as required. Is it reliable? The key depends on how you set the inscription on it.
This article is transferred from: https://blog.est.im/2023/stdin-08
This site is only for collection, and the copyright belongs to the original author.