surroundings
- window 10 64bit
- yolo v5 v6.2
- torch1.7.1+cuda101
- tensorflow-gpu 2.9.1
foreword
The previous article uses NCNN to run YOLOv5 target detection on Android and yolov5 target detection on Android. Using torchscript , we used ncnn and torchscript to deploy YOLOv5 to android phones. In this article, we will use another method, tflite , for deployment, so use whichever you like.
Specific steps
The latest v6.2 version code is used here, using the official yolo v5s.pt model. To use your own data set, you need to train yourself first. For the training steps, please refer to the link at the end of the article.
The model conversion process also requires the tensorflow environment, install it
pip instal tensorflow-gpu
Then you can use the export.py script to convert, the command is as follows
python export.py --weights yolo v5s.pt --include tflite --img 416
The parameter weights specifies .pt model, the --img --include specifies the image size
(pytorch1.7) PS D:\Downloads\ yolo v5-6.2> python export.py --weights yolo v5s.pt --include tflite --img 416 export: data=D:\Downloads\yolov5-6.2\data\coco128.yaml, weights=['yolov5s.pt'], imgsz=[416], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['tflite'] YOLOv5 2022-8-17 Python-3.8.8 torch-1.7.1+cu110 CPU Fusing layers... YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients PyTorch: starting from yolov5s.pt with output shape (1, 10647, 85) (14.1 MB) TensorFlow SavedModel: starting export with tensorflow 2.9.1... from n params module arguments 2022-08-23 15:19:30.085029: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected 2022-08-23 15:19:30.091351: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic information for host: USERMIC-Q2OSJCT 2022-08-23 15:19:30.092531: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:176] hostname: USERMIC-Q2OSJCT 2022-08-23 15:19:30.094067: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2 To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2] 1 -1 1 18560 models.common.Conv [32, 64, 3, 2] 2 -1 1 18816 models.common.C3 [64, 64, 1] 3 -1 1 73984 models.common.Conv [64, 128, 3, 2] 4 -1 1 115712 models.common.C3 [128, 128, 2] 5 -1 1 295424 models.common.Conv [128, 256, 3, 2] 6 -1 1 625152 models.common.C3 [256, 256, 3] 7 -1 1 1180672 models.common.Conv [256, 512, 3, 2] 8 -1 1 1182720 models.common.C3 [512, 512, 1] 9 -1 1 656896 models.common.SPPF [512, 512, 5] 10 -1 1 131584 models.common.Conv [512, 256, 1, 1] 11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 12 [-1, 6] 1 0 models.common.Concat [1] 13 -1 1 361984 models.common.C3 [512, 256, 1, False] 14 -1 1 33024 models.common.Conv [256, 128, 1, 1] 15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 16 [-1, 4] 1 0 models.common.Concat [1] 17 -1 1 90880 models.common.C3 [256, 128, 1, False] 18 -1 1 147712 models.common.Conv [128, 128, 3, 2] 19 [-1, 14] 1 0 models.common.Concat [1] 20 -1 1 296448 models.common.C3 [256, 256, 1, False] 21 -1 1 590336 models.common.Conv [256, 256, 3, 2] 22 [-1, 10] 1 0 models.common.Concat [1] 23 -1 1 1182720 models.common.C3 [512, 512, 1, False] 24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512], [416, 416]] Model: "model" __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_1 (InputLayer) [(1, 416, 416, 3)] 0 [] tf_conv (TFConv) (1, 208, 208, 32) 3488 ['input_1[0][0]'] tf_conv_1 (TFConv) (1, 104, 104, 64) 18496 ['tf_conv[0][0]'] tfc3 (TFC3) (1, 104, 104, 64) 18624 ['tf_conv_1[0][0]'] tf_conv_7 (TFConv) (1, 52, 52, 128) 73856 ['tfc3[0][0]'] tfc3_1 (TFC3) (1, 52, 52, 128) 115200 ['tf_conv_7[0][0]'] tf_conv_15 (TFConv) (1, 26, 26, 256) 295168 ['tfc3_1[0][0]'] tfc3_2 (TFC3) (1, 26, 26, 256) 623872 ['tf_conv_15[0][0]'] tf_conv_25 (TFConv) (1, 13, 13, 512) 1180160 ['tfc3_2[0][0]'] tfc3_3 (TFC3) (1, 13, 13, 512) 1181184 ['tf_conv_25[0][0]'] tfsppf (TFSPPF) (1, 13, 13, 512) 656128 ['tfc3_3[0][0]'] tf_conv_33 (TFConv) (1, 13, 13, 256) 131328 ['tfsppf[0][0]'] tf_upsample (TFUpsample) (1, 26, 26, 256) 0 ['tf_conv_33[0][0]'] tf_concat (TFConcat) (1, 26, 26, 512) 0 ['tf_upsample[0][0]', 'tfc3_2[0][0]'] tfc3_4 (TFC3) (1, 26, 26, 256) 361216 ['tf_concat[0][0]'] tf_conv_39 (TFConv) (1, 26, 26, 128) 32896 ['tfc3_4[0][0]'] tf_upsample_1 (TFUpsample) (1, 52, 52, 128) 0 ['tf_conv_39[0][0]'] tf_concat_1 (TFConcat) (1, 52, 52, 256) 0 ['tf_upsample_1[0][0]', 'tfc3_1[0][0]'] tfc3_5 (TFC3) (1, 52, 52, 128) 90496 ['tf_concat_1[0][0]'] tf_conv_45 (TFConv) (1, 26, 26, 128) 147584 ['tfc3_5[0][0]'] tf_concat_2 (TFConcat) (1, 26, 26, 256) 0 ['tf_conv_45[0][0]', 'tf_conv_39[0][0]'] tfc3_6 (TFC3) (1, 26, 26, 256) 295680 ['tf_concat_2[0][0]'] tf_conv_51 (TFConv) (1, 13, 13, 256) 590080 ['tfc3_6[0][0]'] tf_concat_3 (TFConcat) (1, 13, 13, 512) 0 ['tf_conv_51[0][0]', 'tf_conv_33[0][0]'] tfc3_7 (TFC3) (1, 13, 13, 512) 1181184 ['tf_concat_3[0][0]'] tf_detect (TFDetect) ((1, 10647, 85), 229245 ['tfc3_5[0][0]', [(1, 2704, 3, 85), 'tfc3_6[0][0]', (1, 676, 3, 85), 'tfc3_7[0][0]'] (1, 169, 3, 85)]) ================================================================================================== Total params: 7,225,885 Trainable params: 0 Non-trainable params: 7,225,885 __________________________________________________________________________________________________ 2022-08-23 15:19:33.627375: I tensorflow/core/grappler/devices.cc:66] Number of eligible GPUs (core count >= 8, compute capability >= 0.0): 0 2022-08-23 15:19:33.627658: I tensorflow/core/grappler/clusters/single_machine.cc:358] Starting new session Assets written to: yolov5s_saved_model\assets TensorFlow SavedModel: export success, saved as yolov5s_saved_model (27.8 MB) TensorFlow Lite: starting export with tensorflow 2.9.1... Found untraced functions such as tf_conv_2_layer_call_fn, tf_conv_2_layer_call_and_return_conditional_losses, tf_conv_3_layer_call_fn, tf_conv_3_layer_call_and_return_conditional_losses, tf_conv_4_layer_call_fn while saving (showing 5 of 268). These functions will not be directly callable after loading. Assets written to: C:\Users\ADMINI~1\AppData\Local\Temp\tmp2dfxq2oq\assets 2022-08-23 15:21:33.820763: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:362] Ignored output_format. 2022-08-23 15:21:33.821578: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:365] Ignored drop_control_dependency. 2022-08-23 15:21:33.827268: I tensorflow/cc/saved_model/reader.cc:43] Reading SavedModel from: C:\Users\ADMINI~1\AppData\Local\Temp\tmp2dfxq2oq 2022-08-23 15:21:33.933152: I tensorflow/cc/saved_model/reader.cc:81] Reading meta graph with tags { serve } 2022-08-23 15:21:33.934302: I tensorflow/cc/saved_model/reader.cc:122] Reading SavedModel debug info (if present) from: C:\Users\ADMINI~1\AppData\Local\Temp\tmp2dfxq2oq 2022-08-23 15:21:34.244556: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:354] MLIR V1 optimization pass is not enabled 2022-08-23 15:21:34.301240: I tensorflow/cc/saved_model/loader.cc:228] Restoring SavedModel bundle. 2022-08-23 15:21:35.141922: I tensorflow/cc/saved_model/loader.cc:212] Running initialization op on SavedModel bundle at path: C:\Users\ADMINI~1\AppData\Local\Temp\tmp2dfxq2oq 2022-08-23 15:21:35.504643: I tensorflow/cc/saved_model/loader.cc:301] SavedModel load for tags { serve }; Status: success: OK. Took 1677383 microseconds. 2022-08-23 15:21:36.609861: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:263] disabling MLIR crash reproducer, set env var `MLIR_CRASH_REPRODUCER_DIRECTORY` to enable. 2022-08-23 15:21:38.044500: I tensorflow/compiler/mlir/lite/flatbuffer_export.cc:1972] Estimated count of arithmetic ops: 7.666 G ops, equivalently 3.833 G MACs Estimated count of arithmetic ops: 7.666 G ops, equivalently 3.833 G MACs TensorFlow Lite: export success, saved as yolov5s-fp16.tflite (13.9 MB) Export complete (136.66s) Results saved to D:\Downloads\yolov5-6.2 Detect: python detect.py --weights yolov5s-fp16.tflite Validate: python val.py --weights yolov5s-fp16.tflite PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s-fp16.tflite') Visualize: https://netron.app
It can be seen that the converted model is yolov5s-fp16.tflite . At the same time, in the same directory, there is a folder yolov5s_saved_model , which contains the .pb file, which is the protobuf file. Here is a detail, which is the .pt file. is first converted to .pb and then to .tflite .
Next, use the script detect.py to verify it, using the .tflite model generated above
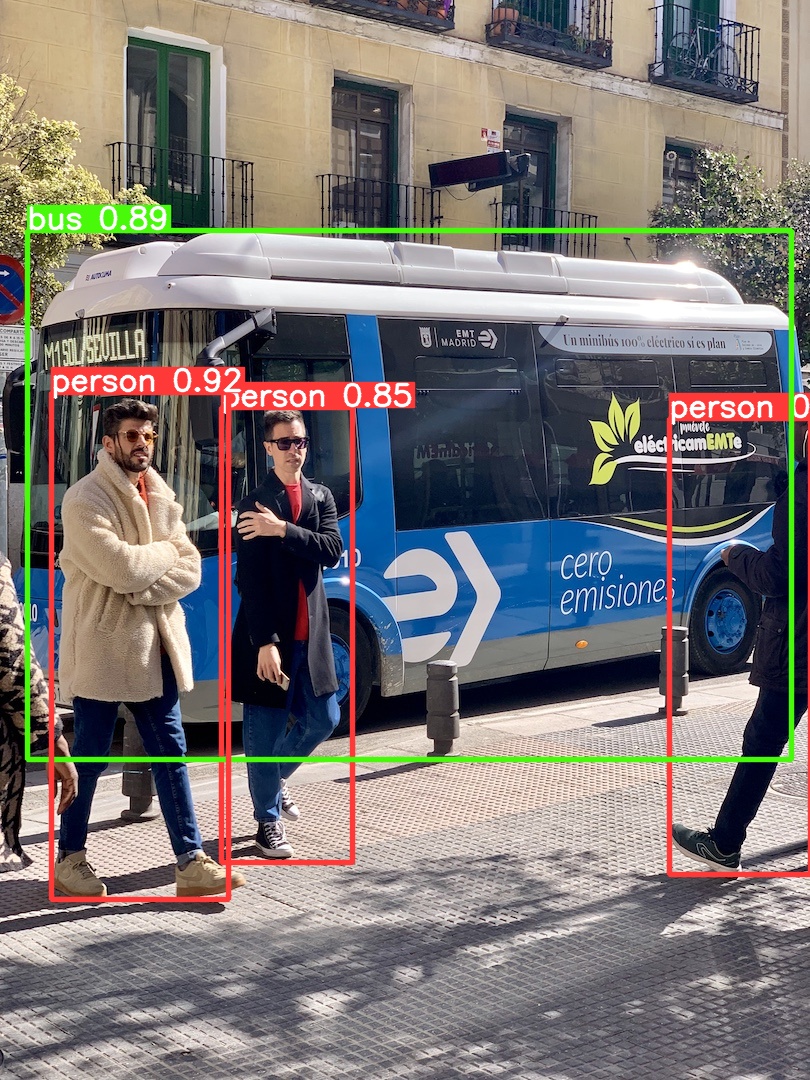
python detect.py --weights yolov5s-fp16.tflite --source data/images/bus.jpg --img 416
Detection is no problem
With the model file, you can come to the android side. I uploaded the sample code to github , and you can clone it directly
git clone https://github.com/xugaoxiang/yolov5_ android _tflite.git
What needs to be replaced are 2 files in the yolov5_ android _tflite/app/src/main/assets folder, class.txt and yolov5s-fp16.tflite
After compiling and installing it on the mobile phone, you can start camera-based target detection.
References
- Running YOLOv5 Object Detection on Android with NCNN
- Install cuda and cudnn on windows 10
- YOLOv5 model training
- YOLOv5 version 5.0
- Workaround for Android studio gradle build failure
This article is reprinted from https://xugaoxiang.com/2022/09/06/yolov5-android-tflite/
This site is for inclusion only, and the copyright belongs to the original author.