Original link: https://www.zhangxinxu.com/wordpress/2022/09/js-selection-range/
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=10541 Xin Space-Xin Life
This article welcomes sharing and aggregation. It is not necessary to reprint the full text. The copyright is respected. The circle is so big. If you need it urgently, you can contact for authorization.

First, look at the big screen
Recently, I have been working on the development of word-marking comments. There are still some thresholds for the development of this interactive function. I thought that some small partners may encounter similar needs, so I decided to share some processing experience.
Before the specific introduction, you can take a look at a suggested demo demonstration effect: https://zhangxinxu.gitee.io/word-comment/
Screenshot of part of the demo page:

You may have noticed that the domain name of the demo is gitee, yes, I have open sourced the related implementation.
The project address is: https://gitee.com/zhangxinxu/word-comment
However, this project only has the core function of the word-marking part. Comments are taken in one stroke. In the actual production process, there are many linkages between comments and word-marking. You can complete the final development based on the demo of this project and your own business.
Well, let’s start to formally talk about the difficulties and technical implementations encountered in the implementation process.
Second, first understand the basic concepts of constituencies and ranges
In the Web, the constituency refers to the Selection and the range refers to the Range .
The concept of constituency is a bit larger, and there may be multiple ranges in a constituency, that is, the Range can be obtained from the Selection.
Both Selection and Range provide many properties and methods that allow us to add, delete, and modify selections.
In the past, when compatibility with IE was required, constituencies and ranges were confusing, because IE had its own set, and other browsers had their own set.
Now that IE has been sleeping for a long time, there is no need to worry so much, just learn the standard API directly, happy!

The realization of word-marking comments is essentially some processing operations between Selection, Range and DOM. In other words, it is actually a stage play between the following three things.
// i'm scope const selection = document.getSelection(); // I am a selection const range = selection.getRangeAt(0); // I am element const container = document.querySelector('.xxx');
The so-called “operation” is actually to execute each API in the appropriate position according to the requirements. Therefore, the difficulty in realizing the requirements lies in the familiarity with the API.
Therefore, you only need to read the MDN document for a day, try each API once, and combine the content of this article, then what kind of word-marking function is properly implemented.
Moreover, not only word-marking comments, but also various constituency-related developments in the future will be at your fingertips.
Here is a good article on the introduction of constituencies: “Selection” and “Cursor” in the Web
I also wrote an article about Range more than ten years ago, but the content is too old, a product of the IE era, if your project still needs to be compatible with the IE browser, you can take a look.
Well, enough warm-up, you can get to the main topic, based on example learning, this is the way most developers like to learn.
//zxx: If you see this text, it means that you are visiting the original site. A better reading experience is here: https://ift.tt/L3kUBCA (by Zhang Xinxu)
3. Difficulties, problems and solutions
1. Centering of constituencies
Select a piece of text, and then display the button to add a comment, and then the button should be in the middle of the selection, as shown below:
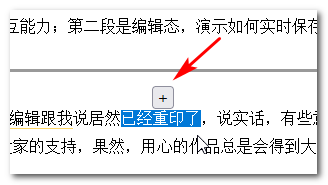
How to achieve this?
The key to this positioning implementation is to know the location and size of the constituency. It is best to have an existing API. Does the browser provide the relevant API?
provided!
We open the MDN document and we can see the API named getBoundingClientRect shown in the figure below.
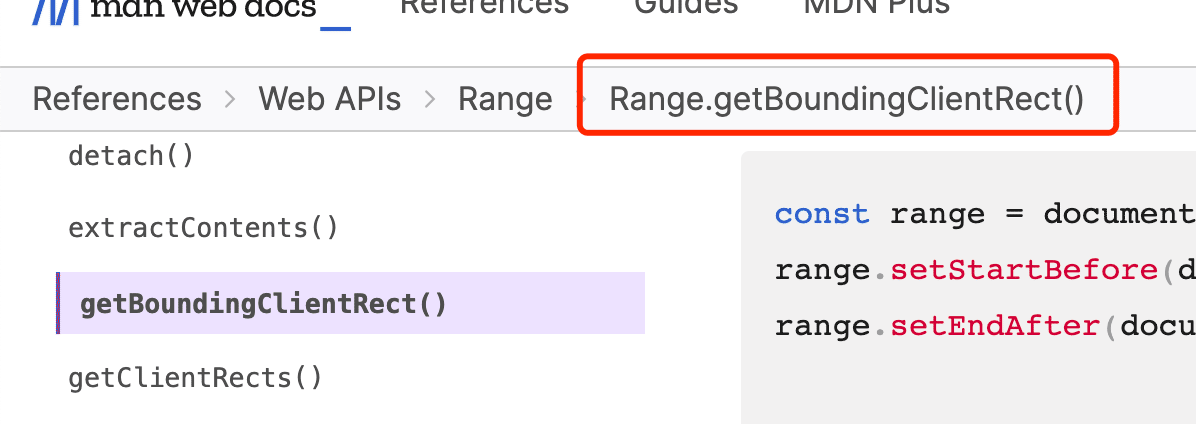
We can use this API to perform absolute positioning.
const selection = document.getSelection(); const range = selection.getRangeAt(0); const boundRange = range.getBoundingClientRect(); // The comment button can be absolutely positioned based on boundRange
However, things are not so simple. The constituency does not have to be a regular line, but may span lines, like the following:

At this time, if it is still displayed in the center, there will be a problem, because the arrow of the positioned comment button does not point to the selection area, but the text of the non-selection area. What should I do at this time?
My workaround is to position directly to the far right of the first row selection, like this:
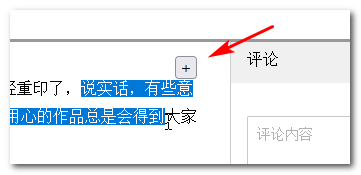
The judgment logic is very simple, as long as the height of the constituency exceeds the height of a row of constituencies, indicating:
if (boundRange.height > 30) { // Think it's a cross-line selection // Floating positioning on the right side of the comment button}
However, things are not over yet. If the user double-clicks to select, it is very likely that there will be a line break (under a specific layout structure), which will make the position and visual performance of the selection inconsistent, that is, it looks like It’s just a few words now, but the whole line is actually selected, as shown in the following figure:
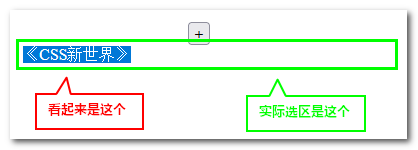
At this time, special processing needs to be performed on the selection area, that is, the selection area needs to be modified. For the specific implementation, see “3. Special processing for double-clicking all selections”.
2. Determine the starting and ending positions of the words
That is, the index value of the starting and ending positions of the current constituency in the entire paragraph. For example, if a paragraph is “A boat of Qiu Meng presses the galaxy”, the starting index of “Autumn Dream” is 1, and the ending index is 3.
This value is sent to the backend for storage.
In this way, when the next page loads, we can highlight the corresponding content based on this start and end position.
Ok, the concept is known, how to implement it?
In other words, does the browser provide a native start and end position API?
There really is! But it can’t be used directly!
What does it mean?
Looking at the image below, the Selection API provides several offset properties.
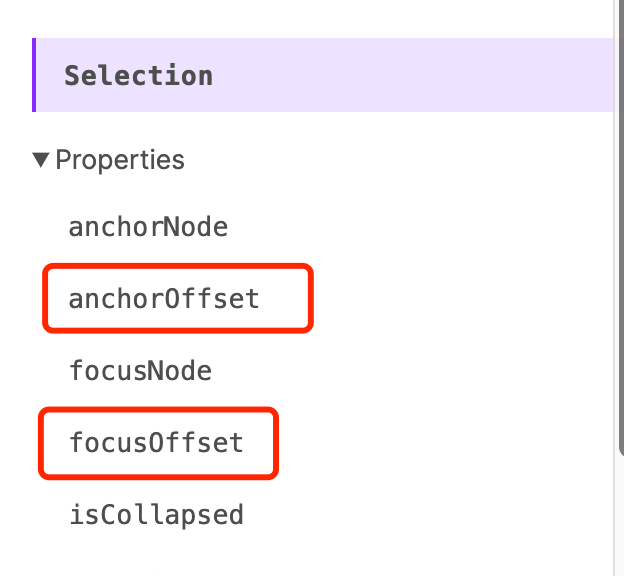
The Range API also has several offset properties.
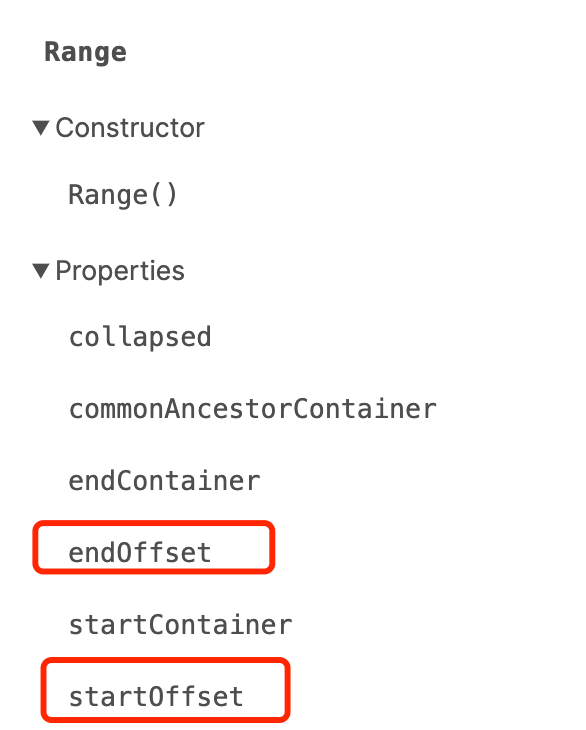
However, these offsets are relative to a node, not necessarily the offset value of the entire paragraph element, so they cannot be used directly.
For example, there is the following HTML code:
<p> Front text <i>tag element</i>back text</p>
If the selection of the text is the word “behind”, then the anchorNode of the Selection will be: the text behind #Text, and the anchorOffset will also be 0. The screenshot shows:


The correct way is to perform node traversal on the external paragraph element. If the node (or the child node of the node) matches the anchorNode, the length of all the previous text plus the anchorOffset is the real starting index value.
Here is the implemented code:
const selection = document.getSelection(); const range = selection.getRangeAt(0); let startNode = range.startContainer; let startOffset = range.startOffset; // calculation of starting position let startIndex = 0; let loopIndex = function (dom) { [...dom.childNodes].some(function (node) { if (!node.textContent) { return; } // node matched // no more traversal if (node == startNode) { startIndex += startOffset; return true; } if (startNode.parentNode == node) { loopIndex(node); return true; } startIndex += node.textContent.length; }); }; // container is the container element of the content loopIndex(container); // end index let endIndex = startIndex + selection.toString().trim().length;
3. Double-click to select all special handling
There may be a difference between double-clicking the selection to select all and the selection of box-selecting all to remove the text.
Note the wording here it is possible!
Regarding the impact of CSS layout on the selection range, although I have studied this, it was all 10 years ago, and it was still the era when IE browser was king. For details, see the article “Usability of Different CSS Layout Implementations and Text Mouse Selection ” , the knowledge in it has not kept up with the times, and the current mainstream layout, as well as the text constituencies with mixed content, I have not studied in depth, and I have not yet figured out the rules.
Therefore, double-clicking to select all may have a pit problem, which may occur under certain layout conditions. Generally, the more complex the layout and the more content, the more likely the selection area is not clean.
OK, back here.
As far as my own project development is concerned, I encountered the problem that when I double-click the text, it will be selected together with the text of other elements (when the ancestor element is set with user-select:none, yes, none range selection, a bit Counter-intuitive), or the selected content has a newline character at the end (which will automatically become a space).
Usually copy and paste, the above problem is not big.
However, if it is a scene with high requirements for constituencies such as word-marking comments, the above phenomenon will have major problems. For example, at this time, the anchorNode or focusNode of the constituency is not text, but a higher-level element. The original execution logic is There will be bugs.
How to do it? Only such constituencies can be dealt with specially.
The processing method is very simple, reset the content of the Range, and then use the new Range for processing (it can be to change the node of the Range selection, or to change the start and end points of the Range selection, there are corresponding APIs).
At this point, although visually the user is imperceptible, in fact, the code has already done a lot of things.
The processing code is shown as follows, and you can also refer to utils.js in the gitee project:
// eleTarget is the container element where the content is located // get the selection const selection = document.getSelection(); let selectContent = selection.toString(); let selectContentTrim = selectContent.trim(); if (!selectContentTrim) { return; } // If there is out-of-range content if (eleTarget.textContent.indexOf(selectContentTrim) == -1) { return; } const range = selection.getRangeAt(0); // Re-modify the selection if (selectContent != selectContentTrim && eleTarget.textContent.trim() == selectContentTrim) { // If plain text, use current node if (!eleTarget.children.length) { range.selectNode(range.startContainer); } else { // If it contains child elements, change the start and end points of the selection range.setStartBefore(eleTarget.firstChild); range.setEndAfter(eleTarget.lastChild); } selectContent = selectContentTrim; }
Next, it can be processed according to the regular text selection.
4. Implementation of reverse highlighting
With the starting and ending positions of the selection area, when you re-enter the page, what if the text at the corresponding position is highlighted?
Obviously, we need to create a new range and wrap a highlighted span element around it. Here we need to use the surroundContents() API of the Range object. This API allows naked text to wrap HTML elements without affecting other text content.
Well, the difficulty below becomes how to create an accurate selection based on startIndex and endIndex . This is a bit troublesome, because the creation of the start and end points of the Range needs to accurately find the corresponding node elements and offset positions.
The following code is an illustration of the implementation:
function getNodeAndOffset(dom, start = 0, end = 0){ const arrTextList = []; const map = function(chlids){ [...chlids].forEach(el => { if (el.nodeName === '#text') { arrTextList.push(el) } else if (el.textContent) { map(el.childNodes) } }) } map(dom.childNodes); let startNode = null; let startIndex = 0; let endNode = null; let endIndex = 0; // total character length let total = startIndex; // Calculate length arrTextList.forEach(function (node) { if (startNode && endNode) { return; } let length = node.textContent.length; // The current node, the total length range const range = [total, total + length]; // see if start and end are in it // start is in this range // can determine startIndex if (!startNode && start >= range[0] && start range[0] && end
The core of the implementation is the getNodeAndOffset() method, which you can use directly by copying and pasting.
5. The starting and ending points and content of editing are saved in real time
Editable wordmark comments like documents, when the corresponding content is modified, need to save the starting and ending points and content of the selection in real time. At this time, how to obtain the relevant information?
The following code is the algorithm I use:
function getContentAndIndexList (target, selector) { const divTmp = document.createElement('div'); // replace divTmp.innerHTML = target.innerHTML; // The final returned data let operateCommentsList = []; // Traverse and match const getRange = function () { let eleWrod = divTmp.querySelector(selector); if (!eleWrod) { return; } let text = ''; [...divTmp.childNodes].some(function (node) { if (node === eleWrod) { const selectContent = node.textContent; operateCommentsList.push({ selectContent: selectContent, startIndex: text.length, endIndex: text.length + selectContent.length, // The gid naming here is based on the business, you can use other names gid: Number(node.dataset.gid) }); // Node replacement node.replaceWith.apply(node, [...node.childNodes]); // Continue to traverse getRange(); return true; } text += node.textContent; }); }; getRange(); return operateCommentsList; }
The principle is: create a temporary div object, clone the content of the element completely, then traverse all the highlighted elements, and replace the highlighted elements with child elements in turn, so as to obtain all the highlighted word data.
Just the opposite of constantly using surroundContents() for highlighting.
Well, with the solutions to the above core difficulties and some common interaction logic, a complete word-marking function can be achieved.
For the specific implementation logic and code, see the gitee project shown at the beginning of this article.
4. Conclusion
Some people may have noticed. With this article, I have posted 3 consecutive times in 3 days, and the high yield seems to be so.
Weird, blogger! I thought you were so addicted to fishing that you stopped updating your blog.
NoNoNo! Although fishing did spend more time than before, it was freeing up time for writing novels before.
The reason why the article in the past two months is not as diligent as before is because I have been busy writing the second edition of “CSS Selectors” in the past two months. No, I just finished submitting the draft last week, and this week I will be posting an update. .
It’s time.
But don’t be complacent, I’ll be working on The CSS World Revised Edition after October, and I’ll be busy for a few more months.
So, while there is still a week left in October, I plan to publish a few more articles.
Please look forward to it~
![]()
This article is an original article, welcome to share, do not reprint in full text, if you really like it, you can collect it, it will never expire, and will update knowledge points and correct errors in time, and the reading experience will be better.
The address of this article: https://www.zhangxinxu.com/wordpress/?p=10541
(End of this article)
This article is reprinted from: https://www.zhangxinxu.com/wordpress/2022/09/js-selection-range/
This site is for inclusion only, and the copyright belongs to the original author.