Original link: https://www.msra.cn/zh-cn/news/features/cvpr-2022
Editor’s note: The International Conference on Computer Vision and Pattern Recognition (CVPR) is one of the most academically influential top conferences in the field of artificial intelligence. Microsoft Research Asia also successfully held the CVPR 2022 paper sharing session in April. Today, we have selected 8 excellent papers of Microsoft Research Asia included in CVPR 2022 to take you to explore the hot frontiers in the field of computer vision! Interested readers are welcome to read the original paper.
Video Restoration Based on Neural Compression

Paper link: https://ift.tt/Sp1HFgj
Video restoration tasks rely heavily on temporal features for better reconstruction quality. Existing video restoration methods mainly focus on how to design better network structures to extract temporal features, such as bidirectional propagation. As for how to effectively use temporal features and fuse them with the current frame, it is often overlooked. In fact, temporal features usually contain a lot of noise and irrelevant information, and if they are used directly without any feature purification, they will interfere with the restoration of the current frame.
To this end, researchers at Microsoft Research Asia have proposed a neural compression-based algorithm to learn efficient temporal feature representations. Since neural compression discards irrelevant information or noise in order to save bits, it is a natural denoiser. Therefore, this paper uses neural compression to effectively filter the interference of noise and retain the most important information in time series. As shown in Figure 1(b), researchers use neural compression to purify temporal features before feature fusion. In order to achieve robustness to noise, this paper designs an adaptive and learnable quantization mechanism for the compression module, so as to effectively deal with different types and degrees of noise disturbance. During the training process, the cross-entropy loss function and the reconstruction loss function guide the learning of the quantization module.
Figure 1(c) shows that the features learned by our model are more robust to noise and are closer to features from clean videos. Experiments show that this feature learning approach helps our model achieve the best performance in multiple video restoration tasks, including video denoising, video deraining, and video dehazing. Moreover, our method also outperforms the previous state-of-the-art methods in terms of complexity. Especially on the video denoising task, our method is 0.13 dB better than BasicVSR++, and only has 0.23 times the complexity.
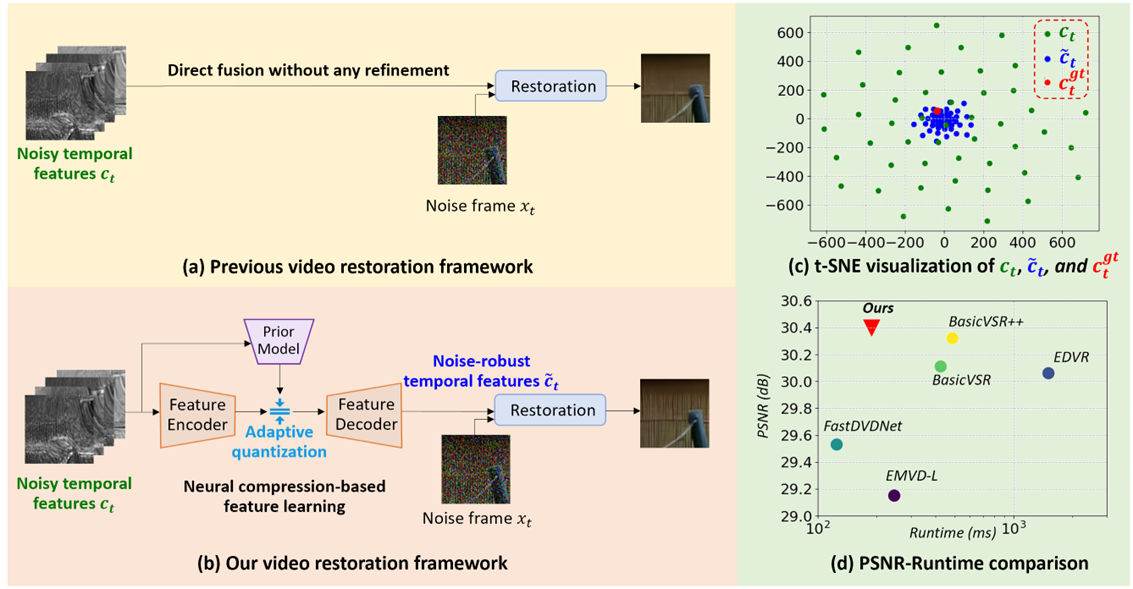
Figure 1: (a) Existing video restoration framework, (b) neural compression-based video restoration framework proposed in this paper, (c) t-SNE visualization comparison, (d) performance comparison
Three-dimensional controllable image generation based on neural radiation manifold

Paper link: https://ift.tt/fQF4bDd
Traditional Generative Adversarial Networks (GANs) already have the ability to generate two-dimensional images that look like real ones. But they do not take into account the 3D geometric properties behind the objects in the generated images, so they cannot generate multi-view images of the objects. In the past two years, some generative adversarial networks that can achieve 3D viewing angle control have gradually emerged. Given a single-view image set of a class of objects as training data, these methods can generate multi-view images of objects using an adversarial learning process on the images. A key factor in enabling this is to integrate the 3D representation of objects with an image generation process, where state-of-the-art methods utilize neural radiation fields (NeRF) as object representations.
However, the image generation quality of existing NeRF-based generative adversarial networks still lags far behind traditional two-dimensional image generative adversarial networks. The researchers observed that an important reason for this problem is that NeRF’s volume rendering process combined with the adversarial learning process has a large memory overhead, which limits the number of sampling points allowed per ray during volume rendering. When the number of sampling points is limited, the NeRF representation cannot effectively deal with the fine geometric texture of objects, and its rendered images contain obvious noise patterns, which seriously affects the stability of the adversarial learning process.
In this paper, a novel neural radiation manifold representation is proposed to solve the above problems when NeRF is combined with adversarial learning. The neural radiation manifold restricts the learning of radiation fields and the sampling points of image rendering to a cluster of two-dimensional surface manifolds in three-dimensional space, which helps the network to learn the fine structure of objects on the surface and effectively avoids image rendering. noise pattern at the time. Experiments show that, based on neural radiation manifold representations, the researchers greatly improve the realism of the generated images and their 3D consistency under changing viewing angles.

Figure 2: Schematic diagram of image generation process based on neural radiation manifold
StyleSwin – Using Transformer to build Generative Adversarial Networks suitable for high-quality image generation

Paper link: https://ift.tt/psf69Fd
Image generation models represented by generative adversarial networks have made great progress in the past few years. Its early research mainly focused on making adversarial training more stable, while recent breakthroughs in generative quality have mainly benefited from the introduction of more expressive networks, such as the introduction of attention mechanisms, the use of larger networks, and Style-based generators. .
Transformers have recently gained a lot of attention and have achieved great success in a range of discriminative tasks. Inspired by this, researchers at Microsoft Research Asia tried to explore whether a series of excellent properties of Transformer, especially long-distance modeling capabilities, are also helpful for generative tasks. To build a Transformer-based generator network, it is necessary to overcome the problem of excessive computational complexity when generating high-resolution images. To this end, the researchers used the Swin Transformer proposed by Microsoft Research Asia as the basic module to achieve a good balance between computational complexity and model expression ability.
The researchers further proposed several improvements that made the Swin Transformer better suited to image generation tasks. First, the entire generator adopts a Style-based structure and explores several style injection mechanisms suitable for Transformer modules. Second, the researchers propose to replace the overlapping windows in the Swin Transformer with double attention, so that each layer of Transformer modules has a larger attention span. Furthermore, the researchers point out that for generative models, it is necessary to employ both relative and absolute position encoding.
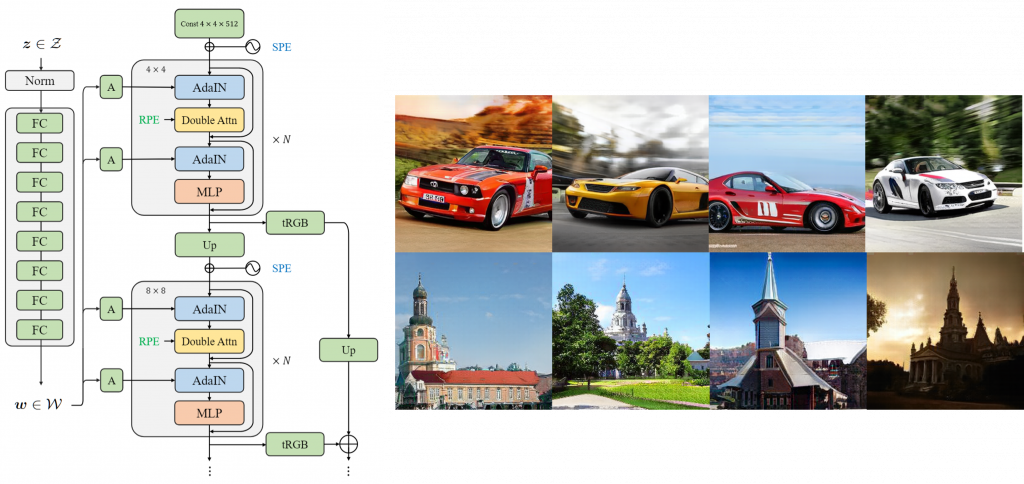
Figure 3: (left) StyleSwin network structure, (right) 256×256 generation results are stable beyond StyleGAN
More importantly, the researchers found that computational attention within local windows produces blocking artifacts similar to DCT compression, an issue that is only noticed in generative tasks. To this end, the researchers proposed a wavelet transform-based discriminator model to identify such blocky defects in the frequency domain space, which effectively improved the generation quality under the perception of the naked eye.
The StyleSwin proposed in this paper has achieved competitive generation quality on several datasets, such as FFHQ, CelebA-HQ, LSUN church, LSUN car and other standard datasets. At 256×256 resolution, StyleSwin surpasses all existing GAN methods and achieves image quality comparable to StyleGAN2 at 1024×1024 resolution. The significance of this paper is to verify the effectiveness of the Transformer model in high-resolution, high-quality image generation tasks for the first time, and provide new inspiration for the development of the basic network of generative networks.
Image-to-text generation based on quantized denoising diffusion model

Paper link: https://ift.tt/grAQRhm
Text-to-image generation is a hot generation problem in recent years. Previous related work is mainly divided into two categories: generative adversarial networks and autoregressive models. Generative adversarial networks are limited by their fitting ability, and often can only fit images of a single scene or category. The autoregressive model transforms the image generation problem into a serialization generation problem, however, this method has the problem of one-way bias, error accumulation, and the speed of generating images is slow. This paper proposes a new generative model, quantized denoising diffusion model (VQ-Diffusion), which can solve the above problems well. Specifically, the method first uses a vector quantized variational autoencoder (VQVAE) to encode the image into discrete codes, and then uses a conditional denoising diffusion model (DDPM) to fit the distribution of the latent space.
Unlike the quantized denoising model in continuous space, in order to fit discrete data distributions, researchers use probability transition matrices instead of Gaussian noise to denoise the target distribution in the noise-adding step of the denoising-diffusion model. Specifically, this paper proposes a noise addition strategy of occlusion and replacement, which can successfully avoid the problem of error accumulation. Furthermore, by exploiting a bidirectional attention mechanism for denoising, this method avoids the problem of unidirectional bias. This paper also proposes adding a reparameterization trick to the discrete diffusion model to effectively balance generation speed and image quality. The schematic diagram of the quantized denoising diffusion model is shown in Figure 4:
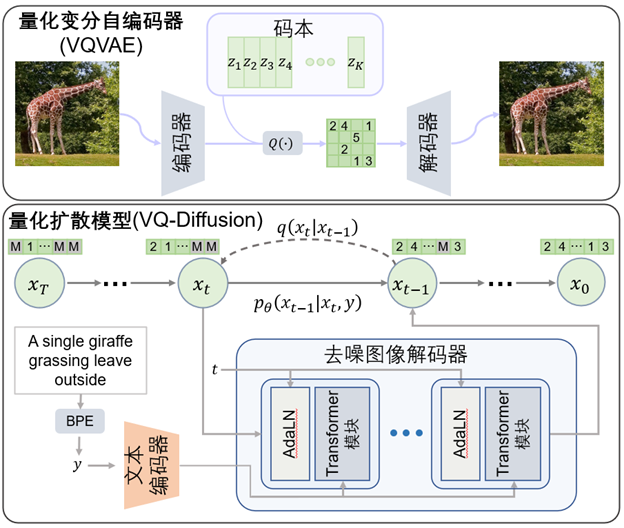
Figure 4: Algorithm flowchart of VQ-Diffusion
This paper conducts experiments on many text-to-image generation datasets, including CUB-200, Oxford-102, and MSCOCO. Compared with the autoregressive model, the quantitative diffusion model can obtain better generation results with similar parameter quantities at 15 times faster generation speed. Compared with previous text-to-image generation methods based on generative adversarial networks, this algorithm can handle more complex scenes and greatly improve the quality of generated images. In addition, the method is also universal and can be used for both unconditional image generation (such as FFHQ) and conditional image generation (such as ImageNet).
A Sign Language Translation Model Based on Multimodal Transfer Learning

Paper link: https://ift.tt/0Wm7oMx
With 70 million deaf people around the world speaking more than 200 sign languages, research into sign language translation (SLT) can help improve communication between deaf and hearing people. In recent years, machine sign language translation (SLT) follows the machine text (NMT) translation framework and adopts an encoder-decoder architecture to translate visual signals into natural language. However, SLT suffers from data scarcity compared to the success of NMT. In order to solve this problem, this paper proposes a simple and effective multimodal transfer learning sign language translation model, which adopts a step-by-step pre-training method: the model is successively trained on the general-domain and intra-domain datasets. By transferring knowledge from existing datasets, researchers hope to reduce reliance on data. Using sign language transcription annotation (Gloss) as an intermediate representation, the researchers decompose SLT into Sign2Gloss and Gloss2Text so that vision and language modules can be pre-trained on the two domains, respectively.
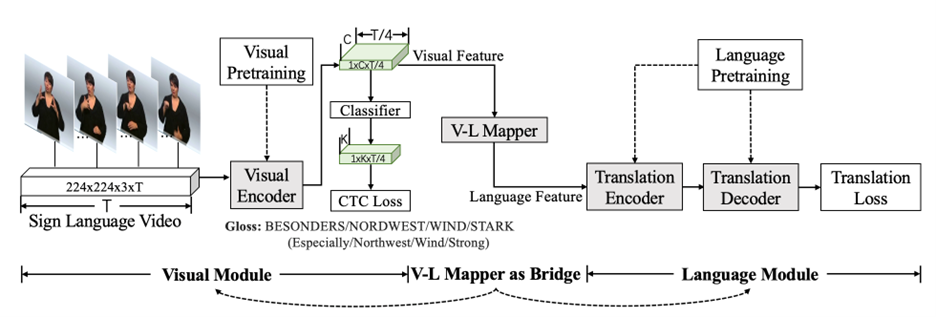
Figure 5: The researchers split sign language translation into a visual task (left) and a language task (right), and used a visual-language mapper (VL Mapper) to connect the two tasks. Perform pre-training on large-scale data, implement transfer learning, and finally jointly train the entire model.
The model in this paper includes: a vision module for extracting video features, a language module for translating video features into text, and a vision-linguistic mapper connecting the above two modules. For the vision module, the researchers first pre-trained the S3D network on Kinetics-400 (action recognition dataset) and WLASL (American Sign Language word recognition dataset), and then further trained the visual encoder on the target dataset with Sign2Gloss as the training task. For the language module, the researchers used the mBART model pre-trained on a large-scale text corpus, and then further trained the language module with Gloss2Text on the target data. Using a VL mapper consisting of a two-layer MLP, the researchers transformed visual features into the input of the translation network. In this way, the two pre-training modules are connected by visual features, and the entire model will be able to achieve joint training.
Our model outperforms previous sign language translation methods by a large margin: it achieves BLEU-4 of 28.4 and 23.9 on Phoenix-2014T and CSL-Daily, respectively. In addition, this paper also conducts ablation experiments to verify the effectiveness of the transfer learning strategy.
Rethinking Minimum Sufficient Representations in Contrastive Learning

Paper link: https://ift.tt/JXLzD0f
As a self-supervised learning method, contrastive learning has been widely used in video and image domains as the main method for pre-training in recent years. Since contrastive learning uses different “perspectives” of the data to supervise each other, the learned data representations often only contain the shared information among the “perspectives”, while excluding their non-shared information. In other words, the final result of contrastive learning is to learn the minimum sufficient representation between different “perspectives”. This raises a question – does the excluded non-shared information contain content that contributes to downstream tasks? Since the generation of “view” is highly dependent on the augmentation method, and the information related to downstream tasks is often missing in the pre-training stage, this possibility does exist intuitively.
Through rigorous reasoning proof and experimental verification from the aspect of information theory, researchers at Microsoft Research Asia found that the non-shared information with minimum sufficient representation exclusion does indeed contain useful information related to downstream tasks, thus revealing that contrastive learning has overfitting to a “perspective” “The risks of sharing information. This risk can seriously reduce the generality and performance of the pretrained model on downstream tasks. To this end, researchers believe that contrastive learning should learn sufficient representations between “perspectives” rather than minimum sufficient representations, and propose a simple, effective and general approach: increasing the mutual information between “perspectives” in contrastive learning. To put it simply, while learning the shared information of the “perspective”, it also learns the non-shared information related to the downstream tasks as much as possible. On this basis, the researchers proposed two general pre-training strategies, one is to introduce more original input information by reconstructing the input data to achieve the purpose of increasing non-shared information; the other is to add regular terms to calculate mutual The lower limit of information can directly improve mutual trust. Extensive experimental results show that our proposed pre-training strategy greatly improves the accuracy in a series of downstream tasks such as classification, detection and segmentation.

Figure 6: Information distribution map of fully-represented and least-sufficiently represented in contrastive learning
SimMIM: A Simple Image Mask Modeling Framework

Paper link: https://ift.tt/m4ABXoG
Code address: https://ift.tt/N6q0rv1
Masked Signal Modeling is a pre-training method that predicts invisible information by exploiting partially visible information. Its application in the field of natural language processing (NLP) – Masked Language Modeling (MLM) has become the most representative and widely used pre-training method in the field of NLP.
In fact, there have also been a series of attempts to use Masked Image Modeling (MIM) for visual model pre-training in the field of computer vision, but previous methods often require the introduction of additional designs. In this paper, the researchers propose a simple pre-training framework SimMIM, and demonstrate that good visual model pre-training can be achieved using only a simple random mask strategy and a single-layer linear decoder to restore the original image signal, and learn High-quality image representation.
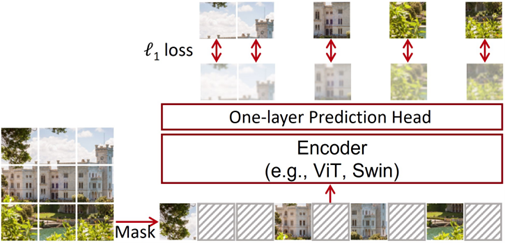
Figure 7: SimMIM uses a simple random mask strategy and a lightweight single-layer linear decoder to reconstruct the original signal of an image, pre-trained with a simple l1 loss function.
SimMIM can adapt to any base network, including ViT, Swin and ConvNets. As shown in Figure 8 (left), when using ViT-B, SimMIM achieves better fine-tuning performance than other methods while spending less training cost.
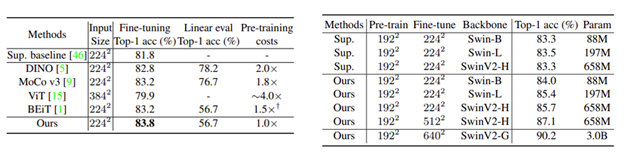
Figure 8: (Left) Performance comparison of SimMIM and other methods when using ViT-B. (Right) SimMIM compared to Supervised Pre-training when using Swin.
Figure 8 (right) shows that SimMIM achieves better performance than Supervised pre-training when using Swin, and the larger the model, the more obvious the advantage of SimMIM, which shows that SimMIM is a good Model scalable learner. By using SimMIM, Swin-G with 3B parameters can achieve 90.2% Top-1 Acc in ImageNet-1K image classification task.
SimMIM is not only suitable for Transformer-based networks, it is also effective for ConvNets. ResNet-50×4 achieves 81.6% Top-1 Acc using SimMIM, which is higher than the 80.7% result obtained by supervised pretraining. These experiments demonstrate the broad applicability of SimMIM.
Video Super-Resolution Networks for Learning Trajectory-Aware Transformers

Paper link: https://ift.tt/KjmZHzy
Code link: https://ift.tt/ZRr2Xe6
Video super-resolution (VSR) aims to recover high-resolution (HR) video frames from their low-resolution (LR) counterparts. Although some progress has been made in the field of video super-resolution, there are still huge challenges in how to effectively utilize the temporal information of the whole video. Existing methods usually generate high-resolution frames by aligning and aggregating the information of short-distance adjacent frames (such as 5 or 7 frames), so they cannot achieve satisfactory results.
This paper proposes a novel trajectory-aware Transformer to perform the task of video super-resolution (TTVSR), which further explores more efficient spatial and temporal information learning methods in videos by introducing motion trajectories. Specifically, TTVSR takes the frames in the whole video as visual features, and defines some continuous visual features in space and time as some spatio-temporal trajectories that are pre-aligned on the content. For each query, the self-attention mechanism just follows the Pre-defined spatiotemporal trajectories to execute. In order to realize the modeling of the above trajectory, the researchers propose an ingenious position map mechanism, which achieves the purpose of modeling visual feature trajectories by performing motion transformation on the coordinate position map of pre-defined visual features. Compared with the traditional Transformer that performs self-attention mechanism in the whole space and time, the trajectory-aware Transformer greatly reduces the computational cost and enables the Transformer to model long-range video features.

Figure 9: Network structure diagram of the video super-resolution Transformer based on trajectory awareness
At the same time, this paper further proposes a cross-scale feature tokenization module to overcome the frequent target scale variation problem in long-distance videos. Through extensive quantitative and qualitative evaluations on four widely used video super-resolution benchmark datasets, experimental results demonstrate that the proposed trajectory-aware Transformer outperforms other state-of-the-art models. The related code and models have been open sourced on GitHub: https://ift.tt/ZRr2Xe6.
This article is reprinted from: https://www.msra.cn/zh-cn/news/features/cvpr-2022
This site is for inclusion only, and the copyright belongs to the original author.