Original link: https://www.luozhiyun.com/archives/805
Please declare the source of the reprint~, this article was published on luozhiyun’s blog: https://www.luozhiyun.com/archives/805
This article is mainly to summarize the content related to data replication and partitioning in chapters 5 and 6 of “designing-data-intensive-applications”
In the distributed database, the distributed nodes of the database have copy backup through replication, mainly for the following purposes:
- Scalability, because the amount of data carried by a single machine is limited;
- Fault tolerance and high availability. In a distributed system, single-machine failure is the norm. Do more redundancy so that other machines can take over in time when a single-machine failure occurs;
- Performance, if there is a situation where users access across regions, the access delay can be reduced by deploying in multiple places nearby;
So how to copy it? There are many replication algorithms in the database, such as single leader (single leader) replication, multi-leader (multi-leader) replication, and leaderless (leaderless) replication.
But for a large amount of data and concurrency, just copying is not enough, so partitions or partitions are introduced. Partitioning allows each partition to be its own small database, and each piece of data belongs to and only belongs to one partition, so that the database can support multiple partitions and operate in parallel, allowing the database to support very high throughput and data volume.
single master replication
Synchronous or asynchronous? Half sync!
Synchronous or asynchronous actually refers to whether the data of the distributed node is consistent with the master node. Synchronous replication means that the master library needs to wait for the confirmation from the slave library before returning, while asynchronously returns without waiting for the response from the slave library.
The advantage of synchronous replication is that the slave library can guarantee the latest data copy consistent with the master library. If the master library suddenly fails, we can be sure that the data will still be found on the slave library. The downside is that if the sync slave is unresponsive (e.g. it has crashed, or there is a network failure, or whatever), the master cannot process the write. The master must block all writes and wait for the in-sync replica to become available again.
Although asynchronous replication will not block, if the read request is undertaken from the replica, the data synchronized by the replica may be inconsistent due to the difference in replication speed between different users accessing data from different replicas.
In order to avoid this situation, one is to allow the client to read data only from the primary copy, so that under normal circumstances, the data read by all clients must be consistent; the other is to use semi-synchronous ) , such as setting a slave library to synchronize with the master library, and other libraries to be asynchronous. Change an asynchronous slave to run synchronously if that synchronous slave becomes unavailable or slow. This guarantees that you have the latest copy of the data on at least two nodes.
Take Kafka as an example, the ISR (In-Sync Replication) list will be maintained in the leader of Kafka, and there will be some delay for the follower to synchronize data from the leader (the timeout threshold is set by the parameter replica.lag.time.max.ms), and the follower exceeding the threshold will be Excluded from the ISR, the message is submitted only after the message is successfully replicated to all ISRs, so that performance and data availability are guaranteed without waiting for confirmation from all nodes.
Troubleshooting
The goal of high availability is to keep the entire system running even if individual nodes fail, and to control the impact of node downtime as much as possible.
Slave node failure – fast recovery
If the slave crashes and restarts, or if the network between the master and the slave is temporarily interrupted, it is easier to recover: the slave can know from the log, the last transaction processed before the failure, and then follow this transaction Just do it.
Let’s take a look at how Redis master-slave synchronization is restored. The master node will record those instructions that have a modifying effect on its own state in the local memory buffer, and then asynchronously synchronize the instructions in the buffer to the slave node, and the slave node will execute the synchronous instruction flow to achieve the same level as the master node. Status, while feeding back to the master node where it is synchronized (offset).
If the slave node cannot synchronize with the master node in a short period of time, then when the network condition recovers, those unsynchronized instructions in the master node of Redis may have been overwritten by subsequent instructions in the buffer, then you need to use snapshots sync .

It first needs to perform a bgsave on the main library to snapshot all the data in the current memory to a disk file, and then transfer all the contents of the snapshot file to the slave node. After the slave node accepts the snapshot file, it immediately executes a full load. Before loading, the data in the current memory must be cleared. After the loading is complete, notify the master node to continue incremental synchronization.
master-slave switching
Master failure One of the slaves needs to be promoted to be the new master, clients need to be reconfigured to send their writes to the new master, and the other slaves need to start pulling data changes from the new master.
The failover of the main library usually consists of several steps: 1. Confirm the failure of the main library; 2. Select a new main library; 3. Configure and enable the new main library. The seemingly simple steps of stuffing an elephant into a freezer actually have a lot of things that could go wrong:
- If asynchronous replication is used, the new master library may not have received the last write operation before the old master database went down . After the new main library is selected, if the old main library rejoins the cluster, the new main library may receive conflicting writes during this period. How should these writes be handled? The most common solution is to simply discard the unreplicated writes of the old main library, which is likely to break the customer’s expectations for data persistence. If the database needs to coordinate with other external storage, then discarding the write content is an extremely dangerous operation;
- There may be a situation where both nodes think they are the main library, that is, split brain . If both masters can accept writes, but there is no conflict resolution mechanism, data can be lost or corrupted. Some systems have taken safety precautions: when two main library nodes are detected to exist at the same time, one of the nodes will be shut down, but a poorly designed mechanism may eventually cause both nodes to be shut down;
- How should the timeout be configured? Longer means longer recovery time, too short and unnecessary failover may occur. Temporary load spikes can cause nodes to time out, and if the system is already under high load or network issues, unnecessary failovers can make things worse.
Let’s see how the Redis Sentinel cluster solves these problems. Redis Sentinel is responsible for continuously monitoring the health of the master and slave nodes. When the master node hangs up, it will automatically select an optimal slave node to switch to the master node. When the client connects to the cluster, it first connects to sentinel, queries the address of the master node through sentinel, and then connects to the master node for data interaction. When the master node fails, the client will ask sentinel for the address again, and sentinel will tell the client the latest master node address.
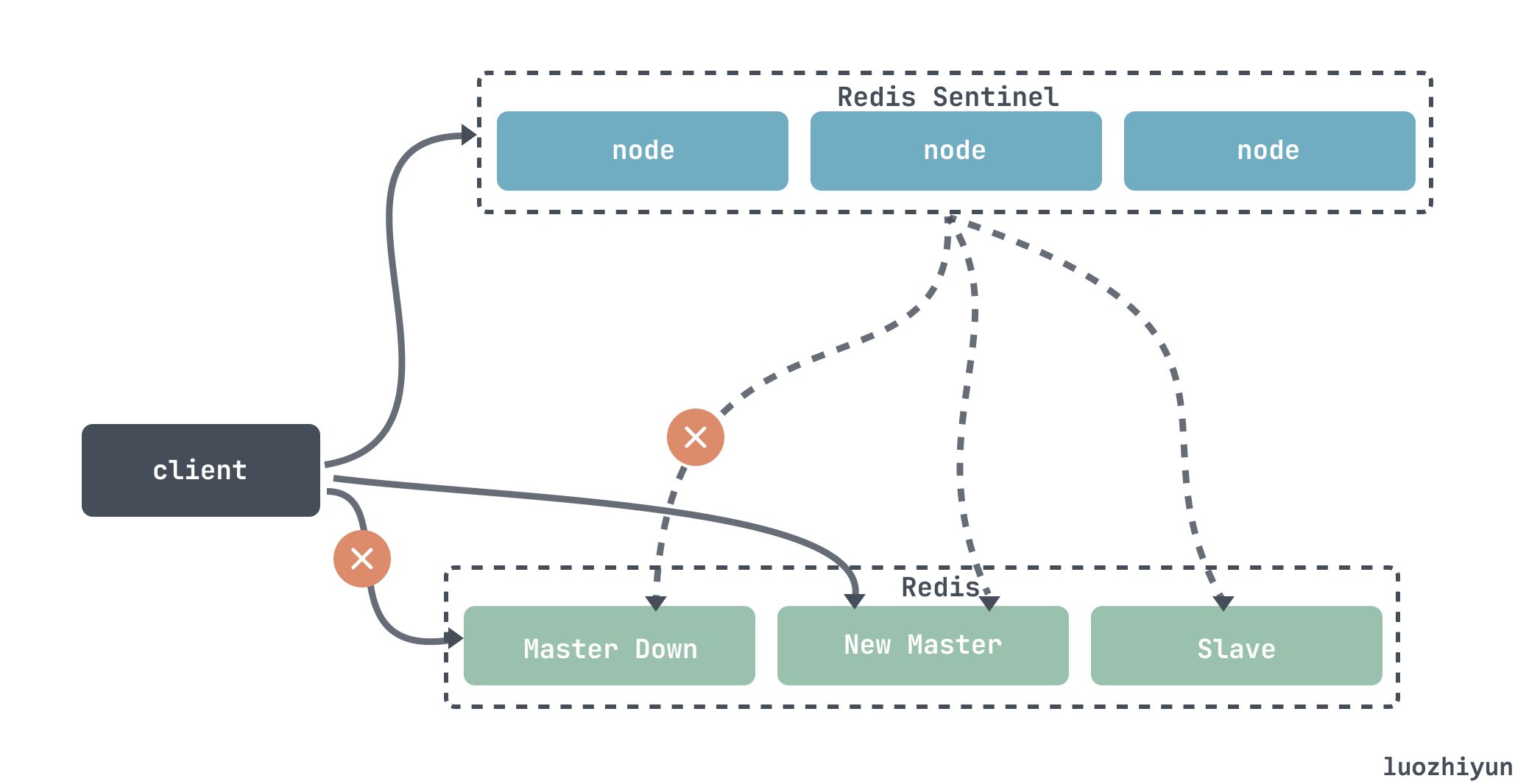
Because the master node is elected by Redis Sentinel through voting, we can set the sentinel to be more than 3 nodes, and it is an odd number (n/2+1) Nodes agree to pass, the minority obeys the majority, and two leaders with the same number of votes will not be elected at the same time.
Redis master-slave adopts asynchronous replication. When the master node hangs up, the slave node may not receive all the synchronization messages. Sentinel cannot guarantee that the messages will not be lost at all, but try to ensure that the messages are less lost. With these two configurations:
min-slaves-to-write 1 min-slaves-max-lag 10
min-slaves-to-write means that the master node must have at least one slave node performing normal replication, otherwise the external write service will be stopped and availability will be lost;
min-slaves-max-lag indicates how many seconds no feedback is received from the slave node, then the master will not accept any request at this time. We can reduce the value of the min-slaves-max-lag parameter, so that a large amount of data loss can be avoided in the event of a failure.
How to replicate logs?
The simplest idea might be SQL statement-based replication , where each INSERT , UPDATE or DELETE statement is forwarded to each slave as if received directly from the client. But this will also have many problems:
- What if functions such as
NOW()orRAND()are used in the statement? What to do with user-defined functions, triggers, and stored procedures; - If auto-incrementing ids are used, or rely on existing data in the database (e.g.,
UPDATE ... WHERE <某些条件>), execute them in exactly the same order on each replica, otherwise they may have different effects . This can become a limitation when there are multiple concurrently executing transactions;
Statement-based replication was used in versions of MySQL prior to 5.1. But now by default, MySQL switches to row-based replication if there is any uncertainty in the statement.
Based on write-ahead log (WAL) replication , WAL writes these change operations into the log before making any data changes (updates, deletions, etc.), so through this log, the slave library can build a data that is exactly the same as the main library Structural copy. The disadvantage is that it is tightly coupled with the storage engine. If the database version changes and the log format is modified, this will make replication impossible.
So WAL replication is very uncomfortable for operation and maintenance, if the replication agreement does not allow version mismatch, such upgrades require downtime.
Another is row-based logical log replication . Logical logs are used by relational databases to represent the sequence of records written by row operations. MySQL’s binary log (binlog) uses this method. Since the logical log is decoupled from the internal implementation of the storage engine, the system can be more easily backward compatible, enabling the master and slave to run different versions of database software, or even different storage engines.
read-after-write consistency problem
Reading Your Own Writes
Many apps let users submit some data and then view what they submitted. It could be a record in a user database, or it could be a comment on a discussion thread, or something like that. When new data is submitted, it must be sent to the master, but when a user views the data, it can be read from the slave. This is very appropriate if data is frequently viewed, but only occasionally written.
But with asynchronous replication, if a user looks at the data right after it is written, the new data may not have reached the replica yet. To the user, it will appear as if the data just committed is lost.
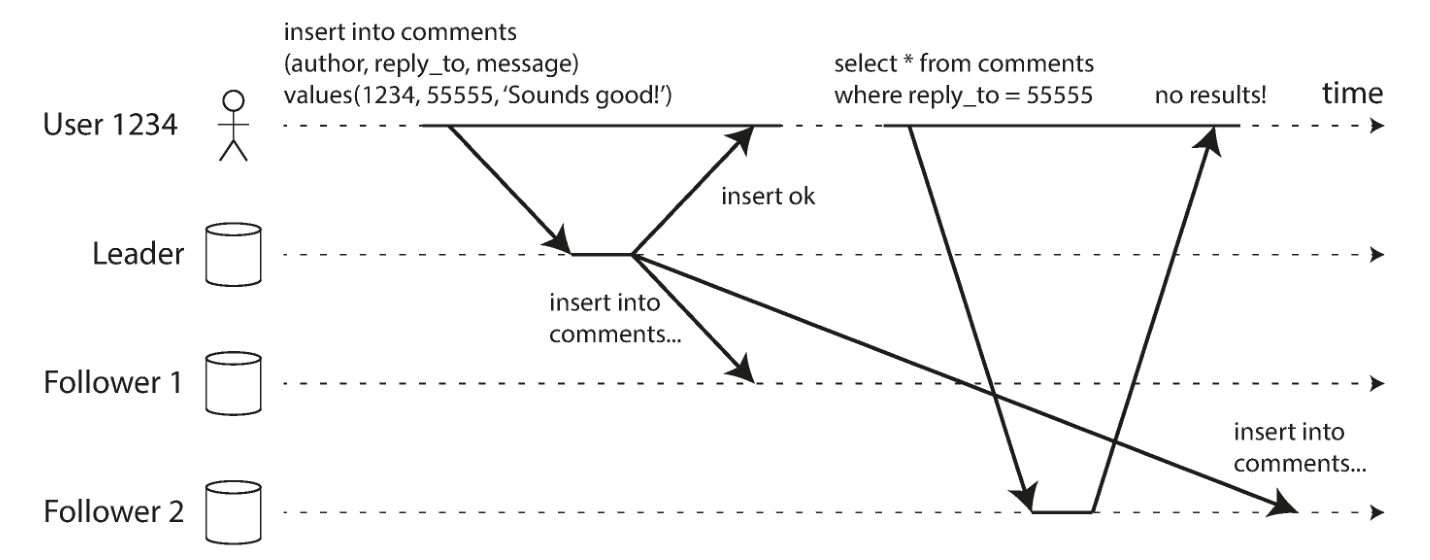
In this case, we need read-after-write consistency (read-after-write consistency), also known as read-your-writes
consistency. This is a guarantee that if the user reloads the page, they will always see any updates they submitted themselves.
Achieving read-after-write consistency in a leader-based replication system:
- For content that the user may have modified, always read from the main repository ; this requires a way to know whether the user has modified something without actually querying it.
- If most of the content in the application is likely to be edited by the user, in this case other criteria can be used to decide whether to read from the main library. For example, you can track the time of the last update, and read from the main library within one minute after the last update.
- The client can remember the timestamp of the last write, and the system needs to ensure that when the slave library processes the user’s read request, all changes before the timestamp have been propagated to the slave library. If the current slave library is not new enough, you can read from another slave library, or wait for the slave library to catch up. The timestamp here can be either a logical timestamp (something indicating write order, such as a log sequence number) or an actual system clock
- There is additional complexity if your replicas are spread across multiple datacenters (for geographical proximity to users or for availability purposes). Any requests that need to be serviced by a master must be routed to the data center containing that master.
Another complication occurs when the same user requests services from multiple devices , such as a desktop browser and a mobile app. In this case, it may be necessary to provide read-after-write consistency across devices: if the user enters some information on one device and then views it on another device, they should see the information they just entered.
In this case, there are a few more things to consider:
- The method of remembering the timestamp of the user’s last update becomes more difficult because a program running on one device has no idea what happened on the other. Centralized storage of these metadata is required.
- If replicas are distributed across different data centers, it is difficult to guarantee that connections from different devices will be routed to the same data center. If your method needs to read the main library, you may first need to route requests from all of the user’s devices to the same data center.
Monotonic Reads monotonic read
Moving backward in time can happen if the user does multiple reads from different slaves. For example, user 2345 makes the same query twice, first querying a slave with a small delay and then a slave with a higher delay, the first query returns the most recent comment added by user 1234, but the second query Returns nothing because the lagging slave has not yet pulled the write. It would be very confusing for user 2345 to see user 1234’s comment and then see it disappear.
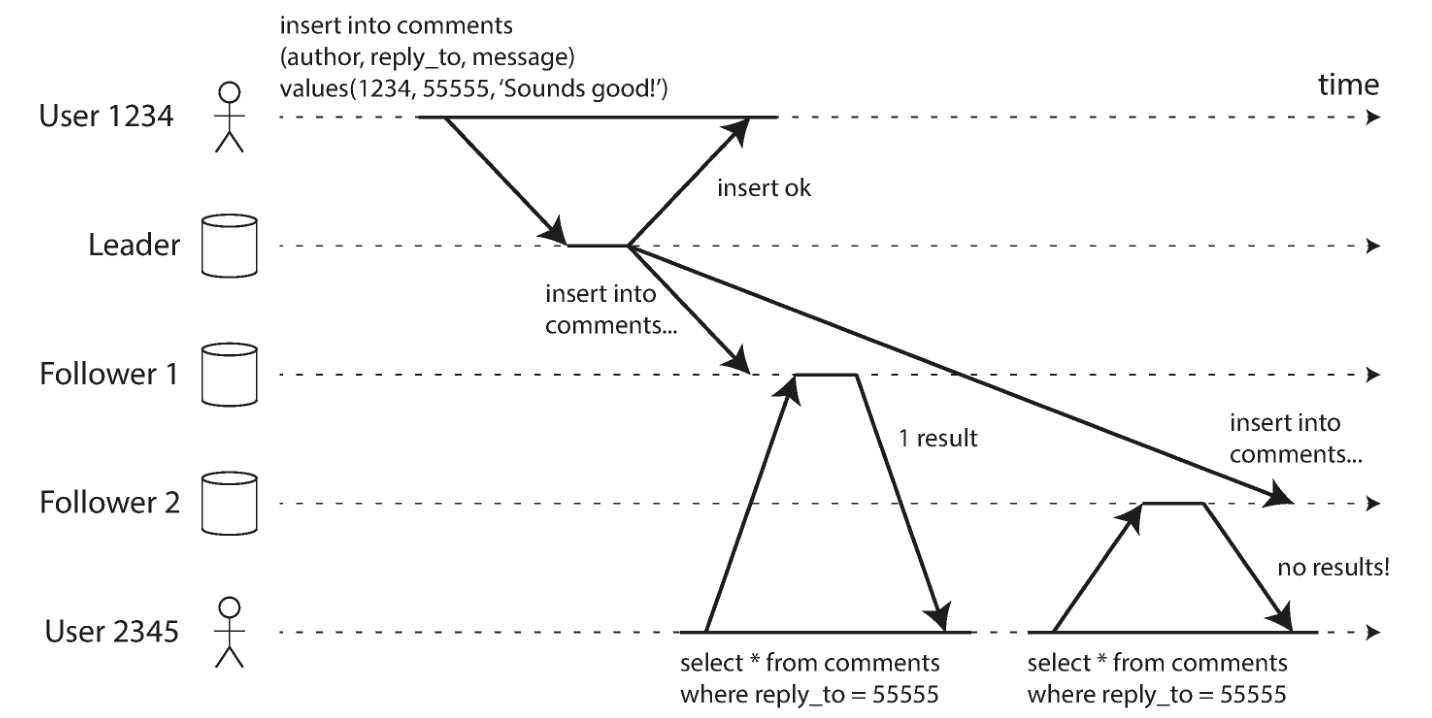
Monotonic reads This is a guarantee that is weaker than strong consistency , but stronger than eventual consistency . When reading data, you may see an old value; monotonic reads only mean that if a user does multiple reads sequentially, they will not see time go back, that is, if they have already read Newer data, subsequent reads will not get older data.
One way to achieve monotonic reads is to ensure that each user always reads from the same replica, eg a replica can be selected based on a hash of the user ID.
multi-master replication
Suppose you have a database with replicas spread across several different datacenters (perhaps to tolerate failure of a single datacenter, or to be geographically closer to users). There can be masters in each data center in a multi-master configuration.
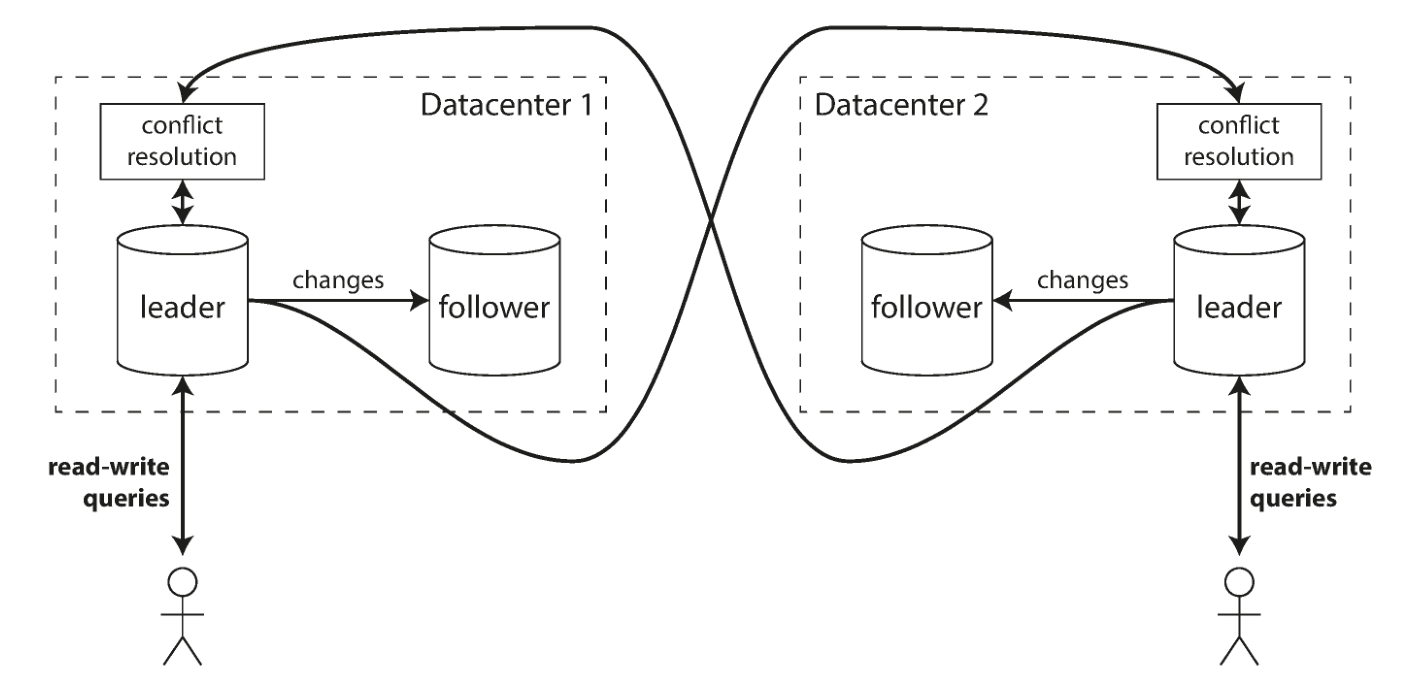
There are many advantages in operating and maintaining multiple data centers with multiple masters. For example, in a multi-master configuration, each write operation can be processed in the local data center nearby, and the performance will be better; each data center can be independent from other data centers. The data center continues to operate, and the failure of other data centers will not cause global paralysis;
Multi-master configuration also has a big disadvantage: two different data centers may modify the same data at the same time, and write conflicts must be resolved.
Handle write conflicts
avoid confict
The simplest strategy for dealing with conflicts is to avoid them. If an application can ensure that all writes to a particular record go through the same master, then conflicts will not occur. For example, in an application where users can edit their own data, you can ensure that requests from a particular user are always routed to the same data center and use that data center’s master library for reading and writing. Different users may have different “primary” data centers.
But it is also possible that because of a data center failure, you need to reroute traffic to another data center, in which case conflict avoidance will fail and you have to deal with the possibility of simultaneous writes by different masters.
Converge to a consistent state
In a multi-master configuration, since there is no clear order of writes, if each replica just wrote in the order it saw writes, the database would end up in an inconsistent state. So there needs to be a way to converge to the same final value when all changes are replicated.
For example, each replica can be assigned a unique ID, and writes with higher ID numbers have higher priority, but this method also means data loss.
User’s own processing
This operation is directly handed over to the user, and the user is allowed to resolve the conflict before reading or writing. This kind of example is not uncommon, and Github adopts this method.
masterless replication
In some masterless replication implementations, clients send writes directly to several replicas, while in others, a coordinator node writes on behalf of the client.
In a masterless configuration, there is no failover. Suppose a client (user 1234) sends a write to all three replicas in parallel, and two available replicas accept the write, but the unavailable replica misses it. It is sufficient to assume that two of the three replicas acknowledge the write: after user 1234 has received two positive responses, we consider the write to be successful.
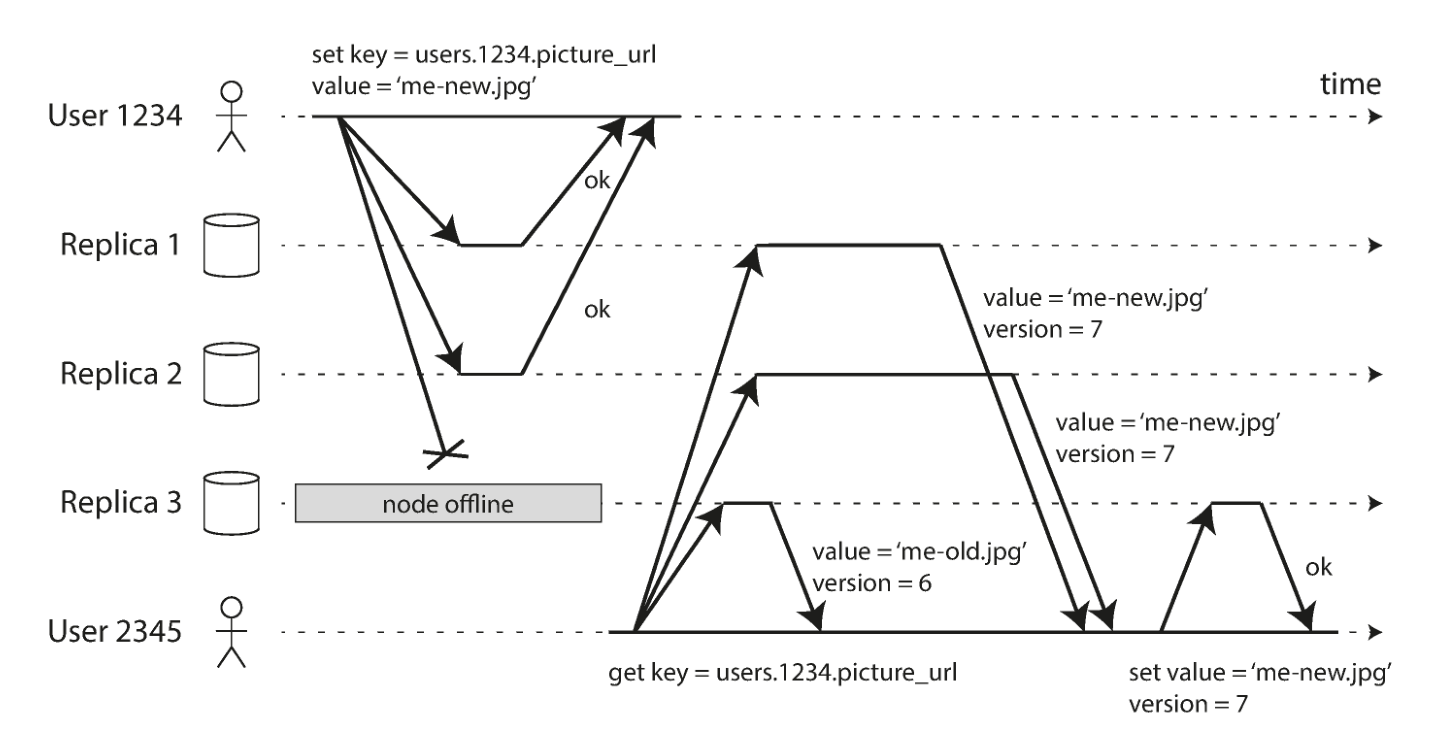
Because there may be nodes that don’t write successfully, when a client reads data from the database, it doesn’t just send its request to one replica, but to multiple replicas in parallel. Clients may get different responses from different replicas, and then use the version number to determine which value is newer.
So how does it catch up to the writes it missed after an unavailable node comes back online? Generally speaking, there are two methods:
- Read repair (Read repair), when the client reads multiple nodes in parallel and finds that the value of some copy is old, it writes the new value back to the copy;
- Anti-entropy process, a background process that continually looks for data differences between replicas and copies any missing data from one replica to another.
In the example above, the write was successful when processing was performed on two of the three replicas. So how many replicas need to be successfully written in a cluster with multiple replicas?
In general, if there are n replicas, each write must be acknowledged by w nodes to be considered successful, and we must query at least r nodes for each read. We can expect to get the latest value on read as long as w + r > n , r and w being the minimum number of votes required for efficient reads and writes.
However, quorums (as described thus far) are not as fault-tolerant as they could be. A network outage can easily cut clients off from a large number of database nodes. While these nodes are alive and other clients may be able to connect to them, they may also be dead as seen from the client that the database node is cut off from. In this case, there may be fewer than w or r remaining available nodes, so clients can no longer reach a quorum.
Detect concurrent writes
Events may arrive at different nodes in a different order due to variable network latency and failure of some nodes. Then there will be data inconsistencies. For example, the following figure shows that two clients A and B write to the key X in the three-node data store at the same time:
- Node 1 receives writes from A, but does not receive writes from B due to a temporary outage.
- Node 2 first receives the write from A, and then receives the write from B.
- Node 3 receives writes from B first, followed by writes from A.
If each node simply overwrites a key whenever it receives a write request from a client, the nodes will be permanently inconsistent.
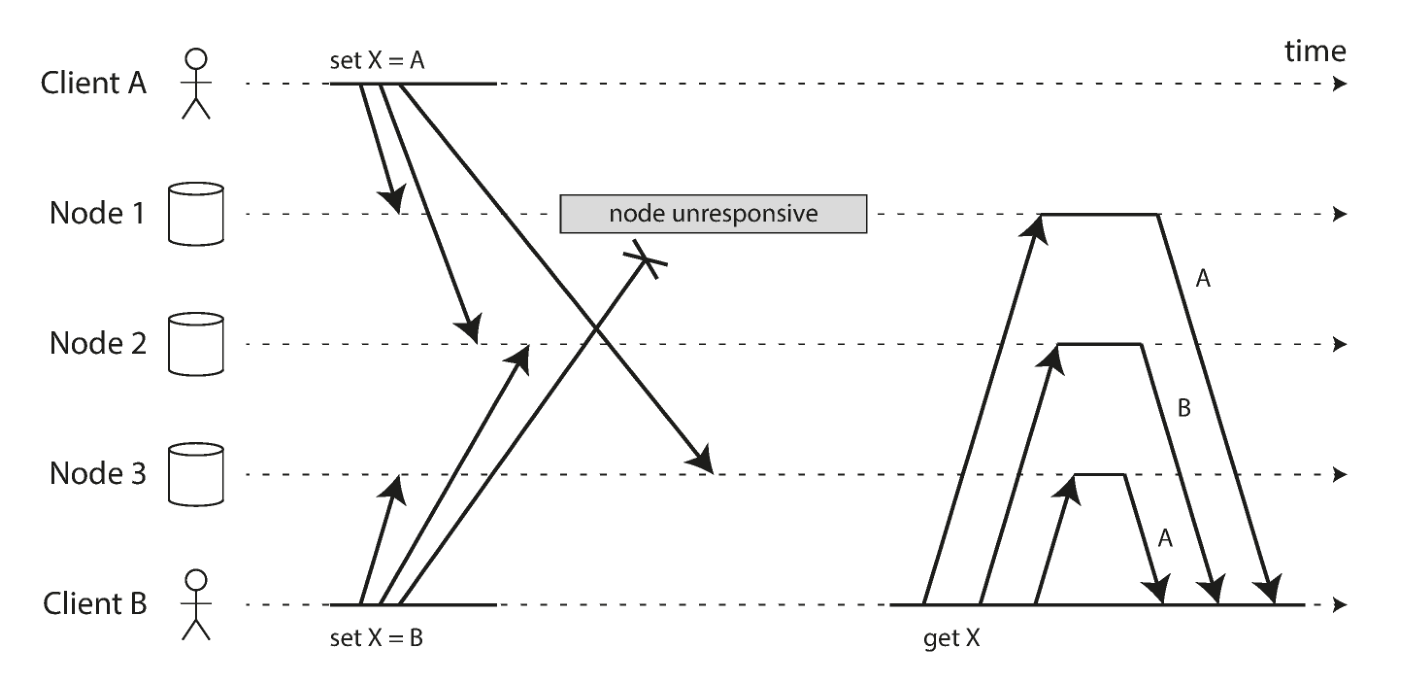
One solution is Last write wins (discarding concurrent writes). The so-called Last write wins only need to store the “recent” value and allow the “older” value to be overwritten and discarded. The implementation could actually append a timestamp to each write, then pick the largest timestamp as “recent” , and discard any writes with an earlier timestamp.
Partition
Partitioning is often used in conjunction with replication so that copies of each partition are stored on multiple nodes, and a node may also store multiple partitions. Each partition leader (master) is assigned to a node, and followers (slaves) are assigned to other nodes. Each node may be the master library for some partitions and the slave library for other partitions.
Let me use TiKV, which is stored in TiDB, as an example. TiKV data is stored in Regions, and a Region is a partition. When the size of a Region exceeds a certain limit (default is 144MB), TiKV will split it into two or more Regions to ensure that the sizes of each Region are roughly similar. Similarly, when a Region is deleted due to a large number of If the size of the Region becomes smaller due to the request, TiKV will merge the two smaller adjacent Regions into one.
After dividing the data into Regions, TiKV will try to ensure that the number of Regions served on each node is about the same, and perform Raft replication and member management in units of Regions. That is, as shown in the figure below, you can see that different node nodes actually have a copy of the Region.
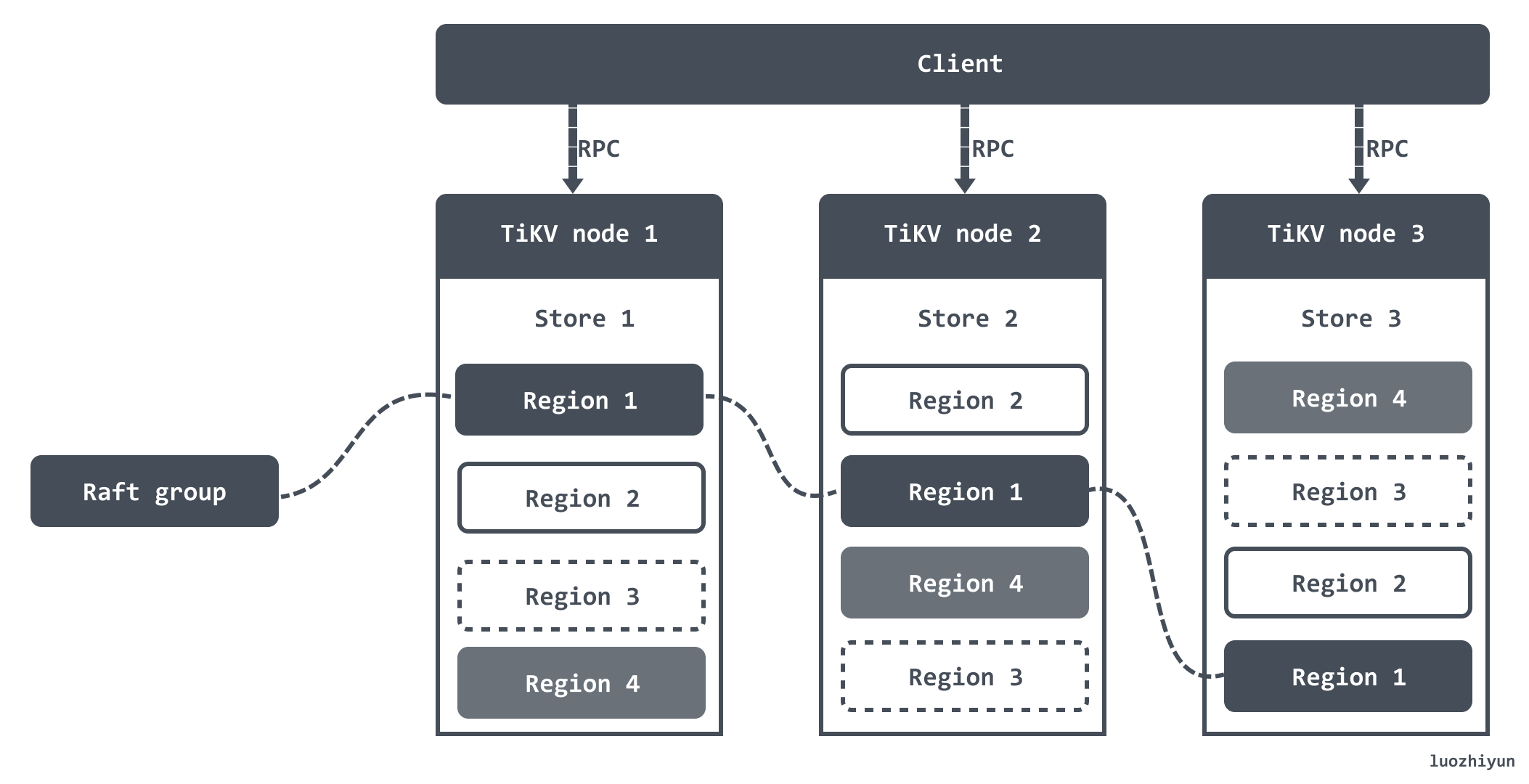
Partition division
Assuming you have a lot of data and want to partition it, how do you decide which records to store on which nodes? The goal of partitioning is to evenly distribute data and query load across nodes. If partitioning is unfair and some partitions have more data or queries than others, we call it skew. Unbalanced load may lead to inconsistency among different nodes. A partition with high load is called a hot spot, which loses the load-balancing feature of the partition, which needs to be avoided.
In fact, the easiest way is to randomly assign records to nodes. This will distribute the data evenly across all nodes, but it has a big disadvantage: when you try to read a particular value, you have no way of knowing which node it is on, so you have to query all nodes in parallel, which Obviously unscientific.
So now there are two typical solutions:
- Range: Range is divided according to Key, and a certain continuous Key is stored on one storage node.
- Hash: Hash is done according to the Key, and the corresponding storage node is selected according to the Hash value.
Partitioning by Range of Keys
So without randomization, one way to partition is to assign each partition a contiguous range of keys (from min to max). But the range of keys isn’t necessarily evenly distributed, because the data most likely isn’t evenly distributed either. In order to evenly distribute data, partition boundaries need to be adjusted according to the data.
Partition boundaries can be chosen manually by the administrator or automatically by the database, and then within each partition we can store the keys in a certain order.
For TiDB, it is also partitioned according to the range of the key. Each partition is called a Region. Because it is ordered, it can be described by a left-closed right-open interval such as [StartKey, EndKey). Then it adjusts the boundary according to the size of the Region. By default, a new Region will be created when the size of a Region is 96 MiB.
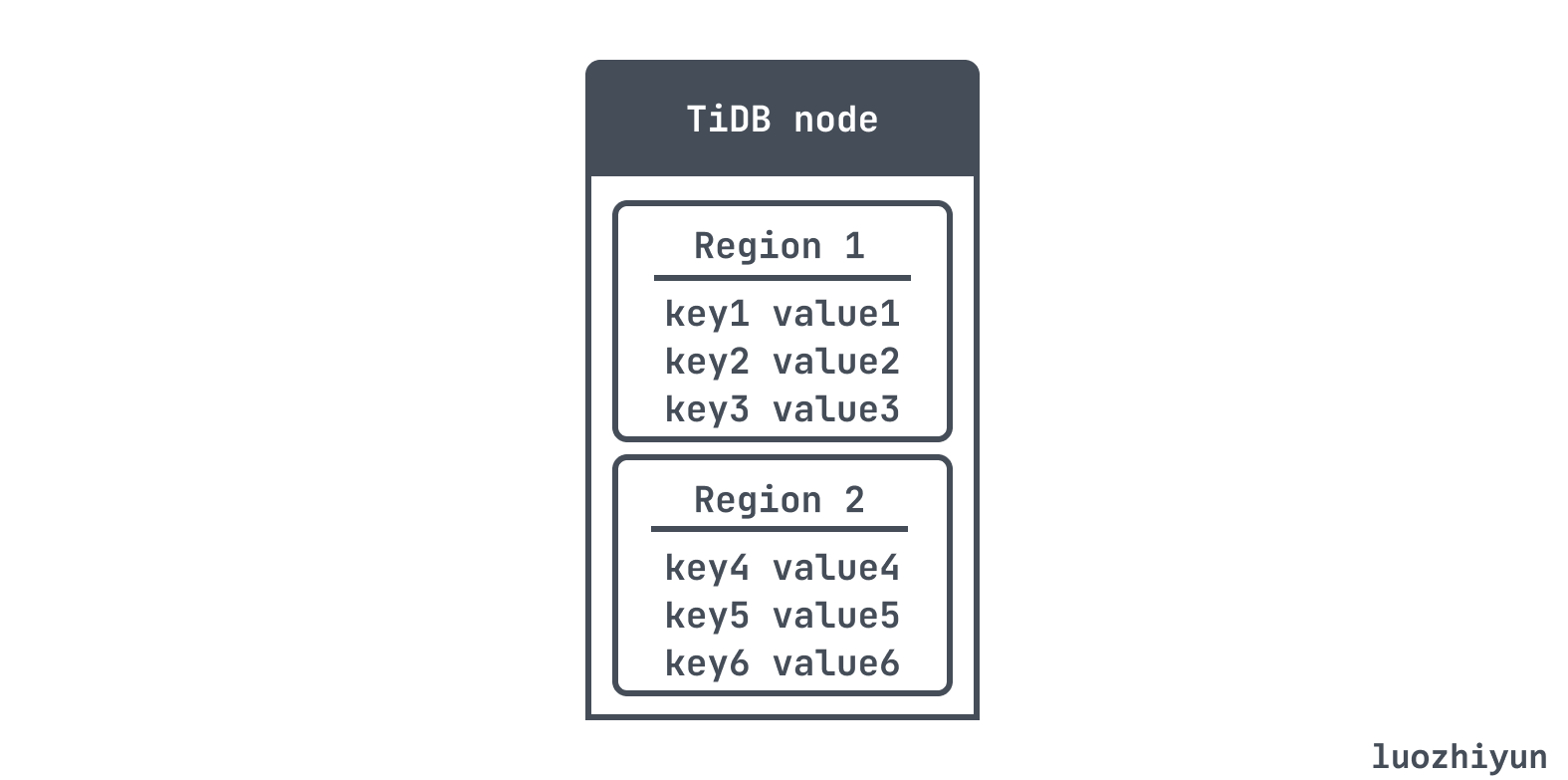
Another problem with partitioning based on range is that specific access patterns can lead to hotspots. If the primary key is a timestamp and a partition is assigned to each day, the partition of the day’s data may be overloaded due to writing, so you need to use it in addition to the timestamp. Something other than as the first part of the primary key.
Hash partition by key
Hash partitioning is through the hash hash function, whenever a new string input is given, it will return a “random” number between 0 and 2^32 -1. Even if the input strings are very similar, their hashes will be evenly distributed within this number range. Each partition is then assigned a hash range, and every key that hashes within the partition range will be stored in that partition.

But this also has disadvantages. It loses the ability to efficiently execute range queries. Therefore, for relational databases, because table scans or index scans are often required, range sharding strategies are basically used, such as the nosql database redis cluster. It is a Hash partition.
partition rebalancing
fixed number of partitions
The above mentioned the Hash partition based on the key, so how to store it in the partition according to the hash value? A simple idea is to make the number of partitions equal to the number of machine nodes, and take the modulo according to the number of partitions, that is, hash(key) % 分区数. So what if you want to add a new partition? How to migrate data from one partition to another partition? The cost of this kind of data migration will actually be very high.
There is another way to do this: create more partitions than nodes, and assign multiple partitions to each node. For example, a database running on a 10-node cluster might be split into 1,000 partitions from the start, so approximately 100 partitions are assigned to each node. If a node is added to the cluster, the new node can steal some partitions from every current node until the partitions are distributed fairly again.
Only the movement of partitions between nodes. The number of partitions does not change, nor does the partition specified by the key. The only thing that changes is the node where the partition resides.
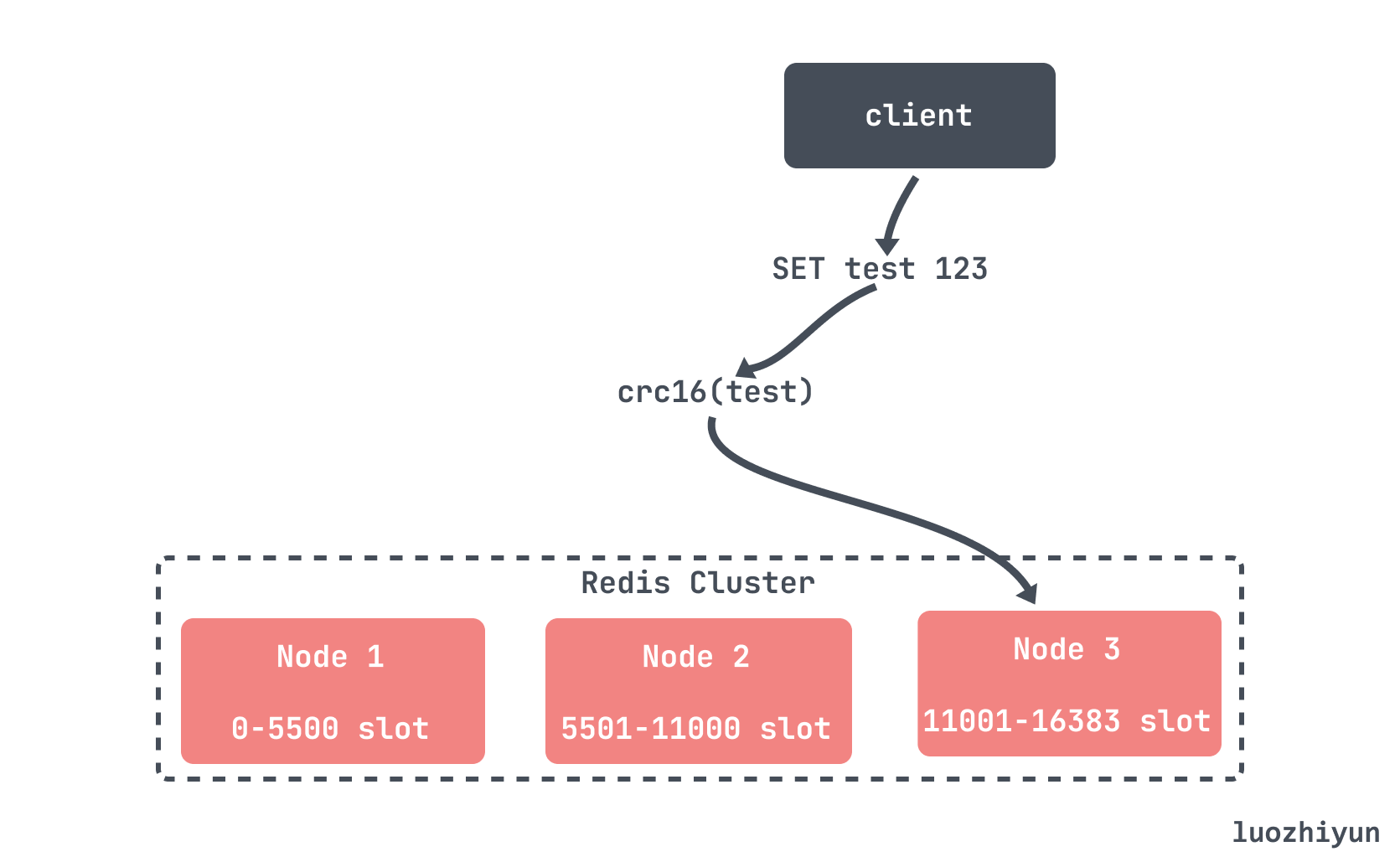
Redis cluster adopts this method. Redis Cluster defines a total of 16384 slots for the entire cluster. A slot is a partition, and each node is responsible for a part of the slot. Then the key will locate the slot according to the result calculated by crc16 and the modulus of 16384, so as to locate the specific node.
dynamic partition
For a database partitioned according to the range of the key, it will be very inconvenient to have a fixed number of partitions with a fixed boundary, so it is generally automatically partitioned when the partition grows beyond the configured size. I also mentioned TiDB above, which is based on the size of the partition. To adjust the boundary, a new partition will be created when a partition is 96MB by default.
In addition to splitting, partitions can also be merged. TiDB will trigger the merge if the size of the partition and the number of keys are less than 20MB by default and the number of keys is less than 200,000.
routing
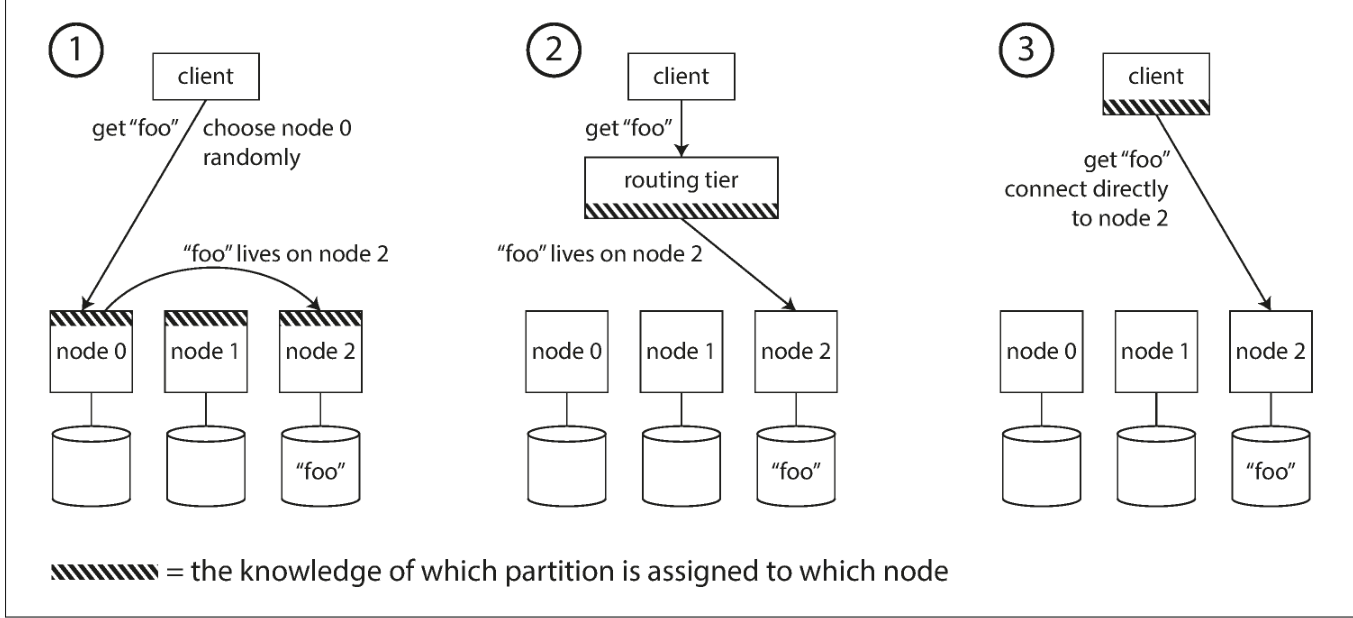
The last thing to talk about is routing. How does the client know which partition the data I want to check is in. Generally speaking, there are three ways:
- Let the client connect to any node. If the data happens to be on this node, then you can directly query; if the data is not on this node, this node will forward the request to the node where the data is located. This kind of cluster is decentralized Yes, Redis Cluster is this kind of architecture, and the nodes exchange information through the gossip protocol;
- The client first needs to connect to the routing layer of the cluster. The routing layer knows which partition and node the requested data is in. TiDB has this kind of architecture. The PD in the TiDB cluster is responsible for managing the routing information of all partitions. TiDB needs to access a certain partition. When partitioning data, you need to query the status and location of the partition from PD first;
- The last way is that the client itself saves the partition and node information, so that the client can directly query the desired data and return it.
Summarize
This article mainly summarizes the details of some main technologies of replication and partitioning, discusses the similarities and differences of various implementation methods, as well as possible problems, and then combines the current mainstream databases to explain how to implement them.
Whether it is replication or partitioning, it revolves around availability, performance, and scalability. For replication, there are mainly single-master replication, multi-master replication, and no-master replication.
At present, single-master replication is the most popular. Many distributed databases use single-master replication + partition architecture to provide high-throughput support, and single-master replication does not need to worry about conflict resolution, which is easier to implement. However, single-master replication may also cause data loss due to asynchronous replication leader downtime, so many of them are replicated in a semi-synchronous manner. For example, Kafka adds an ISR anti-loss mechanism. ISR has a set of reliable backup sets. When all the machines in the ISR are successfully replicated, the message is considered to be submitted successfully.
Next, we will talk about strange behaviors caused by replication delays. For example, if data is written in the master database, but it has not been synchronized to the slave database, then the data will not be found; The data from Kucha are also different.
The next step is partitioning. This technology is used in many distributed databases. It is mainly used for scalability, because different partitions can be placed on different nodes in the non-shared cluster, so concurrent loads can be distributed to different processing. On the server, new partitions can be added when the load increases, and partitions can also be merged when the load decreases.
Partitioning needs to consider how to divide the partition, generally divided by range and divided by hash. It is also necessary to consider the rebalancing of partitions, and how to distribute the number of partitions when adding new nodes so that the load can be evenly distributed. Then there is routing, which partition and node the client’s request should be routed to.
Reference
《Designing Data-Intensive Application》
https://tech.meituan.com/2022/08/25/replication-in-meituan-01.html

Database data replication and partition first appeared on luozhiyun`s Blog .
This article is transferred from: https://www.luozhiyun.com/archives/805
This site is only for collection, and the copyright belongs to the original author.