Please declare the source for reprinting~, this article was published on luozhiyun’s blog: https://www.luozhiyun.com/archives/667
Redis 5.0 source code used in this article
Overview
When we learn Redis’s Hash table, we will inevitably think of other Hash table implementations in our minds, and then make a comparison. Usually if we want to design a Hash table, then we need to consider the following issues:
- whether there are concurrent operations;
- How to resolve Hash conflicts;
- How to expand.
For Redis, first of all, it is a single-threaded working mode, so there is no need to consider concurrency issues, this question passes.
For the resolution of Hash conflict, there are usually open addressing method, re-hashing method, zipper method and so on. However, most programming languages use the zipper method to implement the hash table. Its implementation complexity is not high, and the average search length is relatively short. The memory used for each storage node is dynamically allocated, which can save a lot. of storage space.
Therefore, for Redis, the zipper method is also used to solve the hash conflict. As shown below, the nodes are strung together by a linked list:
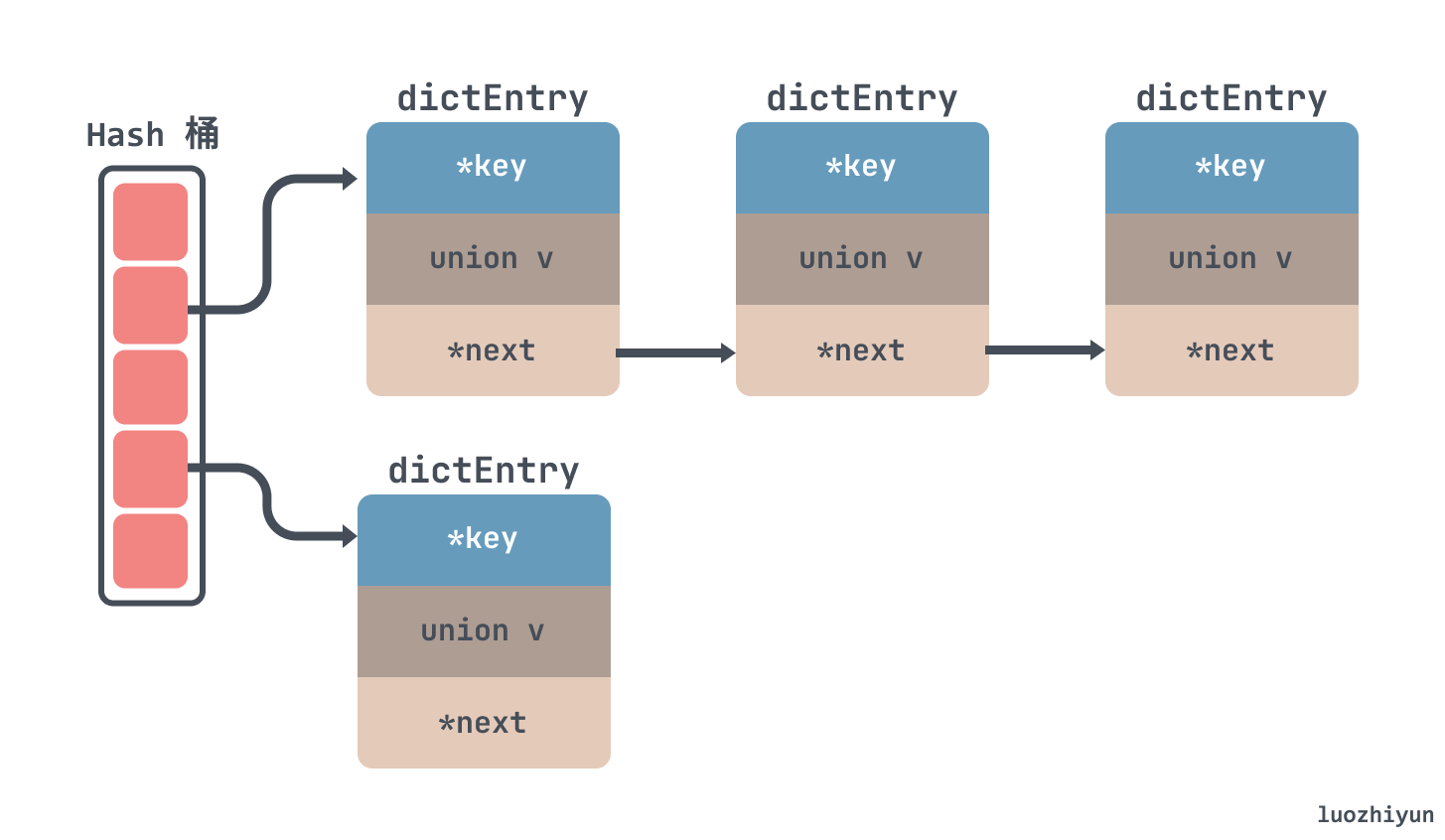
As for why there is no red-black tree like JDK’s HashMap to resolve conflicts, I think there are actually two aspects. On the one hand, it takes time and cost to convert the linked list to red and black numbers, which will affect the operation efficiency of the linked list; on the other hand, the red-black number In fact, the efficiency of a tree is not as good as a linked list when there are fewer nodes.
Let’s take a look at expansion. For expansion, we generally need to create a new block of memory, and then migrate the old data to the new memory block. Because this process is single-threaded, the main thread cannot be blocked for a long time when expanding. , In Redis, progressive rehash + timed rehash is used.
Progressive rehash will first determine whether the current dictionary is rehashing before performing additions, deletions, and changes. If so, rehash a node. This is actually a divide and conquer idea. By dividing the big task into small tasks, each small task only executes a small part of the data, and finally the entire large task is completed.
Timed rehash If the dict has no operation and cannot migrate data incrementally, the main thread will perform a migration operation every 100ms by default. Here, data will be migrated with 100 buckets as the basic unit at a time, and if an operation takes a timeout of 1ms, the task will end, and the migration will be triggered again next time
Redis sets two tables ht[0] and ht[1] in the structure. If the current capacity of ht[0] is 0, it will directly give 4 capacities for the first time; if it is not 0, then the capacity will be directly turned over times, and then put the new memory into ht[1] to return, and set the flag 0 to indicate that it is expanding.
The operation of migrating hash buckets will migrate one hash bucket at a time from ht[0] to ht[1] when adding, deleting, modifying and checking the hash table. After the migration and copying of all buckets, the space of ht[0] will be released. Then assign ht[1] to ht[0] , reset the size of ht[1] to 0, and set the flag 1 to indicate that the rehash is over.
For the search, in the process of rehash, because there is no concurrency problem, the search for dict will also search for ht[0] and then ht[1] in turn.
Design and Implementation
The hash implementation of Redis is mainly in the two files dict.h and dict.c.
The data structure of the hash table is roughly as follows, I will not post the code of the structure, the fields are marked on the figure:
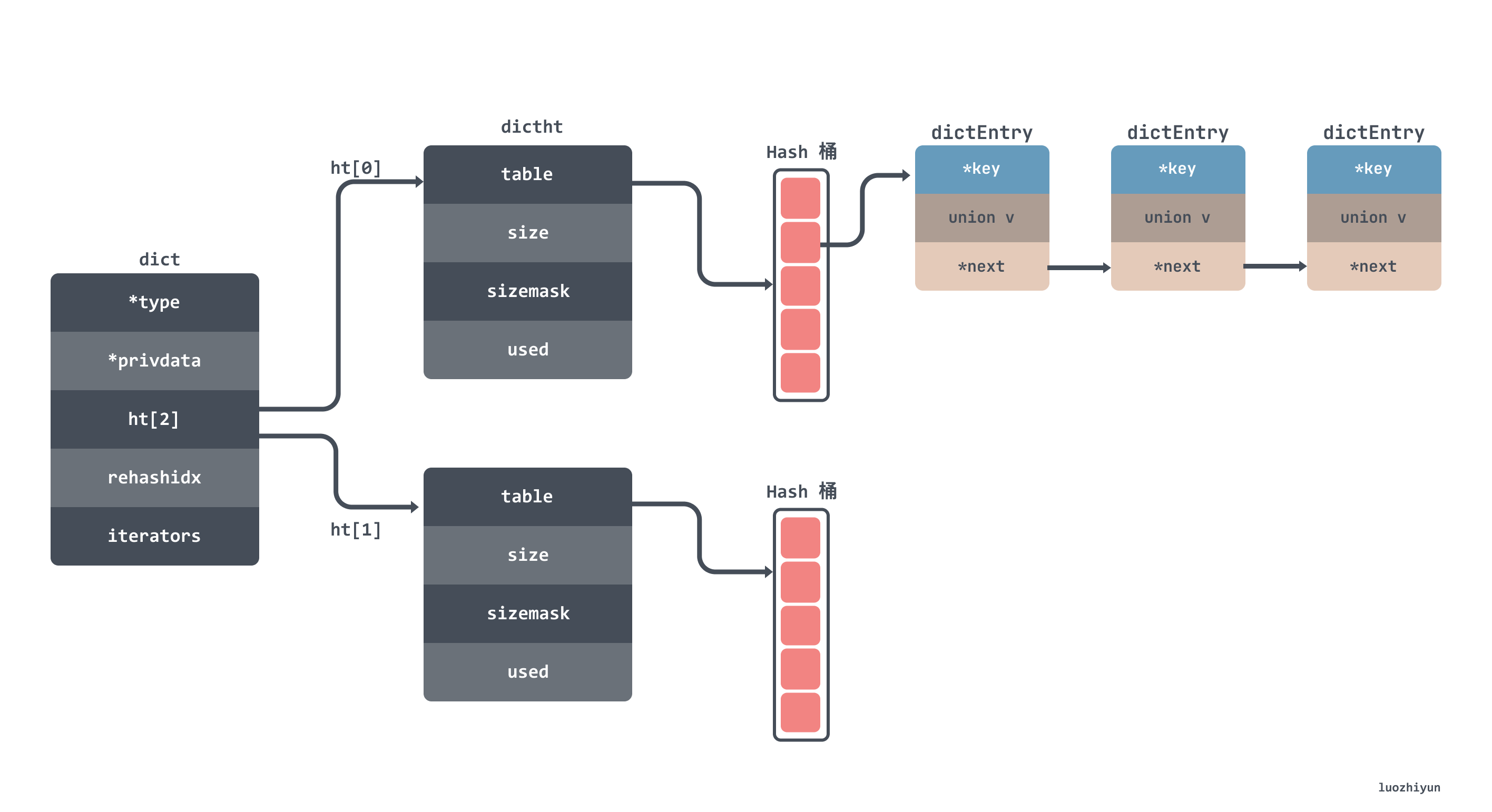
From the above figure, you can also see that there is a dictht array with a space of 2 in the hash table. This array is used to save data alternately when doing rehash. The rehashidx in the dict is used to indicate whether rehash is being performed.
When is the scaling triggered?
Many hash tables can only be expanded, but dict has both expansion and contraction in Redis.
Expansion
In fact, expansion is generally to check whether a certain threshold is reached when adding elements, and then decide whether to expand. So after searching, you can see that adding an element will call the function dictAddRaw , and we can also know that it is the underlying function of add or lookup through the annotation of the function.
Low level add or find:
This function adds the entry but instead of setting a value returns the dictEntry structure to the user, that will make sure to fill the value field as he wishes.
The dicAddRaw function will call the _dictKeyIndex function, which will call _dictExpandIfNeeded to determine whether expansion is required.
┌─────────────┐ ┌─────────┐ ┌─────────────┐ ┌─────────────────────┐ │ add or find ├────►│dicAddRaw├─────►│_dictKeyIndex├─────►│ _dictExpandIfNeeded │ └─────────────┘ └─────────┘ └─────────────┘ └─────────────────────┘ _dictExpandIfNeeded function determines that there are roughly three situations in which expansion will occur:
- If the size of the hash table is 0, then create a hash table with a capacity of 4;
- The server is not currently performing rdb or aof operations, and the load factor of the hash table is greater than or equal to
1; - The server is currently performing rdb or aof operations, and the load factor of the hash table is greater than or equal to
5;
The load factor of the hash table can be calculated by the formula:
// load ratio = the number of elements / the buckets load_ratio = ht[0].used / ht[0].size
For example, for a hash table of size 4 containing 4 key-value pairs, the load factor for the hash table is:
load_ratio = 4 / 4 = 1
For another example, for a hash table with a size of 512 and containing 256 key-value pairs, the load factor of this hash table is:
load_ratio = 256 / 512 = 0.5
Why should it be judged whether it should be expanded based on the combined load factor of rdb or aof operations? In fact, it is also mentioned in the comments of the source code:
as we use copy-on-write and don’t want to move too much memory around when there is a child performing saving operations.
That is to say, increasing the load factor required to perform the expansion operation during copy-on-write can avoid the hash table expansion operation during the existence of the child process as much as possible, which can avoid unnecessary memory write operations, and maximize the This saves memory and improves the performance of subprocess operations.
We have finished the logic, let’s take a look at the source code:
static int _dictExpandIfNeeded(dict *d) { // 正在扩容中if (dictIsRehashing(d)) return DICT_OK; // 如果hash 表的size为0,那么创建一个容量为4的hash表if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); // hash表中元素的个数已经大于hash表桶的数量if (d->ht[0].used >= d->ht[0].size && //dict_can_resize 表示是否可以扩容(dict_can_resize || // hash表中元素的个数已经除以hash表桶的数量是否大于5 d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) { return dictExpand(d, d->ht[0].used*2); // 容量扩大两倍} return DICT_OK; }
From the above source code, we can know that if the size of the used space of the current table is size, then the table will be expanded to the size of size*2. The new dict hash table is created by dictExpand.
int dictExpand(dict *d, unsigned long size) { //正在扩容,直接返回if (dictIsRehashing(d) || d->ht[0].used > size) return DICT_ERR; dictht n; // _dictNextPower会返回size 最接近的2的指数值// 也就是size是10,那么返回16,size是20,那么返回32 unsigned long realsize = _dictNextPower(size); // 校验扩容之后的值是否和当前一样if (realsize == d->ht[0].size) return DICT_ERR; // 初始化dictht 成员变量n.size = realsize; n.sizemask = realsize-1; n.table = zcalloc(realsize*sizeof(dictEntry*)); // 申请空间是size * Entry的大小n.used = 0; //校验hash 表是否初始化过,没有初始化不应该进行rehash if (d->ht[0].table == NULL) { d->ht[0] = n; return DICT_OK; } //将新的hash表赋值给ht[1] d->ht[1] = n; d->rehashidx = 0; return DICT_OK; }
This piece of code is still relatively clear, you can follow the comments above to look at it a little bit.
shrink
After talking about expansion, let’s take a look at shrinking. Students who are familiar with Redis know that in Redis, one is lazy deletion for cleaning expired data, and the other is regular deletion. In fact, shrinking is also done in regular deletion.
The Redis timer will call the databasesCron function every 100ms, and it will call the dictResize function to shrink:
┌─────────────┐ ┌──────────────────┐ ┌──────────┐ ┌──────────┐ │databasesCron├──►│tryResizeHashTable├──►│dictResize├──►│dictExpand│ └─────────────┘ └──────────────────┘ └──────────┘ └──────────┘The same dictResize function will also judge whether rehash is being executed and whether dict_can_resize is performing copy on write operation. Then reduce the bucket size of the hash table to the same size as the key-value pair:
int dictResize(dict *d) { int minimal; if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR; minimal = d->ht[0].used; // 将bucket 缩小为和被键值对同样大小if (minimal < DICT_HT_INITIAL_SIZE) minimal = DICT_HT_INITIAL_SIZE; return dictExpand(d, minimal); }
Finally, call dictExpand to create a new space and assign it to ht[1].
How does data migration work?
We also mentioned above that, whether it is expansion or contraction, the new space created will be assigned to ht[1] for data migration. Then perform data migration in two places, one is triggered when adding, deleting, modifying and checking the hash table, and the other is triggered regularly
Triggered when adding, deleting, modifying, and querying the hash table
When adding, deleting, modifying and checking, the rehashidx parameter will be checked to check whether the migration is in progress. If it is migrating, the _dictRehashStep function will be called, and then the dictRehash function will be called.
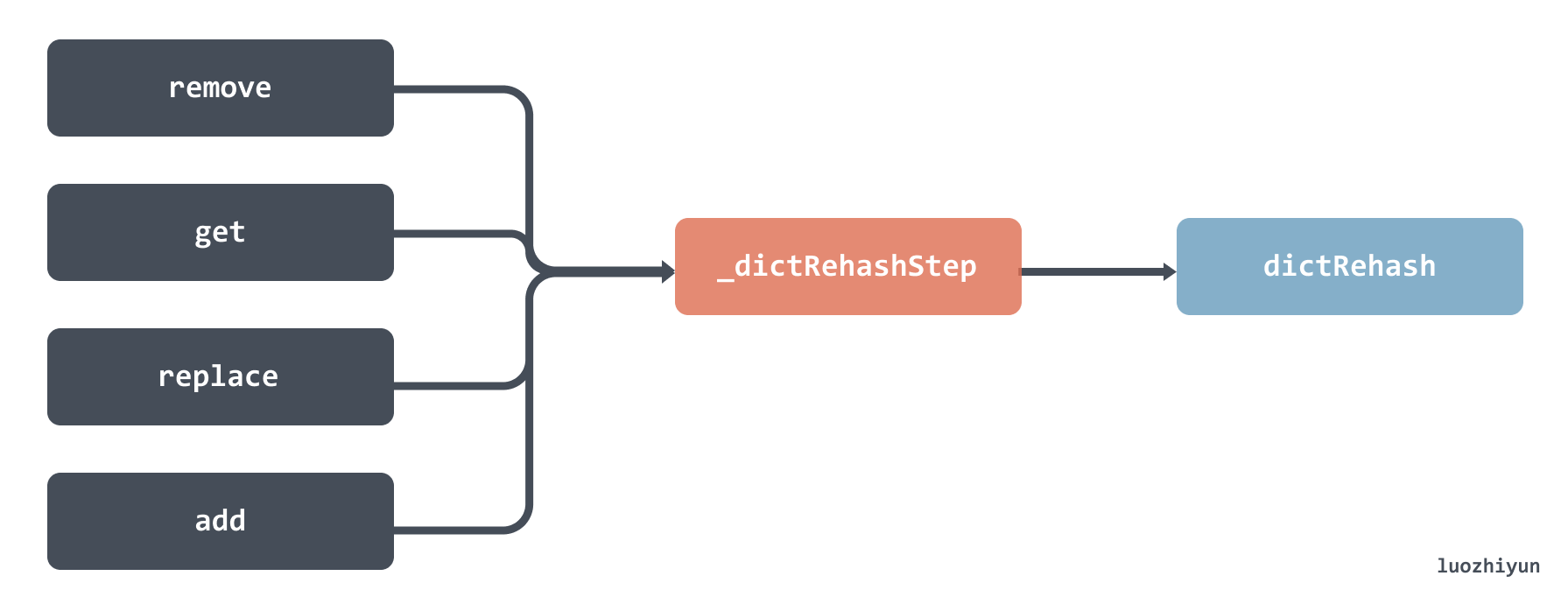
However, it should be noted that the size passed in by calling the dictRehash function here is 1, which means that only one bucket is migrated at a time. Let’s take a look at the dictRehash function, which is the most important function in the entire migration process. This function mainly does the following things:
- Check whether the number of buckets currently migrated has reached the online limit, and whether ht[0] still has elements;
- Determine whether the current migration bucket slot is empty. The maximum number of empty slots accessed cannot exceed n*10, where n is the number of buckets in this migration;
- Obtain the entry list in the non-empty slot for circular migration;
- First get the index of the new slot of ht[1];
- One node is placed in the head of the new bucket;
- until all migrations are completed;
- After migration, empty the bucket corresponding to the old hash table ht[0];
- Check if the rehash has been completed, then you need to free the memory footprint and assign ht[1] to ht[0];
If you are interested, you can take a look at the following source code, which has been marked with comments:
int dictRehash(dict *d, int n) { // 最大的空bucket访问次数int empty_visits = n*10; /* Max number of empty buckets to visit. */ if (!dictIsRehashing(d)) return 0; // 校验当前迁移的bucket数量是否已达上线,并且ht[0]是否还有元素; while(n-- && d->ht[0].used != 0) { dictEntry *de, *nextde; assert(d->ht[0].size > (unsigned long)d->rehashidx); // 判断当前的迁移的bucket槽位是否为空while(d->ht[0].table[d->rehashidx] == NULL) { d->rehashidx++; if (--empty_visits == 0) return 1; } // 获取到槽位里面entry 链表de = d->ht[0].table[d->rehashidx]; // 从老的bucket迁移数据到新的bucket中while(de) { uint64_t h; nextde = de->next; // hash之后获取新hash表的bucket槽位h = dictHashKey(d, de->key) & d->ht[1].sizemask; // 一个个节点放置到新bucket的头部de->next = d->ht[1].table[h]; d->ht[1].table[h] = de; d->ht[0].used--; d->ht[1].used++; de = nextde; } // 迁移完了将旧的hash表对应的bucket置空d->ht[0].table[d->rehashidx] = NULL; d->rehashidx++; } // 如果已经rehash完了,那么需要free掉内存占用,并将ht[1]赋值给ht[0] if (d->ht[0].used == 0) { zfree(d->ht[0].table); d->ht[0] = d->ht[1]; _dictReset(&d->ht[1]); d->rehashidx = -1; return 0;// 返回0表示迁移已完成} return 1; // 返回1表示迁移未完成}
timing trigger
The timing trigger is triggered by the databasesCron function. This function will run every 100ms , and will eventually call the dictRehash function mentioned above through the dictRehashMilliseconds function.
┌─────────────┐ ┌───────────────────┐ ┌──────────────────────┐ ┌──────────┐ │databasesCron├──►│incrementallyRehash├──►│dictRehashMilliseconds├──►│dictRehash│ └─────────────┘ └───────────────────┘ └──────────────────────┘ └──────────┘The ms parameter passed in by the dictRehashMilliseconds function indicates how long it can run. The default is 1, that is, the function will exit after running for 1ms:
int dictRehashMilliseconds(dict *d, int ms) { long long start = timeInMilliseconds(); int rehashes = 0; // 每次会迁移100 个bucket while(dictRehash(d,100)) { rehashes += 100; if (timeInMilliseconds()-start > ms) break; } return rehashes; }
When calling the dictRehash function, 100 buckets will be migrated each time.
Summarize
The reason why I want to talk about the implementation of the hash table is because the dict data structure is used in all scenarios that require O(1) time to obtain kv data in Redis. In this article, we can clearly understand how Redis’s kv storage stores data, when it expands, and how the expansion migrates data.
When reading this article, you may wish to compare how the hash table is implemented in the language you use.
Reference
https://tech.meituan.com/2018/07/27/redis-rehash-practice-optimization.html
http://redisbook.com/preview/dict/rehashing.html
https://juejin.cn/post/6986102133649063972#heading-1
https://tech.youzan.com/redisyuan-ma-jie-xi/
https://time.geekbang.org/column/article/400379

Exploring the implementation of Hash table through Redis source code first appeared in luozhiyun`s Blog .
This article is reproduced from: https://www.luozhiyun.com/archives/667
Love reading is only for inclusion, and the copyright belongs to the original author.