Original link: https://www.barretlee.com/blog/2021/12/12/ly6l83/

I studied the page architecture design of Google documents on the weekend, and I have to sigh that Google has put a lot of effort into how to write good documents.
Architecture design is mainly divided into two parts, the first part is paging design and typesetting engine. For smoother performance and better multi-terminal compatibility, Google chose to use Canvas to draw the entire page. Each input will cause an OP ( Operational Transformation ) transmission and canvas redrawing. From the interactive state of the interface, the typesetting of the front and back ends Computing engines should be isomorphic. The other part is the implementation of the plug-in. Considering performance and security issues, the operation of the plug-in is completely isolated from the main process. The rendering engine will provide the plug-in with two capabilities, one for fetching data and the other for inserting data. Note, The ability to modify documents, such as deletion and replacement, is not provided. This design also ensures that the editing history of the entire document must be generated by human operations, not programs or plug-ins. Editing history records and multiple people When coordinating and interacting, many unnecessary troubles can be avoided.
The way the plug-in obtains data is by reading getSelection API exposed on the page, but it can only detect the text position currently selected by the user, such as [2038, 2044] , which means that 7 characters are selected from the 2038th character, and then appended Some auxiliary information, that is to say, the plug-in cannot directly obtain the content of the user document. If the data cannot be obtained, how to deal with the selected content? From the point of view of the interaction process, the plug-in service runs on Google’s back-end platform. When the front-end plug-in interacts, for example, when the selected content is converted into Markdown format, a network request will be initiated to pass the location information and token authorization information to the back-end On the end platform, the backend executes the logic of the plug-in, and returns to the foreground after the processing is completed. Finally, it is necessary to perform an insert operation on the foreground plug-in to insert the content at the current cursor position, or perform a copy operation to put the content on the clipboard.
From the perspective of the type of plug-in, it can be roughly divided into three categories, which need to be coupled with the document’s deep data, such as word-marking comments, suggestions, etc., which belong to the first category and are implemented by the editor itself. There are many “word-marking comments” Rich interaction, not suitable for frequent network interaction with back-end services, and the ability to “make suggestions” is more powerful, a bit like the pull request function of git, allowing reviewers to directly modify, and the author decides to merge the modification or reject it Modification, there are a lot of conflicts that need to be dealt with in this interaction process. Considering the performance and implementation cost, it is more convenient to implement this logic in the kernel extension part; the second category is Google-related businesses, such as Calendar, Note, Keep, etc. , they also run independently on the page and are not directly related to the document. They mainly share data to establish a relationship, such as initiating a meeting, inserting a note, etc., and the data can be consumed by the document; the third category is a variety of three-party plug-ins , such as QR code generation, format conversion, code insertion, drawing, etc. Considering security issues, you can only interact with the page through the two capabilities of getSelection and insertToDoc. The logic of this type of plug-in is separated from the interaction, and the data The processing is all performed on the back end, and inserted into the document after processing. 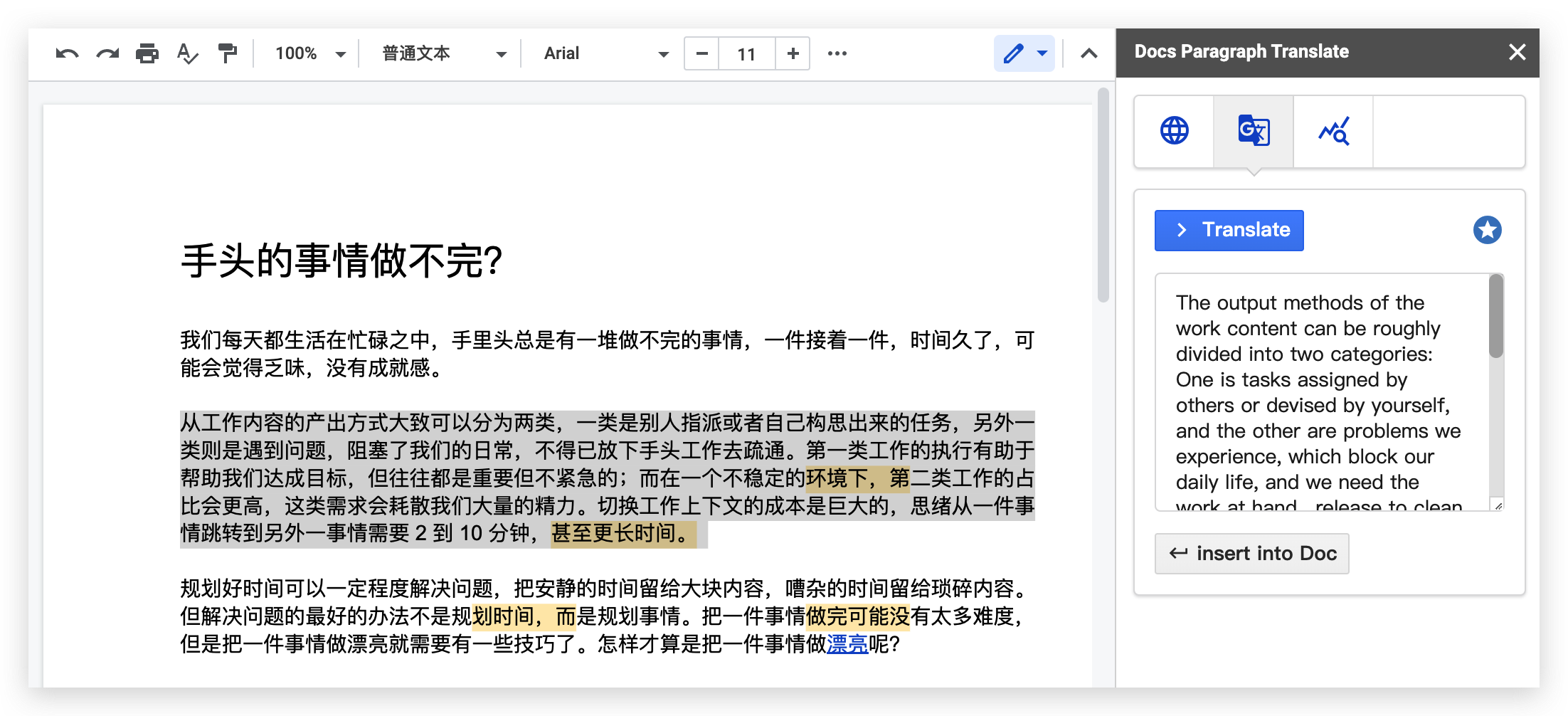
In addition to the two core capabilities of typesetting and plug-ins, another important part is the collaboration part, which depends on the efficient processing of Operational Transformation by the collaboration service. Since the transmitted data format is too complicated, it has not been carefully studied.
After a few hours of experience, I deeply feel that Google Docs is thinking about helping users write good documents. There are two meanings to writing good documents here. It can also ensure that no frames are dropped during the interaction process; the other layer refers to being able to help users write good documents. Using one-, two-, and three-party plug-ins, it is almost possible to complete document writing without leaving the page, such as translation and text error correction , literature index, secretary content query, drawing ability, etc., if it is not enough, it even provides a “script editor” ability, which allows users to customize scripts to process text content, without switching the user’s work context at will. It is a sufficient condition for efficient writing. 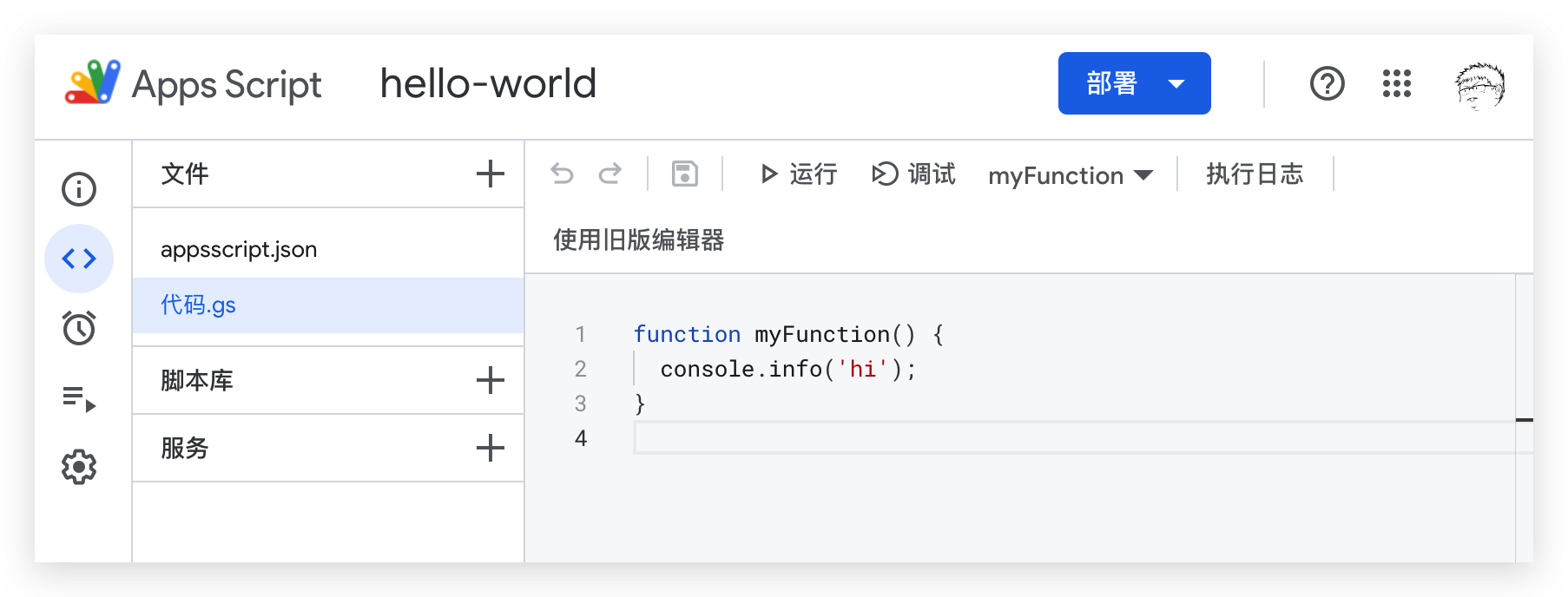
Google regards a document as a container. Various plug-ins, scripts, and services can be configured during the editing process of this container. The configured resources can be found in the toolbar and plug-in bar of the page. Saying this is a very geeky way of doing it. However, this approach is not without disadvantages. The isolation design of the main operating environment and the plug-in operating environment not only keeps the kernel clean and efficient, but also makes users lose a lot of WYSIWYG capabilities. For example, if you want to translate, you first need to Install the plug-in, wait for startup, initialization and loading data after installation, and wait for at least one network IO during the period. If you operate within the wall, the user experience is still terrible and very slow.
This article is transferred from: https://www.barretlee.com/blog/2021/12/12/ly6l83/
This site is only for collection, and the copyright belongs to the original author.