
What is intelligent document processing? For text data processing, especially plain text, people usually think of using natural language processing (NLP) technology to solve semantic understanding and analysis processing. Research on natural language processing technology has a long history. There are many technical points for text processing and analysis at different levels. Common technologies such as word segmentation and part-of-speech tagging, named entity recognition, syntactic structure analysis, text classification, text summarization and other functions.
Compared with plain text, the information expression of a document is more complex. In addition to various forms of text information, it also includes information such as tables and pictures. Therefore, to correctly understand everything in the document, it is very difficult to rely on natural language processing technology alone, and it needs to be combined with other technologies.

Figure 1 Common ways of expressing textual information
Intelligent Document Processing (IDP) technology is a package of technologies for automatic processing and analysis of document content. In addition to natural language processing technology, it also includes related underlying technologies such as computer vision and document parsing. Therefore, compared with NLP technology, IDP technology more complicated. Among the IDP technologies, Optical Character Recognition (OCR) technology, Document Parsing (DP) technology and Information Extraction (IE) technology are the most important and most widely used.
Optical character recognition technology mainly solves the problem of displaying text in the form of images. A lot of text information is displayed in the form of diagrams in the document, and even many documents are saved in the form of images, so OCR technology is required to extract all the text in the document and its position for analysis. In addition, some PDF files encrypt the text content, so the character information cannot be directly obtained, and OCR technology is also required to obtain the correct text content.
Document parsing technology includes protocol parsing of different types of files, unified representation of document content, layout analysis technology, table parsing technology, etc. The purpose is to use the same set of protocols to represent document structure and content, including images and semantics information.
Information extraction technology refers to using different algorithms to extract information from different document elements according to the document structure and content information, combine the extracted information results, and output them according to business requirements.
Based on the above core technologies, the general process of intelligent document processing is shown in the following figure:
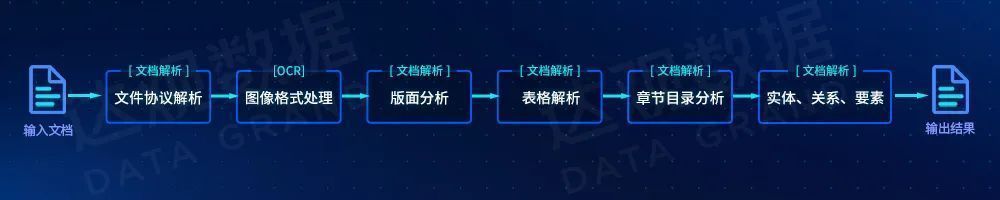
Figure 2 General intelligent document processing flow
Optical Character Recognition Technology
Optical character recognition technology is relatively mature and has a wide range of applications. Usually, for clear images, the accuracy of character recognition is high. However, in certain scenarios, such as perspective, blur, insufficient light, high-density text, etc., the recognition effect of the OCR system is greatly reduced, which brings difficulties to the document processing in the form of pictures in the actual scene.
There are usually two types of OCR technology routes:
- End-to-end one-stage approach
- Two-stage method of detection and identification
The two technical routes have their own advantages, and there is no absolute good or bad. The advantage of the end-to-end method is that it has a strong ability to fit the effect of a specific scene, but the disadvantage is that the training is more difficult and the effect is less controllable. For the one-stage method, Optimistic is often used for character recognition in specific scenarios such as seals and license plates. The two-stage method can achieve the best results in different steps, and can use the output results in different stages through business intervention. Therefore, philosophical is often used in general document recognition scenarios. The disadvantage is that two independent modules need to be maintained, and the cost is relatively high.

Figure 3 OCR mainstream technology route
01 Overview of Text Detection Algorithms
The purpose of the text detection algorithm is to find the location of the text in the image. Usually, the text box composed of text fragments is the detection target. Of course, there are also text detection methods for single characters. For text detection, it is currently divided into regression-based methods and segmentation-based methods.
Regression-based methods represent algorithms such as CTPN, SegLink, EAST, CRAFT, etc. These methods have their own advantages and disadvantages, and there is a problem of different effects in different situations. Regression-based methods are better for regular-shaped text detection, but not for irregular texts and long texts.
The representative algorithms based on instance segmentation include PSENet, DBNet, and FCENet, which can achieve good detection results for texts of various shapes, such as text distortion caused by a large number of mobile phone shooting, so they are used more in actual landing. . The disadvantage of the instance-based segmentation method is that the post-processing is usually complicated, and special optimization is required for the post-processing part of the code to ensure the best effect and speed.
The following table shows common text detection algorithms and their advantages and disadvantages.

Table 1 Common text detection algorithms and their advantages and disadvantages
02Overview of Text Recognition Algorithms
The text recognition technology route mainly goes through three stages:
- Recognition model based on CNN-RNN structure represented by CRNN
- Transformer-based Encoder-Decoder recognition model
- A model based on Vision-Language visual-semantic fusion.
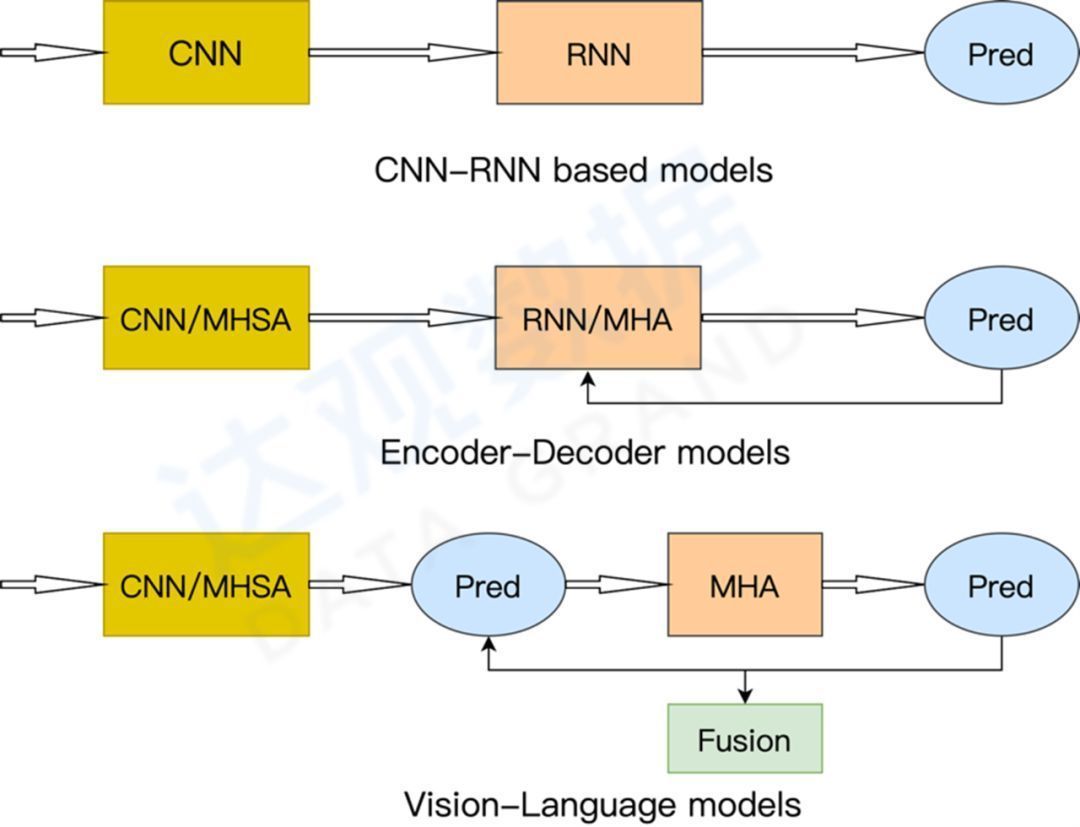
Figure 4 Three text recognition technology routes
The model represented by CRNN mainly includes two modules: Vision Model (visual feature extraction) and Sequence Model (text transcription). Visual feature extraction is easier to understand by using the classic CNN method, while the text transcription module uses Bi-LSTM and CTC decoding to convert visual features into text sequence features. The CRNN model is more classic, and can achieve better results in most occasions, and is widely used. The disadvantage is that it is very sensitive to interference such as text deformation and occlusion, and it is easy to be misidentified.
The model based on the Transformer Encoder-Decoder structure improves the accuracy because it can better utilize the context information, but because the Transformer model is relatively heavy, in actual use, it is necessary to consider methods such as clipping distillation to better land.
The Vision-Language-based model integrates vision and semantics. The advantage is that more and more accurate semantic information can be obtained, sometimes with better results, but usually the model is larger, which affects the recognition efficiency. The complete process of text recognition consists of image correction, visual feature extraction, sequence feature extraction and predictive decoding. The general general process is shown in the following figure:
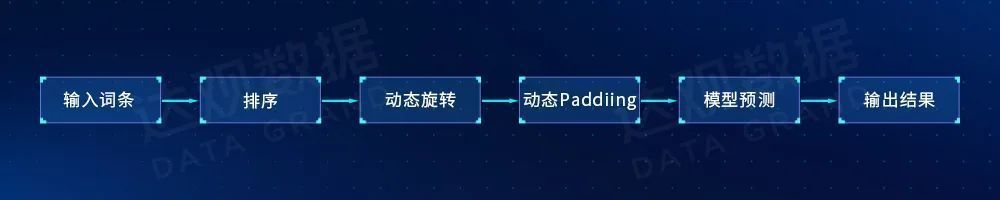
Figure 5 General process of text recognition
The representative algorithms involved in the above process are introduced in the following table:
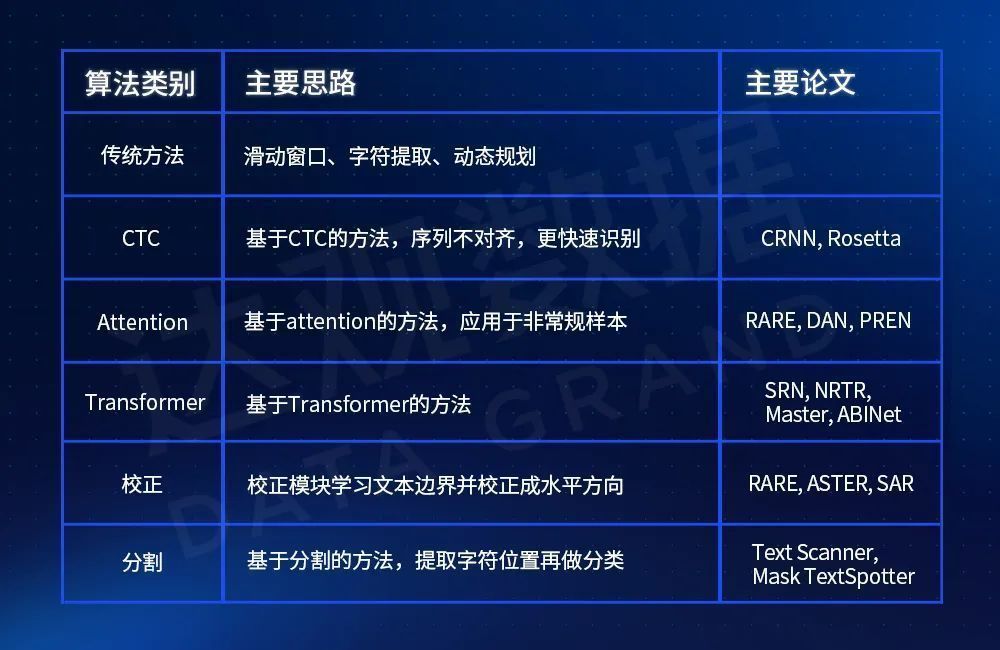
Table 2 Mainstream algorithms and comparisons of text recognition
CTC decoding is a very classic method in text recognition, but it will have effect problems in complex interference scenarios, and attention-based methods can often achieve better results for difficult samples. These two methods are the mainstream methods in Optimistic products, which can be flexibly adapted according to the scene. The network structure diagram of the two methods is compared as follows:
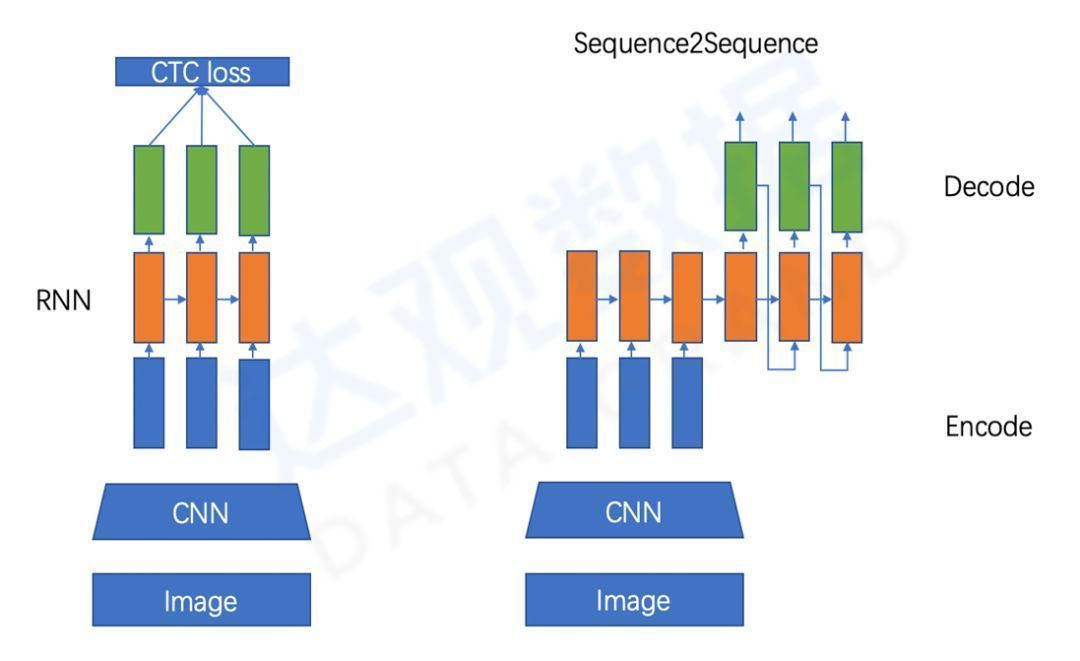
Figure 6 Comparison of two character recognition network structures
03Daguan ‘s practice and optimization of OCR technology
For the complex scene of document processing, there is no general technical framework and algorithm that can solve all the problems, and various model optimization and process adjustments need to be carried out for specific problems. For document OCR recognition, common problems, including text detection and masking, and dense small text target detection, need to be solved in a targeted manner.
Detection problems caused by text cover are common. In practical scenarios, such as seals, watermarks, etc., the underlying text detection fails. For stamps, red stamps can achieve good results through channel filtering, but for black stamps, the difficulty increases a lot. The figure below is an intuitive representation of the impact on text detection when there are red and black seals at the same time. It can be seen that in the middle result of the black background on the right, there is a fuzzy judgment in the text detection within the red frame.
There are three main ways to optimize for the cover problem:
- Document preprocessing to eliminate stamp effects, such as red stamps removed by color channel fade
- Data Plane Enhanced Stamp Masking Sample
- The seal segmentation design is added at the model level to strengthen feature separation.

Figure 7 Influence of different color stamp cover on text detection
Small targets with dense text are also common scenarios, such as bank flow, form data, engineering drawings, etc. Since the separate text area occupies a small area of the entire image and the density is relatively large, large areas of missed detection and false detection will occur without optimization. For this scenario, in addition to increasing the accumulation of data, Daguan also performs multi-scale feature design at the model level, which greatly improves the recall and accuracy of small targets. The figure below shows the test results for the flow results, this optimization has been successfully applied to the actual product project.

Figure 8 Bank flow-intensive text detection optimization
document parsing technology
Document parsing technology is another key technology in intelligent document processing.
Different types of documents in actual scenarios often encounter the following problems during processing:
- Documents such as electronic PDF or scanned copies will lose structured information such as paragraphs and tables;
- How document structure information such as layouts and tables is used by the algorithm;
- Academic algorithms are often faced with simple and standardized text forms, and there is a gap between them and real industrial scenarios;
- The expression of different document protocol formats is complex. How to express different types of documents uniformly can meet the processing of different upstream and downstream tasks.
The main work of document parsing includes the following three aspects:
- Different types of file protocol analysis, such as PDF, Word, OFD, etc., need to be mapped to a unified abstract document format;
- Layout restoration, identifying various elements on each page, such as headers and footers, headings, paragraphs, tables, illustrations, table of contents, etc.;
- Table analysis, accurately restore the information in the table to a two-dimensional matrix structure.
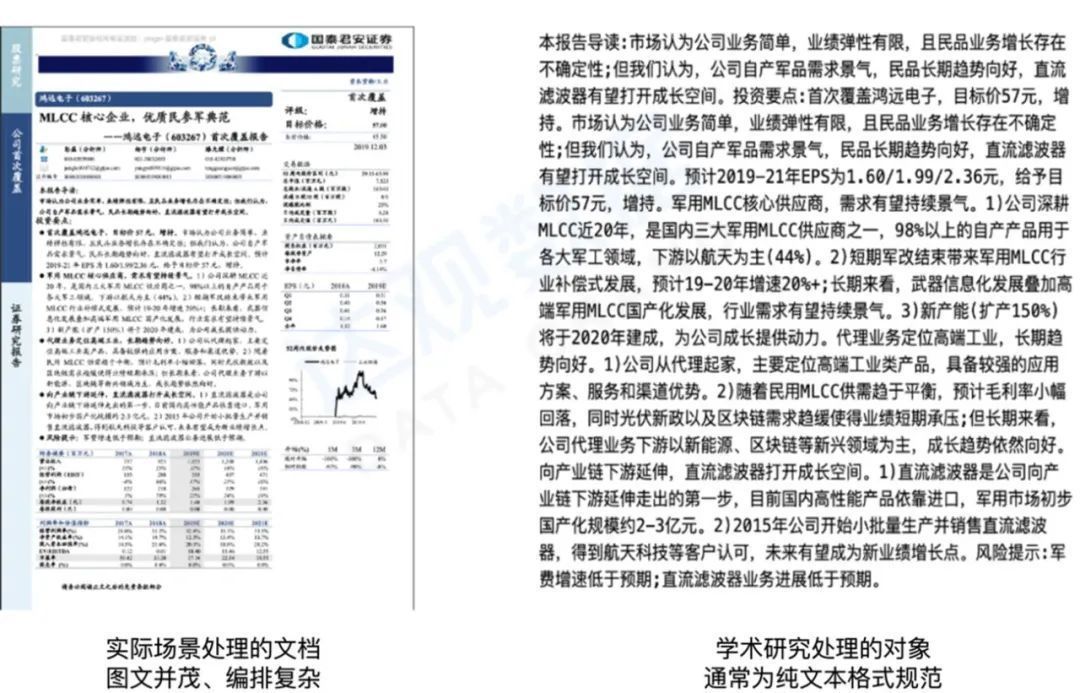
Figure 9 The objects of text processing in industry and academia are very different
01Document format parsing technology
Common document formats include Word, PDF (Portable Document Format), OFD (Open Fixed-layout Document), etc. Most of the file protocols are designed with an object tree as the main structure. Taking the PDF protocol as an example, the following figure shows the actual content of the PDF file and the organization structure of the document element object:
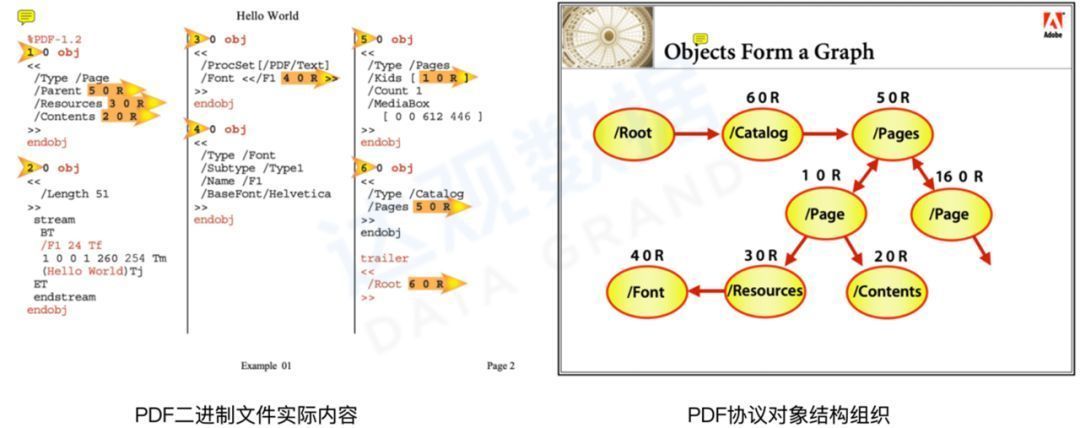
Figure 10 Organization structure of PDF protocol document element objects
The PDF format has great advantages in rendering and display. It can stably maintain the consistency of the rendered content under different devices and system environments, and is friendly to reading. However, it is relatively difficult to parse and edit PDF because the built-in object types of the PDF protocol are limited. Element type information such as headers and footers is missing, and elements such as text, lines, and shapes only include information such as content, color, size, and position coordinates. The element type needs to be judged and further processed according to the rendering result. Common excellent open source PDF libraries include PDFBox, MuPDF, PDFMiner, etc. OFD is a national standard for format documents formulated by the format writing group established by the China Electronics Standardization Institute led by the Software Department of the Ministry of Industry and Information Technology. Similar to PDF, it is an independent format in my country. For example, OFD format invoices have been widely used. The Word format docx based on OpenXML is relatively easy to parse, and can get rich information including styles. In addition to the SDK officially provided by Microsoft, there are also many excellent open source projects.
02Layout restoration technology
Layout restoration technology is to analyze the types of elements on each page in the document and the image information such as the size, position and shape of each element. Usually, the analysis is performed according to the rendered page image, so computer vision technology is mainly used. The significance of the layout restoration technology is mainly related to the lack of high-level document element objects in file formats such as images and PDFs. For example, headers and footers need to be filtered out in many business scenarios, but in PDF files, headers and footers are only A simple text box, text information alone is not enough to determine whether this text box is a header or footer. Although some rules can be used to filter out headers and footers, the rules are less general. In addition, more page areas such as paragraphs, headings, table of contents, tables, illustrations, etc. need to be divided, and document element types may also change according to business scenarios.
The method based on computer vision has good versatility and is consistent with the process of human observation of document layout information. Usually, the target detection scheme and the image segmentation scheme are used, and the two schemes have their own advantages and disadvantages. For the task of layout restoration, there are clear business attributes. An area is either a paragraph, a table or other types. There is no situation where it is both a paragraph and a table. When using the target detection scheme, it is necessary to additionally sort out the problem of reframing. The solution using image segmentation does not have this problem. It is more suitable from the perspective of input and output, but the resource requirements for image segmentation are relatively high. For example, MaskRCNN based on FasterRCNN expands a Mask branch on the basis of the original model, and the speed is relatively slower. .

Figure 11 Layout restoration effect based on FasterRCNN

Figure 12 Layout restoration effect based on MaskRCNN
03Table Analysis Technology
Tables are an important way of carrying information. As a kind of semi-structured data, tables are widely used in documents. For table information, there are usually two forms: electronic format (excel, csv, html) and image format. Compared with image tables, electronic tables can not only be rendered for reading, but also can be read and modified according to relevant protocols. Wait. The table parsing technology introduced here mainly solves the problem of identifying the structure and content of tables in the form of images, rather than identifying the problem of spreadsheets such as excel. In particular, the tables in electronic PDF files also need to be parsed using images due to the lack of relevant protocols.
The types of tables are generally divided into three types according to whether the table lines are complete: full-line tables, few-line tables, and wireless tables. The analysis methods for the above three tables are also different.

Figure 13 Division of three table types
The goal of table parsing is to find all table regions in the document and restore the table structure to a two-dimensional matrix. From the technical framework point of view, table parsing has an end-to-end one-stage approach and a two-stage approach of region detection and structure parsing. In our test, there is little difference between the end-to-end and the two-stage method in terms of overall accuracy, but considering the quick repairability of the business, Optimistic chooses the two-stage method.
Representative methods of end-to-end methods include TableNet, CascadeTabNet, etc. TableNet adopts the idea of image segmentation, sends the image into the backbone network, and then generates the mask of the table area and column through two branches, and then generates the row through the rules, and finally obtains the content of the specific cell. CascadeTabNet is based on Cascade R-CNN. It first detects the table area and divides the table type (wired, wireless), then detects the cell area, and finally does post-processing according to the table type to obtain the final table structure. These algorithms work well in public datasets, but due to the difficulty in solving specific bad cases end-to-end, there are certain limitations in actual business use.
The two-stage method is mainly composed of table area detection and table line detection. The table area detection problem is relatively simple, and it can be implemented based on target detection or segmentation. The main problem is that the difference in actual business definitions will affect the model effect, and more efforts need to be made at the data level. The table line detection is the technical focus, because the table parsing algorithm can finally be regarded as the problem of table line recognition. With all table lines in the table, the entire table structure can be restored. The solutions include traditional CV-based algorithms and deep learning algorithms. .
The algorithm based on traditional CV, represented by the classic Hough transform, has the advantage that it does not require data annotation and GPU resources, the algorithm is mature and stable, and the effect is very good for electronic PDF forms, but the distortion, lighting, etc. in scenes such as photo scanning and scanning The generalization ability is average due to factors, which requires a lot of effort in image preprocessing and post-processing. Algorithms based on deep learning, such as UNet, have the advantage of strong generalization ability for the above-mentioned distortion, deformation, illumination, etc., but the disadvantage is that a large amount of data annotation is required, and the computing resources are relatively high.
By using the algorithm based on deep learning, it can better solve the problem that traditional algorithms have high requirements for image quality. The following two figures show the effect of using the idea of segmentation to identify table lines. It can be seen that although the quality of the original image is not good, or the lines are special Blur or overall distortion perspective is more serious, but the overall resolution is better.
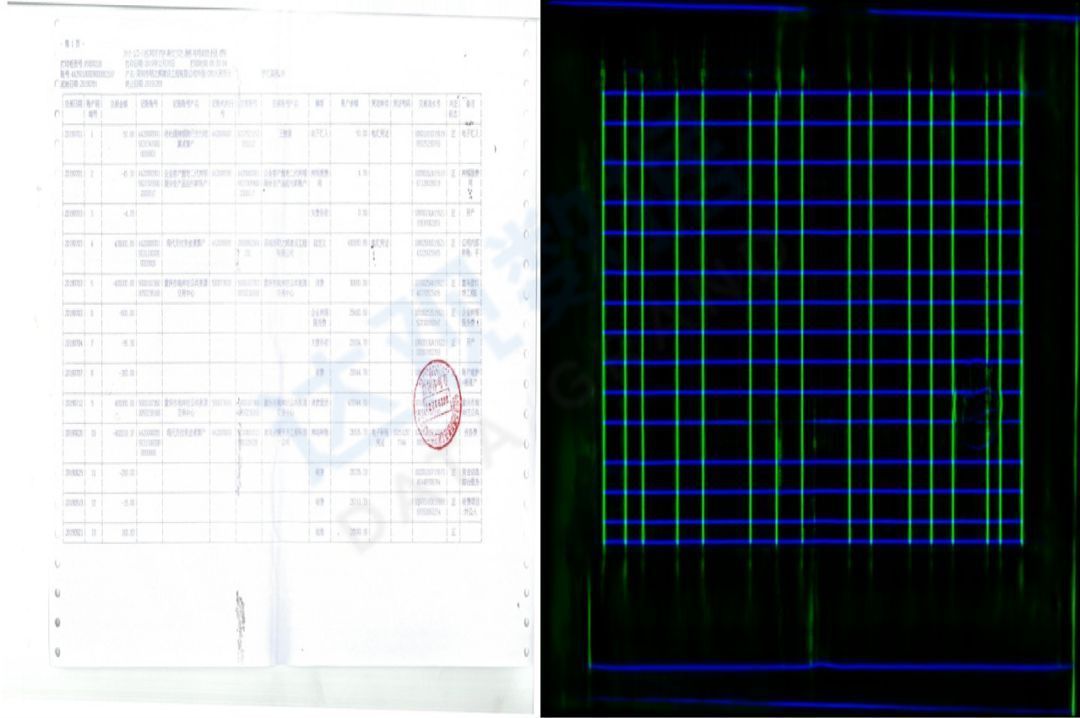
Figure 14 Line detection effect of line blurred image table
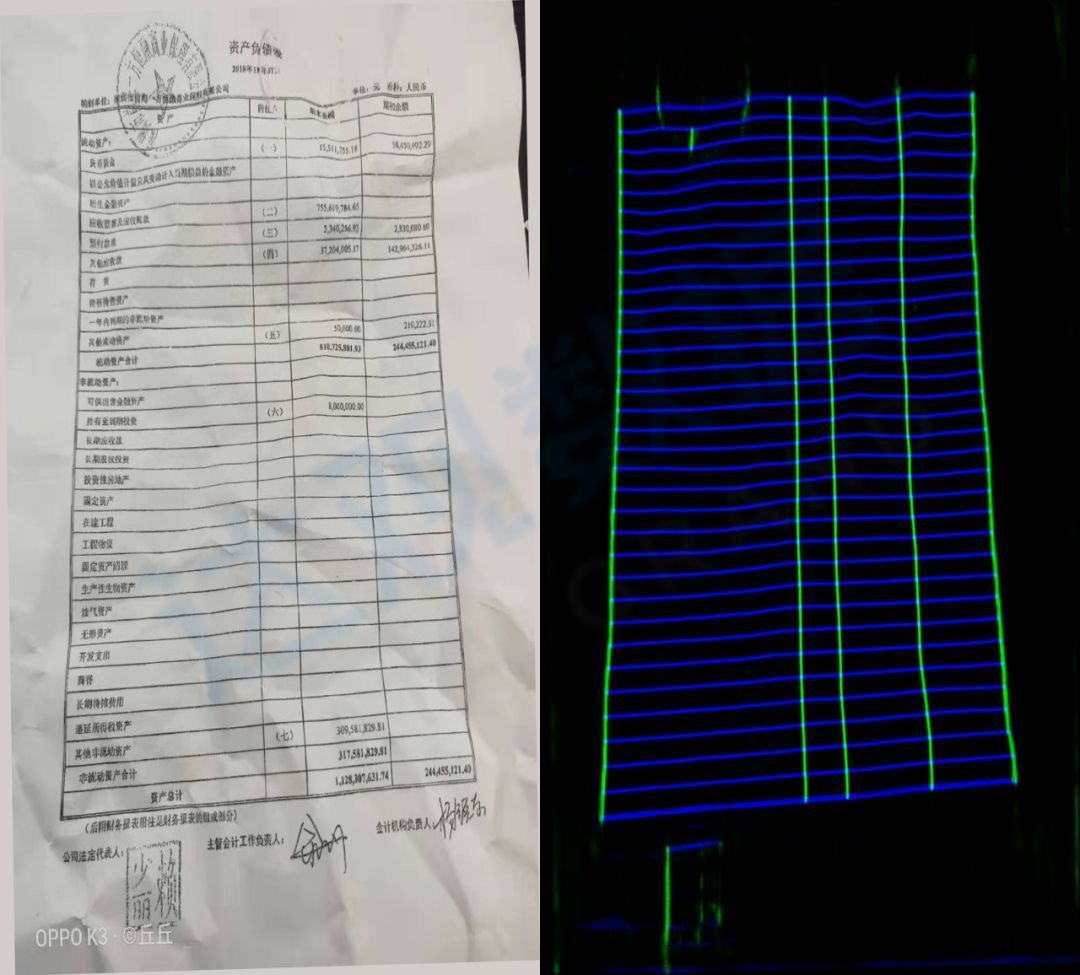
Figure 15 Kneading and twisting table line detection effect
Information extraction technology
Different from traditional plain text entity recognition, document information extraction is more challenging in practical scenarios, mainly due to the following difficulties:
- The text expression is complex, and there are various ways of expressing text information such as headers, footers, tables, and pictures in the document, which need to be processed separately;
- Lack of domain knowledge, the vocabulary used in actual documents is highly related to the industry scene, such as product, model and other proper names, and the model needs to be optimized for proprietary domain data;
- The information point context spans a wide range, including both short text entity information extraction and long context extraction. For example, in the prospectus, short text information such as company name and fundraising amount needs to be extracted, as well as long text information such as company profile and basic information of executives. The program span is very large;
- Software and hardware resource constraints, in addition to the simple model effect, also need to consider the two measurement dimensions of inference time and hardware cost, which need to be flexibly selected and balanced according to the actual situation.
In view of the above problems, not only need to solve specific problems one by one, but also need to design an excellent information extraction framework, which can be flexibly configured to realize one or more information extraction work in actual use. The following will describe the experience of Optimistic in related problem solving.
01Plain text extraction vs document extraction
Compared with plain text extraction, document information extraction has the following differences:
- There are many document formats. In addition to editable formats such as word, there are also non-editable formats such as PDF and jpg. It is difficult to obtain text information from it and match the reading order. The document parsing technology introduced earlier in this paper mainly solves the problem of text information extraction from documents of different formats, and lays the foundation for text extraction.
- The semantic context spans a large amount. In addition to the traditional context information near information points, it also includes context information that spans farther, such as chapter titles and even document types.
- For high-dimensional text problems, text information is not only related to its own semantic information, but also to its style and form (such as tables and pictures).
- There are few related researches on document information extraction. Most mature technologies are still based on plain text data. Although there have been good researches on multimodal information extraction and long document information modeling in recent years, there are few in the actual implementation process. Systematic and mature experience is for reference, and manufacturers need to develop and research by themselves.
For document extraction, in addition to the optimization and improvement of various algorithms themselves, it is very important to design a feature-rich and reasonable extraction framework. In order to meet the above requirements, Daguan Data has designed a set of extraction framework based on micro-service architecture. By decomposing a complex extraction task into multiple extraction sub-tasks, they are processed separately, and finally the results are combined and returned to the final extraction result.
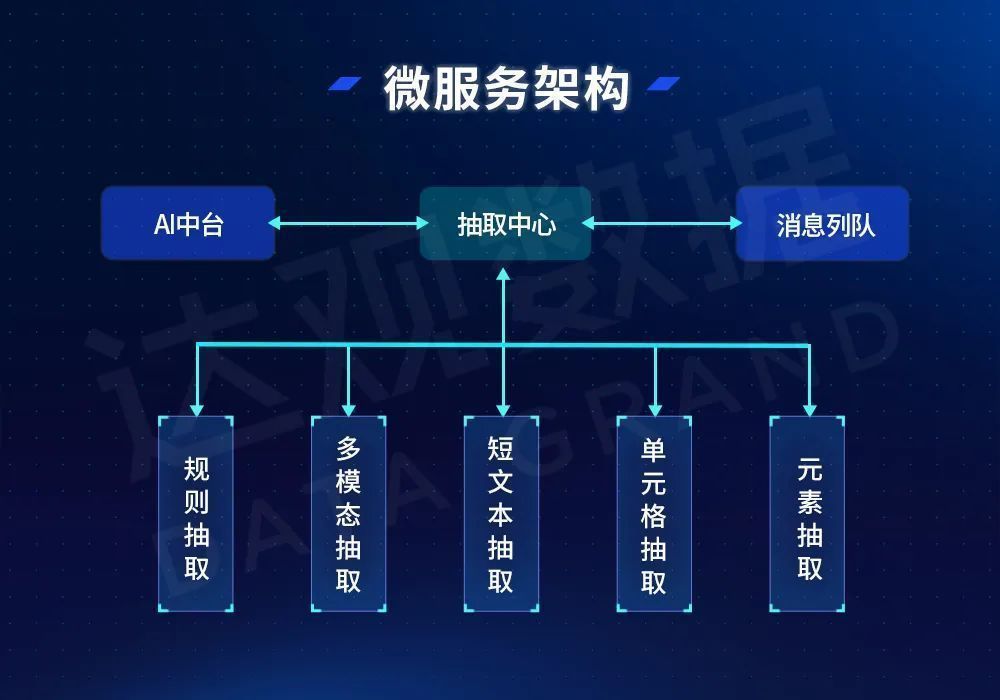
Figure 16 Extraction framework based on microservices
In actual tasks, according to different document types, the extraction center pushes messages of different extraction types into the queue, and the downstream related extraction algorithm modules perform independent processing. For simple extraction tasks, such as information extraction from financial statements, the extraction center only needs to generate table cells to extract information and provide table-related context information. For the extraction of complex long documents such as prospectuses and bond prospectuses, the extraction center needs to distribute messages of different extracted information according to field types, and provide public context and private context required by each algorithm, and various downstream extraction algorithm modules work simultaneously. Another advantage of the above solution is that for the extraction of special scenarios, the service type can be flexibly tailored, or the number of service copies of a certain type of extraction algorithm can be adjusted according to the business volume to achieve a balance between resources and business volume.
In terms of algorithm design, in addition to the previous work of extracting entity relationships based on joint annotation of sequence annotations, Optimistic also tries to use the Unified Information Extraction (UIE) framework. Because the Daguan IDPS platform supports tasks such as relation extraction and element extraction in addition to entity extraction tasks, the network structure differences of different task types lead to limited reuse of data and pre-training models, resulting in waste of resources and a more complex system. By setting Schemas of different extraction types and using the idea of UIE to generate structured results end-to-end, the extraction effect of single model and multiple tasks can be achieved.

Table 3 Schema design and effect of different tasks under UIE
02 Generic Model vs Domain Model
At present, semantic representation is based on large-scale pre-trained language models, and the downstream network structure is designed according to the task type. less. However, publicly available pre-trained language models are usually trained using general-purpose corpus data, and the effect will be compromised when transferring to downstream tasks in specific domains. The main reason is that the distribution of data between fields is very different.
The specific performance is as follows:
- The training data is inconsistent. For example, the probability of specific words in financial scenarios such as stocks, funds, interest rates, assets, etc. is much higher than that in other fields;
- The distribution of predicted labels is different. For example, in the data related to the financial crisis, the number of negative labels is far more than the number of positive labels;
- The context information is inconsistent. For example, in table data, the context information includes not only adjacent text in the same cell, but also the same cell, row header, column header, and so on.
In order to solve the problem of domain adaptation, the research directions are mainly divided into model-centric methods and data-centric methods. In terms of implementation, using a data-centric approach is more flexible, has wider applications, and allows for continuous training iterations. In practice, Daguan Data has served many financial institutions such as securities and banks, and has accumulated a large amount of financial corpus and related downstream task training data. Continued pre-training of language models in the financial field can solve the differences in domain knowledge and data distribution. , to improve the performance of NLP downstream tasks related to financial documents.
Specifically, there are two aspects of work:
- At the data processing level, collect financial and financial news announcements and other data obtained from public websites, combine with the text data in the financial field accumulated by Optimistic, and obtain millions of pre-training text data after data cleaning
- At the model design level, Chinese RoBERTa is selected as the basic model, and the mask method of whole word masking is used to continue pre-training. After testing, using the pre-trained language model after iterative tuning has generally improved the effect by 2-3% in downstream tasks in various financial fields
In addition, from the perspective of use, domain migration requires a lot of technical knowledge and requires high algorithm technology for users. However, the users of Optimistic IDPS products are mostly non-technical personnel such as business teachers and knowledge engineers. The system is able to explore optimal models and hyperparameters within a limited number of iterations and integrate them automatically. Specifically, various information such as the distribution data of the number of pages of the training document, the distribution of page numbers of the labeling data, and machine performance resources are considered for automatic learning, and a relatively good model effect can be obtained with less intervention.
03Short text extraction vs long text extraction
General text extraction technology research needs to deal with short text contexts. For example, Bert can process 512 characters in length, which can meet most scenarios. If this length is exceeded, window sliding is required. In practical scenarios, such as prospectus extraction, the context length is much more than 512 characters.
Usually long text extraction has the following difficulties:
- The amount of data is small, and the positive samples are too sparse;
- The data distribution is uneven, the negative samples are far more than the positive samples, and the Easy Negative data is far more than the Hard Negative data. As a result, in the training process, after a few iterations, the model will be fully learned and correctly predicted, resulting in “difficulties in the data”. “Negative samples” and positive samples have too little impact on model training iterations and cannot be fully learned;
- The end-to-end method lacks flexibility and is limited in actual use. The SOTA method often uses the end-to-end method, but industrial scenarios often require accurate monitoring of the contributions of each link and accurate optimization of each module.
In order to solve the above problems, in addition to modifying the model structure and parameters to make the traditional classic network better model long texts, it is also possible to optimize the process through business features. The main idea is to preprocess the training or prediction data according to the keywords or related title context. , only modeling in a limited document area, reducing the data imbalance problem caused by negative samples, and at the same time, it can greatly improve the training and prediction speed. For example, Optimistic uses chapter splitting and positioning technology, uses the document directory structure obtained by document parsing, and narrows the modeling scope according to the labeled data. For example, the entity extraction scope can be located in a certain chapter or even some paragraphs, and hundreds of pages of context information can be compressed. To the most relevant natural segments, improve the performance of the model, and achieve very good results in practice.
04Three -dimensional measurement evaluation system
In general, the most important optimization goal of academic research is the effect, and the weight of resources and time is relatively low. Compared with the academic world, industrial landing often pays more attention to the comprehensive results of time, space and effect, which we call three-dimensional measurement. In industrial implementation, there is a huge gap between customer software and hardware, and it is necessary to adapt to different deployment hardware solutions, and there may be hardware bottlenecks that may lead to major changes to the solution. For example, some customers do not have GPUs or have very limited related resources, resulting in limited deep learning-based algorithm solutions. . At the same time, the project target inspection point not only focuses on the effect, but also needs to pay attention to various factors such as response time and processing capacity during use, and needs to be weighed according to the actual situation. In addition, due to the limited resources in the actual scenario, it is necessary to make full use of existing resources, rationally use resources for different tasks, and flexibly support changes in business traffic, which puts forward great requirements on the architecture and scheduling capabilities of the system.
In order to meet the three-dimensional measurement evaluation system, in actual production, it is necessary to use tailoring, distillation, quantization and other methods to optimize the model volume and resource occupation. At the same time, it is also hoped that the effect of the original model can be guaranteed as much as possible, which is a big challenge. In practice, Daguan summarizes multiple sets of mature system algorithm configurations, and selects the best configuration according to project requirements to automatically complete related optimization work. For example, Bert distillation, the teacher network uses the classic base Bert model, with a total of 12 layers of network and more than 20M parameters to ensure the accuracy of data fitting, while the student network uses 8 times smaller tiny Bert or even Bi-LSTM according to the actual scene resource constraints to ensure the prediction accuracy . The figure below shows the knowledge distillation process used in Daguan IDPS.
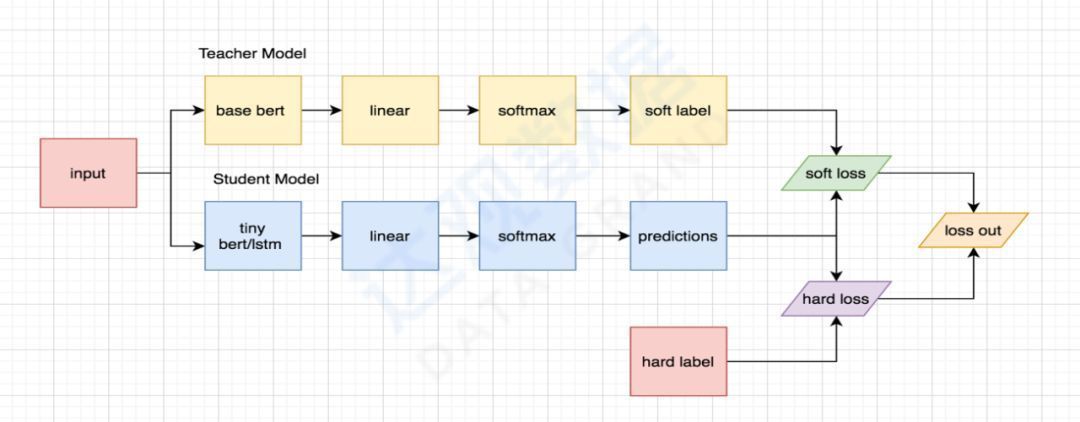
Figure 17 The use of knowledge distillation in Optimistic IDPS
In addition, in terms of service architecture, considering resource constraints, especially GPU resource constraints, the model network is split, and the heavy-calculation and multi-task common semantic encoding network is isolated as a service and deployed on limited GPU resources. Remote calls support various downstream tasks. Based on this, Daguan proposes the Transformer as a Service solution. The advantage of this solution is that it facilitates centralized management of GPU resources, uses Redis and other middleware to achieve distributed caching, optimizes the time-consuming of the entire large task, and can well support cross-environment, Different services across architectures (many customer CPU and GPU machines are independently deployed and operated), while facilitating the iteration and optimization of the overall effect of the pre-trained language model. It has been verified that the overall resource requirements are greatly reduced under the effect of losing about 1 point of accuracy, and it has been used in multiple projects.
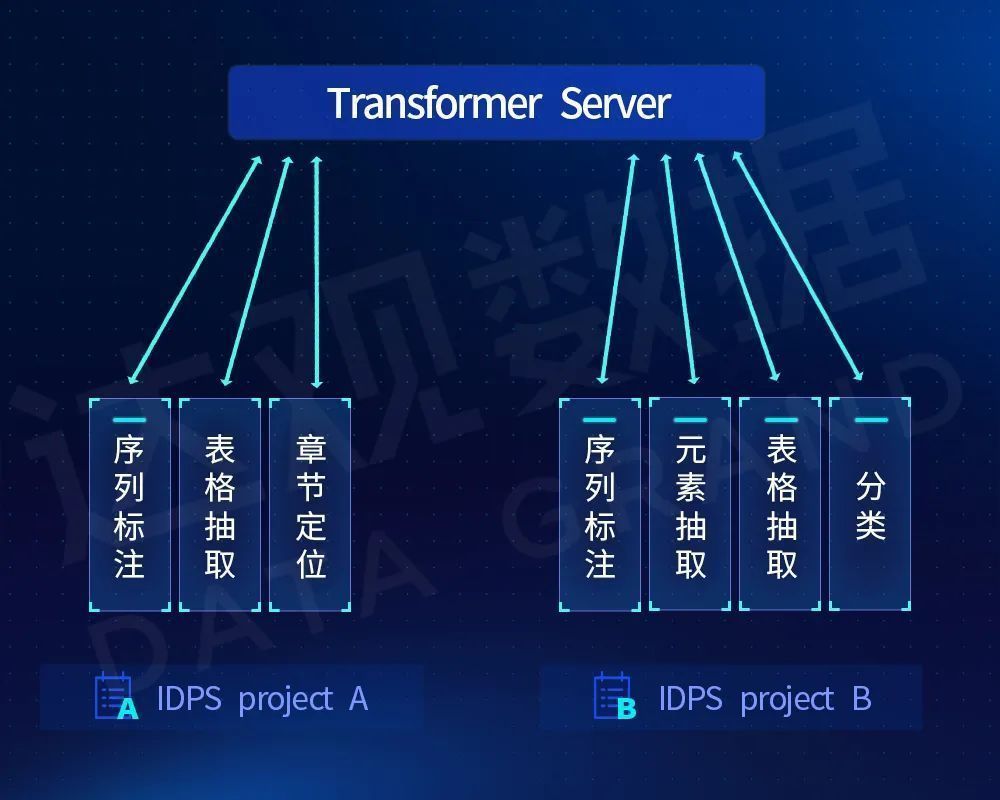
Figure 18 Example of use of Transformer As Service
Issues and Outlook
The principle and use of some key technologies in intelligent document processing are introduced in the previous article. Although it is subject to the limited content and space, it can still be seen that compared with pure NLP or CV, the intelligent document processing system is more complicated, and the systematic research work is relatively more complicated. It requires long-term investment of more resources for in-depth research and development. And because the processing object is a document, which is closely integrated with the actual work, it is often required to compare with manual work when it is actually implemented, and the effect is very demanding. Overall, the implementation of intelligent document processing in actual scenarios mainly has the following three problems:
01 Scene selection problem
The problem of scene selection is a key issue for the implementation of many projects. With the development of artificial intelligence technology, many difficult problems in the past have been solved or improved. For example, technologies such as speech recognition and face recognition have been relatively mature and used in many scenarios, which has enhanced confidence in the implementation of AI-related technology projects. For the field of intelligent document document processing, many project scenarios for document processing part, hope to improve efficiency with the help of IDP technology, usually a reasonable use of the process can achieve this goal.
However, in practice, because the IDP system is benchmarked against white-collar workers, coupled with the cognitive bias of AI capabilities, the requirements for the use and effect of the IDP system in many scenarios are unreasonable. The most common misunderstanding is to hope that the system completely replaces the artificial whole The process is 100% machine-performed, and the overall accuracy rate exceeds that of humans. The biggest advantage of machines over humans is speed and meticulousness. However, for intelligence-intensive work such as document processing, the processing effect of the system is still slightly worse than that of humans in complex business scenarios, especially document processing that requires logical thinking. Therefore, in this scenario, it is more appropriate to use machine pre-processing to solve some simple problems, and then perform manual review to improve the overall efficiency, such as the review of bond prospectus. At present, many securities companies have successfully used the method of machine pre-review and manual review. Improve efficiency. For simple scenarios, or scenarios where relevant systems can perform business verification, machines can be used completely, such as financial reimbursement, financial contract review, etc. As long as there is no problem with cross-validation of key information points and external data, it can be automatically passed. The problematic documents are then processed manually. Therefore, reasonable scene selection and process design of human-computer interaction are very important, which can achieve the final overall project goal.
02 Business Knowledge Questions
Business knowledge issues are another common problem. The IDP core technology discussed earlier is less related to business knowledge. In practical scenarios, the system lacks business knowledge even more seriously than the lack of model data. For example, for the same contract, the business information points that legal affairs and finance care about are very different. , only financial knowledge cannot complete a legal review. Business knowledge is not an AI problem in essence, but is based on the work requirements or experience summarized in the scene. This kind of knowledge logic is difficult to be accurately learned by AI systems at this stage, and usually needs to be expressed through coding, or certain knowledge reasoning through knowledge graphs. Therefore, in the actual implementation process, the roles of business analysts and knowledge engineers are very important. It is necessary to sort out the actual business processes and related information points, and cooperate with coders to write programs, model training, and finally cooperate with business knowledge and AI models to complete specific business tasks. . For the IDP system, the depth and breadth of business knowledge precipitation is particularly critical, which requires continuous accumulation on projects.
03Production problems
Productization is the most critical factor related to the cost and scope of the specific implementation of intelligent document processing. Different from other AI products, IDP products are oriented to actual business. Therefore, apart from technical personnel, business personnel account for the majority of users. How to design product interaction, combine product functions, and make it easier for business personnel to use it is the key issue. Many technical concepts Knowledge points need to go through product packaging and cannot be oriented by technical thinking. At the same time, it is also necessary to meet the rapid customization of models and services in different scenarios. The underlying core technical capabilities must be easily used by secondary development for technical personnel. For example, the richness of technical functions such as model parameter adjustment and interface calling is also very important. . A good product design should meet the above two points, design product functions and interfaces according to the user corner, simple when simple, complex when complex.
In addition, for specific business scenarios, productization is very helpful for project replication. When the business scenario is more specific, it means that the relevant business knowledge is relatively clear and the data type is relatively fixed. If this scenario is common in the industry, you can spend more time optimizing the model effect, enriching business knowledge, and even upgrading the product interface. For example, on the basis of the IDPS system platform and combined with the knowledge of business scenarios, Daguan has developed products such as intelligent flow audit, prospectus audit, financial report audit, etc., which can be used out of the box, which greatly facilitates project delivery and reduces costs. The above products are based on the core technology of IDP and combined with industry knowledge to optimize and improve the model. It can be accumulated continuously, so that the product capabilities of IDP will become stronger and stronger, and it can also push back the continuous improvement of IDP-related technologies and solve more problems. Many scene problems.
It is believed that with the development of technology and products, intelligent document processing IDP can deal with wider and deeper document processing work, and Optimistic Data will continue to invest in related product technology research and development, deeply cultivate industry scene applications, and continue to create greater value for many customers.
About the Author
Gao Xiang, Co-founder of Daguan Data, General Manager of Daguan Intelligent Document Review IDP and OCR. Expert in natural language processing technology, master of communication in Shanghai Jiaotong University, deputy secretary general of AI branch of Shanghai Jiaotong University Alumni Association, tutor of off-campus graduate students of Fudan University, awarded the title of Shanghai “Youth Science and Technology Rising Star” in 2019, the first batch of Shanghai artificial intelligence Recipients of senior titles.
This article is reprinted from: https://www.52nlp.cn/%E6%99%BA%E8%83%BD%E6%96%87%E6%A1%A3%E5%A4%84%E7%90%86idp% E5%85%B3%E9%94%AE%E6%8A%80%E6%9C%AF%E4%B8%8E%E5%AE%9E%E8%B7%B5-%E9%AB%98%E7 %BF%94
This site is for inclusion only, and the copyright belongs to the original author.