Written at the beginning: Many years ago, when I was just starting to use linux, just in time for the birth of Sunpinyin. At that time, Yong Sun wrote the Sunpinyin code guide. Although at that time, because the knowledge reserve was not rich enough, I basically could not understand the content of the article, but if I look back now, I finally wrote an input method engine similar to the algorithm from scratch in 2017 to replace the outdated one. Default pinyin and code table in Fcitx 4.
Although some people may have doubts, why write such an input method engine from scratch, is Sunpinyin not good enough? A blog of mine a long time ago actually made some functional explanations . Here we will explain the ins and outs of libime from the perspective of code again.
The current library of libime is divided into 4 parts, among which Yuepin is in a Git code repository alone, and most of the code of Yuepin is similar to Pinyin. Later, I will not introduce the part of Cantonese Pin in particular.
Another reason is that many of the core codes are not very familiar to me, and I also took this opportunity to record and refresh my memory. In addition, I believe that the part of these experiences is also very interesting to understand the development process of Linux input method and Fcitx, and it is probably not bad to look at it as a story?
Core part (Core)
Before explaining Core, let’s talk about why libime is written. And this has to say about the previous seniors, some of which I only have a general understanding of, so there may be mistakes. The first is the pinyin input of fcitx4. Its basic principle is Forward maximum matching. In short, it is to find the longest matching content in the thesaurus according to your current input. This algorithm itself is also used in the field of Chinese character segmentation. Of course, the advantage is that it is fast, but the disadvantage is also obvious, that is, the prompts given are not accurate enough, and there is no concept of sentences. And Sunpinyin is an input method based on N-gram statistical language model. It calculates the probability of a final sentence based on the words matched by pinyin, and sorts the results according to the probability. Rime I’m not sure what algorithm was used, but there must be no language model, since there is no such sign in the data file, the presumed algorithm is unigram.
But Sunpinyin, as an input method, lacks many APIs with rich functions, for example, there is only one thesaurus. There is no particularly convenient way to modify the thesaurus. In addition, the thesaurus itself is stored in sqlite, which is not necessary for the input method.
Therefore, the core goal of libime is to implement an N-gram-based input method engine similar to Sunpinyin, and it needs to easily support the functions I need, including functions such as multi-word library.
As a spiritual sequel to Fcitx 4, I also wanted it to take up as little resources as possible.
As a core part, the data structures I mainly want to include include two, the Trie and the language model. If you look at the early history, you can see several implementations of Trie’s code that have been removed. If you have studied data structure code, you probably know that a Trie is a data structure representing a tree, suitable for storing many strings. When you walk on the trie, you can find other nodes matching this prefix based on the position of the current letter of the string.
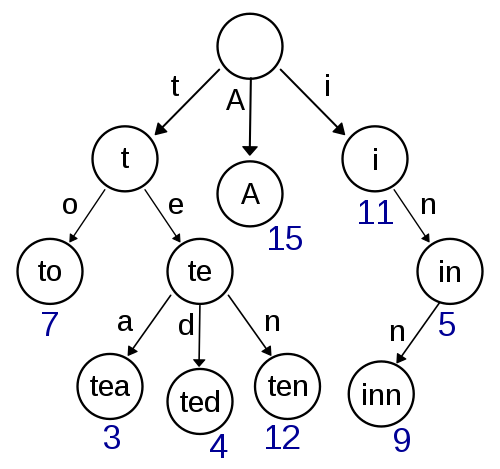
Among them, my requirements for its data structure function are mainly as follows:
1. Can be modified at runtime (some Trie implementations cannot be dynamically modified)
2. Compact memory footprint
After trying multiple implementations, I finally adopted the double array trie as the implementation of Trie and the code of cedar as the implementation, but replaced the parts that can be replaced by the C++ standard library, thus simplifying a lot of unnecessary code . There is also a pit in it. In short, the performance of std::vector after replacement is not as good as the original performance. Finally, it is found that the reason is that the allocator of C++ does not have a function that can correspond to realloc. When you can realloc in place, you can save a lot of operations. Therefore, a naivevector is implemented, and the implementation in std::vector is replaced by malloc and realloc, thus obtaining similar performance to the original.
As for the language model, I found kenlm as an implementation, and encapsulated the corresponding API on it for easy invocation. The corresponding is encapsulated in the LanguageModel class. kenlm provides a variety of storage methods. Here libime directly adopts an option with a smaller memory footprint.
At this point, the problems of the two core data structures in Core have been solved.
The core function provided by kenlm is to give a current state and query the probability of the corresponding word.
LanguageModel model(LIBIME_BINARY_DIR "/data/sc.lm"); State state(model.nullState()), out_state(model.nullState()); std::string word; float sum = 0.0f; while (std::cin >> word) { float s; WordNode w(word, model.index(word)); std::cout << w.idx() << " " << (s = model.score(state, w, out_state)) << '\n'; std::cout << "Prob" << std::pow(10, s) << '\n'; state = out_state; sum += s; }
State saves the current state information, which essentially stores the WordNodes that appeared before, so as to calculate the probability of the corresponding next word appearing. Probability values are all logarithmic. Therefore, it is only necessary to simply add the obtained probabilities to obtain the overall probability.
After having the Trie and the language model, the core function that Core finally provides is to use the Trie and the model to search to obtain the result of the final matching sentence. This process is generally called decode in NLP. The corresponding implementation is placed in the Decoder in libime. The algorithm used here is Viterbi . Of course, in order to simplify the corresponding pruning, the overall algorithm is generally called Beam search. (Non-NLP major, the wording may be inaccurate)
Before that, let’s go back to the input method we need to implement, so that we can better explain how the algorithm works here.
The first thing we want to mention is this class, SegmentGraph. It represents a graph of the way the string is split. Each of the splittable nodes is a node in the graph. Corresponding to the pinyin, it is the way of segmenting the pinyin. The way of slicing is complete. For one of the most complex cases, such as (anana), the possible splits look like this.
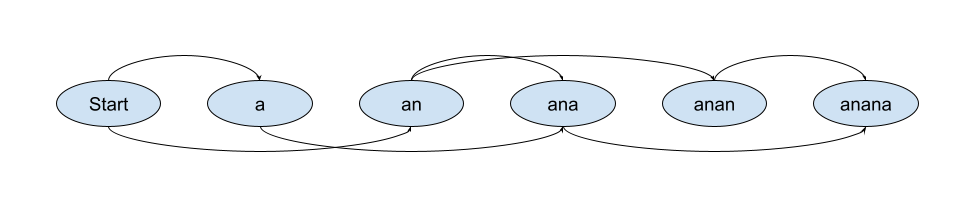
Correspondingly represents three segmentation methods: a na na, an a na, and an an a.
The input of the decoder is a Segment Graph, and the output is a Lattice (grid). What’s going on here? Simply put, it is to put each path on the Segment Graph into the dictionary to match. The specific matching method used is determined by the dictionary. For example, for the above example, for the segmentation of a na na, it is necessary to match several different paths of a na na, a na, a, na na, and na. The Lattice built for this path is similar:
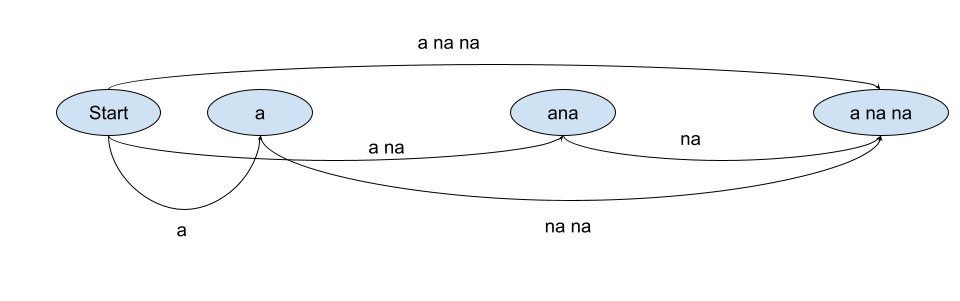 Of course, this is only for a na na this kind of segmentation, other segmentation will add different edges on it. The pinyin marked on each side of the above picture will be matched in the dictionary when using the Pinyin dictionary for decoder. Each edge expands the SegmentGraphNode in the corresponding SegmentGraph to the LatticeNode of the corresponding word.
Of course, this is only for a na na this kind of segmentation, other segmentation will add different edges on it. The pinyin marked on each side of the above picture will be matched in the dictionary when using the Pinyin dictionary for decoder. Each edge expands the SegmentGraphNode in the corresponding SegmentGraph to the LatticeNode of the corresponding word.
Here we use a different example to explain. For example, the classic example of internal segmentation in Pinyin is xian (xi an). At the node corresponding to the prefix xian, we have “first, line, county, now…” matched by xian as a whole. In the xi prefix node, there is only xi (xi, xi, department, wash…), and then these xi nodes can reach xian, the SegmentGraphNode, through an. For example, there is an “I, press, Ann, …). Finally, there is (Xian) that directly passes through xi an as a whole word to reach xian.
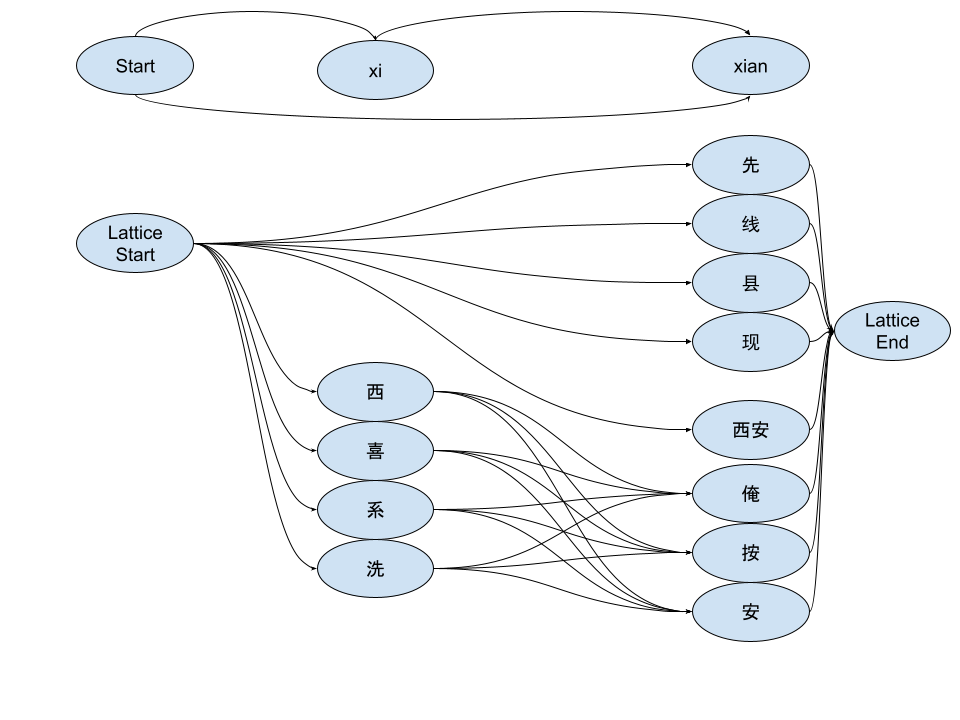 The graph after converting SegmentGraph to Lattice through dictionary matching is shown in the figure. Of course, because it is connected on the Segment Graph, there is no need to directly display each edge in memory. You only need to manage the mapping relationship between Lattice Node and Segment Graph Node.
The graph after converting SegmentGraph to Lattice through dictionary matching is shown in the figure. Of course, because it is connected on the Segment Graph, there is no need to directly display each edge in memory. You only need to manage the mapping relationship between Lattice Node and Segment Graph Node.
After building Lattice, that’s where classic Beam search comes into play. The probability (or score) of each possible path is calculated by dynamic programming, which will reduce the possible search results in some cases, otherwise the search space may be huge.
The beam search here is divided into three steps as a whole. The first step is to build the Lattice (grid) as mentioned above, the second step is forward search, and the third step is backward search.
The basic step of the second step forward search is to traverse all the nodes on the Segment Graph breadth first, or in other words, traverse all possible segmentation points (regardless of the segmentation path), and then calculate the corresponding segmentation point Segment Graph Node The highest score of the Lattice Node is calculated by finding the parent Segment Graph Node of the Segment Graph Node corresponding to the Lattice Node. This node is unique because the Lattice Node is found by counting the words that match a certain pinyin. Then traverse the Lattice Node in the parent Segment Graph Node to calculate the highest score. In short, latticeNode.score = latticeNodeFrom.score + languageModel.score(latticeNodeFrom.state, latticeNode.word) . This continues to solve until the score of the Lattice End Node is obtained.
The main purpose of Backward Search is to calculate the N-Best score. If only one result is needed, it is obviously the path corresponding to the highest score of the Lattice End Node. But how to solve the path of the next level score?
Simply put, it’s going backwards from the end. Other candidate replacements for the parent Segment Graph Node of the highest scoring Lattice Node to compare to obtain better results.
This article is reprinted from https://www.csslayer.info/wordpress/fcitx-dev/libime-intro-1/
This site is for inclusion only, and the copyright belongs to the original author.