Original link: https://www.msra.cn/zh-cn/news/features/naturalspeech
Editor’s note: AI-synthesized speech is now commonplace, but when users hear it, it cannot make people feel as immersive as talking with real people and reading. However, NaturalSpeech, a new end-to-end speech synthesis model jointly launched by Microsoft Research Asia and Microsoft Azure Speech Team, has reached the level of human speech for the first time in the CMOS test. This will further improve the level of synthetic speech in Microsoft Azure, making all synthetic voices lifelike.
Text to Speech (TTS) is a computer technology that generates intelligible and natural speech from text. In recent years, with the development of deep learning, TTS has achieved rapid breakthroughs in academia and industry and has been widely used. In TTS research and products, Microsoft has always had a deep accumulation.
In terms of research, Microsoft has innovatively proposed several TTS models, including Transformer-based speech synthesis (TransformerTTS), fast speech synthesis (FastSpeech 1/2, LightSpeech), low-resource speech synthesis (LRSpeech), customized speech synthesis (AdaSpeech) 1/2/3/4), singing voice synthesis (HiFiSinger), stereo synthesis (BinauralGrad), vocoder (HiFiNet, PriorGrad), text analysis, speaker face synthesis, etc., and launched the most detailed literature review in the field of TTS. At the same time, Microsoft Research Asia also held speech synthesis tutorials at several academic conferences (such as ISCSLP 2021, IJCAI 2021, ICASSP 2022), and launched DelightfulTTS in the Blizzard 2021 speech synthesis competition, which won the best results. In addition, Microsoft also launched the open source speech research project NeuralSpeech and so on.
On the product side, Microsoft provides a powerful speech synthesis function in Azure Cognitive Services, where developers can use the Neural TTS function to convert text into realistic speech for use in many scenarios, such as voice assistants, audiobooks, Game dubbing, auxiliary tools, and more. With Azure Neural TTS, users can either directly select preset sounds, or record and upload sound samples to customize sounds. Currently, Azure Neural TTS supports more than 120 languages, including multiple language variants or dialects, and the feature has also been integrated into multiple Microsoft products and adopted by many partners in the industry. In order to continuously promote technological innovation and improve service quality, the Microsoft Azure Voice team has worked closely with Microsoft Research Asia to make TTS sound more diverse, pleasing and natural in different scenarios.
Recently, Microsoft Research Asia and Microsoft Azure Speech Team have developed a new end-to-end TTS model NaturalSpeech, which uses CMOS (Comparative Mean Opinion Score) as an indicator on the widely used TTS dataset (LJSpeech), and achieves for the first time. Excellent results with no significant difference from natural speech. This innovative scientific research achievement will also be integrated into the Microsoft Azure TTS service for more users to use in the future.
Four innovative designs allow NaturalSpeech to surpass traditional TTS systems
NaturalSpeech is a fully end-to-end text-to-speech waveform generation system (see Figure 1) that bridges the quality gap between synthetic speech and human voice. Specifically, the system uses a Variational Auto-Encoder (VAE) to compress high-dimensional speech (x) into a continuous frame-level representation z (denoted as posterior q(z|x)), using for the reconstruction of the speech waveform x (denoted as p(x|z)). The corresponding prior (denoted as p(z|y)) is obtained from the text sequence y.
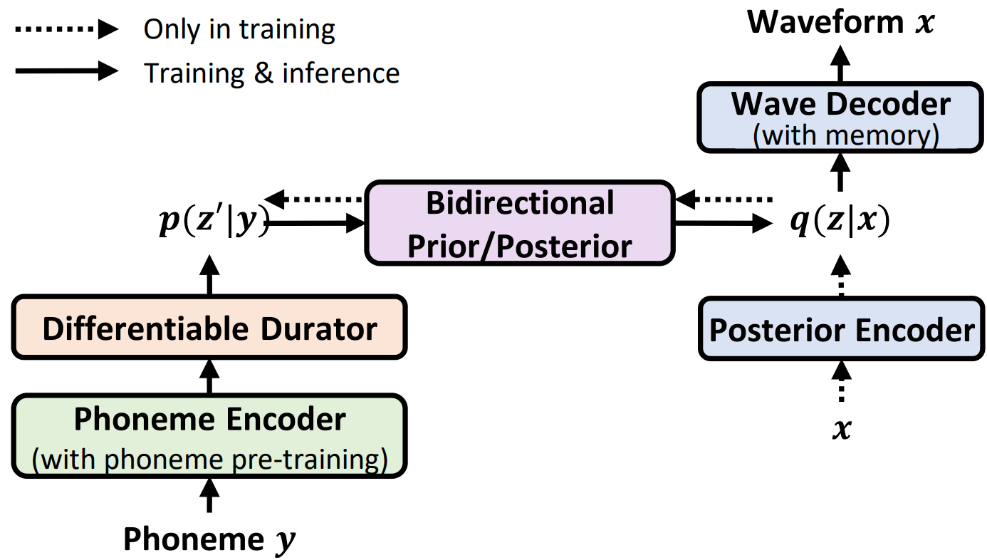
Figure 1: Overview of the NaturalSpeech system
Considering that the posterior from speech is more complex than the prior from text, the researchers designed several modules (see Fig. 2) to match the posterior and prior as closely as possible, so that by y→p(z| y)→p(x|z)→x realizes text-to-speech synthesis.
- Leveraging large-scale phoneme pre-training on a phoneme encoder to extract better representations from phoneme sequences.
- Use a fully differentiable duration module (durator) consisting of a duration predictor and an upsampling layer to improve the duration modeling of phonemes.
- The bidirectional prior/posterior module based on the flow model (flow) can further enhance the prior p(z|y) and reduce the complexity of the posterior q(z|x).
- Memory-based Variational Autoencoders (Memory VAEs) that reduce the posterior complexity required to reconstruct waveforms.
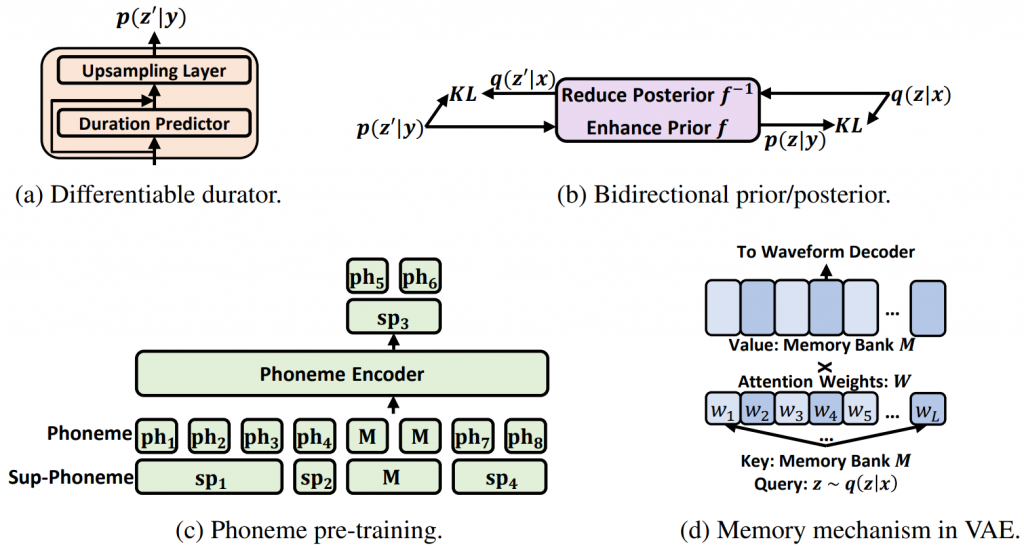
Figure 2: NaturalSpeech key modules
According to Tan Xu, a researcher in charge of Microsoft Research Asia, compared with the previous TTS system, NaturalSpeech has the following advantages:
1) Reduce the mismatch between training and inference. Both previous cascaded acoustic model/vocoder systems and explicit duration prediction suffer from training inference mismatches. The reason for this is that the vocoder uses the real mel spectrum and the mel spectrum encoder uses the real duration, and the corresponding predicted value is used in the inference. NaturalSpeech’s full end-to-end text-to-waveform generation and differentiable duration modules avoid mismatches in training inference.
2) The one-to-many mapping problem is alleviated. A text sequence can correspond to multiple different speech expressions, such as changes in pitch, duration, speed, pause, prosody, etc. Previous studies only additionally predict pitch/duration and cannot handle one-to-many mapping problems well. The memory-based VAE and bidirectional prior/posterior in NaturalSpeech can reduce the complexity of the posterior and enhance the prior, helping to alleviate the one-to-many mapping problem.
3) Improve expressive ability. Previous TTS models were often insufficient to extract good representations from phoneme sequences and learn complex data distributions in speech. NaturalSpeech can learn better textual representation and speech data distribution through large-scale phoneme pre-training, VAE with memory mechanism, and powerful generative models such as Flow/VAE/GAN.
Authoritative evaluation results show: NaturalSpeech synthetic voice and real voice are on par
Previous work usually uses the Mean Opinion Score (MOS) to measure TTS quality. In the MOS evaluation, participants rated the characteristics of the two voices on a five-point scale, including voice quality, pronunciation, speaking speed, and intelligibility, by listening to real voice recordings and TTS synthesized voices. But MOS was not very sensitive to discriminating differences in sound quality, because participants only scored each sentence individually from the two systems, not pairwise compared to each other. In the evaluation process, CMOS (Comparative MOS) can score the sentences of the two systems side by side, and use a seven-point scale to measure the difference, so it is more sensitive to quality differences.
Therefore, when evaluating the quality of the NaturalSpeech system and real recordings, the researchers conducted both MOS and CMOS tests (the results are shown in Tables 1 and 2). Experimental evaluations on the widely adopted LJSpeech dataset show that NaturalSpeech achieves -0.01 CMOS on sentence-level comparisons with human recordings, and p>>0.05 on the Wilcoxon signed-rank test. This shows that for the first time on this dataset, NaturalSpeech is not statistically significantly different from human recordings. This score is much higher than other TTS systems previously tested on the LJSpeech dataset.

Table 1: MOS comparison between NaturalSpeech and human recordings, using the Wilcoxon rank sum to measure p-values in the MOS assessment.

Table 2: CMOS comparison between NaturalSpeech and human recordings, using the Wilcoxon signed rank test to measure p-values in the CMOS evaluation.
The speech synthesized by NaturalSpeech and the corresponding real recording are shown below:
Content 1: Maltby and Co. would issue warrants on them deliverable to the importer, and the goods were then passed to be stored in neighboring warehouses.
NaturalSpeech synthesized speech:
Live recording:
Content 2: who had borne the Queen’s commission, first as cornet, and then lieutenant, in the 10th Hussars.
NaturalSpeech synthesized speech:
Live recording:
For more technical details, see the NaturalSpeech paper and GitHub home page:
NaturalSpeech Paper: NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
https://ift.tt/KcrCByt
NaturalSpeech GitHub home page:
https://ift.tt/jPMbE1f
The development of TTS is long and difficult, and the industry needs to work together to create responsible AI
According to Zhao Sheng, chief R&D director of voice for Microsoft Azure Cognitive Services, the NaturalSpeech system achieved an effect that is not significantly different from real recordings for the first time, which is a new milestone in TTS research. In the long run, although higher quality synthesized speech can be achieved with the help of the new model, this does not mean that the problems faced by TTS are completely solved. At present, there are still many challenging scenarios in TTS, such as emotional speech, long recitation, improvisation speech, etc., which all require more advanced modeling techniques to simulate the expressiveness and variability of real speech.
As the quality of synthesized speech continues to improve, ensuring that TTS can be trusted by people is a tough issue. Microsoft has taken the initiative to take a series of measures to anticipate and reduce the risks posed by artificial intelligence technologies, including TTS. Microsoft is committed to promoting the development of artificial intelligence in accordance with human-centered ethical principles. As early as 2018, it released six responsible artificial intelligence principles (Responsible AI Principles) of “fairness, inclusiveness, reliability and security, transparency, privacy and security, and responsibility”. ), and then released the Responsible AI Standards to implement the principles, and set up a governance structure to ensure that each team implements the principles and standards into their daily work. We are working with researchers and academic institutions around the world to continue advancing the practice and technology of responsible AI.
Explore more features and sounds of Azure AI Neural TTS
Azure AI Neural TTS currently provides more than 340 voices and supports more than 120 languages and dialects. In addition, Neural TTS helps companies create their own brand voice in multiple languages and styles. Now, users can explore more features and featured sounds with the Neural TTS trial.
Related Links:
- Microsoft Azure Cognitive Services TTS
- Speech-related research at Microsoft Research Asia
- NeuralSpeech, Microsoft’s open source speech research project
- NaturalSpeech Paper: NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
- Responsible AI principles from Microsoft
- Our approach to responsible AI at Microsoft
- The building blocks of Microsoft’s responsible AI program
This article is reprinted from: https://www.msra.cn/zh-cn/news/features/naturalspeech
This site is for inclusion only, and the copyright belongs to the original author.