Original link: https://www.kingname.info/2022/06/20/translate-html/
I believe that everyone has used the browser’s translation webpage function, for example, for the English webpage shown below:
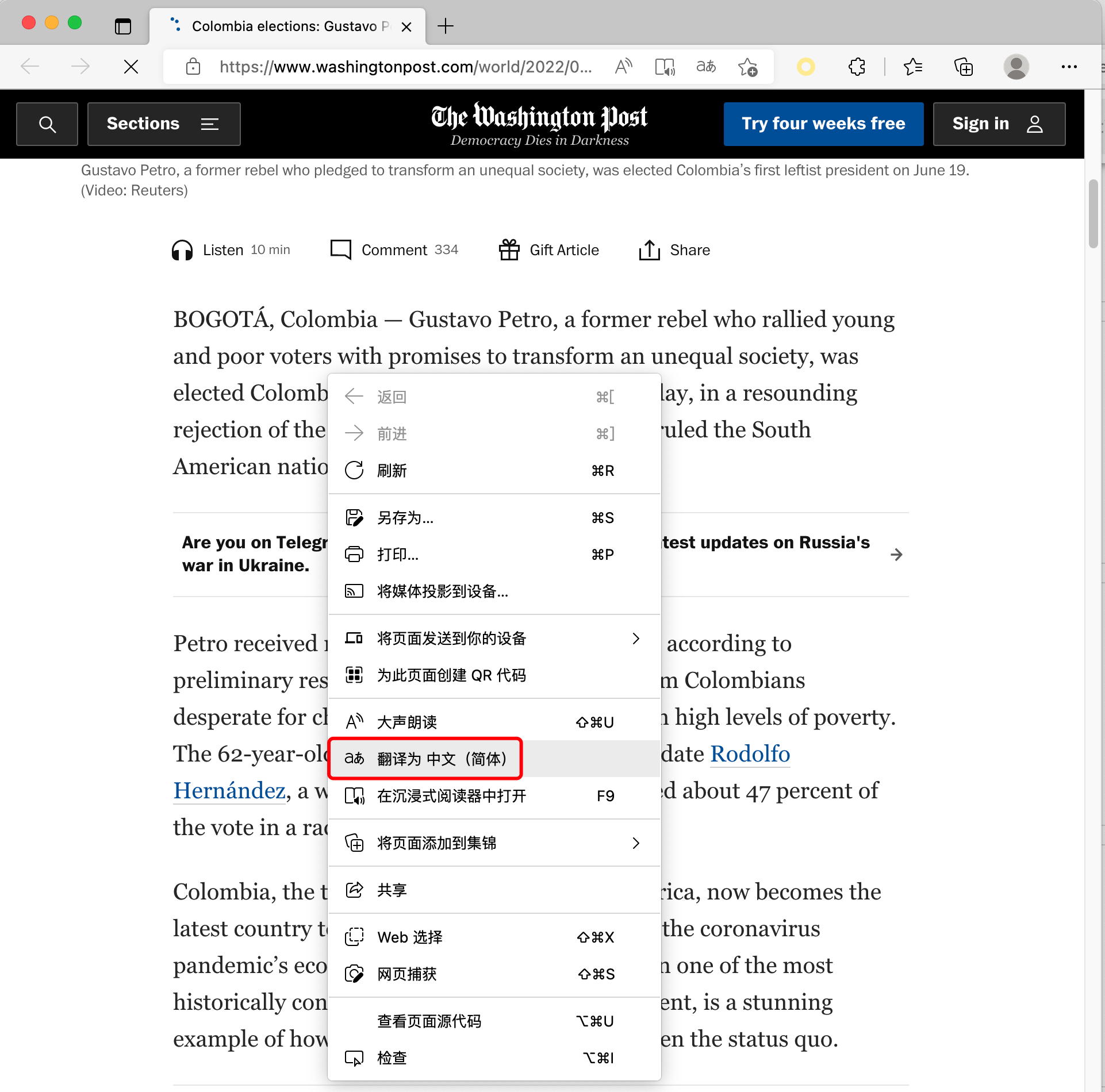
After one-click translation into Chinese, it looks like this:
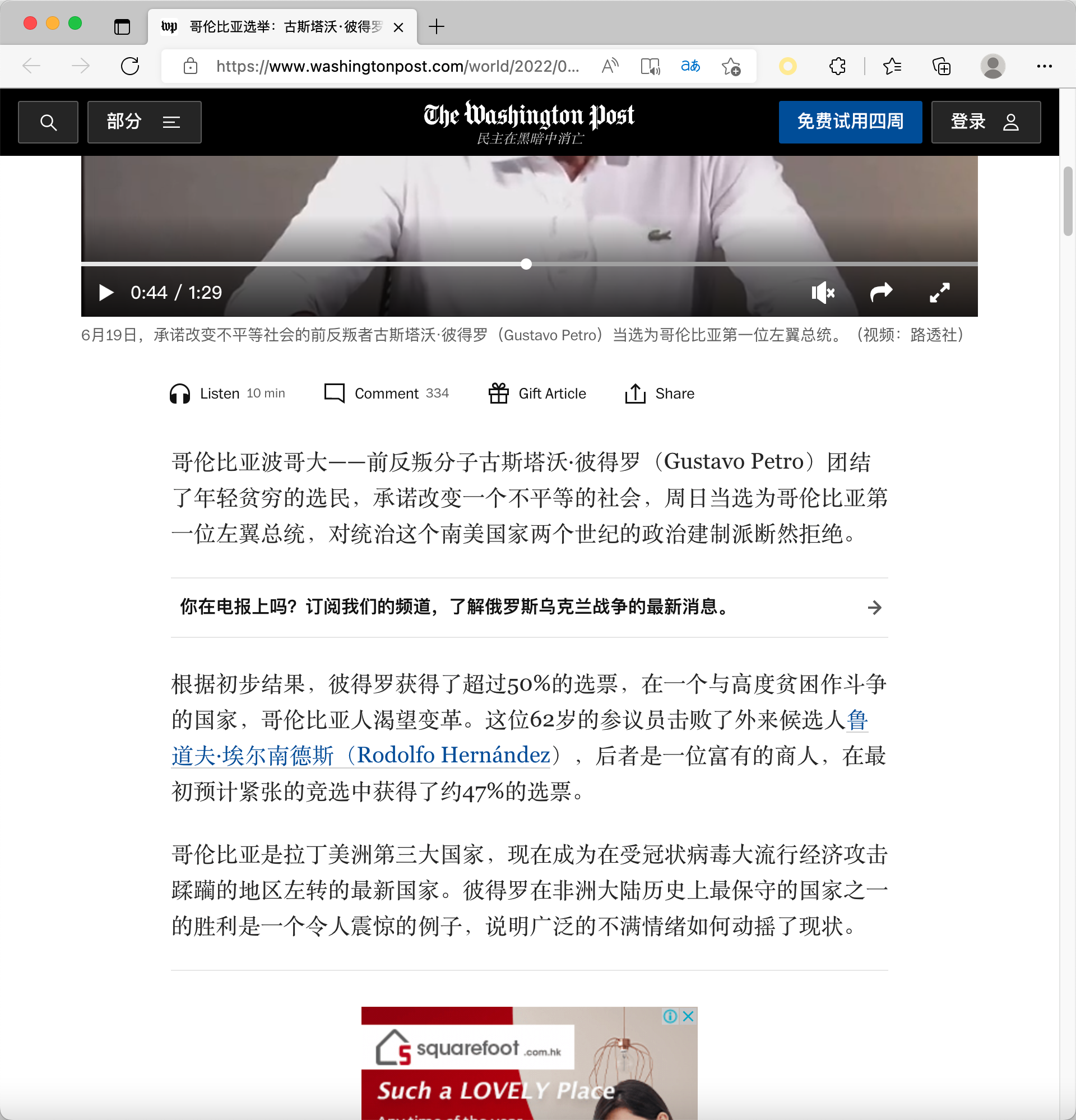
You may think this function is very simple, isn’t it just string replacement? Then you can try to translate the English below the <p> tag in the HTML fragment below into Chinese. Do not change in other tags:
1 |
< div > |
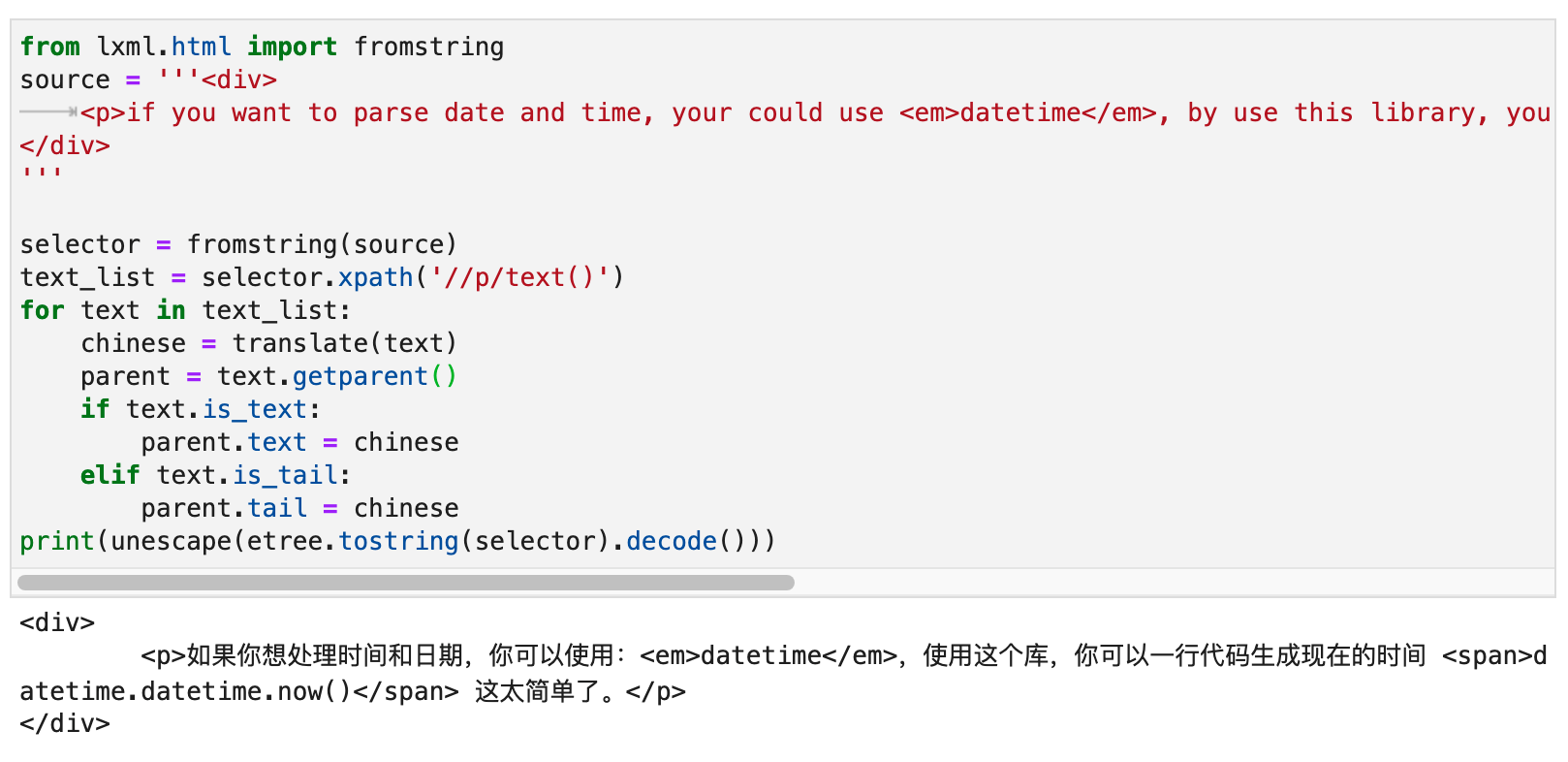
Datetime in <em> tags and datetime datetime.datetime.now() in <span> tags do not require translation.
As soon as you patted your head, you immediately wrote the following lines of code (assuming you already have a ready-made translate() function, passing in English and outputting Chinese):
1 |
from lxml.html import fromstring |
When you write this, you should be taken aback. Because you suddenly found a problem, how to replace the Chinese back?
Don’t try to go to Baidu. Before today (2022-06-20), in the entire Chinese network, you cannot find a solution.
A dumber solution is to do text replacement directly on the raw HTML string:
1 |
for text in text_list: |
But doing so is very inefficient. Because you’re going to keep scanning the entire HTML string. Generally, the HTML of a medium-sized website has thousands of lines and more than 100,000 to 200,000 characters. You replace the whole text every time you translate a small paragraph, which will take a long time.
Is there a way to replace only the text in the current <p> tag? The key question is, you can replace it, but how can it not affect the two sub-tags under the <p> tag? To ensure that the relative position of the text and subtags does not change.
If there is only a paragraph of text under the <p> tag and no subtags, then it is very simple, as shown in the following figure:
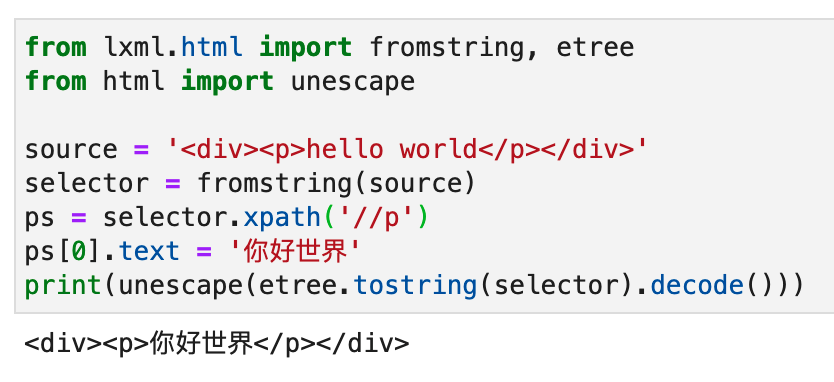
But now the problem is that there are three paragraphs of text below the <p> tag. Additional subtags are inserted between each paragraph of text. How can we replace each piece of text, but keep the relative order of the text, and still not affect the subtags?
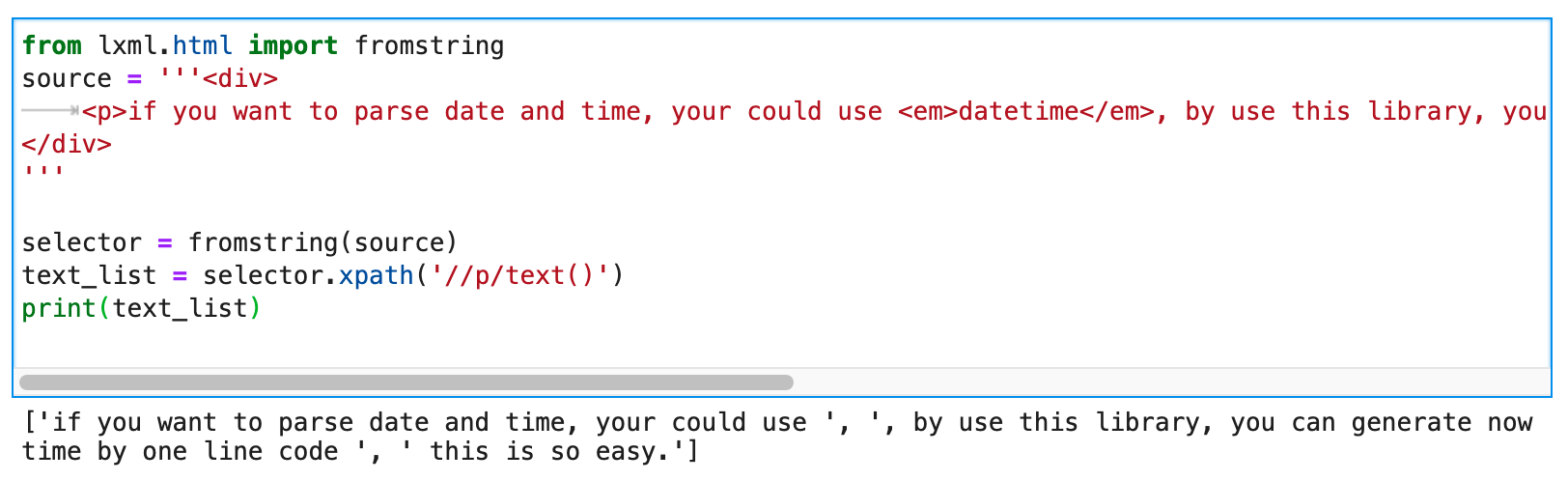
The writing method of p.text can be excluded at first, because it has no way to specify which paragraphs of text to replace.
The reason why you think this problem is difficult to solve is because you have an illusion, please see the screenshot above, I printed the text_list . What prints out is a list containing strings. So you might think. When using lxml to write Xpath, /text() always returns a list containing strings.
But in fact, the elements in the returned list are not strings, but _ElementUnicodeResult objects. As shown below:
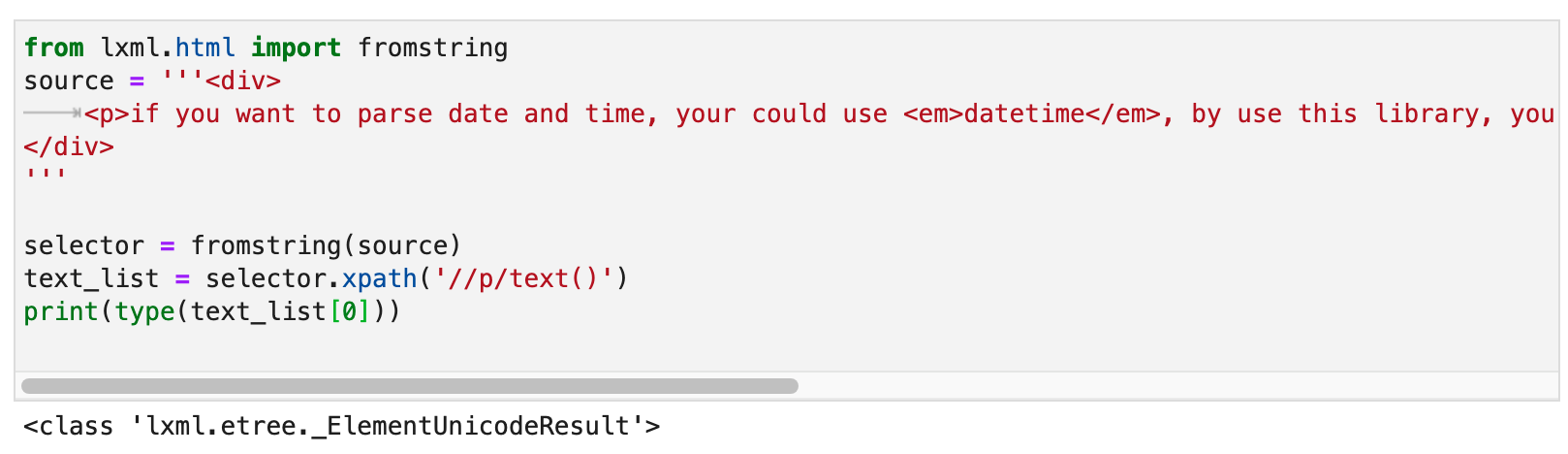
If it is not a string, it is simple, then we can get the parent tag of each text object. Then modify the text below the parent tag.
Seeing this, you will definitely ask, aren’t the parent tags of these three text nodes all the same <p> ? If you think so, then you’ve made the mistake of taking it for granted. Let’s take a look with code:
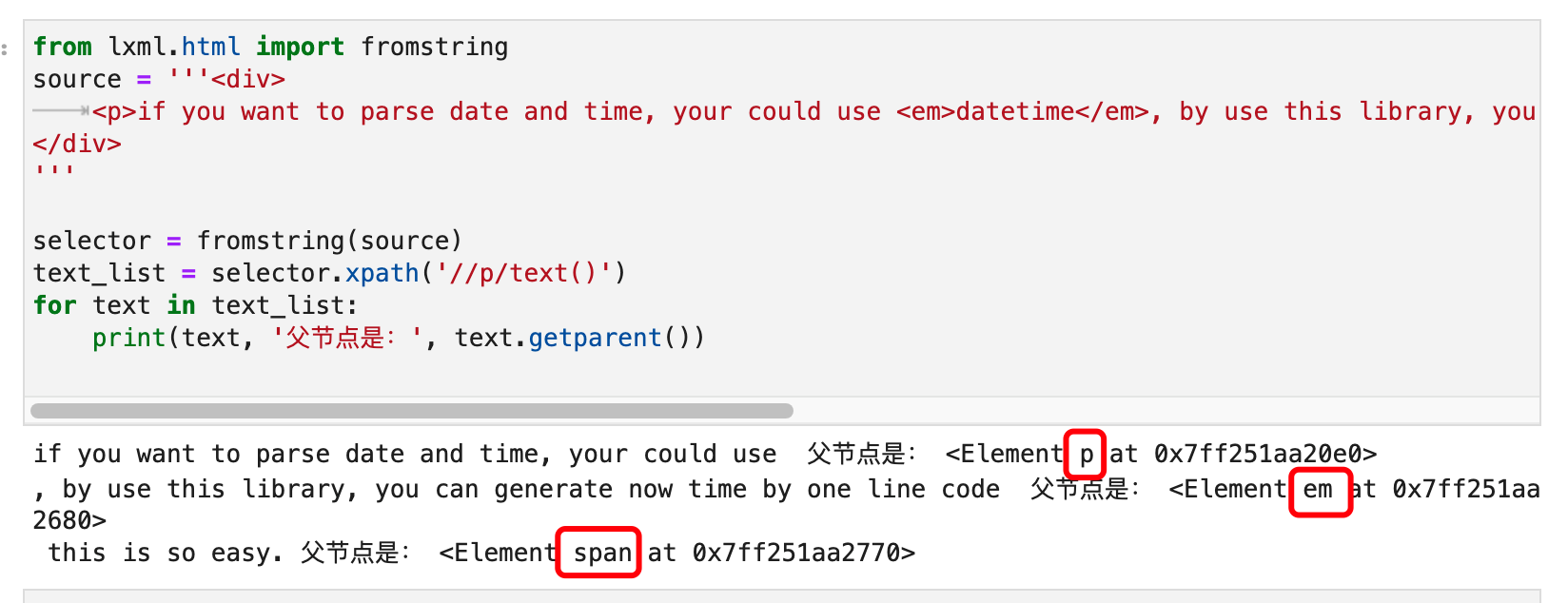
Actually only the parent tag of the first paragraph of text is <p> . The parent tag of the second paragraph of text is actually a child tag <em> of <p> >. The parent tag of the third paragraph of text is <span> .
Wait, if the parent tag of the second paragraph of text is <em> , what is the parent tag of the datetime inside the <em>datetime</em> ? Its parent tag is also <em> ! So the question is, how can the text() text node of <em> be datetime and the second paragraph of text below <p> ?
In fact, <em> ‘s text() is always datetime . As shown below:
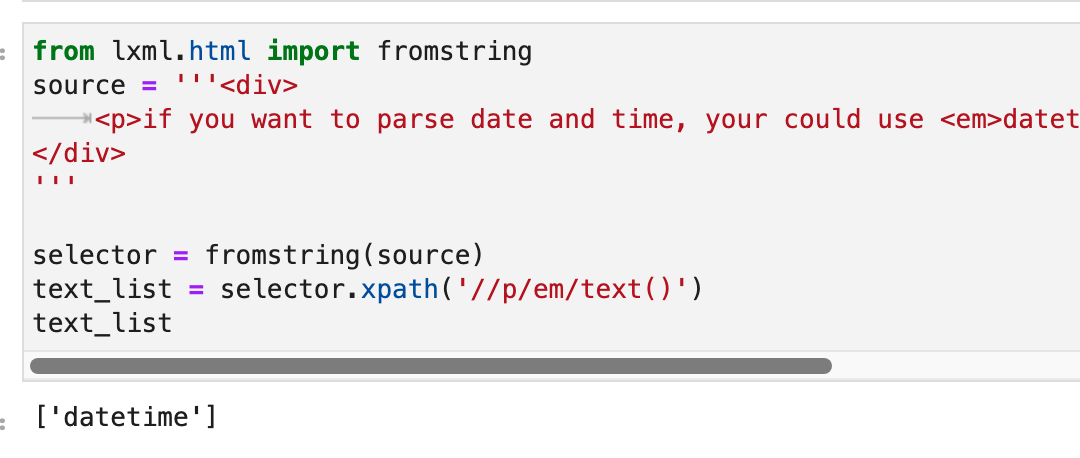
So, what does the second paragraph of <p> have to do with this <em> tag? Actually, this relationship is called tail . As shown below:
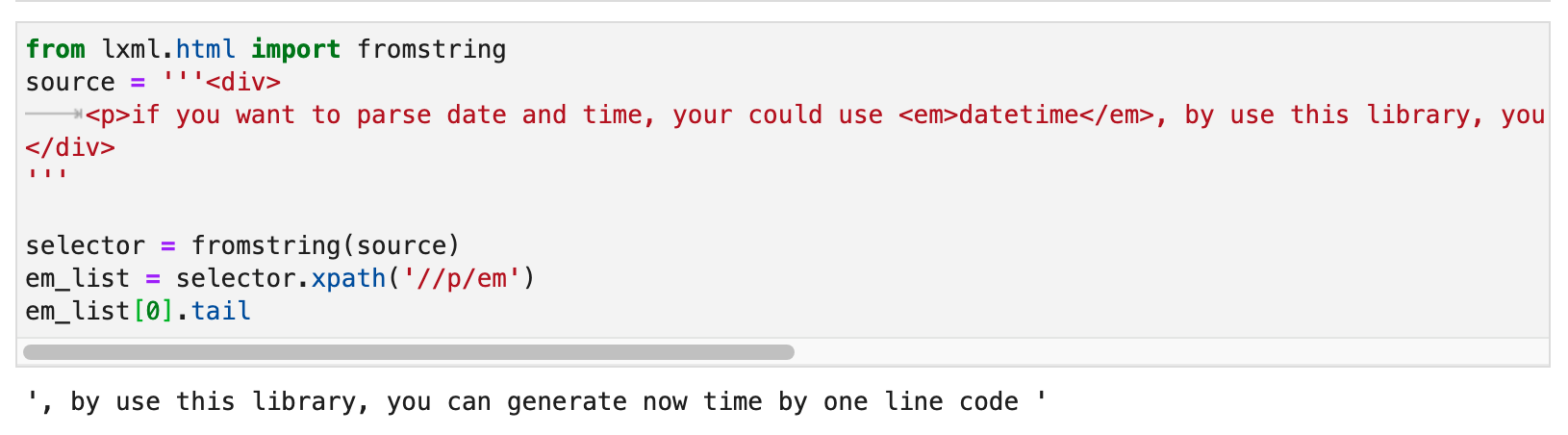
In a tag, only the first paragraph of text is its real text() . If the tag has subtags, the text behind the subtag is the tail of the subtag. It’s just that when we write /text() in the regular expression, lxml will help us count the tail of all subtags as the text of the current tag.
We can use the .is_text and .is_tail of a text node to tell what kind of text it belongs to. The final operation effect is shown in the following figure:
This article is reproduced from: https://www.kingname.info/2022/06/20/translate-html/
This site is for inclusion only, and the copyright belongs to the original author.