Original link: http://mednoter.com/manage-rails-deploys.html
When using the command line rails new to create a new project, Rails creates three environments by default:
- development: The local development environment.
- test: used to run tests.
- production: The production environment, used to serve customers.
At the earliest stage of the project, it was still in the stage of validating the idea. The workflow of engineers is also relatively rough, writing code, running tests, and then deploying directly to the production environment.
The first stage of the business: the small number of customers stage
The product continues to iterate, and gradually customers begin to use the product. In order to ensure the quality of the project, it is necessary to add a pre-release environment to Rails at this time, which is usually named as the staging environment, and the workflow is also rigorous:
- Engineers develop new features locally. (developer environment)
- Run tests in CI (or locally). (test environment)
- The code is merged into the staging branch and deployed to the staging environment, where QA engineers test new features.
- If there are no bugs, deploy to the production environment for customer use.
environments ├── development.rb ├── staging.rb ├── production.rb └── test.rb
The second stage of the business: a large number of customers + multi-team collaboration
If the product market responds well, there are more and more customers. The size of the engineering team has also expanded from a few people to dozens or hundreds of people. There are many people and they share a staging environment, so it is easy to conflict when merging the code into the staging branch.
When programmers are patient, they will contact the original author when they encounter code conflicts and solve them together. If it is a multinational team, it will take a day for a back-and-forth communication due to the time difference. At this time, the programmer may be impatient and reset the staging branch of git directly. This will lead to a series of misunderstandings. The function that others are testing disappears out of thin air, and the QA engineer reports a bug, and the result is that the code is reset.
In order to reduce code conflicts and communication costs, many companies choose to create dedicated deployment instances for different teams, rather than eating a big pot of rice. Each team is not guilty of water. If a bug occurs in a deployment, it will only affect a single team and will not drag down the development progress of the entire company.
| example | The deployed Git branch | use |
|---|---|---|
| production | release/xxx | Production environment for customers |
| demo | demo | Sales to clients for presentations. |
| staging | main / next release branch | For regression testing before going live |
| staging-1 | staging-1-branch | For the “Little Panda” team |
| staging-2 | staging-2-branch | For the “Suicide Squad” team |
| staging-3 | staging-3-branch | For the “Starship” team |
| staging-4 | staging-4-branch | For the “Deep Sea Monster” team |
| staging-5 | staging-5-branch | For the “Argonne” team |
| staging-… | staging-6-branch | For use by the team |
The more engineers, the more Rails environment is required. How to create more deployment environments?
You can create configuration files for 7 environments in the Rails config/environments directory. This is the configuration style recommended by Rails, and it is original.
> tree environments environments ├── demo.rb ├── development.rb ├── production.rb ├── staging.rb ├── staging-1.rb ├── staging-2.rb ├── staging-3.rb ├── staging-4.rb ├── staging-5.rb ├── staging-6.rb └── test.rb
But things are not that simple, there is a lot of extra work besides config/environments . We are going to add database configuration for 7 new environments in config/database.yml .
default : &default adapter : postgresql database : <%= ENV['DATABASE_NAME'] %> username : <%= ENV.fetch("DATABASE_USER", 'postgres') %> password : <%= ENV['DATABASE_PASSWORD'] %> port : 5432 production : << : *default demo : << : *default staging-1 : << : *default staging-2 : << : *default staging-3 : << : *default ...
In addition, if some engineers define configuration in constants, then we also need to check various constants to ensure that the newly created environment has matching assignments. Especially for variables defined in corners, if you don’t notice it, the new environment will always report errors. So need to search Rails.env , so as not to miss.
# config/initializers/sidekiq.rb case Rails.env when :staging-1 REDIS_HOST = 'redis-s1.3922002.redis.aws.com:6379' when :staging-2 REDIS_HOST = 'redis-s2.3922002.redis.aws.com:6379' ...
Defining configuration in constants is too error-prone. Most engineers will extract the configuration of different deployment environments, put them in different files, and use some libraries to manage the configuration. The commonly used library for Rails is rubyconfig/config . If the team is using these libraries, we also need to add configuration files for the new environment.
config/settings/production.yml config/settings/staging.yml config/settings/demo.yml config/settings/staging-1.yml config/settings/staging-2.yml config/settings/staging-3.yml config/settings/staging-4.yml config/settings/staging-5.yml ...
The above solutions have several disadvantages:
First, even if there are complete internal documents, the whole set is completed, the amount of engineering is not small, and the labor cost is very high.
Second, every time a new environment is created, the constants in the old code must be modified. Modifying the old code that is running is a big taboo in the military. If you are not careful, you will be riddled with bugs and die without a place to die.
Third, the security is poor. The configuration includes client_secret, token, and private key. If the code is unfortunately leaked, all kinds of secret keys will be taken away. The docker image created using this scheme is mixed with various configuration information and is not clean. In case of leakage, it is also a hassle.
Despite its flaws, this Rails-native solution can hold up for a while.
The third stage of business: privatized deployment + development team of more than 100 people
Many programmers have an assumption: “there is only one production deployment environment”. There are two reasons for this assumption:
- Most To C products only need a production deployment to meet the needs of all customers.
- Even To B’s SaaS is a multi-tenant design, and one Production deployment environment can meet the needs of all tenants.
As the business grows, this assumption will be shattered.
For the sake of national security, some countries require that the data of their citizens must be stored in their own data centers . Apple iCloud has both a data center in the United States and a data center in Guizhou, China. The same set of code is deployed in China and the United States, both of which are production deployment instances. Douyin is deployed on Oracle Cloud in the United States, and in its own computer room in China, and their operating mode is also production mode.
Large customers are required to privatize deployment due to security concerns . The same set of code of Alibaba Cloud will be sold to the government, China Telecom, and the public security system, and the code will be deployed in their respective computer rooms. Github Enterprise Edition allows companies to deploy code to their own computer rooms, and their operating mode is also production.
So a set of SaaS, the deployment scenario in the real world should look like this:
| example | The deployed Git branch | use |
|---|---|---|
| production | release/100* | Deployed on the public cloud, multi-tenant SaaS |
| production-gov | release/101 | The customer is the government, deployed in the government’s private computer room |
| production-cnpc | release/99 | The client is PetroChina, which is deployed in the private computer room of PetroChina |
| production-china-police | release/100 | The client is a Chinese policeman, deployed in the private computer room of the public security |
| production-us-police | release/100 | The customer is the US police, deployed on AWS |
| production-microsoft | release/100 | The customer is Microsoft, privatized deployment |
| demo | demo | Sales to clients for presentations. |
| staging | main / next release branch | For regression testing before going live |
| staging-1 | staging-1-branch | For the development and testing of the “Little Panda” team |
| staging-2 | staging-2-branch | For the “Suicide Squad” team development and testing use |
| staging-3 | staging-3-branch | For the “Starship Battleship” team development and testing use |
| staging-4 | staging-4-branch | For the development and testing of the “Deep Sea Monster” team |
| staging-5 | staging-5-branch | For “Argonne” team development and testing use |
| staging-… | staging-6-branch | For… team development and testing use |
note:
release/xxx represents a deployment branch that has been QA tested.
When there are many production deployment environments, do you have to mix all the configuration into the code? Obviously not possible! Customers do not agree!
Therefore, everyone agrees that the code should be stateless, and the configuration information should be stored separately, so that there is no need to change a line of code when adding deployments.
The 12-factor Application
Heroku has written a SaaS architecture article ” 12-factor Application “, which outlines 12 principles for designing SaaS applications and is regarded as a standard. To this day, it is still unrivaled.
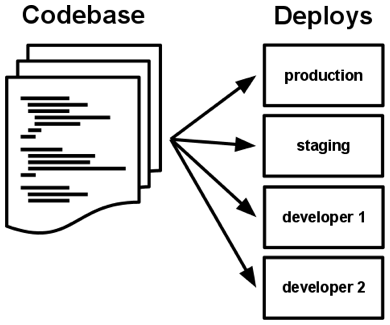
Principle 1: One Codebase, Many Deployments
Although each application corresponds to only one benchmark code, multiple deployments can exist at the same time. Each deployment is equivalent to running an instance of the application. Typically there will be one production environment and one or more staging environments.
Second Principle: Explicitly declare dependencies ( dependency )
The same code, on different machines, has the same dependencies and the same behavior, for example:
- JavaScript uses npm or yarn to manage dependencies for various libraries.
- Ruby uses Bundler to manage version dependencies of various libraries.
- Docker not only packages the library dependencies of the code, but also the operating system dependencies. Anyone can run the code after getting the docker image, and there will be no embarrassing situation: a piece of code can only run on my computer, not on your computer.
The third principle: store configuration in the environment
The 12-factor App: Configuration
12-Factor recommends storing application configuration in environment variables ( env vars, env ). Environment variables can be easily changed between deployments without changing a single line of code.
Docker
For example, Docker allows you to put configuration into environment variables to create different instances (containers).
docker run --name postgresql \ -e POSTGRES_USER=myusername \ -e POSTGRES_PASSWORD=mypassword \ -p 5432:5432 -v /data:/var/lib/postgresql/data \ -d postgres
Helm
Helm is a package management tool for Kubernetes applications. It has three core concepts, chart, config, and release.
- chart is a template
- config is configuration information
chart + config = release (a deployed instance)
Optimize the plan according to the 12-factor principle
The first step is to make the code stateless, and all configuration information in the code is taken from environment variables.
For example, the configuration of the DB is taken from environment variables.
# config/database.yml # ... production : << : *default database : <%= ENV['DATABASE_NAME' %> host : <%= ENV['DATABASE_HOST'] %> password : <%= ENV['DATABASE_PASSWORD'] %>
Sidekiq’s configuration is also taken from environment variables.
Sidekiq . configure_server do | config | config . redis = { host: ENV [ 'REDIS_HOST' ], port: 6379 } end # ...
Any logic, as long as it is related to the environment, is configured from environment variables.
class OauthController < ApiController def redirect redirect_to ( ENV [ 'GOOGLE_OAUTH_URL' ]) end end
The second step is to prepare the configuration file.
Create configurations for deployment environments such as staging-1, staging-2, staging-3, staging-4, staging-5, … staging-x, demo, production, production-gov, production-china-police, production-us-police, etc. document.
If you are using AWS, you can save the configuration of a deployment in Parameter Store , and sensitive information can be saved in AWS secret manager .
# 创建staging-1 的配置信息aws ssm put-parameter \ --name "staging-1-configuration" \ --value "parameter-value" \ --type String \ --tags "DB_HOST=xxx,DB_USER=xxx,DB_PASSWORD=xxx,REDIS_HOST=xxx,GOOGLE_OAUTH_URL=xxxx"
If you are using Kubernetes, you can save the configuration information of different deployments in different ConfigMaps , and save sensitive information in Secret .
kubectl create configmap staging1-config-map \ --from-literral="DB_HOST=xxx" \ --from-literral="DB_USER=postgres" \ --from-literral="DB_PASSWORD=xxx"
The third step is to run each deployment environment in production mode.
Because there are many production environments and many staging environments, the files production.rb / staging.rb under config/environments have nothing to do with running instances, but represent a running mode.
staging-1, staging-2, staging-3, staging-4, staging-5, … staging-x, demo, production, production-gov, production-china-police, production-us-police The internal running scripts are as follows shown:
export .env RAILS_ENV=production rails s
Step 4: Combine the code and configuration to create a deployment instance.
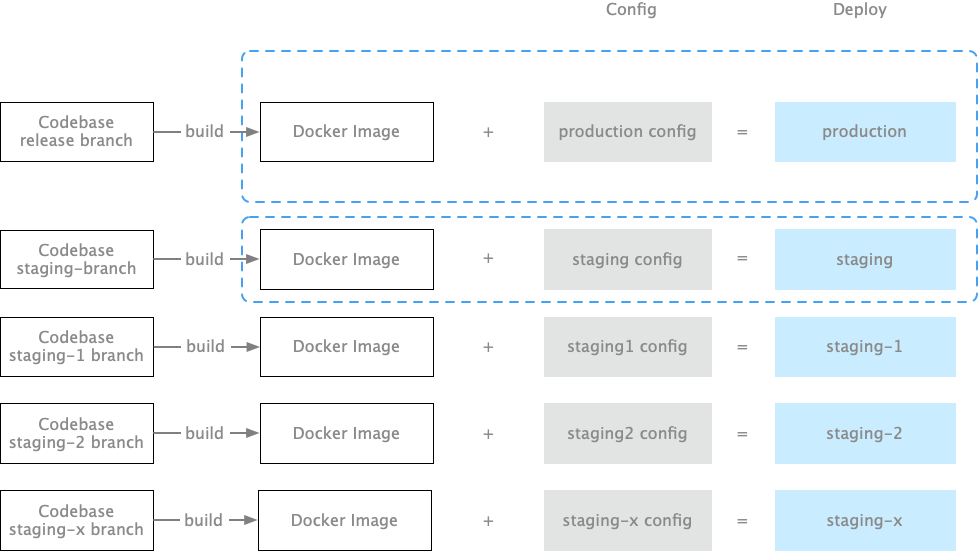
If you are using Capistrano to deploy code, then
Code + 不同配置= 部署实例
If you are using Docker deployment then:
Docker Image + 不同配置= 部署实例
If you are using Kubenetes, injecting different configuration files into the Pod becomes a different deployment instance.
--- apiVersion : v1 kind : Pod metadata : labels : name : webapp name : webapp namespace : default spec : containers : - name : web-app image : web-app:staging-1 envFrom : - configMapRef : ? 看这里name : staging-1-config-map - secretRef : ? 看这里name : staging-1-secrets
advantage
To create a deployment instance, you only need to prepare a new configuration file, which saves time and effort.
Code and Docker images do not contain confidential information. Even if the code is leaked, it will not expand the risk, and secondly, it is convenient for private deployment.
Different access permissions can be set for different deployment configuration files, such as allowing only specific teams to access configuration information for production deployment instances.
All deployments in this article are run in production mode, which eliminates the differences ( parity ) between deployments.
shortcoming
Monitoring tools such as NewRelic, Datadog, and Sentry will attach environmental information to the monitoring data by default, which is convenient for filtering. In the second scenario, all deployment instances run in production mode, which results in all monitoring data being mixed under production. In the event of an accident, engineers simply cannot check which deployment instance has the problem.
How to troubleshoot monitoring tools?
In fact, NewRelic, Datadog, and Sentry provide interfaces that allow us to customize the name of the deployment instance. Taking Sentry as an example, its syntax is as follows:
Sentry . init do | config | #... config . environment = "你喜欢的部署名" end
Therefore, we can introduce a new variable “DEPLOYMENT_ID” in the configuration of different deployment instances such as staging-1, staging-2, staging-x, production-x, etc. to declare the name of the instance and assign it to the monitoring tool.
Suppose the configuration information of staging-1 is as follows:
DEPLOYMENT_ID=staging-1 DB_HOST=staging-1.db DB_USER=postgres ...
We can configure Sentry like this:
Sentry . init do | config | #... config . environment = ENV [ 'DEPLOYMENT_ID' ] # 它的值为staging-1 end
Datadog can be configured like this:
Datadog . configure do | c | # ... c . env = ENV [ 'DEPLOYMENT_ID' ] # 它的值为staging-1 end
This will ensure the normal display of monitoring tools.
grateful
The solution in this article comes from the practical experience of Workstream colleagues and former SAP colleagues, and I just wrote it down.
Special thanks to Louise Xu, Felix Chen, Vincent Huang, Teddy Wang, Kang Zhang for review and feedback.
This article is reproduced from: http://mednoter.com/manage-rails-deploys.html
This site is for inclusion only, and the copyright belongs to the original author.