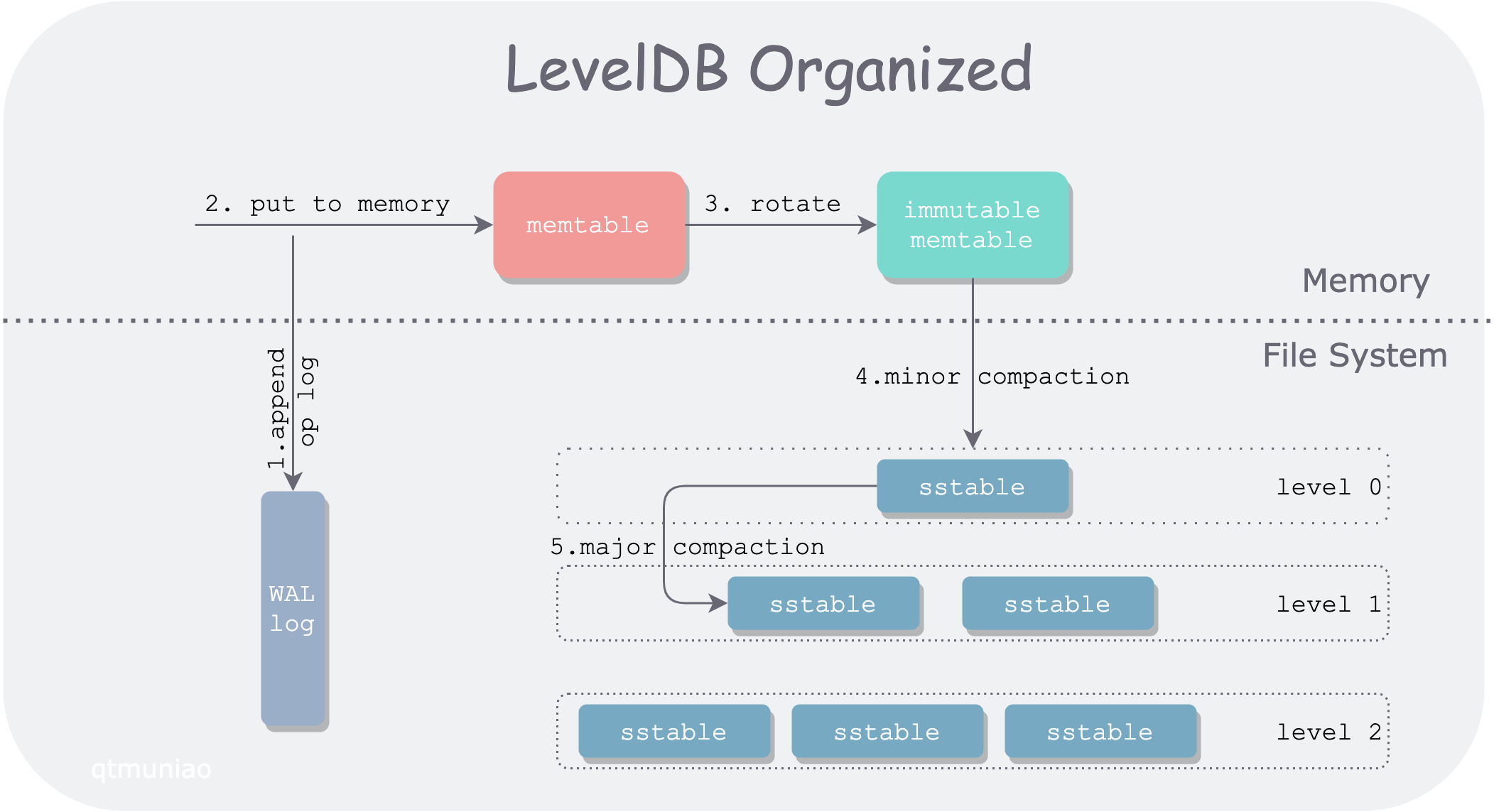
Google LevelDB is an example of an LSM-Tree implementation. However, after the open source was released, in order to maintain a lightweight and concise style, apart from fixing bugs, there has been no major update and iteration. In order to make it able to meet the diverse loads in the industrial environment, Facebook (Meta) made various optimizations after Fork LevelDB. In terms of hardware, modern hardware can be used more effectively, such as flash memory and fast disks, multi-core CPUs, etc. In terms of software, a lot of optimizations have been made for read and write paths and compaction, such as SST index, index sharding, prefix Bloom Filter, column family Wait.
This series of articles, based on the RocksDB series of blogs , combined with source code and some usage experience, shared some interesting optimization points, hoping to inspire everyone. The level is limited, and if it is inappropriate, please leave a message for discussion.
This article is the first article in the RocksDB optimization series. In order to optimize deep query performance, SST at different levels is indexed in a certain way.
This article is reprinted from https://www.qtmuniao.com/2022/08/21/rocksdb-file-indexer/
This site is for inclusion only, and the copyright belongs to the original author.