Content source: ChatGPT and large model seminars
Sharing guest: Zhang Junlin, head of new technology research and development of Sina, director of Chinese Information Society of China
Sharing topic: “Emerging Power of Large Language Models: Phenomena and Explanations”
Reprinted from: https://ift.tt/vDnzB4c
Note 1: This article organizes my on-site sharing of “The Emergent Ability of Large Language Models: Phenomena and Explanations” at the “ChatGPT and Large Model Symposium” hosted by the “Chinese Association for Artificial Intelligence” and organized by Daguan Data on March 11 this year. Introduces emergent phenomena in large language models, and related conjectures about the reasons behind emergent power. Thanks to CSDN for helping to organize the manuscript.
Note 2: In addition, someone asked, since many natural phenomena also show emerging capabilities, does the emergence of large language models need to be explained? I personally think it is necessary. After all, saying that a special phenomenon of the big language model belongs to the “emergent phenomenon” is also proposed by individual studies, and there is no definite proof or evidence. Whether it is similar or the same as the internal mechanism of the emergent phenomenon that appears in natural phenomena is actually the same. Can be suspicious. And I think there should be some reasons behind this phenomenon of large models that we can understand. If we don’t pursue the explanation behind the phenomenon, but just classify the phenomenon that cannot be explained currently as emergence or other concepts, we will leave it at that. Well, in fact, we can also collectively classify many phenomena that cannot be understood in the large model as a kind of “miracle”, and then many things in the world will be much simpler. In addition, using Grokking to explain emerging phenomena, although I call it “explaining metaphysics with metaphysics”, I think it is still worth exploring in depth. Maybe the above statement can be optimized as “explaining metaphysics with less metaphysics” Another metaphysics with a high content of metaphysics.”
Note 3: If you analyze carefully, the so-called “emergence phenomenon” of the large language model, if the phenomenon is only attributed to the size of the model, the current high probability is to simplify the problem, and it is very likely that the influencing factors are diversified. If I were to generalize, the variable y of whether a large language model will appear “emergence phenomenon” in a certain task is likely to be an unknown function affected by the following factors:

As for this, further research and explanation are needed.
1. What is the emergent capability of large models
Emergent phenomena have been studied for a long time in complex systems disciplines. So, what is an “emergent phenomenon”? When a complex system is composed of many micro-individuals, these micro-individuals come together and interact with each other. When the number is large enough, special phenomena that cannot be explained by micro-individuals are displayed at the macro level, which can be called “emergent phenomena”.
 emergent phenomenon in life
emergent phenomenon in life
There are also some emergent phenomena in daily life, such as the formation of snowflakes, traffic jams, animal migration, eddy current formation, etc. Here we take snowflakes as an example to explain: snowflakes are composed of water molecules, and water molecules are very small, but if a large number of water molecules interact under the premise of changing external temperature conditions, a very regular, very symmetrical, Very beautiful snowflakes.
The question, then, is: will super large models emerge? Obviously many of us know the answer, and the answer is yes.
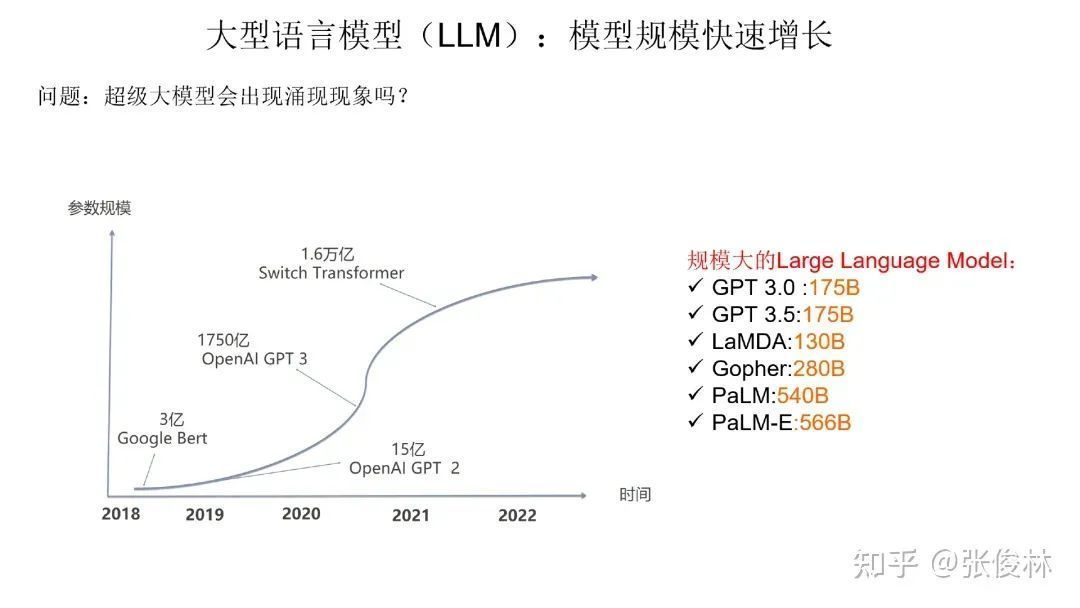
Schematic diagram of large language model parameter growth
Let’s first look at the growth of the large language model. If you summarize the biggest technological progress of the large language model in the past two years, it is likely to be the rapid growth of the model size. Today, large-scale models generally exceed 100B, that is, hundreds of billions of parameters. For example, the multimodal embodied visual language model PaLM-E released by Google is composed of a 540B PaLM text model and a 22B VIT image model. The two integrate and process multimodal information, so its total model size is 566B.
What is the impact on downstream tasks when the scale of large language models continues to grow? There are three different representations for different types of tasks:
The first category of tasks exhibits the law of scaling: tasks of this type are generally knowledge-intensive. As the scale of the model continues to grow, the effect of the task also continues to grow, indicating that this type of task has a higher requirement for the amount of knowledge contained in the large model.
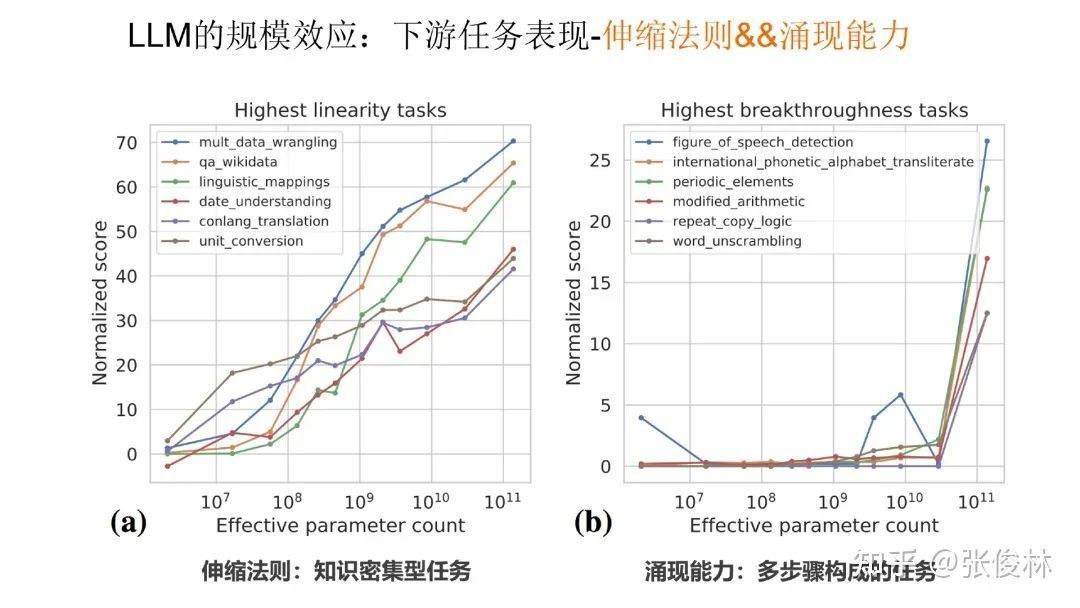
The Law of Scaling and Emergence
The second type of tasks exhibit emergent ability: this type of task is generally a complex task composed of multiple steps. Only when the model scale is large to a certain extent, the effect will increase sharply. Before the model scale is smaller than a certain critical value, the model basically does not have the ability to solve the task. This is a typical manifestation of emergent ability. Such tasks present a commonality: most of them are complex tasks composed of multiple steps.

The number of the third type of tasks is small, and as the scale of the model increases, the task effect reflects a U-shaped curve. As shown in the figure above, as the model scale increases, the model effect will show a downward trend at the beginning, but when the model scale is large enough, the effect will increase instead. If the chain of thought CoT technology is used for such tasks, the performance of these tasks will be transformed into a scaling law, and the effect will continue to increase as the model scale increases.
Therefore, the growth of model scale is an inevitable trend. When the scale of large models continues to grow, the emergence of emergent capabilities will make the task more effective.
2. Emergence shown by LLM

At present, there are two categories of tasks that are considered to have emergent capabilities. The first category is In Context Learning (“Few-Shot Prompt”). The user gave a few examples. The large model can handle the task well without adjusting the model parameters ( Refer to the example of affective computing given above).
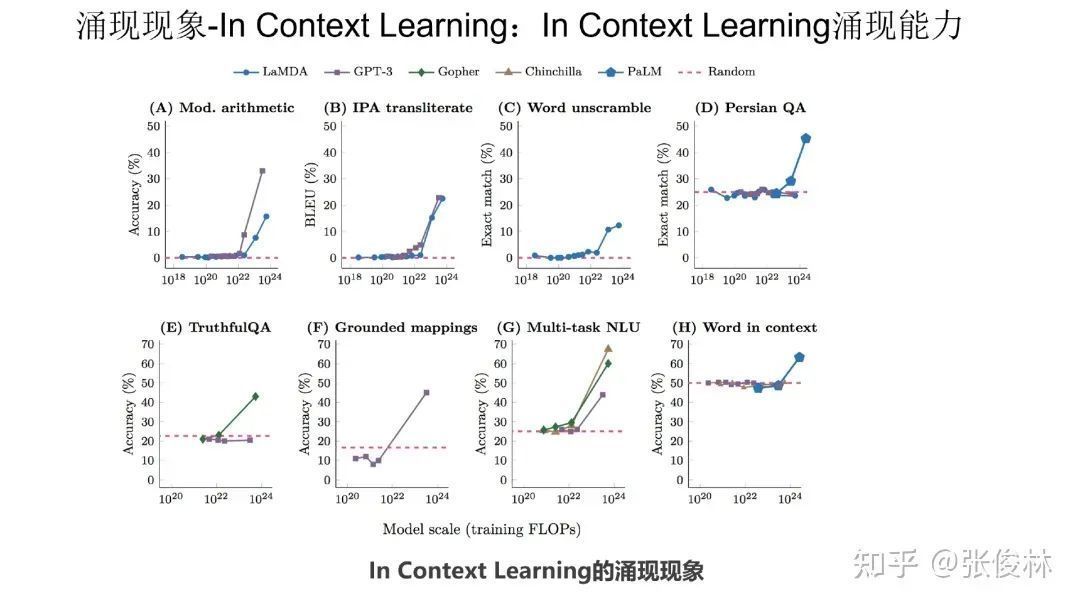
As shown in the figure above, using In Context Learning, it has been found that in various types of downstream tasks, large language models have emerged. This is reflected in the fact that various tasks cannot be handled well when the model size is not large enough, but when cross After a certain model size threshold, large models suddenly handle these tasks better.
The second category of emerging technologies is Chain of Thought (CoT). CoT is essentially a special few shot prompt, that is to say, for a complex reasoning problem, the user writes out the step-by-step derivation process and provides it to the large language model (as shown in the blue text in the figure below), In this way, the large language model can do some relatively complex reasoning tasks.
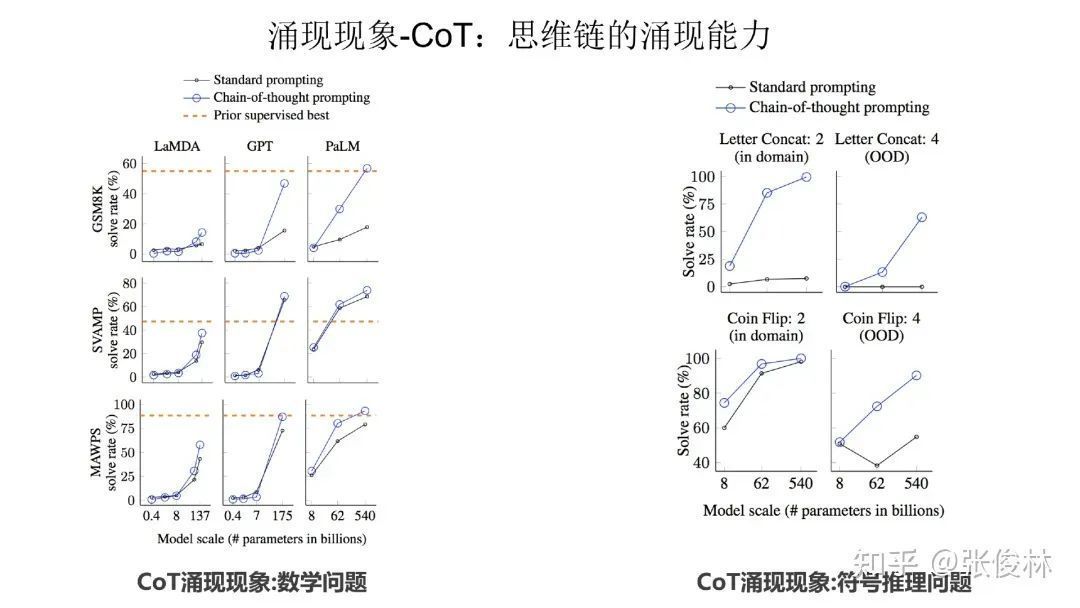

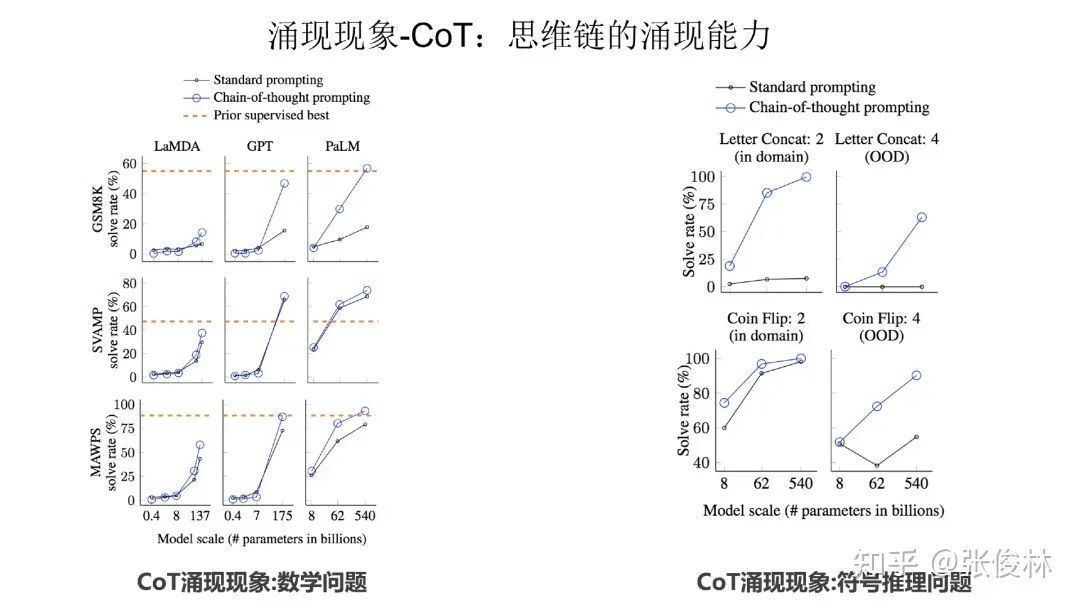
As can be seen from the above figure, whether it is a mathematical problem or a symbolic reasoning problem, CoT has the ability to emerge.

In addition, other tasks also have emergent capabilities, such as mathematical multi-digit addition and command comprehension shown in the figure above.
3. The relationship between LLM model size and emergence ability
It can be seen that there is a certain relationship between the emergent capacity and the size of the model. Then, our question is, specifically, what is the relationship between the two?
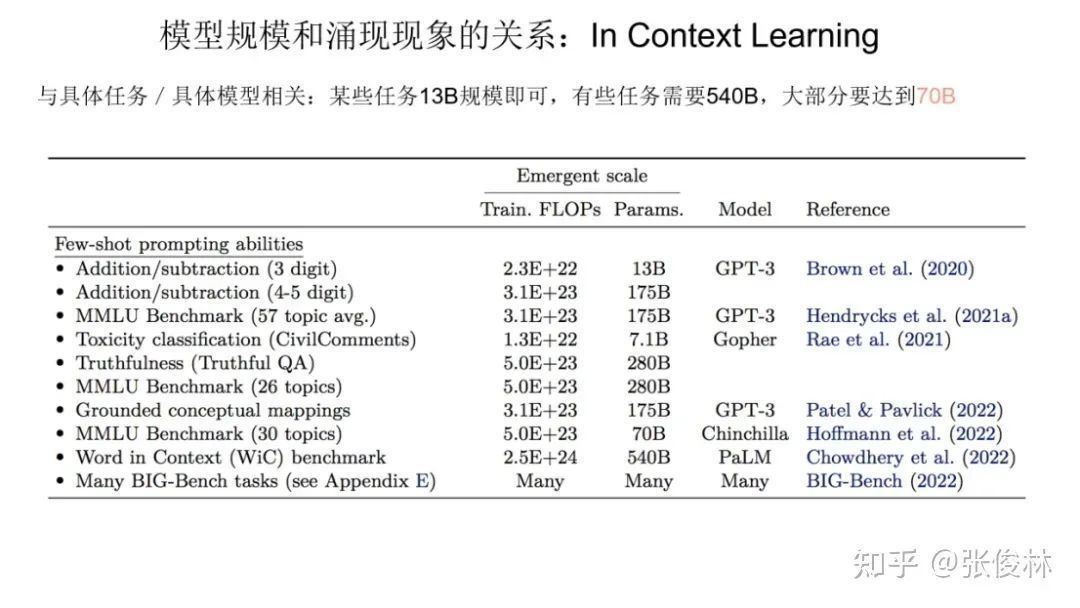 Let’s look at it separately, first look at the relationship between the emergence ability of In Context Learning and the model size. The figure above shows the relationship between the emerging ability of In Context Learning and the size of the model for different types of specific tasks.
Let’s look at it separately, first look at the relationship between the emergence ability of In Context Learning and the model size. The figure above shows the relationship between the emerging ability of In Context Learning and the size of the model for different types of specific tasks.
As can be seen from the data in the figure, it is difficult for us to give a unique model size value. For different types of tasks, in terms of In Context Learning, the size of the model has the ability to emerge, which has a certain binding relationship with specific tasks. For example: for the 3-digit addition task in the first row of the chart, as long as the model reaches 13B (13 billion parameters), it can have the emergence capability, but for the Word in Context Benchmark task in the penultimate row, it has been proved that the size is only 540B model can do this. We can only say that in terms of In Context Learning, if the model reaches 100B, most tasks can have emergent capabilities.
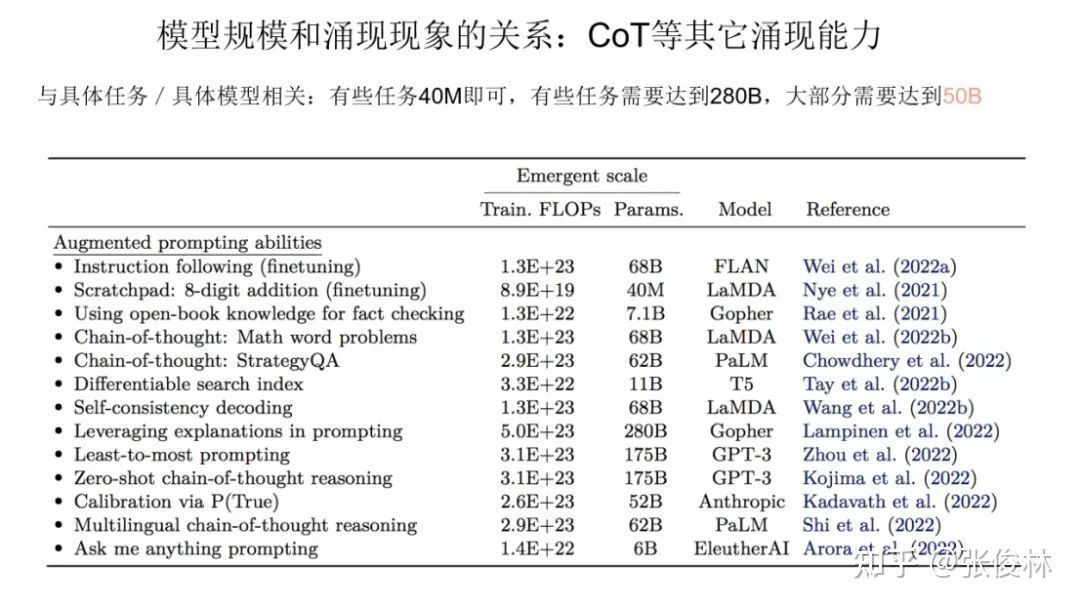 For CoT, the conclusion is similar, that is to say, in order to have emergent capabilities, the size of the model has a certain binding relationship with specific tasks.
For CoT, the conclusion is similar, that is to say, in order to have emergent capabilities, the size of the model has a certain binding relationship with specific tasks.
4. Will making the model smaller affect the emergent ability of LLM?
Because for many tasks, only when the scale of the model is relatively large can it have the ability to emerge, so I am more concerned about the following questions: Can we make the model smaller? Will making the model smaller affect the emergent ability of LLM? This is an interesting question. Here we take two small model representatives to discuss this issue.
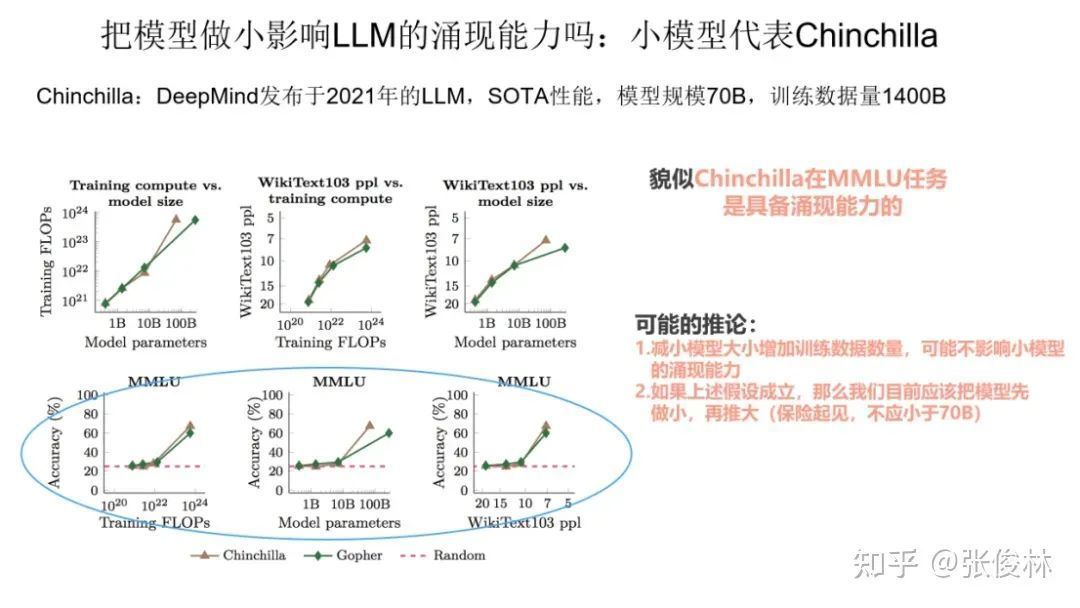 The first small model representative is Chinchilla, a model published by DeepMind in 2021. The effect of this model on various tasks is basically the same as that of PaLM with a size of 540B. Chinchilla’s idea is to give more data, but make the model smaller. Specifically, it targets the Gopher model. The size of the Chinchilla model is only 70B, which is a quarter of Gopher, but the price paid is the total amount of training data, which is four times that of Gopher. Therefore, the basic idea is to enlarge the amount of training data. , to reduce the model size.
The first small model representative is Chinchilla, a model published by DeepMind in 2021. The effect of this model on various tasks is basically the same as that of PaLM with a size of 540B. Chinchilla’s idea is to give more data, but make the model smaller. Specifically, it targets the Gopher model. The size of the Chinchilla model is only 70B, which is a quarter of Gopher, but the price paid is the total amount of training data, which is four times that of Gopher. Therefore, the basic idea is to enlarge the amount of training data. , to reduce the model size.
We have made Chinchilla smaller. The question is, does it still have the ability to emerge? As can be seen from the data given in the above figure, at least we can say that Chinchilla has emergent capabilities on the comprehensive task MMLU of natural language processing. If the small model can also have the ability to emerge, then this actually reflects a problem: for a model like GPT3, it is likely that its 175B model parameters have not been fully utilized, so we will train the model in the future When it comes to time, you can consider increasing the training data first, reducing the amount of model parameters, making the model smaller, and making full use of the model parameters first. On this basis, continue to increase the data and increase the model size. That is to say, at present, it seems feasible for us to make the model smaller first, and then make the model larger.
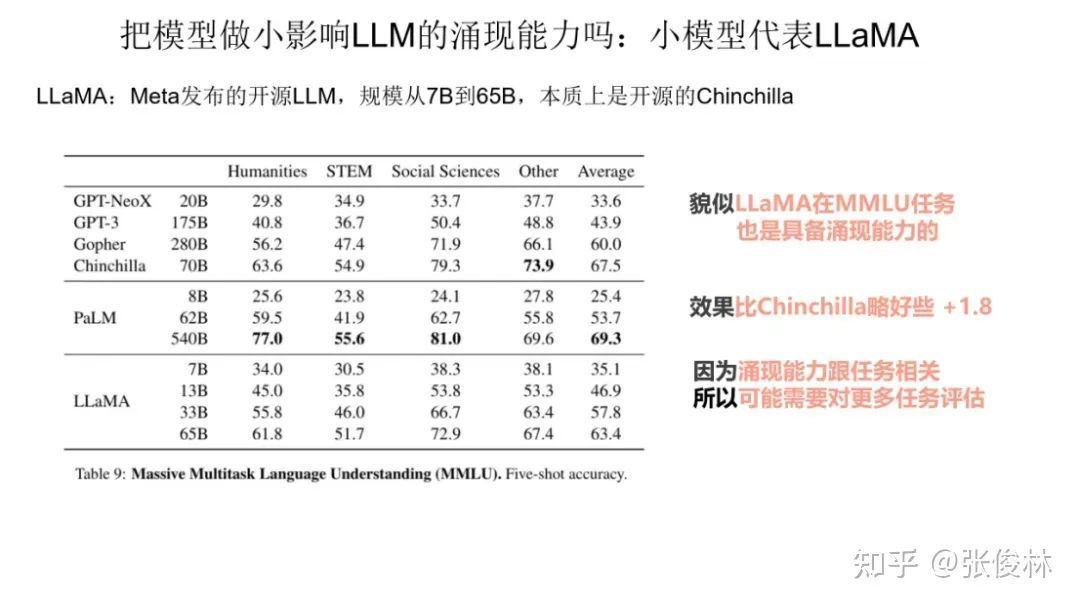 The second small model represents the open source model LLaMA released by Meta. Its approach is actually very easy to understand. It is essentially the open source Chinchilla. Its idea is to completely follow Chinchilla, that is to say, increase the training data, but reduce the model size. make small. So does LLaMA have emergent capabilities? As can be seen from the table data in the above figure, although LLaMA is slightly worse than Chinchilla on the task of MMLU, the effect is also good. This shows that LLaMA basically has the ability to emerge on MMLU.
The second small model represents the open source model LLaMA released by Meta. Its approach is actually very easy to understand. It is essentially the open source Chinchilla. Its idea is to completely follow Chinchilla, that is to say, increase the training data, but reduce the model size. make small. So does LLaMA have emergent capabilities? As can be seen from the table data in the above figure, although LLaMA is slightly worse than Chinchilla on the task of MMLU, the effect is also good. This shows that LLaMA basically has the ability to emerge on MMLU.
In fact, there is a work that has not been done yet, but this work is very valuable. It is to fully test whether the emergent ability of various tasks is still available when the model becomes small enough (such as 10B-50B scale)? This is a very valuable thing, because if our conclusion is that even if the scale of the model is made small, the emergent ability of various tasks can be maintained, then we can safely pursue the small model first.
5. Epiphany phenomenon in model training
Here is a relatively new research direction, epiphany phenomenon, which is called “Grokking” in English. The epiphany in the model training process is introduced here in order to establish the connection between it and the emergent ability of large models. Later in this article, I will try to explain the emergent ability of large models with the phenomenon of epiphany.
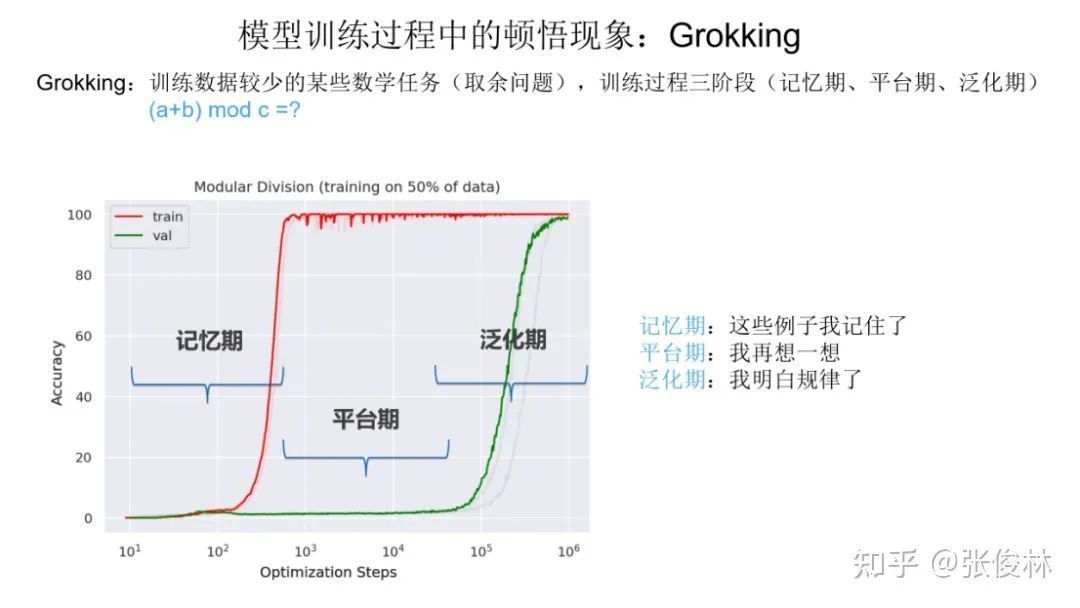
Let’s first explain what the epiphany phenomenon is. As shown in the figure above, for a mathematical task with less training data (usually the problem of summing numbers and taking the remainder), the researchers discovered a novel phenomenon. For example, we cut the data set into two pieces, 50% of the data is used as the training set (the red line in the figure shows the change of task indicators as the training process progresses), and 50% of the data is used as the verification set (the green line in the figure The trend shows the training dynamics). When learning the task of summing numbers and taking remainders, its training dynamics go through three phases:
- The first stage is the memory period: the training data index corresponding to the red line suddenly rises, indicating that the model has memorized 50% of the training data results, while the verification set index corresponding to the green line is close to 0, indicating that the model has no generalization ability at all, that is Said that he did not learn the rules of this task. So the model at this stage is simply memorizing the training data.
- The second stage is the platform stage: this stage is the continuation of the memory stage, which is reflected in the fact that the effect of the verification set is still very poor, indicating that the model still has not learned the law.
- The third stage is the generalization stage: at this stage, the effect of the verification set suddenly becomes better, which means that suddenly, the model has learned the rules in the task, that is, what we call, the epiphany phenomenon occurs, and it suddenly understands.
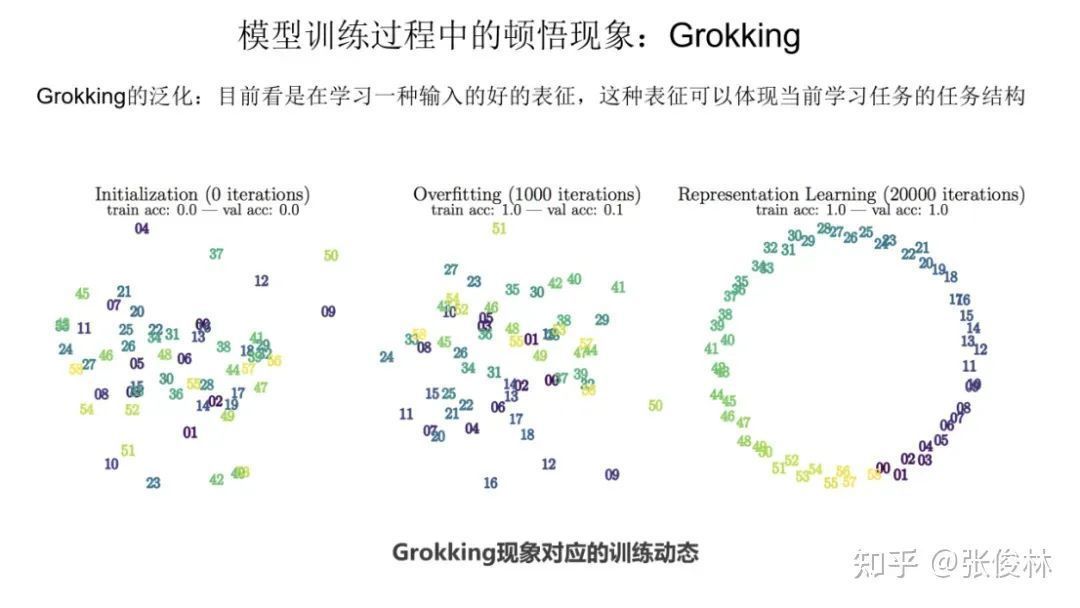 Follow-up studies have shown that Grokking is essentially learning a good representation of the input number. As shown in the figure, we can see the process from initialization to memory period to epiphany phenomenon, and the representation of numbers gradually begins to reflect the task structure of the current learning task.
Follow-up studies have shown that Grokking is essentially learning a good representation of the input number. As shown in the figure, we can see the process from initialization to memory period to epiphany phenomenon, and the representation of numbers gradually begins to reflect the task structure of the current learning task. 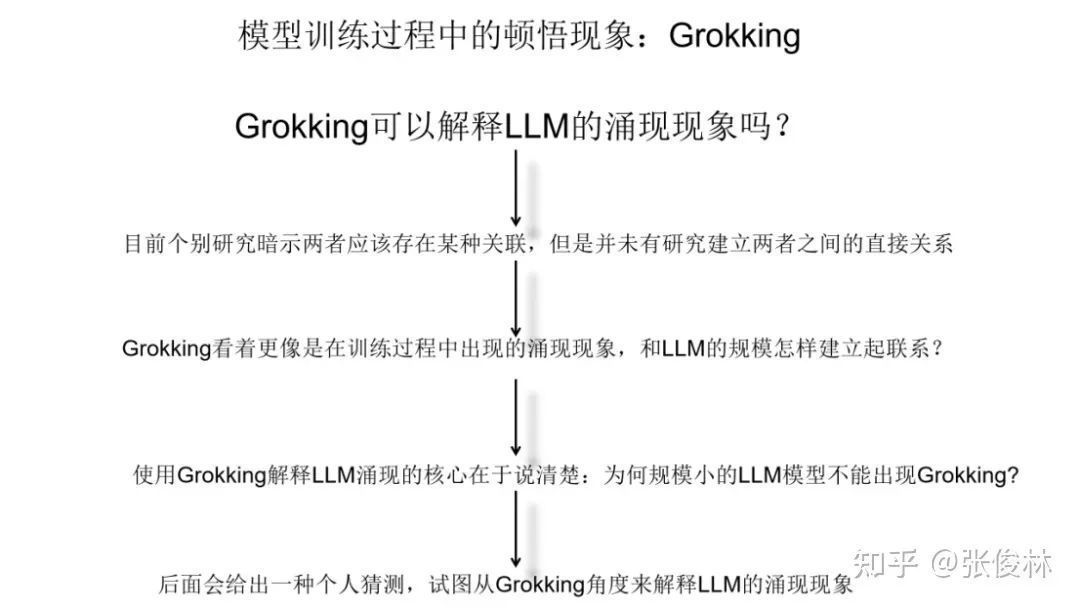 So, can we use Grokking to explain the emergence of large models? At present, some studies suggest that there is actually some connection between the two, but no research has clearly pointed out the relationship between the two. The two are very close from the trend curve, but there is a big difference, because Grokking describes the performance in the model training dynamics, while the emergence expresses the task performance when the model scale changes. Although the trend is similar, the two are not one thing. In my opinion, in order to use Grokking to explain the emerging phenomenon, the core is to explain the following questions clearly: Why does Grokking not appear in small-scale language models? This is a very critical question. Because if Grokking appears in both small-scale and large-scale language models, it means that Grokking has nothing to do with the model size, and it is impossible to explain the emergence of large models. Later in this article, I will give a conjecture of my own to establish the connection between the two.
So, can we use Grokking to explain the emergence of large models? At present, some studies suggest that there is actually some connection between the two, but no research has clearly pointed out the relationship between the two. The two are very close from the trend curve, but there is a big difference, because Grokking describes the performance in the model training dynamics, while the emergence expresses the task performance when the model scale changes. Although the trend is similar, the two are not one thing. In my opinion, in order to use Grokking to explain the emerging phenomenon, the core is to explain the following questions clearly: Why does Grokking not appear in small-scale language models? This is a very critical question. Because if Grokking appears in both small-scale and large-scale language models, it means that Grokking has nothing to do with the model size, and it is impossible to explain the emergence of large models. Later in this article, I will give a conjecture of my own to establish the connection between the two.
This article is reproduced from: https://www.52nlp.cn/%E6%96%B0%E6%B5%AA%E5%BC%A0%E4%BF%8A%E6%9E%97%EF%BC%9A% E5%A4%A7%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E7%9A%84%E6%B6%8C%E7%8E%B0%E8% 83%BD%E5%8A%9B-%E7%8E%B0%E8%B1%A1%E4%B8%8E%E8%A7%A3
This site is only for collection, and the copyright belongs to the original author.