Original link: https://wsgzao.github.io/post/sre/
foreword
I have shared DevOps before, but I have always forgotten to supplement SRE-related information. In fact, there is not much difference between the two, both are operation and maintenance.
- Divided by operation and maintenance stage
- Human flesh operation and maintenance -> script operation and maintenance -> platform operation and maintenance -> intelligent operation and maintenance
- Divided by technology stack
- Physical machine heap hardware -> x86 virtualization -> private cloud + public cloud -> cloud native
This article mainly records some SRE backgrounds and learning interview materials, so that they can be linked together when needed.
update history
August 13, 2022 – first draft
Read the original article – https://wsgzao.github.io/post/sre/
Introduction to SREs
SRE is literally a position defined by Google Technical VP Ben Treynor Sloss . The full name is Site Reliability Engineering, which translates to website reliability engineer (engineer). However, in my opinion, he is not just a job, but a service guarantee system.
Why have an SRE?
Why does the position of SRE appear? This starts with the famous DevOps , which is a theoretical system proposed by Google Senior R&D Director Melody Meckfessel in 2017. This system is to efficiently integrate various roles in the R&D process by building a series of DevOps toolchains and standards. Together, efficient output and stable delivery results. This system breaks the boundary between R&D and O&M, combining the goals of R&D to build more features and O&M to not introduce too much instability.
DevOps solves the process of efficiently producing stable services, further shortening the production iteration cycle of services. However, with the construction of various services, more and more services are continuously evolving, but the work of operation and maintenance services is also increasing, and the online unstable state is also increasing. So how to solve this problem? Is it up to the developers to keep an eye on their services? How can the stability of the overall structure be guaranteed?
Hence the SRE. The responsibility of the SRE is to be responsible for the stability of the overall site (service). However, to ensure stability, it must not be to solve the problem when a problem occurs, but to observe and avoid the problem in a systematic way. This is the SRE system as I understand it.
https://sre.google/
https://www.googblogs.com/sre-vs-devops-competing-standards-or-close-friends/
https://sre.google/sre-book/table-of-contents/
https://linkedin.github.io/school-of-sre/
DevOps Roadmap
About DevOps Roadmap has been shared before, keep a lifelong learning attitude
https://roadmap.sh/
https://roadmap.sh/devops
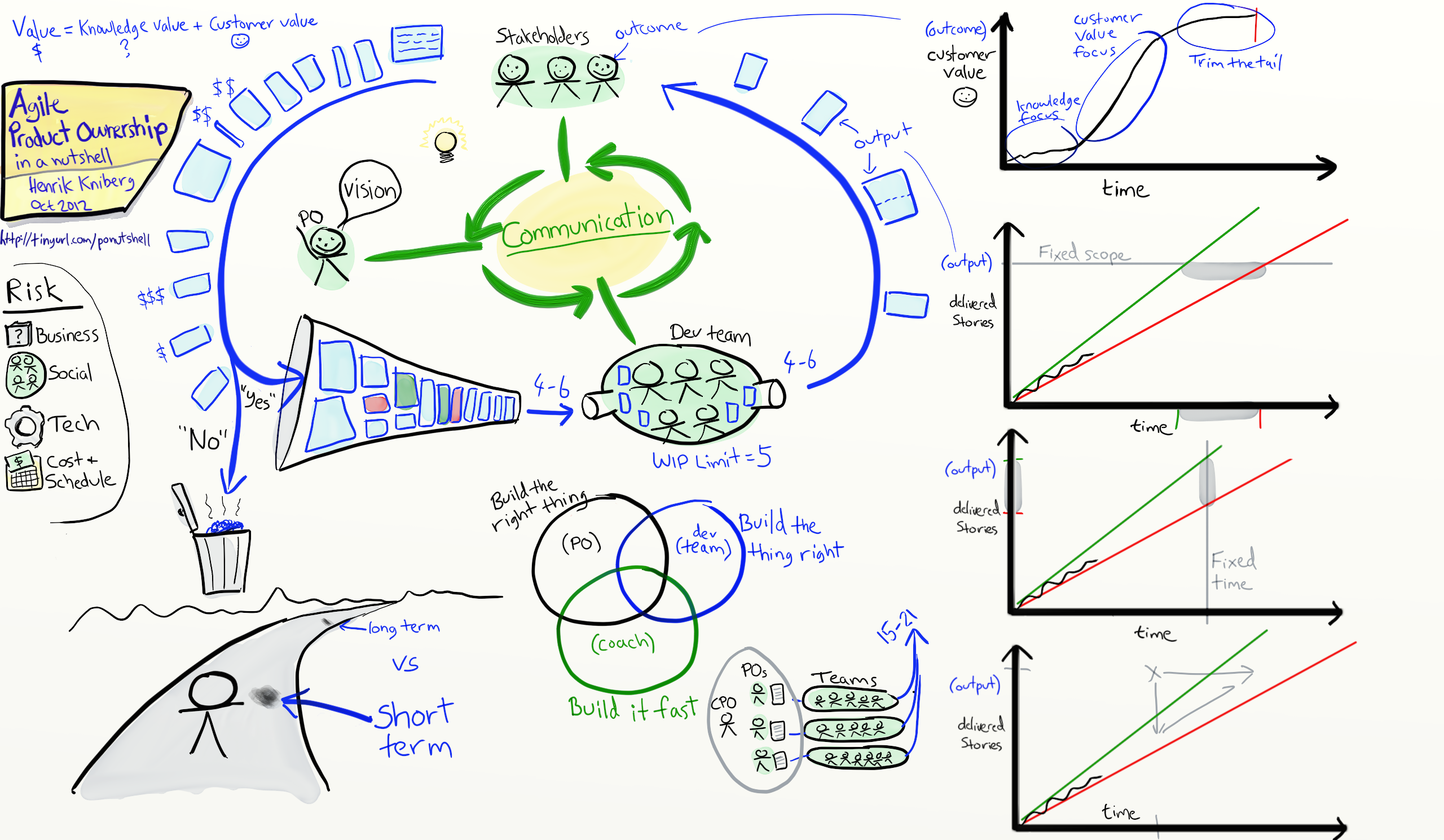
Agile and Scrum
Agile Product Ownership in a nutshell
https://blog.crisp.se/2012/10/25/henrikkniberg/agile-product-ownership-in-a-nutshell
Introduction to Scrum – 7 Minutes
https://www.youtube.com/watch?v=9TycLR0TqFA
Phoenix Project – The Phoenix Project
https://m.douban.com/book/subject/26644070/

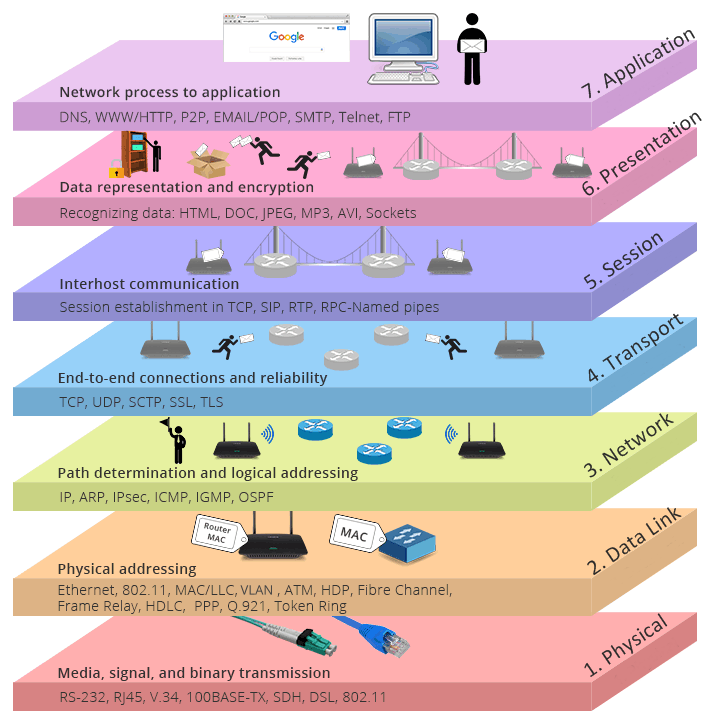
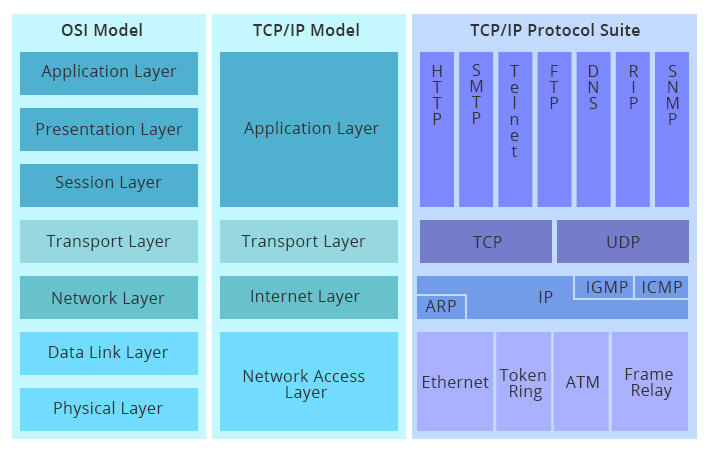
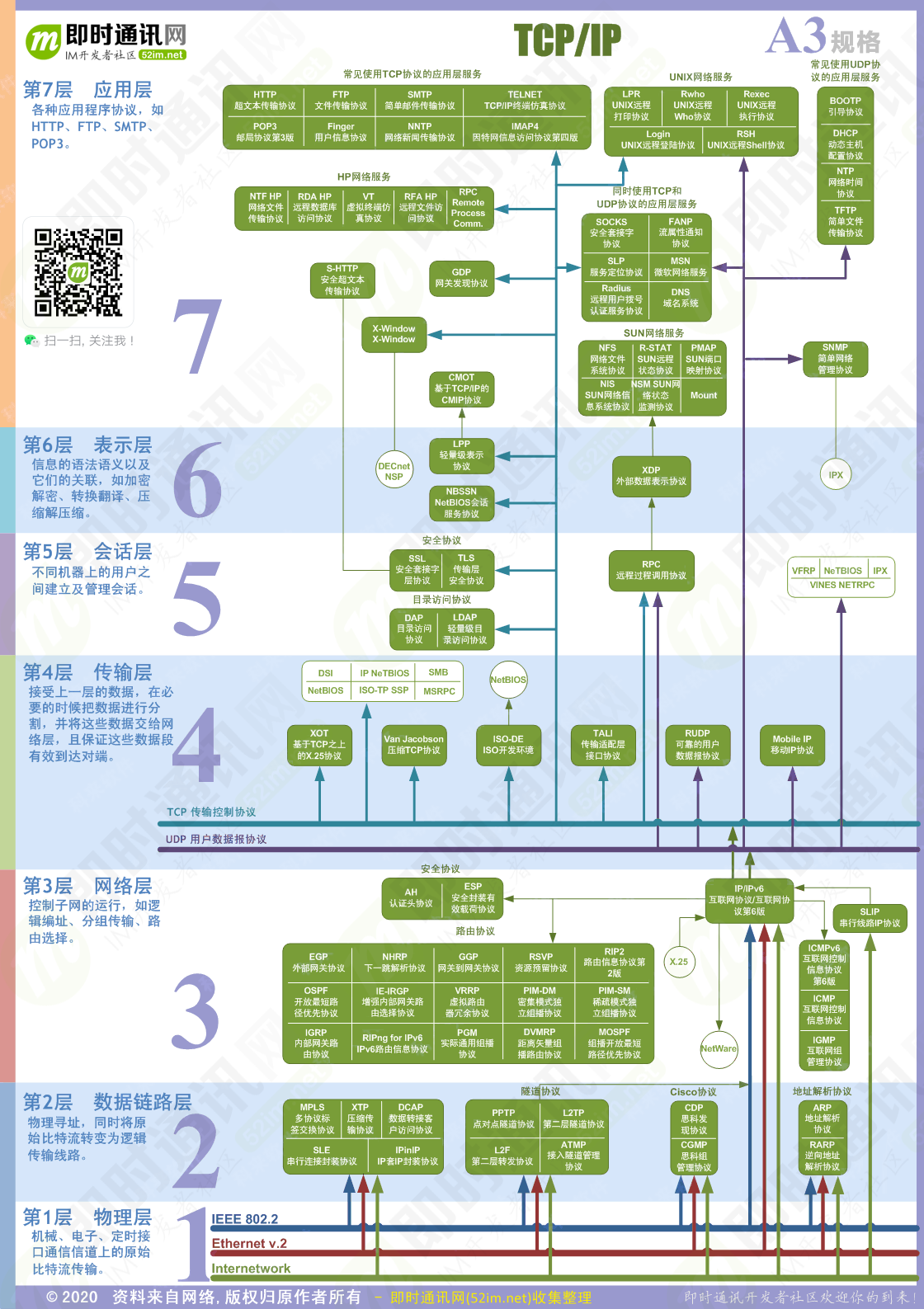
Network TCP/IP and OSI
https://community.fs.com/blog/tcpip-vs-osi-whats-the-difference-between-the-two-models.html
http://www.52im.net/thread-180-1-1.html
https://zqlxtt.cn/2020/09/23/tcpip-overview/
System Design
The System Design Primer
https://github.com/donnemartin/system-design-primer

What happens when you type google.com into your browser’s address box and press enter?
https://github.com/alex/what-happens-when
https://4ark.me/post/b6c7c0a2.html
Coding
LeetCode
https://leetcode.com/
https://leetcode.com/discuss/interview-question
LeetCode solutions in any programming language | Implementation of LeetCode in multiple programming languages, “The Sword Offer (2nd Edition)”, “Programmer Interview Golden Code (6th Edition)” problem solutions
https://leetcode.cn/
https://github.com/doocs/leetcode
labuladong algorithm cheat sheet
https://github.com/labuladong/fucking-algorithm
Code Caprice
https://www.programmercarl.com/
Xiaohao algorithm
https://github.com/geekxh/hello-algorithm
Eight-legged essay
What is eight-legged text? Baguwen is not a dead thing. Baguwen should refer to basic computer knowledge. It tests the basic ability, breadth and depth of the interviewee. The interviews of large factories do not pay much attention to dead Bagu, and are often very flexible analysis.
Computer Network Common Knowledge Points & Interview Questions
https://javaguide.cn/cs-basics/network/other-network-questions.html
Summary of common operating system interview questions
https://javaguide.cn/cs-basics/operating-system/operating-system-basic-questions-01.html
Summary of Linux Basics
https://javaguide.cn/cs-basics/operating-system/linux-intro.html
Rank and Salary Range Evaluation
This article is reprinted from: https://wsgzao.github.io/post/sre/
This site is for inclusion only, and the copyright belongs to the original author.