Original link: https://innei.in/posts/programming/nextjs-rsc-ssr-data-hydration-persistence
This rendering is generated by marked, and there may be typography problems. For the best experience, please go to: https://innei.in/posts/programming/nextjs-rsc-ssr-data-hydration-persistence
Because recently after rewriting my personal site and trying the new RSC architecture of NextJS, I also stepped on a lot of pitfalls. I intend to use this article to record some practice.
In the SSR architecture, if the requested data is on the server side, when transferring to the CSR rendering and relying on the SSR data, it must be ensured that the data obtained in the CSR is consistent with the server side. Only in this way can the rendering of both ends be consistent and hydrated. Success, otherwise there will be an error of Hydration failed because the initial UI does not match what was rendered on the server. Although this error will not cause the page to crash, and there will be no obvious LCP reduction after use, but in the development process It’s very bad, there will be a lot of NextJS red pop-up windows, and Sentry bombing in the production environment (if Sentry is connected). The picture below is the bad experience of kami now. Because it can’t be changed, so I have the idea of rewriting.
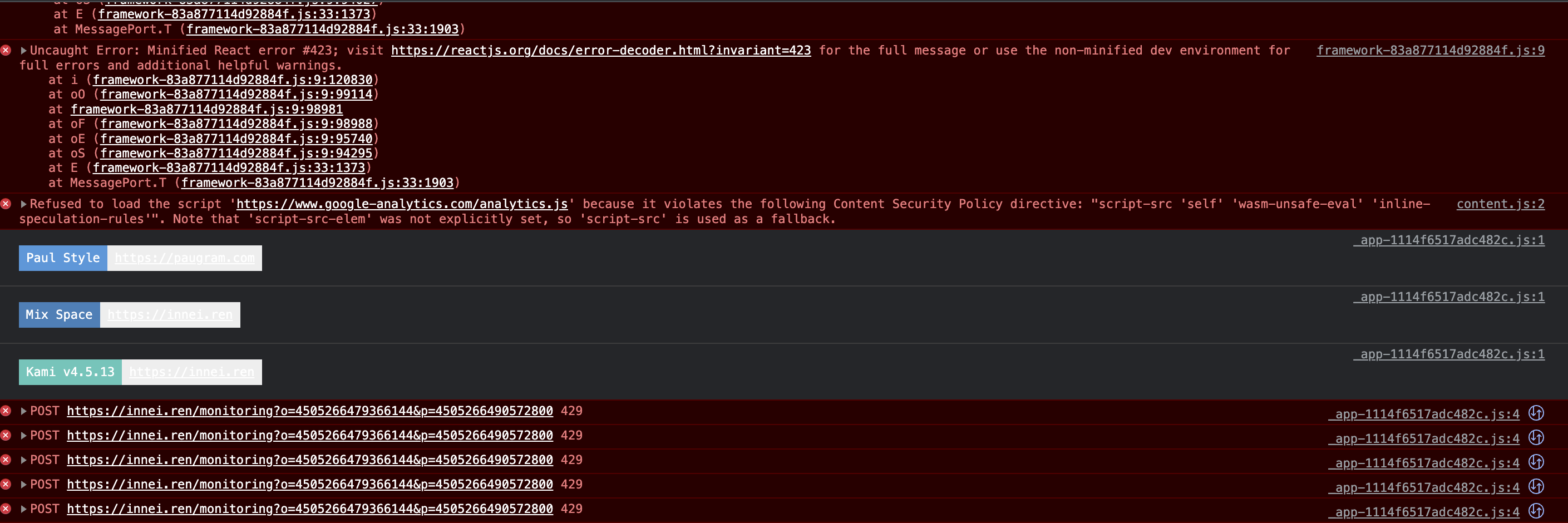
Sentry reports that the interface 429 is limited
In the RSC architecture, it is also based on SSR, but now the routing is completely taken over by the Server, so the router in the original NextJS is completely replaced. At the beginning of route rendering, from the top-level component down, it is rendered by the server and then returned to the client. In theory, if the component of use client is not encountered, the browser does not need to render. In most projects, the business cannot be so simple, for example, my data will change with the push of server-side events.
One thing to note is that you must ensure that the data is consistent when the browser is hydrated. If you can’t do it, you can only give up the SSR rendering of the component. The most conventional way, but he can’t do much more.
// app/pageImpl.tsx 'use client' export default (props: { data: PageData }) => { // ... } // app/page.tsx import PageImpl from './pageImpl' export default async () => { const data = await fetch('...') return <PageImpl data={data} /> }
The above is the data transmission method I first tried. With this method, there is no problem at all, as long as the transmitted data can be serialized by JSON.
But using the above method, the data passed through props is immutable, and the components of the page are driven by this data. To change this data according to various subsequent events, state management needs to be introduced.
Back to the already rotten kami, how is it done. After the data required by the page is requested, the server renders the page according to the obtained data and returns the HTML to the browser. The first frame rendered by the browser is the complete state of the page, but the page is not in the interactive state at this time, until JS After loading, React starts to intervene in hydration, but because the data of the page is not passed according to props, but is extracted from the store, the store has not completed the hydration at this time, so the first frame after hydration enters the loading state of the page without data, resulting in React reports a Hydration Error and turns to Client Render.
The Zustand used before doesn’t seem to provide a good solution. This time I plan to use Jotai to complete this part of the migration. Our page data is still driven by the Store, rather than transparently transmitted through props.
React Query scheme
I tried React Query as a medium. React Query naturally provides Hydrate components, which can solve this problem to a certain extent, but if React Query is used as data management, it will not be possible to control the granularity of each component. The select ability of React Query is not very flexible, and in some attempts, it was found that the use of select in time cannot be granularly updated to each component.
Is it really easy?
If you use the React Query solution, simple scenarios only need to do the following.
Create ReactQueryProvider and Hydrate components, which are two client components.
// app/provider.tsx 'use client' import { QueryClient, QueryClientProvider } from '@tanstack/react-query' import { PropsWithChildren } from 'react' export const queryClient = new QueryClient({ defaultOptions: { queries: { staleTime: 1000 * 60 * 5, // 5 minutes refetchInterval: 1000 * 60 * 5, // 5 minutes refetchOnWindowFocus: false, refetchIntervalInBackground: false, }, }, }) export const ReactQueryProvider = ({ children }: PropsWithChildren) => { return ( <QueryClientProvider client={queryClient}>{children}</QueryClientProvider> ) }
// app/hydrate.tsx 'use client' import { Hydrate as RQHydrate } from '@tanstack/react-query' import type { HydrateProps } from '@tanstack/react-query' export function Hydrate(props: HydrateProps) { return <RQHydrate {...props} /> }
Then import it in layout.tsx .
import { QueryClient, dehydrate } from '@tanstack/react-query' import { Hydrate } from './hydrate' import { ReactQueryProvider } from './provider' import { QueryKeys } from './query-key' import { sleep } from '@/utiils' const queryClient = new QueryClient({ defaultOptions: { queries: { cacheTime: 1000, staleTime: 1000, }, }, }) export default async function RootLayout({ children, }: { children: React.ReactNode }) { await queryClient.fetchQuery({ queryKey: [QueryKeys.ROOT], queryFn: async () => { await sleep(1000) const random = Math.random() console.log(random) return random }, }) const state = dehydrate(queryClient, { shouldDehydrateQuery: (query) => { if (query.state.error) return false if (!query.meta) return true const { shouldHydration, skipHydration, } = query.meta if (skipHydration) return false return (shouldHydration as Function)?.(query.state.data as any) ?? false }, }) return ( <ReactQueryProvider> <Hydrate state={state}> <html lang="en"> <body>{children}</body> </html> </Hydrate> </ReactQueryProvider> ) }
Note here that you must also create a QueryClient on the Server side. The QueryClient is dedicated to the Server Component, but the Client Component is not the same, and the Server Side is used for Hydrate. So in layout.tsx we created a QueryClient for Server Side Only. We defined a Query fetch in RootLayout, simulated the acquisition of a random data, and waited for the asynchronous request to complete before entering the Dehydrate phase. Please note that cacheTime set above will be mentioned later. Next, verify that Hydrate is in effect. If Hydrate Error does not appear this indicates that there is no problem.
Create page.tsx and turn it into Client Component.
'use client' import { useQuery } from '@tanstack/react-query' import { QueryKeys } from './query-key' export default function Home() { const { data } = useQuery({ queryKey: [QueryKeys.ROOT], queryFn: async () => { return 0 }, enabled: false, }) return
Hydrate Number: {data}
}
Here we disable the automatic refetch feature of Query to ensure that the data will not be refreshed. In this example, as long as the page does not display 0, it is OK.
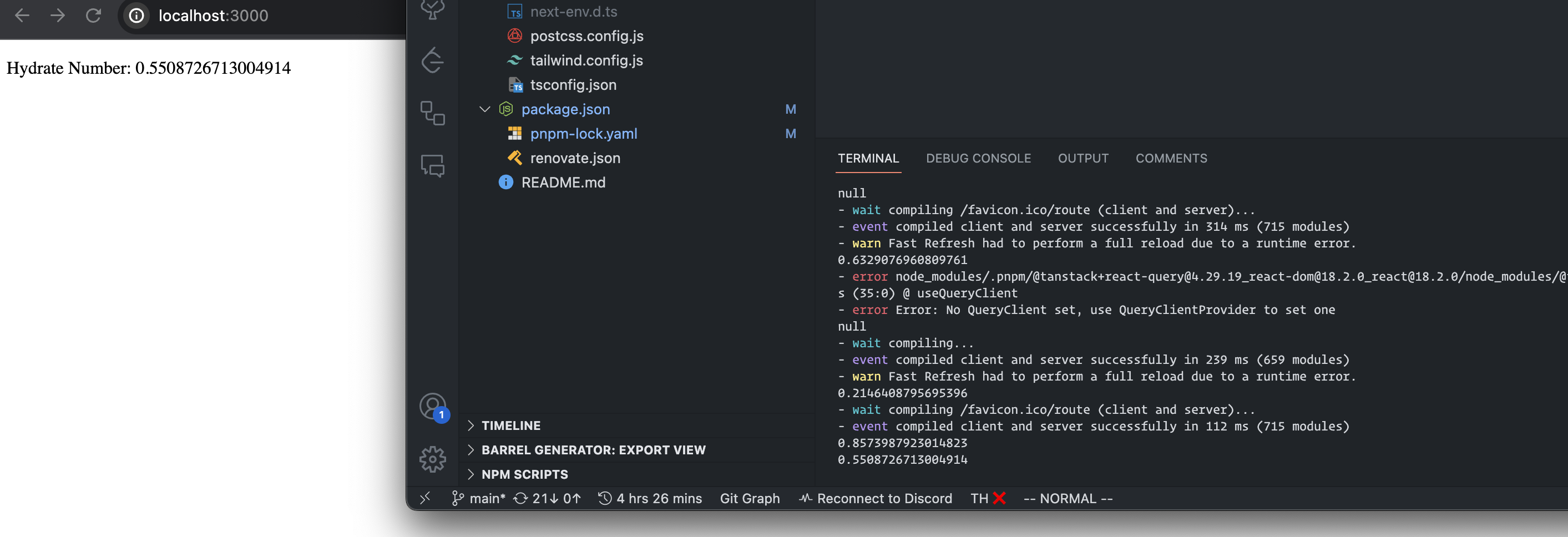
We see that the random number is the same as that printed by the Server, and there is no Hydrate error reported by the browser.
data cache
As mentioned earlier, we set cacheTime in the QueryClient of ServerSide Only. This parameter is not the data cache time you think, but the existence time of the Query instance. In React Query, all queries are hosted in QueryCache, as long as this Time Query will be destroyed. In useQuery in React Hook, Query hangs in the component for a long time and does not need to perceive this value, and the data manually fetched in QueryClient will also generate Query instances, so in ServerSide, you must first hit a data multiple times Remember not to set too short time for the same Query, the default value is 5 minutes.
Let’s take an example. I set the QueryClient cacheTime of ServerSide to 10 milliseconds. When the queryClient fetches data, an asynchronous task is inserted, which causes the Query instance to be destroyed when the dehydrate is not reached.
const queryClient = new QueryClient({ defaultOptions: { queries: { cacheTime: 10, // 设置10ms,也许是为了不要让Server 长期命中API 缓存保证数据最新。 }, }, }) export default async function RootLayout({ children, }: { children: React.ReactNode }) { await queryClient.fetchQuery({ queryKey: [QueryKeys.ROOT], queryFn: async () => { await sleep(1000) const random = Math.random() console.log(random) return random }, }) await sleep(10) // 模拟异步任务跳出,超过10ms const state = dehydrate(queryClient, { shouldDehydrateQuery: (query) => { if (query.state.error) return false if (!query.meta) return true const { shouldHydration, skipHydration, } = query.meta if (skipHydration) return false return (shouldHydration as Function)?.(query.state.data as any) ?? false }, }) return ( <ReactQueryProvider> <Hydrate state={state}> <html lang="en"> <body>{children}</body> </html> </Hydrate> </ReactQueryProvider> ) }
At this time, look at the browser page again. There is no data.
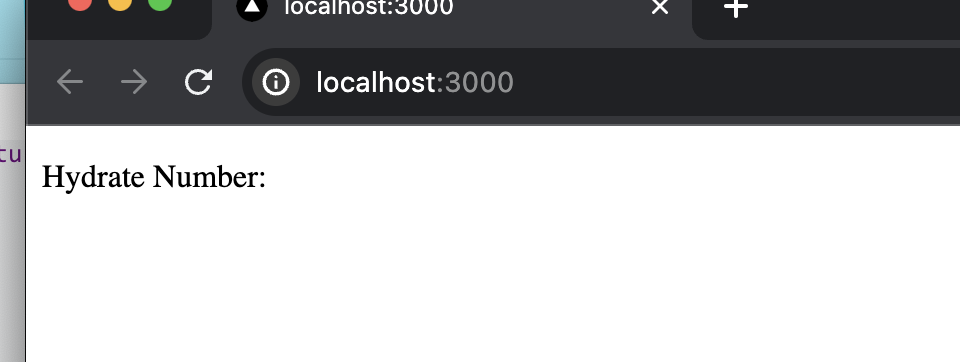
It is conceivable that it is still a little difficult to use React Query and not want the Server to cache the API in itself.
potential data breach
If you are not running this Next.js in Serverless Mode, since there is only one QueryClient on the server side, but there are many users visiting your site, and they visit different sites, QueryClient will cache different request data.
When user A visits the site, it may contain the hydration data of the content visited by user B.
For example, write a Demo. We annotate cacheTime of ServerSide and return it to the default 5 minutes.
Create A and B pages.
// app/A/layout.tsx import { queryClient } from '../queryClient.server' export default async () => { await queryClient.fetchQuery({ queryKey: ['A'], queryFn: async () => { return 'This is A' }, }) return null } // app/A/page.tsx export default () => { return null }
B In the same way, change all the above A to B.
Visit /A and /B . Refresh the page to view /A HTML source code.
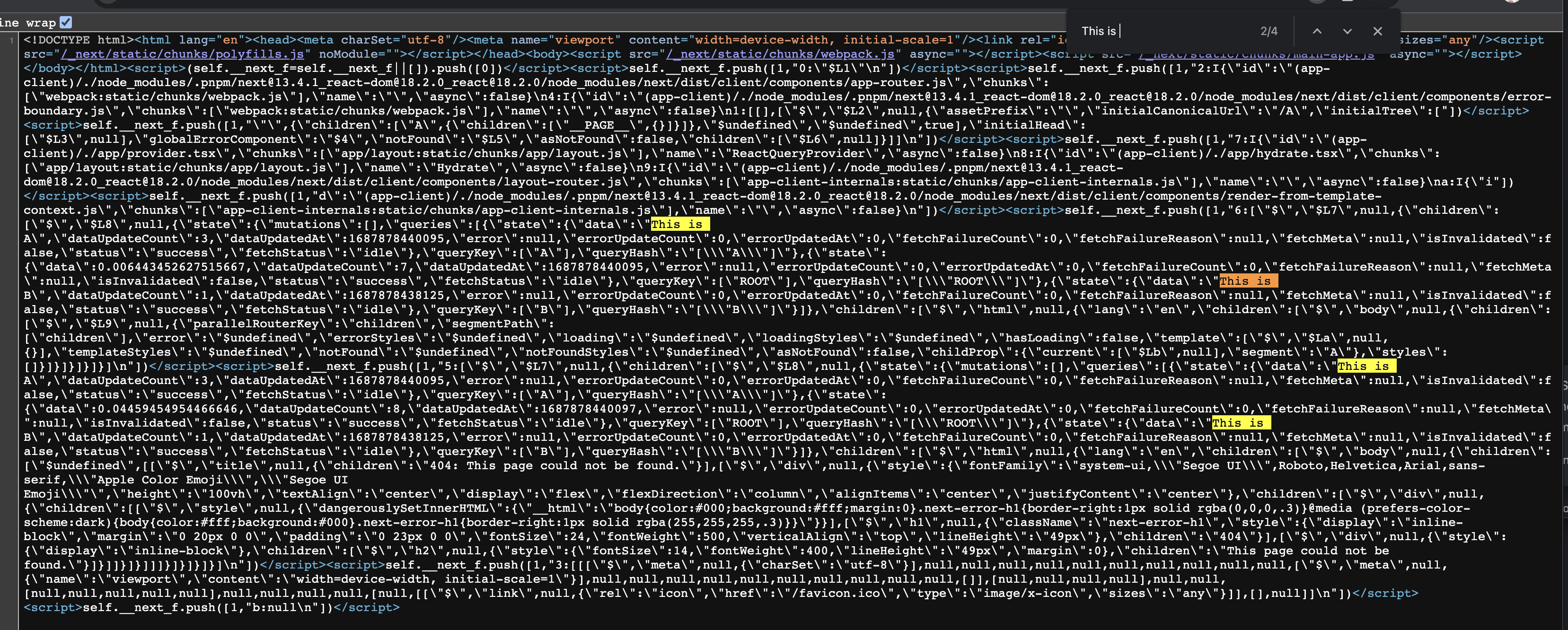
We can see that accessing /A carries the data of /B .
When the number of visits increases, the hydration data will become very large, which we do not want to see. And if you forward the cookie to the server, visitors may see something they shouldn’t see.
How to avoid it, my solution is to judge based on meta. In the definition of query, you can customize a meta key value to indicate whether the query needs to be hydrated. Then only hydrate the data of the current route according to the current route. Forcibly skip hydrate for sensitive content (authenticated and partially viewable).
const dehydratedState = dehydrate(queryClient, { shouldDehydrateQuery: (query) => { if (query.state.error) return false if (!query.meta) return true const { shouldHydration, hydrationRoutePath, skipHydration, forceHydration, } = query.meta if (forceHydration) return true if (hydrationRoutePath) { const pathname = headers().get(REQUEST_PATHNAME) if (pathname === query.meta?.hydrationRoutePath) { if (!shouldHydration) return true return (shouldHydration as Function)(query.state.data as any) } } if (skipHydration) return false return (shouldHydration as Function)?.(query.state.data as any) ?? false }, })
Just modify the dehydrateState. I used shouldHydration hydrationRoutePath skipHydration forceHydration to control the hydrate state.
Reference usage method:
defineQuery({ queryKey: ['note', nid], meta: { hydrationRoutePath: routeBuilder(Routes.Note, { id: nid }), shouldHydration: (data: NoteWrappedPayload) => { const note = data?.data const isSecret = note?.secret ? dayjs(note?.secret).isAfter(new Date()) : false return !isSecret }, }, queryFn: async ({ queryKey }) => { const [, id] = queryKey if (id === LATEST_KEY) { return (await apiClient.note.getLatest()).$serialized } const data = await apiClient.note.getNoteById(+queryKey[1], password!) return { ...data } }, })Seeing this, you may say, do you need to be so troublesome? Re-creating a new QueryClient instance inside the RootLayout component can ensure that the data of each request will not be polluted. Indeed, the solution mentioned in the React Query document is the same, but this is only applicable in the traditional SSR architecture, and it also has many limitations. For example, if this method is not used, QueryClient will not be called by other Layouts, such as sub-Layouts The Data fetching in must create a new QueryClient, and then use the Hydrate component to wrap it again, which will have a lot of extra overhead.
cache (next.js has implemented this method) method provided in React 18.3 may be able to solve this problem. Using cache(() => new QueryClient()) package makes it always hit the same QueryClient in this React DOM rendering. Although such a solution solves cross-request state pollution, it cannot enjoy the dedupe bonus brought by a single instance in high concurrency, and the overload caused by sending too many requests in an instant also needs to be considered.
I won’t go into too much detail here.
In short, there are still too many issues to consider in React Query, which increases the complexity, prompting me to turn to other solutions.
Jotai
I’m tired of writing. Let’s listen to the next chapter.
finish watching? say something
This article is transferred from: https://innei.in/posts/programming/nextjs-rsc-ssr-data-hydration-persistence
This site is only for collection, and the copyright belongs to the original author.