Editor’s note: In recent years, non-autoregressive generation has shown its unique advantages in natural language processing, speech processing and other fields due to its parallel and rapid reasoning ability, and has increasingly become a research hotspot of generative models. In order to promote the development of non-autoregressive generative models, Microsoft Research Asia and researchers from Soochow University co-authored a review paper “A Survey on Non-Autoregressive Generation for Neural Machine Translation and Beyond”, which reviewed the use of non-autoregressive generation in neural machines. Translations, as well as developments in other tasks, and an outlook for the future of non-autoregressive generation.
In natural language and speech generation tasks such as machine translation, dialogue generation, speech synthesis, etc., auto-regressive (AR) generation is one of the most commonly used generation methods. Simply put, AR generation refers to generating a sentence of speech or text in turn in an iterative loop. For example, to generate a sentence of length 5, AR generation will first generate the first word, then generate the second word based on the first word, then generate the third word based on the first two words, and so on. Since each new word generation depends on the previously generated words, the autoregressive generation method can ensure the accuracy of the generation.
But obviously, the generation efficiency of such a loop is very inefficient, especially for generating long sentences. In order to speed up the generation process, non-autoregressive (NAR) generation is proposed, which greatly improves the generation efficiency by generating all the words in a sentence in parallel at one time. However, the accuracy of NAR generation is not guaranteed, and its performance still lags behind autoregressive generation. Therefore, how to balance the advantages and disadvantages of AR generation and NAR generation is the research focus of current generation tasks.
Overview overview
NAR generation was first proposed in neural machine translation (NMT), and since then NAR generation has attracted extensive attention in the fields of machine learning and natural language processing. As mentioned earlier, although NAR generation can significantly speed up inference generation for machine translation, the speedup is achieved at the expense of translation accuracy compared to AR generation. In recent years, in order to bridge the accuracy gap between NAR generation and AR generation, many new models and algorithms have been proposed.
In order to promote the development of NAR generation models, Microsoft Research Asia and researchers from Soochow University co-authored the review paper “A Survey on Non-Autoregressive Generation for Neural Machine Translation and Beyond” (click to read the original text to view the paper details).
In the article, the researchers present a systematic and comprehensive review. First, the researchers compared and discussed various non-autoregressive translation (NAT) models from different aspects, specifically several different categories of NAT work, including data manipulation. , modeling methods, training criteria, decoding ways, and benefit from pre-training. In addition, the researchers briefly summarize and review other applications of NAR generation beyond machine translation, such as dialogue generation, text summarization, grammatical error correction, semantic parsing, speech synthesis, and automatic speech recognition, among others. Finally, the researchers discuss potential future directions for NAR worth continuing exploration, including reducing the reliance on knowledge distillation (KD), dynamic decoding length prediction, pre-training for NAR generation, and broader applications. Figure 1 shows the overall structure of this review paper.
The researchers hope that this review article can help researchers better understand recent advances in NAR generation, inspire the design of more advanced NAR models and algorithms, and enable industry practitioners to select appropriate solutions according to their field.

Figure 1: Overview Architecture of Non-Autoregressive (NAR) Generation Research Overview
Key Challenges and Solutions for the NAT Model
The traditional autoregressive translation (AT) model is composed of an encoder and a decoder. The encoder encodes the source sentence and sends it to the decoder, and then the decoder uses the source sentence and the target language word predicted in the previous step. Predicting the next word, this word-by-word generation limits the decoding speed of the AT model. In order to achieve a parallel decoding method during training and inference, NAT only relies on the source sentence information to generate all target words, and abandons the conditional dependencies between target words. This approach greatly speeds up the decoding of the model, but also increases the difficulty of training the NAR model, making the model “difficult to model the conditional information between words in the target language”.
To address this challenge, existing work proposes a variety of solutions. The review article classifies existing work, and introduces and compares related methods from five perspectives: data, models, loss functions, decoding algorithms, and utilizing pre-trained models. Among them, data, model and loss function are the three basic components of the autoregressive text generation model. The work in this area aims to study the deficiencies of the traditional methods in the above three aspects in the NAR model and make corresponding improvements; the decoding algorithm And the use of pre-training models is a special module in the non-autoregressive text generation model that is different from AR generation, including target sentence length prediction, non-autoregressive pre-training, etc. The work in this area aims to design reasonable and effective algorithms to maximize the Improve the performance of NAR generative models. These connections are shown in Figure 2.
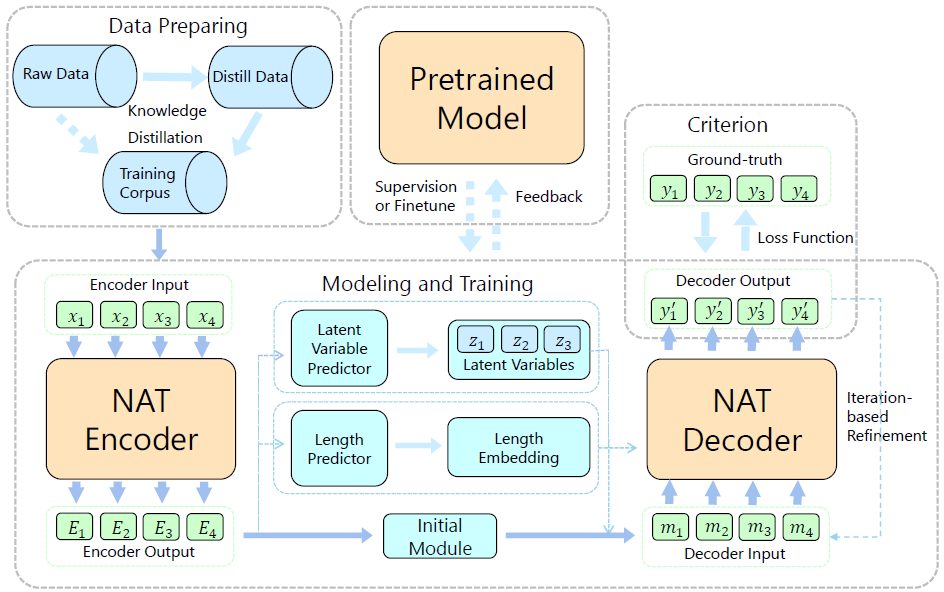
Figure 2: The main framework of a non-autoregressive machine translation model. It involves data processing, model improvement, training criteria, decoding methods, utilization of pre-trained models, etc.
Specifically, the improvements in the above five aspects are as follows:
1. Improvements at the data level, including the use of knowledge distillation to generate data, design data learning algorithms, etc. Using the pre-trained NAR model, the method based on knowledge distillation translates the source sentences in the training set, and uses the source sentences and translation results as the training set of the NAR model. This method can reduce the diversity of training data and ease the training difficulty of the NAR model. Note that data-level methods are general, eg, knowledge distillation-based methods are widely used in most of the NAR generative models introduced in this paper.
2. Improvements at the model level, including designing iterative models, latent variable-based models, and enhancing the decoder model structure, etc. Among them, the iterative model expands the original one-time decoding NAR model into a multiple iterative decoding model, so that in each round of iteration, the result of the previous round of iteration can be used as the dependency information of the target language side, and the difficulty of one decoding is apportioned to In multiple iterations, the effect of the NAR model is improved. Compared with the one-time decoding NAR model, the iterative model translation effect is better, but it also sacrifices part of the translation speed, which belongs to the intermediate state of the AR model and the NAR model.
3. Improvements at the loss function level, mainly aiming at the problem of the traditional cross-entropy loss function, a series of improvement methods are proposed, including the loss function based on CTC, n-gram, and the introduction of sequential information. Among them, since the traditional cross-entropy loss function can only provide word-level supervision information and cannot provide global information, the researchers proposed a loss function to optimize the Bag of N-gram difference between the prediction and the target. Supplement the missing global information in the cross-entropy loss function to better optimize the NAR model.
4. Improvements at the decoding algorithm level, including improvements to the length prediction module of the NAR model and improvements to traditional decoding algorithms. Since the NAR model cannot implicitly determine the length of the target sentence in the decoding process like the AR model, it needs to explicitly predict the length of the target sentence before the decoding process starts. This step is very important, because whether the length of the target sentence matches or not directly affects the final translation effect of the model. Therefore, similar to Beam Search in autoregressive decoding, some models have proposed methods to improve the accuracy of length prediction, such as parallel decoding of multiple lengths. These methods are also widely used in NAR models.
5. Methods using pre-trained models, including methods using autoregressive teacher translation models, and methods using monolingual large-scale pre-training language models. Among them, since the structure of NAR model and AR model is similar, and the translation accuracy of AR model is higher, many methods propose to use pre-trained AR model to additionally supervise the training of NAR model, including introducing additional supervision information at the latent variable level, and Transfer learning methods based on curriculum learning, etc.
The researchers listed the relevant papers discussed in the article in Table 1 by category for your reference.
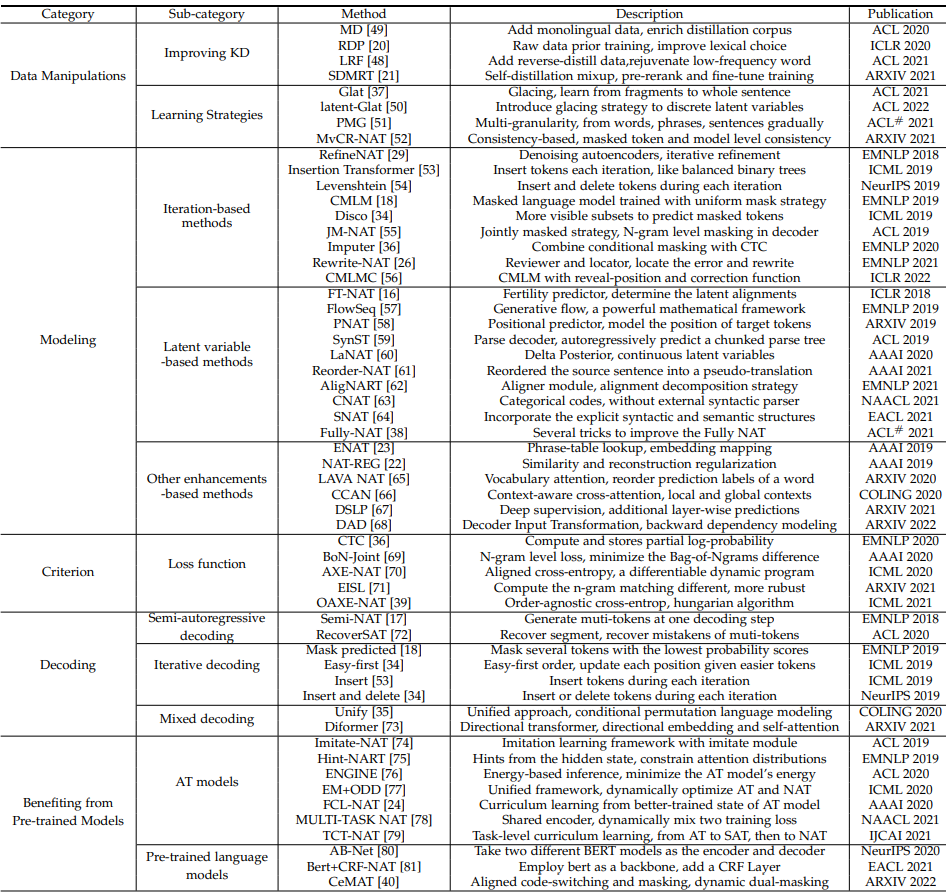
Table 1: Summary of research on 5 aspects of the NAT model and specific related work
Open questions and future directions for exploring NAR
In addition to its application in NMT, NAR has also been extended to many other tasks, including text generation tasks, such as text completion, summary generation, grammar correction, dialogue, style change, semantic parsing tasks, text Voice conversion tasks, voice translation tasks, and more. In the review article, the researchers present some specific examples, and also provide a list of implementations and resources for these related works.
In order to promote the development of NAR in the future, the researchers summarized the problems arising from the current NAR, and looked forward to possible future directions, including: (1) How to get rid of the technical solution that the current NAR relies heavily on AR for knowledge distillation; (2) How to reduce the computational complexity of the iterative NAR model to better focus on the pure NAR model; (3) Dynamically predict the generation length of the target text; (4) How to convert the NAR model like the AR model Extending to multilingual multitasking environments requires further attention; (5) how to better pre-train the NAR model. These are all research questions with promising research prospects.
It is hoped that through this review, scholars who conduct research on generative tasks in different fields can gain a more comprehensive understanding of NAR generation, and inspire the creation of more advanced NAR models to promote the future development of NAR and influence broader generation scenarios.
Related Links:
Paper: https://ift.tt/VljOzHw
GitHub: https://ift.tt/4fnrsTg
This article is reprinted from: https://www.msra.cn/zh-cn/news/features/a-survey-on-non-autoregressive-generation
This site is for inclusion only, and the copyright belongs to the original author.