Original link: https://www.msra.cn/zh-cn/news/features/beit-3
Editor’s note: In recent years, the research on foundation models (also known as pre-training models) has gradually tended to the big convergence from the technical level, and different fields of artificial intelligence (such as natural language processing, computer vision, speech The basic models of processing, multimodality, etc.) are technically dependent on three aspects: First, Transformers become a general neural network architecture and modeling method for different fields and problems, and second, generative pre-training becomes a The most important self-supervised learning method and training goal, the third is the scaling up of data and model parameters to further unleash the potential of the basic model.
The unification of technologies and models will gradually standardize and scale AI models, thus providing the basis and possibility for large-scale industrialization. Through cloud deployment and cloud collaboration, AI will likely truly become a “new infrastructure” like water and electricity, empowering all walks of life, and further spawning disruptive application scenarios and business models.
Recently, Microsoft Research Asia and the Microsoft Turing team launched the newly upgraded BEiT-3 pre-training model, which is used in a wide range of vision and vision-linguistic tasks, including object detection (COCO), instance segmentation (COCO), semantic segmentation ( ADE20K), image classification (ImageNet), visual reasoning (NLVR2), visual question answering (VQAv2), picture description generation (COCO), and cross-modal retrieval (Flickr30K, COCO), etc., to achieve the transfer performance of SOTA. The innovative design and outstanding performance of the BEiT-3 open up new ideas for multimodal research and herald the dawn of AI unification. (Click to read the original text to view the BEiT-3 paper)
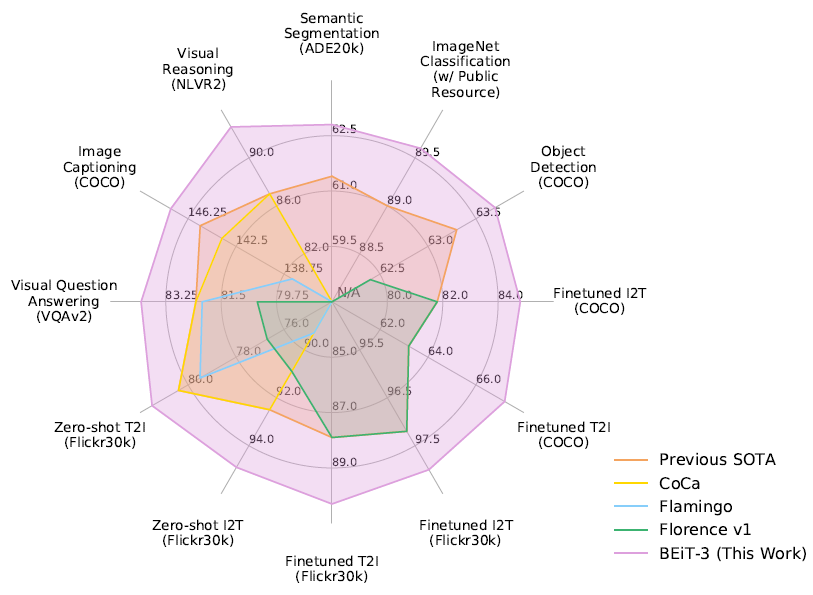
Figure 1: As of August 2022, BEiT-3 achieves SOTA transfer performance on a wide range of vision and vision-language tasks
In fact, in the early exploration of AI and deep learning algorithms, researchers focused on studying single-modal models and using single-modal data to train models. For example, natural language processing (NLP) models are trained on textual data, computer vision (CV) models are trained on image data, speech models are trained on audio data, and so on. However, in the real world, text, image, voice, video and other forms do not exist independently in many cases, but are integrated and presented in a more complex way. Therefore, in the exploration of artificial intelligence, cross-modality, multimodality It has also become the focus of industry research in recent years.
Large-scale pre-training is trending towards “uniformity”
“In recent years, pre-training in fields such as language, vision, and multimodality has begun to show a trend of big convergence. With large-scale pre-training on large amounts of data, we can more easily transfer models to a variety of downstream tasks. This model of pre-training a common base model to handle a variety of downstream tasks has attracted more and more researchers’ attention,” said Dong Li, lead researcher in the Natural Language Computing Group at Microsoft Research Asia. Microsoft Research Asia has seen that the trend of unification has gradually emerged in three aspects, namely backbone network (backbone), pre-training tasks and scale improvement.
First, the backbone network is gradually unified. The unification of the model architecture provides the basis for the unification of pre-training. Under the guidance of this idea, Microsoft Research Asia proposed a unified backbone network Multiway Transformer, which can encode multiple modalities at the same time. Furthermore, through the modular design, the unified architecture can be used for different vision and vision-linguistic downstream tasks. Inspired by UniLM (Unified Pre-trained Language Model), understanding and generation tasks can also be modeled uniformly.
Second, pre-training based on masked data modeling has been successfully applied to multiple modalities, such as text and images. The researchers at Microsoft Research Asia looked at images as a language and achieved the goal of processing both text and image modalities in the same way. Since then, image-text pairs can be used as “parallel sentences” to learn alignment between modalities. By normalizing the data, generative pre-training can also be used to uniformly perform large-scale representation learning. The superiority of generative pre-training is also demonstrated by BEiT-3 achieving state-of-the-art performance on vision, vision-language tasks.
Third, expanding the model size and data size can improve the generalization ability of the base model, thereby improving the downstream transfer ability of the model. Following this concept, researchers have gradually expanded the model scale to billions of parameters. For example, in the field of NLP, the Megatron-Turing NLG model has 530 billion parameters. These large models have achieved better performance in tasks such as language understanding and language generation. Good results; in the CV domain, Swin Transformer v2.0 has 3 billion parameters and sets new records on multiple benchmarks, proving the advantages of large-scale vision models in a wide range of vision tasks. In addition, Microsoft Research Asia proposed a way to treat images as a language, which can directly reuse the existing pre-training methods of large-scale language models, which is more conducive to the expansion of visual basic models.
BEiT: Microsoft Research Asia blazes new trails for vision-based megamodels
In model learning in the CV field, supervised pre-training is usually used, utilizing labeled data. However, with the continuous expansion of the visual model, the labeled data is difficult to meet the needs of the model. When the model reaches a certain scale, even if the model is expanded, it will not be able to obtain better results. This is the so-called data hunger. Therefore, researchers began to use unlabeled data for self-supervised learning to pre-train large model parameters. In the past, in the field of CV, self-supervised learning with unlabeled data often used contrastive learning. However, there is a problem with contrastive learning, which is that it relies too much on image interference operations. When the noise is too simple, the model cannot learn useful knowledge; when the image is changed too much, or even beyond recognition, the model cannot learn effectively. Therefore, it is difficult to grasp the balance between comparative learning, and requires large-scale training, which has high requirements for video memory and engineering implementation.
In this regard, researchers from the Natural Language Computing Group of Microsoft Research Asia proposed the Masked Image Modeling (MIM) pre-training task and launched the BEiT model. Unlike text, images are continuous signals, so how to implement mask training?
To solve this problem, the researchers transformed the image into two representational views. One is to learn Tokenizer through coding, and the image is turned into a discrete visual token (visual token), similar to text; the other is to cut the image into multiple small “pixel blocks” (patch), each pixel block is equivalent to a character . In this way, when pre-training with BEiT, the model can randomly mask some pixel blocks of the image and replace them with a special mask symbol [M], and then continuously learn and predict the appearance of the actual image in the backbone network ViT. After BEiT pre-training, by adding a task layer on the pre-training code, the model parameters of downstream tasks can be directly fine-tuned. Experimental results on image classification and semantic segmentation show that the BEiT model achieves superior results compared to previous pre-training methods. At the same time, BEiT is also more helpful for very large models (such as 1B or 10B), especially when labeled data is insufficient for supervised pretraining of large models.
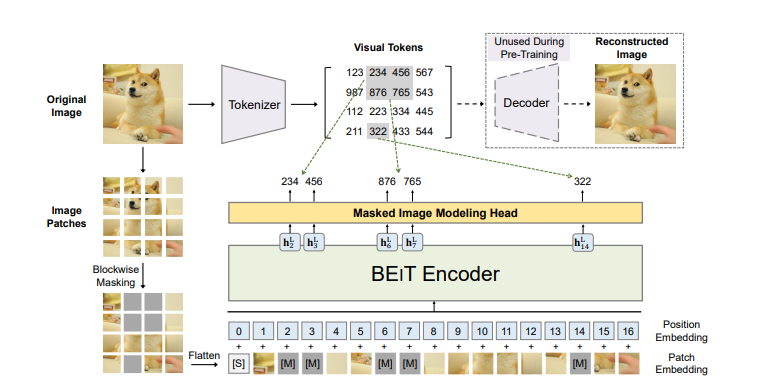
Figure 2: Schematic diagram of BEiT pre-training
BEiT related papers are accepted as Oral Presentation at ICLR 2022 (Oral Presentation Paper, 54 out of 3391). The ICLR conference review committee believes that BEiT has created a new direction for the research on pre-training of large visual models, and it is very innovative to apply mask pre-training in the field of CV for the first time. (For more details, please check the original text of the BEiT paper: https://ift.tt/FQ0Dv5C)

Figure 3: Review comments of BEiT papers at ICLR 2022
(For details, please visit: https://ift.tt/FQ0Dv5C)
BEiT-3 opens up new ideas for AI multimodal basic large model research
On the basis of BEiT, researchers at Microsoft Research Asia further enriched the semantic information of self-supervised learning in BEiT-2 (for more information, please check the original text of the BEiT-2 paper: https://arxiv.org/abs /2208.06366). Recently, the researchers upgraded it to BEiT-3. BEiT-3 utilizes a shared Multiway Transformer architecture, pre-trained by masked data modeling on unimodal and multimodal data, and can be transferred to various visual, vision-linguistic downstream tasks.

Figure 4: Schematic diagram of BEiT-3 pre-training
The innovation of BEiT-3 includes three aspects:
Backbone network: Multiway Transformer. The researchers used the Multiway Transformer as the backbone network to encode different modalities. Each Multiway Transformer consists of a shared self-attention module and multiple modality experts, each of which is a feed-forward network. The shared self-attention module can effectively learn the alignment of different modal information, and deeply fuse and encode different modal information to make it better applied to multi-modal understanding tasks. According to the current input modality class, the Multiway Transformer selects different modality experts to encode it to learn more modality-specific information. Each layer of Multiway Transformer contains a vision expert and a linguistic expert, while the first three layers of Multiway Transformer have vision-linguistic experts designed for the fusion encoder. The unified backbone network for different modalities enables BEiT-3 to widely support various downstream tasks. As shown in Figure 4, BEiT-3 can be used as a backbone network for various vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation, and can also be fine-tuned as a dual-encoder for image-text retrieval, and for multi-modality A fusion encoder for state understanding and generation tasks.
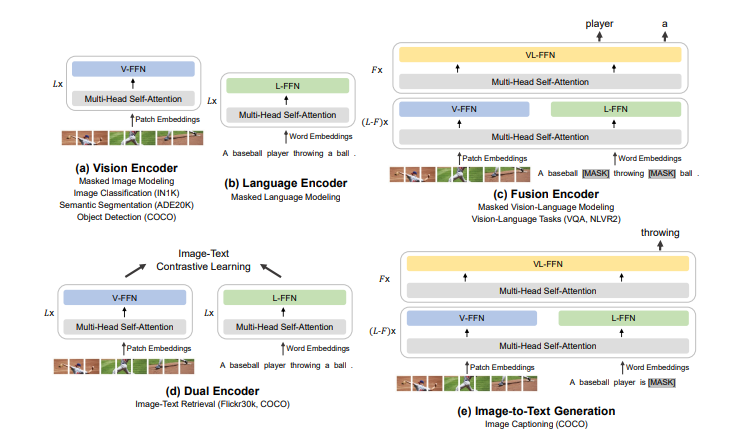
Figure 5: BEiT-3 can be transferred to various visual, visual-linguistic downstream tasks
Pre-training task: masked data modeling. We pre-train BEiT-3 with a unified mask-prediction task on unimodal (i.e., image and text) and multimodal data (i.e., image-text pairs). During pre-training, a certain percentage of text characters or pixel blocks are randomly masked, and the model is trained to recover the masked text characters or their visual symbols to learn the representation of different modalities and the alignment between different modalities. Unlike previous vision-language models that usually employ multiple pre-training tasks, BEiT-3 uses only one unified pre-training task, which is more friendly to training larger models. Due to the use of generative tasks for pre-training, BEiT-3 also does not require large batch training compared to models based on contrastive learning, which alleviates problems such as excessive GPU memory usage.
Expanding model size: BEiT-3 consists of 40 layers of Multiway Transformers, and the model contains a total of 1.9 billion parameters. On pre-training data, BEiT-3 is pre-trained on multiple unimodal and multimodal data, with approximately 15 million images and 21 million image-text pairs collected from five public datasets; single-modality data The state data used 14 million images and a 160GB text corpus.
“A consistent idea and principle of the BEiT series of studies is that we believe that images can also be regarded as a ‘language’ (Imglish) from a general technical level, so that images, texts and image-text pairs can be processed in a unified way. Modeling and Learning. If BEiT leads and advances the unification of generative self-supervised pre-training from NLP to CV, then BEiT-3 achieves the unification of generative multi-modal pre-training,” Microsoft Research Asia Natural Language Computing Wei Furu, the lead researcher of the group, said.
BEiT-3 uses Multiway Transformer to effectively model different visual, visual-linguistic tasks, and uses unified mask data modeling as a pre-training target, which makes BEiT-3 an important cornerstone of a general basic model. “BEiT-3 is both simple and effective, opening a new direction for multimodal base model extension. Next, we will continue to conduct research on BEiT to facilitate cross-language and cross-modal transfer, promote different tasks, Large-scale pre-training of languages and modalities and even unification of models.”
There is still a broader space for multimodal and general basic model research to be explored
Human perception and intelligence are inherently multimodal and are not limited to a single modality such as text or images. Therefore, multimodality is an important research and application direction in the future. In addition, due to the progress of large-scale pre-training models, AI research has shown a major trend, and paradigms, technologies and models in different fields are also approaching a unified state. Interdisciplinary and cross-field cooperation will be easier and more common, and research progress in different fields will be easier to advance each other, thereby further promoting the rapid development of the field of artificial intelligence.
“Especially the research in the fields of general basic models and generalist models will bring more exciting opportunities and development to AI research. The unification of technologies and models will gradually standardize and scale AI models, which will lead to large-scale industrialization. Provide the foundation and possibilities. Through cloud deployment and cloud collaboration, AI will be able to truly become a ‘new infrastructure’ like water and electricity, empowering all walks of life, and further spawning disruptive application scenarios and business models,” Wei Furu said.
For more information on Microsoft Research Asia’s research in the field of large-scale pre-trained models, please visit
https://ift.tt/RETk8rY
Links to related papers:
BEiT: BERT Pre-Training of Image Transformers
https://ift.tt/DhNbjuo
BEiT-2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
https://ift.tt/PCLXQ9O
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks (BEiT-3)
https://ift.tt/nILbq3N
This article is reprinted from: https://www.msra.cn/zh-cn/news/features/beit-3
This site is for inclusion only, and the copyright belongs to the original author.