Original link: https://www.msra.cn/zh-cn/news/features/layoutlmv3
Editor’s note: In the digital transformation of enterprises, structured analysis and content extraction based on multi-modal forms such as documents and images are a key part of the process, which can process information including contracts, bills, and reports quickly, automatically and accurately. It is crucial to improve the productivity of modern enterprises. Therefore, document intelligence technology came into being. In the past few years, Microsoft Research Asia has launched a series of research results of pre-training LayoutLM for general document understanding, and has continuously optimized the pre-training performance of the model for text, layout, and visual information in documents. The latest version of LayoutLM 3.0, released recently, has better performance on text and image-centric tasks, making document understanding models a big step toward cross-modal alignment!
With the digital transformation of every industry, the number of electronic documents covering forms, bills, emails, contracts, reports, papers, and more continues to grow. Electronic documents contain a large amount of industry-related image and text information, and it is time-consuming and costly to manually process these large amounts of information. The automatic identification, understanding and analysis technology of electronic documents is very important to improve the productivity of individuals or businesses, so document intelligence technology emerges as the times require. Document intelligence uses computers to automatically identify, understand and analyze electronic documents, which greatly improves the productivity of individuals and enterprises in processing electronic documents. It is an important research direction in the intersection of natural language processing and computer vision.

Figure 1: Examples of document intelligence tasks: form comprehension, document layout analysis
Although deep learning methods designed for specific tasks can achieve better performance for a certain document understanding task, these methods usually rely on limited labeled data, and for document understanding tasks, especially information extraction tasks, obtaining Detailed annotated data is expensive and time-consuming. To this end, researchers at Microsoft Research Asia have turned their attention to those neglected unlabeled data, using self-supervised pre-training techniques to utilize a large amount of unlabeled data in real life. Since pre-training has been widely used in the field of deep learning in recent years, this technique has also made significant progress in the field of document intelligence. The pre-trained document intelligence model can parse and extract various information of documents, which is of great significance to the academic research and production applications of document intelligence.
LayoutLMv3: One step closer to document understanding cross-modal alignment
Documents in real life not only have a lot of textual information, but also contain rich layout and visual information, and these three modalities have natural alignment characteristics in the document. How to model these documents and achieve cross-modal alignment through training is an important research topic. In this regard, Microsoft Research Asia has carried out many explorations in the field of document intelligence, and launched a series of research results of pre-training LayoutLM for general document understanding. These achievements have not only been widely concerned and recognized in academia, but also widely used in industry, such as the Form Recognizer in Microsoft Azure Cognitive Services.
- LayoutLM – By jointly pre-training text and layout, it achieves significant improvements on a variety of document understanding tasks.
- LayoutLMv2 – By incorporating visual feature information into the pre-training process, the model’s image understanding ability is greatly improved.
- LayoutXLM – Based on the model structure of LayoutLMv2, it extends the multi-language support of LayoutLM by pre-training in 53 languages.
Today, Microsoft Research Asia has proposed a new generation of document understanding pre-training model LayoutLMv3, which greatly simplifies model design and enhances the ease of use of downstream tasks through a simple model architecture and a unified pre-training target. The researchers pre-trained the LayoutLMv3 model on 50 million Chinese and 11 million English document images to meet the needs of Chinese and English users. LayoutLMv3 excels in text-centric tasks such as form understanding, ticket comprehension, and document visual question answering, as well as in image-centric tasks such as document image classification and document layout analysis.
The related papers were accepted as Oral Presentation by ACM Multimedia 2022, the top conference in the field of computer multimedia, and the codes and models have been open sourced. (For links to papers and code, see the end of the article)
LayoutLMv3 pretrains multimodal models with unified text and image mask modeling goals
Self-supervised learning has made rapid progress in representation learning by exploiting large amounts of unlabeled data. In natural language processing research, BERT first proposed a self-supervised pre-training method of “Masked Language Modeling” (MLM), which randomly masks a certain proportion of words in the text and reconstructs the masked words according to the context. to learn representations with contextual semantics. While most multimodal pretrained models for document intelligence use MLM on language modalities, they differ in their pretraining goals on image modalities. For example, there are models whose goal is to reconstruct dense image pixels or reconstruct continuous local region features, and these methods tend to learn noisy details rather than high-level structures (such as document layout). Moreover, the different granularity of image and text objects further increases the difficulty of cross-modal alignment learning, which is critical for multimodal representation learning.
In order to overcome the differences in pre-training targets of text and images and facilitate multi-modal representation learning, researchers at Microsoft Research Asia proposed LayoutLMv3 to pre-train multi-modal models with a unified text and image mask modeling target. That is, LayoutLMv3 learns to reconstruct cover word IDs of language modalities, and reconstructs cover image patch IDs of image modalities symmetrically.

Figure 2: Comparison of image representations and pre-training targets
Furthermore, for documents, each text word corresponds to an image patch. To learn this cross-modal alignment, the researchers also propose a patch alignment pre-training objective to learn the language-image fine-grained alignment by predicting whether the corresponding image patch of a text word is occluded.
LayoutLMv3 model architecture: directly utilize image patches of document images, save parameters and avoid region labeling
In terms of model architecture design, LayoutLMv3 does not rely on complex CNN or Faster R-CNN networks to characterize images, but directly utilizes image patches of document images, which greatly saves parameters and avoids complex document preprocessing (such as manual annotation of targets). area box and document object detection). The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model suitable for both text-centric and image-centric document AI tasks.
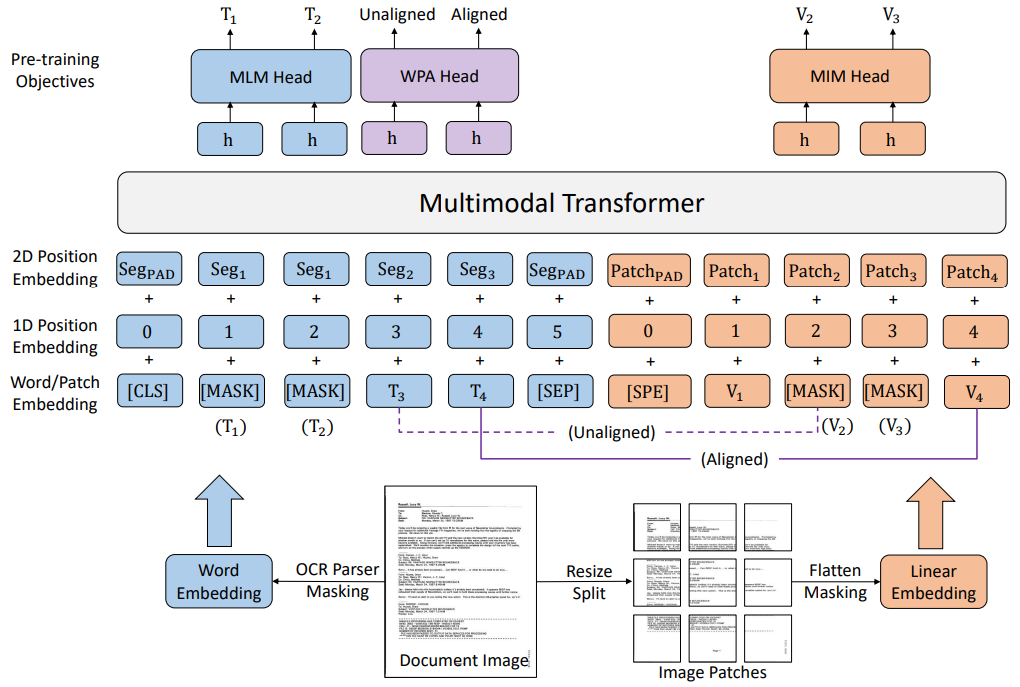
Figure 3: Architecture and pre-training objectives of LayoutLMv3
Microsoft Research Asia evaluated the pretrained LayoutLMv3 model on five datasets, including text-centric datasets: Form Understanding FUNSD dataset, Ticket Understanding CORD dataset, Document Visual Question Answering DocVQA dataset; and Image-centric dataset The datasets: RVL-CDIP dataset for document image classification, PubLayNet dataset for document layout analysis. Experimental results show that LayoutLMv3 achieves better performance with fewer parameters on these datasets.
LayoutLMv3 also applies the text-image multimodal Transformer architecture to learn cross-modal representations. The text vector is obtained by adding the word vector, the one-dimensional position vector of the word and the two-dimensional position vector. The text of the document image and its corresponding two-dimensional position information (layout information) are extracted using optical character recognition (OCR) tools. Because adjacent words of text usually express similar semantics, LayoutLMv3 shares the 2D position vector of adjacent words, while LayoutLM and LayoutLMv2 use different 2D position vectors for each word.
The representation of image vectors usually relies on CNN to extract feature map grid features or Faster R-CNN to extract regional features, which increase computational overhead or rely on region annotations. Therefore, researchers obtain image features through linear mapping of image blocks. This image representation method was first proposed in ViT. The computational cost is extremely small and does not depend on region annotation, which effectively solves the above problems. Specifically, the image is first scaled to a uniform size (e.g. 224×224), then the image is divided into fixed-size blocks (e.g. 16×16), and the image feature sequence is obtained by linear mapping, plus the learnable The image vector is obtained after the one-dimensional position vector.
LayoutLMv3 learns multimodal representations in a self-supervised manner with three pretrained objectives
Masked Language Modeling (MLM). In order to facilitate the model to learn the correspondence between layout information and text and images, this task randomly covers 30% of the text word vectors, but retains the corresponding two-dimensional position (layout) information. Similar to BERT and LayoutLM, the model goal is to restore the covered words in the text based on the uncovered graphics and layout information.
Masked Image Modeling (MIM). To encourage the model to infer image information from contextual information of text and images, the task randomly covers about 40% of image patches. Similar to BEiT, the model goal is to restore the discretized IDs of masked image patches based on the information of the uncovered text and images.
Word-Patch Alignment (WPA). For documents, each text word corresponds to an image patch. Since the first two tasks randomly mask some text words and image patches, the model cannot explicitly learn such fine-grained alignment between text words and image patches. The objective learns the fine-grained alignment relationship between language and visual modalities by explicitly predicting whether the corresponding image patch of a text word is masked.
Experiments and Results
To learn a general representation for various document tasks, the pre-training dataset for LayoutLMv3 is IIT-CDIP, which contains about 11 million scanned document images. Microsoft Research Asia trained BASE and LARGE models with 133M and 368M parameters respectively.
1. Fine-tune multimodal tasks: far beyond SOTA
The researchers fine-tuned LayoutLMv3 on four multimodal tasks:
(1) The form understanding task performs sequence annotation on the text content of the form. FUNSD is a document scan form understanding dataset containing 199 documents with annotations of 9,707 semantic entities. The semantic entity labeling task of the FUNSD dataset aims to classify each semantic entity as one of “question”, “answer”, “title” or “other”.
(2) The bill understanding task needs to extract bill information and classify each word with semantic labels. The dataset for this task is CORD, which contains 1,000 receipts with 30 semantic labels defined under 4 categories.
(3) The purpose of the document image classification task is to predict the category of document images. The task is performed on the RVL-CDIP dataset. The RVL-CDIP dataset contains 400,000 document images labeled with 16 categories.
(4) The document visual question answering task requires the model to take a document image and a question as input and output an answer. The task is performed on the DocVQA dataset. The training set of DocVQA contains about 10,000 images and 40,000 questions.
On these tasks, LayoutLMv3 achieves better or comparable results than previous work. For example, for the LARGE model scale, LayoutLMv3 achieves an F1 score of 92.08 on the FUNSD dataset, which greatly exceeds the previous SOTA result on the LARGE scale (85.14).
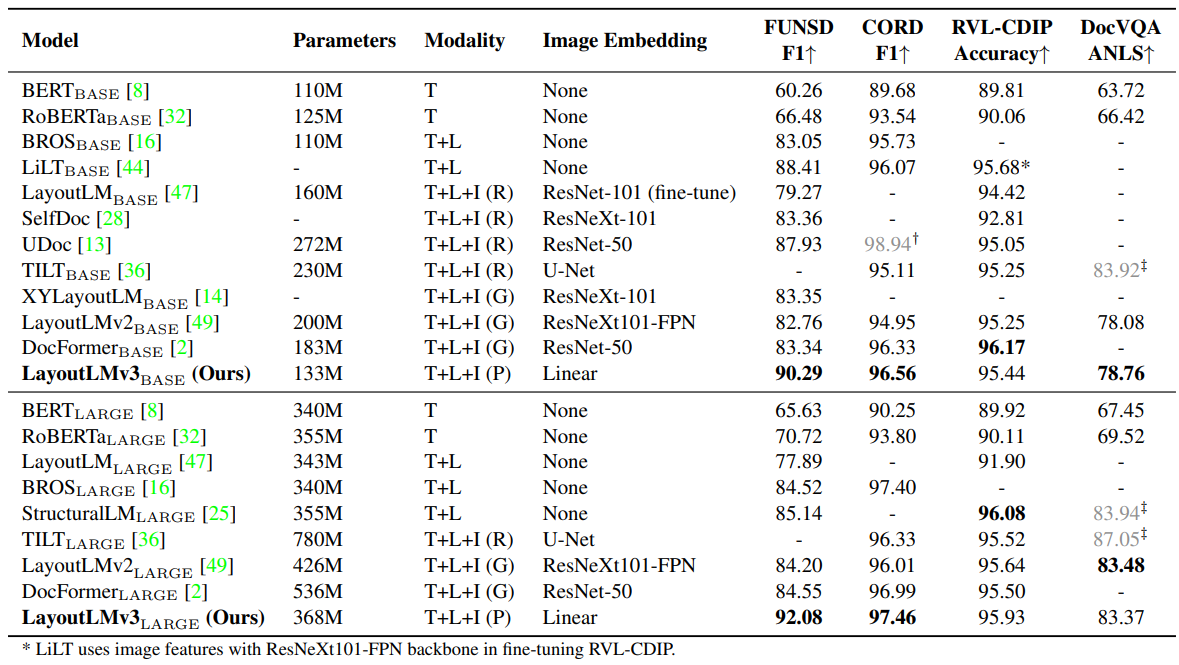
Table 1: Comparison of experimental results between LayoutLMv3 and existing work on CORD, FUNSD, RVL-CDIP, and DocVQA datasets
2. Fine-tune vision tasks: all metrics outperform other models
To demonstrate the versatility of the multimodal pretrained model LayoutLMv3 in the vision domain, the researchers applied LayoutLMv3 to the task of document layout analysis. The document layout analysis task aims to detect two-dimensional positions and categories for different layout elements of a document. This task facilitates parsing the document into a machine-readable format for use by downstream applications. The researchers modeled this task as an object detection problem, using LayoutLMv3 as a feature extraction network to integrate the features extracted by different layers into the object detector. The researchers conducted experiments on the PubLayNet dataset. The dataset contains more than 300,000 research paper images, each with location and category annotations of layout bounding boxes, ranging from text, titles, lists, figures, and tables. Compared to the convolutional neural network model and the contemporaneous visual Transformer pretrained model, LayoutLMv3 outperforms the other models on all metrics.

Table 2: Comparison of experimental results on document layout analysis tasks between LayoutLMv3 and existing work on the PubLayNet dataset
3. Ablation experiments: Strong proof that LayoutLMv3 is suitable for image-centric document analysis tasks
To investigate the effect of LayoutLMv3’s image representation method and pre-trained targets, researchers conduct ablation experiments on four typical datasets. The base model is pretrained with the MLM target using only text and layout information. Next, the researchers sequentially added image representations, MIM and WPA pre-training targets to the base model.
From the results in the table, it can be observed that the base model has no image representation and cannot perform image-centric document analysis tasks. LayoutLMv3 uses the linear map of image blocks as the image representation, and the design is simple, only 0.6M parameters are introduced. This image representation, combined with MIM pre-training targets, not only supports image-centric tasks, but also improves the performance of text-centric tasks. Combining the WPA pre-training objective further improves the performance of all downstream tasks, confirming the effectiveness of WPA in cross-modal representation learning and image representation learning, emphasizing the importance of visual and linguistic cross-modal alignment learning. In addition, the researchers found that MIM can help normalize training, which is critical for model convergence on vision tasks such as document layout analysis on PubLayNet.

Table 3: Comparison of ablation experimental results on image representations and pretrained targets
LayoutLMv3 also has excellent performance for Chinese document understanding
The pre-training data for the LayoutLMv3 model described above are all in English, and can be fine-tuned on the English-language downstream task dataset. In order to meet the needs of the majority of Chinese users, the researchers also trained the Chinese LayoutLMv3 model, which can be used for Chinese tasks.
The researchers obtained massive digital documents through large-scale data scraping, and used automated language detection tools to screen out 50 million Chinese document images for pre-training. The researchers validated the model on a Chinese visual information extraction task. It can be seen from Table 4 that LayoutLMv3 achieved a high score of 99.21 on the average score of all categories, significantly surpassing other models, verifying the effectiveness of the LayoutLMv3 Chinese model.

Table 4: Comparison of experimental results between LayoutLMv3 and existing work on the visual information extraction task in the EPHOIE Chinese dataset
Extensive experimental results demonstrate the generality and superiority of LayoutLMv3, which is not only suitable for text-centric and image-centric document intelligence tasks, but also achieves better or comparable performance with fewer parameters. In the future, Microsoft Research Asia will explore expanding the scale of pre-trained models so that the models can use more training data to further drive results; at the same time, expanding the model’s few-shot learning capabilities, thereby promoting the model in more business scenarios in the document intelligence industry application below.
LayoutLMv3 paper link: https://ift.tt/fQpOtkZ
LayoutLMv3 code link: https://ift.tt/MZ3ULP1
This article is reprinted from: https://www.msra.cn/zh-cn/news/features/layoutlmv3
This site is for inclusion only, and the copyright belongs to the original author.