Original link: https://www.luozhiyun.com/archives/677
One of the problems that we usually cannot avoid in development is how to achieve reliable network communication in unreliable network services, among which http request retry is a frequently used technology. But the Go standard library net/http does not actually have this function of retry, so this article mainly explains how to implement request retry in Go.
Overview
Generally speaking, the handling of network communication failure is divided into the following steps:
- Perception error. Different errors are identified by different error codes. In HTTP, status code can be used to identify different types of errors;
- Retry decision. This step is mainly used to reduce unnecessary retries, such as HTTP 4xx errors. Usually, 4xx indicates a client error. At this time, the client should not retry, or some custom errors in the business should not be used. should be retried. Judgment based on these rules can effectively reduce the number of unnecessary retries and improve the response speed;
- Retry strategy. The retry strategy includes the retry interval, the number of retries, etc. If the number of times is not enough, it may not be able to effectively cover the time period of this short-time failure. If the number of retries is too many, or the retry interval is too small, a lot of resources (CPU, memory, thread, network) may be wasted. We will talk about this below;
- hedging strategy. Hedging refers to actively sending multiple requests for a single call without waiting for a response, and then taking the first returned packet. This concept is the concept in grpc, and I also borrow it;
- The fuse is degraded; if it still fails after retrying, it means that the fault is not a short-term fault, but a long-term fault. Then the service can be fused and downgraded, and subsequent requests will not be retried. During this time, the downgrade processing will be performed to reduce unnecessary requests, and the request will be made after the server is restored. There are many implementations of go-zero , sentinel , hystrix-go is also quite interesting;
retry strategy
There are many types of retry strategies. On the one hand, the business tolerance affected by the long request time should be considered, and on the other hand, the impact of the retry on the downstream services caused by too many requests should be considered. , in short, it is a trade-off problem.
Therefore, for the retry algorithm, a gap time is generally added between retries. Interested friends can also read this article . Combined with our own practice and the algorithm of this article, we can generally summarize the following rules:
- Linear Backoff: Each retry interval is fixed for retry, such as retry every 1s;
- Linear interval + random time (Linear Jitter Backoff): Sometimes the same retry interval may cause multiple requests to be requested at the same time, then we can add a random time and fluctuate a percentage based on the linear interval time. time;
- Exponential Backoff: Each interval is a 2-exponential increment, such as 3s 9s 27s and retry;
- Exponential interval + random time (Exponential Jitter Backoff): This is similar to the second one, adding a fluctuation time on the basis of exponential increase;
The above two strategies have added jitter to prevent the occurrence of the Thundering Herd Problem .
In computer science , the thundering herd problem occurs when a large number of processes or threads waiting for an event are awoken when that event occurs, but only one process is able to handle the event. When the processes wake up, they will each try to handle the event, but only one will win. All processes will compete for resources, possibly freezing the computer, until the herd is calmed down again
The so-called thundering herd problem is when many processes are waiting to be awakened by the same event, and only one process can be dealt with after the event occurs. The rest of the processes are blocked again, which is a waste of context switching. So it is necessary to add a random time to avoid requesting the server at the same time.
Problems with retrying with net/http
Retrying this operation is actually not possible for Go to directly add a for loop to perform it according to the number of times. When there is no request body when the Get request is retried, it can be retried directly, but for the Post request, the request body needs to be put into the Reader , as follows:
req, _ := http.NewRequest("POST", "localhost", strings.NewReader("hello"))
After the server receives the request, it will call the Read() function from the Reader to read the data. Usually, when the server reads the data, the offset will change accordingly. The next time it reads again, it will start from the offset position. Continue reading backwards. So if you retry directly, there will be a situation where the Reader cannot be read.
We can start with an example:
func main() { go func() { http.HandleFunc("/", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { time.Sleep(time.Millisecond * 20) body, _ := ioutil.ReadAll(r.Body) fmt.Printf("received body with length %v containing: %v\n", len(body), string(body)) w.WriteHeader(http.StatusOK) })) http.ListenAndServe(":8090", nil) }() fmt.Print("Try with bare strings.Reader\n") retryDo(req) } func retryDo() { originalBody := []byte("abcdefghigklmnopqrst") reader := strings.NewReader(string(originalBody)) req, _ := http.NewRequest("POST", "http://localhost:8090/", reader) client := http.Client{ Timeout: time.Millisecond * 10, } for { _, err := client.Do(req) if err != nil { fmt.Printf("error sending the first time: %v\n", err) } time.Sleep(1000) } } // output: error sending the first time: Post "http://localhost:8090/": context deadline exceeded (Client.Timeout exceeded while awaiting headers) error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0 error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0 received body with length 20 containing: abcdefghigklmnopqrst error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0 ....
In the above example, a timeout of 10ms is set on the client side. Simulate the request processing timeout on the server side, sleep for 20ms first, and then read the request data, which will inevitably time out.
When requesting again, it is found that the body data requested by the client is not the 20 lengths we expected, but 0, resulting in err. Therefore, it is necessary to reset the Reader of Body, as follows:
func resetBody(request *http.Request, originalBody []byte) { request.Body = io.NopCloser(bytes.NewBuffer(originalBody)) request.GetBody = func() (io.ReadCloser, error) { return io.NopCloser(bytes.NewBuffer(originalBody)), nil } }
In the above code, we use io.NopCloser to reset the requested Body data to avoid unexpected exceptions in the next request.
Then compared to the simple example above, it can be improved, plus the StatusCode retry judgment, retry strategy, number of retries, etc. we mentioned above, it can be written as follows:
func retryDo(req *http.Request, maxRetries int, timeout time.Duration, backoffStrategy BackoffStrategy) (*http.Response, error) { var ( originalBody []byte err error ) if req != nil && req.Body != nil { originalBody, err = copyBody(req.Body) resetBody(req, originalBody) } if err != nil { return nil, err } AttemptLimit := maxRetries if AttemptLimit <= 0 { AttemptLimit = 1 } client := http.Client{ Timeout: timeout, } var resp *http.Response //重试次数for i := 1; i <= AttemptLimit; i++ { resp, err = client.Do(req) if err != nil { fmt.Printf("error sending the first time: %v\n", err) } // 重试500 以上的错误码if err == nil && resp.StatusCode < 500 { return resp, err } // 如果正在重试,那么释放fd if resp != nil { resp.Body.Close() } // 重置body if req.Body != nil { resetBody(req, originalBody) } time.Sleep(backoffStrategy(i) + 1*time.Microsecond) } // 到这里,说明重试也没用return resp, req.Context().Err() } func copyBody(src io.ReadCloser) ([]byte, error) { b, err := ioutil.ReadAll(src) if err != nil { return nil, ErrReadingRequestBody } src.Close() return b, nil } func resetBody(request *http.Request, originalBody []byte) { request.Body = io.NopCloser(bytes.NewBuffer(originalBody)) request.GetBody = func() (io.ReadCloser, error) { return io.NopCloser(bytes.NewBuffer(originalBody)), nil } }
hedging strategy
The above is the concept of retry, so sometimes our interface just occasionally has problems, and our downstream services don’t care about making more requests, then we can borrow the concept in grpc: Hedged requests .
Hedging refers to actively sending multiple requests for a single call without waiting for a response , and then taking the first returned packet. The main difference between hedging and retrying is that hedging will directly initiate a request if there is no response within a specified time, while retrying will only initiate a request after the server responds. So hedging is more like a more aggressive retry strategy.
When using hedging, it should be noted that because downstream services may implement load balancing strategies, downstream services that require requests are generally idempotent, safe in multiple concurrent requests, and in line with expectations.
Hedging requests are generally used to handle “long tail” requests. For the concept of “long tail” requests, see this article: https://segmentfault.com/a/1190000039978117
Handling of Concurrent Modes
Because hedging retry adds the concept of concurrency, goroutines are used for concurrent requests, so we can encapsulate data into channels for asynchronous message processing.
And because multiple goroutines process messages, we need to return err when each goroutine is processed but fails. It is very important that the main process cannot be blocked directly due to channel waiting.
However, since it is impossible to obtain the execution result of each goroutine in Go, we only focus on the correct processing of the result and need to ignore errors, so we need to cooperate with WaitGroup to achieve process control. The example is as follows:
func main() { totalSentRequests := &sync.WaitGroup{} allRequestsBackCh := make(chan struct{}) multiplexCh := make(chan struct { result string retry int }) go func() { //所有请求完成之后会close掉allRequestsBackCh totalSentRequests.Wait() close(allRequestsBackCh) }() for i := 1; i <= 10; i++ { totalSentRequests.Add(1) go func() { // 标记已经执行完defer totalSentRequests.Done() // 模拟耗时操作time.Sleep(500 * time.Microsecond) // 模拟处理成功if random.Intn(500)%2 == 0 { multiplexCh <- struct { result string retry int }{"finsh success", i} } // 处理失败不关心,当然,也可以加入一个错误的channel中进一步处理}() } select { case <-multiplexCh: fmt.Println("finish success") case <-allRequestsBackCh: // 到这里,说明全部的goroutine 都执行完毕,但是都请求失败了fmt.Println("all req finish,but all fail") } }
From the above code, in order to control the process, two more channels are used: totalSentRequests, allRequestsBackCh, and one more goroutine is used to asynchronously shut down allRequestsBackCh. The process control is too troublesome. Students who have a new implementation plan may wish to contact I’ll explore.
In addition to the above problem of concurrent request control, for hedging retry, it should also be noted that since the request is not serial, the context of http.Request will change, so you need to clone the context before each request to ensure that each time The context of each request is independent. But the offset position of the Reader changes again after each clone, so we also need to reset :
func main() { req, _ := http.NewRequest("POST", "localhost", strings.NewReader("hello")) req2 := req.Clone(req.Context()) contents, _ := io.ReadAll(req.Body) contents2, _ := io.ReadAll(req2.Body) fmt.Printf("First read: %v\n", string(contents)) fmt.Printf("Second read: %v\n", string(contents2)) } //output: First read: hello Second read:
So combining the above example, we can change the code to retry the hedge into:
func retryHedged(req *http.Request, maxRetries int, timeout time.Duration, backoffStrategy BackoffStrategy) (*http.Response, error) { var ( originalBody []byte err error ) if req != nil && req.Body != nil { originalBody, err = copyBody(req.Body) } if err != nil { return nil, err } AttemptLimit := maxRetries if AttemptLimit <= 0 { AttemptLimit = 1 } client := http.Client{ Timeout: timeout, } // 每次请求copy新的request copyRequest := func() (request *http.Request) { request = req.Clone(req.Context()) if request.Body != nil { resetBody(request, originalBody) } return } multiplexCh := make(chan struct { resp *http.Response err error retry int }) totalSentRequests := &sync.WaitGroup{} allRequestsBackCh := make(chan struct{}) go func() { totalSentRequests.Wait() close(allRequestsBackCh) }() var resp *http.Response for i := 1; i <= AttemptLimit; i++ { totalSentRequests.Add(1) go func() { // 标记已经执行完defer totalSentRequests.Done() req = copyRequest() resp, err = client.Do(req) if err != nil { fmt.Printf("error sending the first time: %v\n", err) } // 重试500 以上的错误码if err == nil && resp.StatusCode < 500 { multiplexCh <- struct { resp *http.Response err error retry int }{resp: resp, err: err, retry: i} return } // 如果正在重试,那么释放fd if resp != nil { resp.Body.Close() } // 重置body if req.Body != nil { resetBody(req, originalBody) } time.Sleep(backoffStrategy(i) + 1*time.Microsecond) }() } select { case res := <-multiplexCh: return res.resp, res.err case <-allRequestsBackCh: // 到这里,说明全部的goroutine 都执行完毕,但是都请求失败了return nil, errors.New("all req finish,but all fail") } }
Blow & Downgrade
Because when we use http calls, the external services called are often unreliable, and it is very likely that due to external service problems, our own service interface calls wait, so the call time is too long, resulting in a large backlog of calls, which slowly consumes Exhausting service resources will eventually lead to an avalanche of service calls, so it is very necessary to use circuit breaker downgrades in services.
In fact, the concept of circuit breaker downgrade is generally implemented in the same way. The core idea is to use a global counter to count the number of calls and the number of successes/failures. The switch of the fuse is judged by the statistical counter. The state of the fuse is represented by three states: closed, open, and half open.
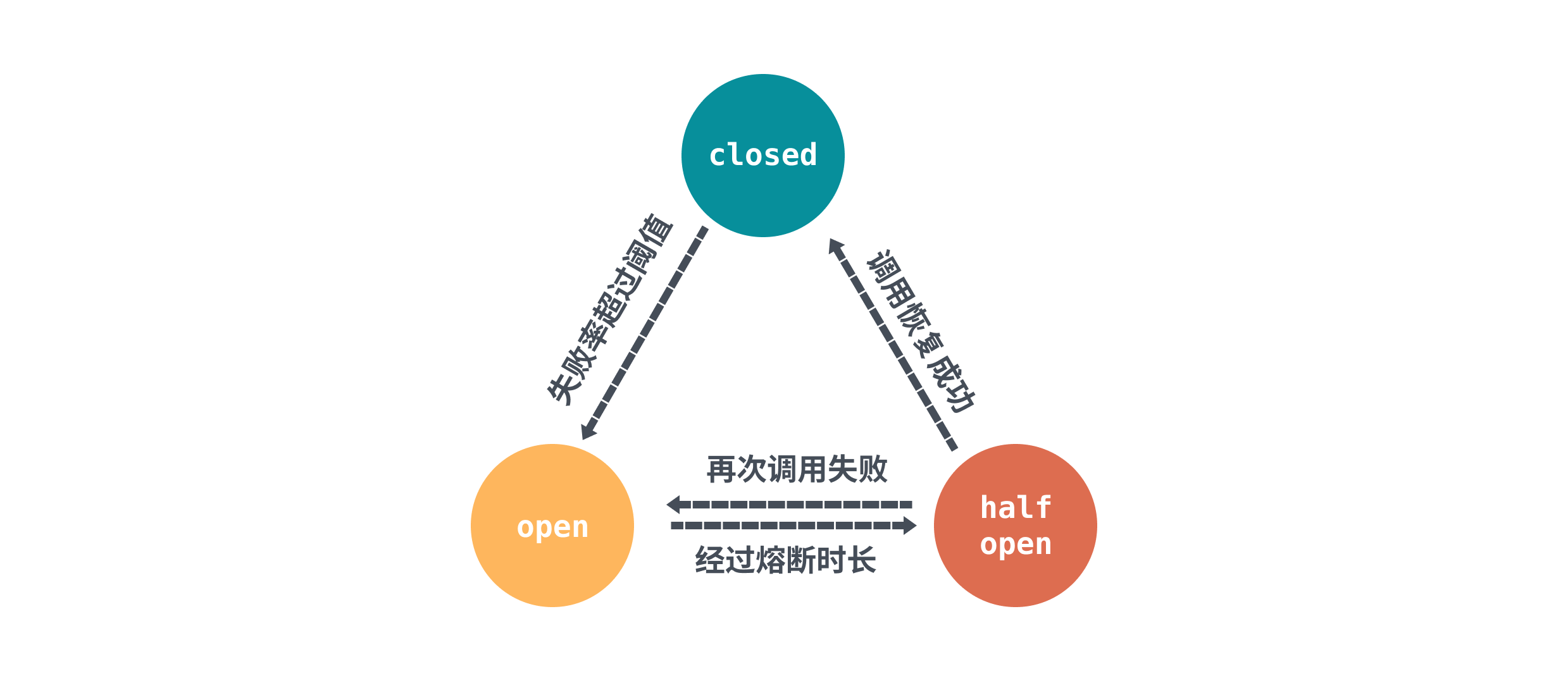
First, the initial state is closed . Each call will count the total number of times and the number of successes/failures through the counter. Then, after reaching a certain threshold or condition, the circuit breaker will switch to the open state, and the initiated request will be rejected.
A fuse timeout retry time will be configured in the fuse rule. After the fuse timeout retry period, the fuse will set the state to half-open state. This state will initiate timing detection for sentinel, and allow a certain percentage of requests for go-zero, whether it is active timing detection or passively passed request calls, as long as the result of the request returns to normal, then it needs to be reset The counter returns to the closed state.
Generally speaking, two fusing strategies are supported:
- Error rate : The number of requests threshold error rate within the circuit breaker time window is greater than the error rate threshold, which triggers circuit breaker.
- Average RT (response time) : The threshold of the number of requests within the circuit breaker time window is greater than the average RT threshold, which triggers circuit breakers.
For example, we use hystrix-go to handle the fusing of our service interface, which can be combined with the retry we mentioned above to further protect our service.
hystrix.ConfigureCommand("my_service", hystrix.CommandConfig{ ErrorPercentThreshold: 30, }) _ = hystrix.Do("my_service", func() error { req, _ := http.NewRequest("POST", "http://localhost:8090/", strings.NewReader("test")) _, err := retryDo(req, 5, 20*time.Millisecond, ExponentialBackoff) if err != nil { fmt.Println("get error:%v",err) return err } return nil }, func(err error) error { fmt.Printf("handle error:%v\n", err) return nil })
In the above example, hystrix-go is used to set the maximum error percentage equal to 30, and if this threshold is exceeded, it will be blown.
Summarize
This article starts from the interface call, explores several key points of retry, and explains several strategies for retry; then in the practical part, it explains what problems will be caused by directly using net/http to retry, and using channel for hedging strategies Add waitgroup to achieve concurrent request control; finally use hystrix-go to fuse faulty services to prevent resource exhaustion caused by request accumulation.
Reference
https://github.com/sethgrid/pester
https://juejin.cn/post/6844904105354199047
https://github.com/ma6174/blog/issues/11
https://aws.amazon.com/cn/blogs/architecture/exponential-backoff-and-jitter/
https://medium.com/@trongdan_tran/circuit-breaker-and-retry-64830e71d0f6
https://www.lixueduan.com/post/grpc/09-retry/
https://en.wikipedia.org/wiki/Thundering_herd_problem
https://go-zero.dev/cn/docs/blog/governance/breaker-algorithms/
https://sre.google/sre-book/handling-overload/#eq2101
https://sentinelguard.io/en-us/docs/golang/circuit-breaking.html
https://github.com/afex/hystrix-go
https://segmentfault.com/a/1190000039978117

How to properly retry requests in Go appeared first on luozhiyun`s Blog .
This article is reproduced from: https://www.luozhiyun.com/archives/677
This site is for inclusion only, and the copyright belongs to the original author.