Original link: https://jyzhu.top/Reading-NeuMan-Neural-Human-Radiance-Field-from-a-Single-Video/
Paper address: https://ift.tt/LcUzh31
Authors: Jiang, Wei and Yi, Kwang Moo and Samei, Golnoosh and Tuzel, Oncel and Ranjan, Anurag
Posted by: ECCV22
Open source code: https://ift.tt/vSahcJi
Why:
-
Human body rendering and new pose generation are important in augmented reality applications
-
The emergence of NeRF has made great progress in new perspective generation tasks
-
But none of the existing work has been implemented: generate new characters and new scenes based on a single wild video
 image-20220824123146868
image-20220824123146868
What:
Questions before reading:
- How the NeRF and human SMPL models are organically unified?
How:
-
The input is a wild video, from the moving camera. Estimate human pose, human shape, human mask (Mask-RCNN), camera pose, sparse scene model, depth maps with existing methods
-
Two NeRF models are then trained, one for the human body and one for the background guided by the segmentation masks estimated by Mask-RCNN. Furthermore, the scene NeRF model is normalized by fusing depth estimates from multi-view reconstruction and monocular depth regression together.
-
About NeRF: (Reference: zhihu )
-
NeRF models a scene with neural radiation fields, with the benefit of generating images from new perspectives. For a static scene, it is necessary to provide a large number of pictures with known camera parameters. The neural network trained based on these images can render the image results from any angle.
-
It uses MLP to implicitly encode a 3D scene into a neural network. The input is the coordinates of a point in 3d space \(\bold x = (x,y,z)\) and the camera angle \(\bold d = (\theta, \phi)\) , the output is the volume corresponding to the point The density opacity of the pixel, and the color \(\bold c = (r,g,b)\) . The formula is \[f(\bold{x},\bold{v})=(\bold c, \sigma)\]
-
In the specific implementation, x is first input into the MLP network and outputs σ and intermediate features, and the intermediate features and d are then input into an additional fully connected layer to predict the color. Therefore, voxel density is only related to spatial position, while color is related to both spatial position and viewing angle. Based on view dependent color prediction, different lighting effects can be obtained under different viewing angles.
-
The NeRF function obtains the color and density information of a 3D space point, but when a camera is used to image the scene, a pixel on the obtained 2D image actually corresponds to a ray from the camera. space point. In the future, there are various efficient ways to perform differentiable rendering, which are essentially upsampling from this ray to obtain average color information.
-
Human body model: NeRF+SMPL
My main focus is the mannequin part. In general, the approach is to:
First generate a human NeRF model, then use ROMP to generate a frame-by-frame human SMPL model, and then define a canonical human model (mainly to remove the pose variable and turn it into a large-character human body), according to the corresponding position of the pixel on the SMPL model, Then correspond to the canonical model to learn the appearance of the human body. (In fact, the NeRF and SMPL models are learned together in training, and there is no order in which they are separated.)
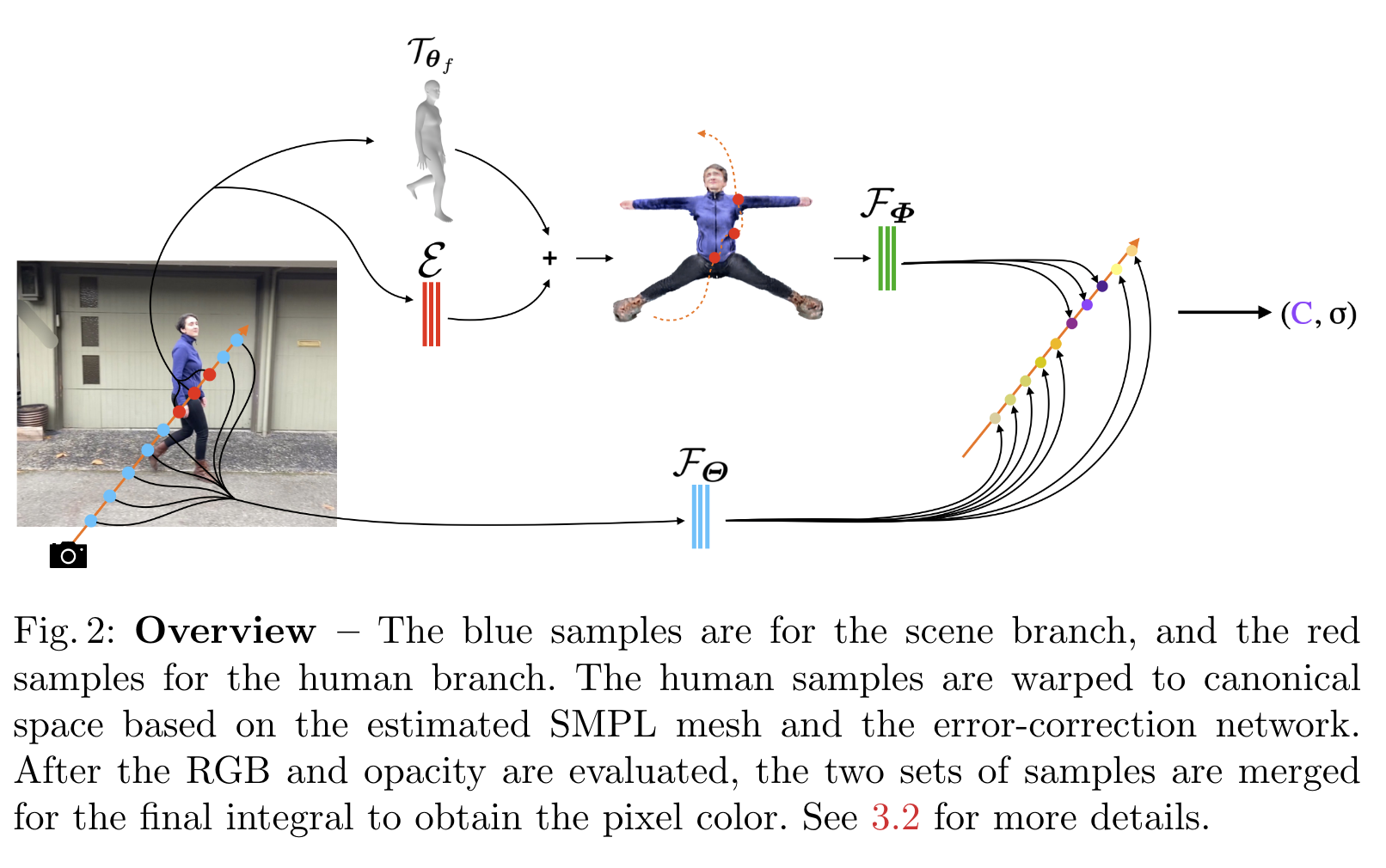 image-20220824180150642
image-20220824180150642
Specifically:
-
For a certain frame of image, ROMP is used to estimate the SMPL model of the human body, but with some improvements:
- Use densepose to estimate the silhouette of the human body, and MMPose to estimate the 2D joints of the human body; optimize the SMPL parameters based on these results
-
Warp the SMPL model just obtained into a canonical human body model with large fonts. This warp transformation is called \(\mathcal T\)
-
How to map the pixels in the image to the canonical human body model with large fonts?
-
First generate a human NeRF model
-
For each point in space \(\bold x_f=\bold r_f(t)\) (here f is the f-th frame image), it can be determined by the corresponding pixel point on a ray \(\bold r\) Rendered; then apply the previous transformation directly to this point \(\mathcal{T}\) to get its corresponding point in canonical space, \(\bold x’_f = \mathcal{T}_{ \theta_f}(\bold x_f)\)
-
However, because the estimation of SMPL is not very accurate, this transformation \(\mathcal{T}\) is not very accurate, so it is proposed here to optimize the SMPL model \(\theta_f\) and the human NeRF model at the same time during training. , can improve the effect.
-
Also, an MLP error correction network \(\mathcal{E}\) is added to correct the warping error. The end result is: \[\bold {\tilde x’_f} = \mathcal{T}_{\theta_f}(\bold x_f) + \mathcal{E}(\bold x_f, f)\]
-
At this time, the camera angle also needs to be corrected: for the i-th sample point on the ray ray, \[\bold d(t_i)’_f = \bold {\hat x}’_f(t_i) – \bold {\hat x} ‘_f(t_{i-1})\]
-
This article is reproduced from: https://jyzhu.top/Reading-NeuMan-Neural-Human-Radiance-Field-from-a-Single-Video/
This site is for inclusion only, and the copyright belongs to the original author.