Original link: https://www.luozhiyun.com/archives/721
Please declare the source for reprinting~, this article was published on luozhiyun’s blog: https://www.luozhiyun.com/archives/721
I haven’t studied in depth what the linking process has done before. Taking advantage of the recent efforts to sort out the knowledge of computer systems, I have sorted out what the linking process has done. If you are interested, you may wish to take a look.
Overview
Generally speaking, converting a C language source code file into an executable file requires compilation to generate an object file, and then multiple object files are linked to generate the final executable file.
编写源代码->编译生成目标文件->链接生成可执行文件Because the code in our project is often scattered in different files, it is necessary to synthesize multiple object files into one executable file. As for how to synthesize, this is what the link has to do. As shown in the image below, the linker combines two object files into one executable:
On the Linux platform, the content and structure of object files and executable files are very similar, so generally object files and executable files are stored in ELF (Executable Linkable Format).
ELF is an object file format that is used to define what is put in different types of object files (Object files), and in what format they are put. We classify ELF files into the following categories:
- Relocatable object files (Relocatable files), .o files generated by assembler assembly, can be used to link into executable files or shared object files;
- The executable object file (Executable file), which represents the ELF executable file, generally has no extension;
- Shared object file (Shared object file), dynamic library file, that is, .so file;
So let’s start with the file structure, what is contained in the ELF file, and then how the linker merges the object file.
ELF file structure
/usr/include/elf.h typedef uint16_t Elf64_Half; typedef uint32_t Elf64_Word; typedef uint64_t Elf64_Addr; typedef uint64_t Elf64_Off; #define EI_NIDENT (16) typedef struct { unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */ Elf64_Half e_type; /* Object file type */ Elf64_Half e_machine; /* Architecture */ Elf64_Word e_version; /* Object file version */ Elf64_Addr e_entry; /* Entry point virtual address */ Elf64_Off e_phoff; /* Program header table file offset */ Elf64_Off e_shoff; /* Section header table file offset */ Elf64_Word e_flags; /* Processor-specific flags */ Elf64_Half e_ehsize; /* ELF header size in bytes */ Elf64_Half e_phentsize; /* Program header table entry size */ Elf64_Half e_phnum; /* Program header table entry count */ Elf64_Half e_shentsize; /* Section header table entry size */ Elf64_Half e_shnum; /* Section header table entry count */ Elf64_Half e_shstrndx; /* Section header string table index */ } Elf64_Ehdr;
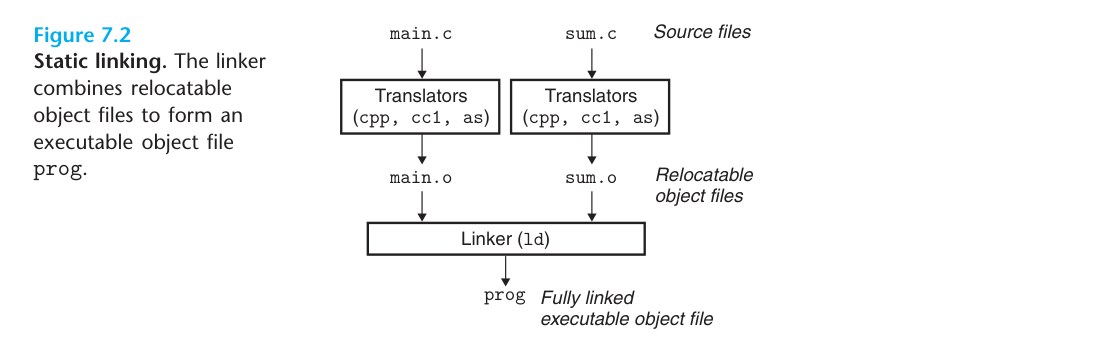
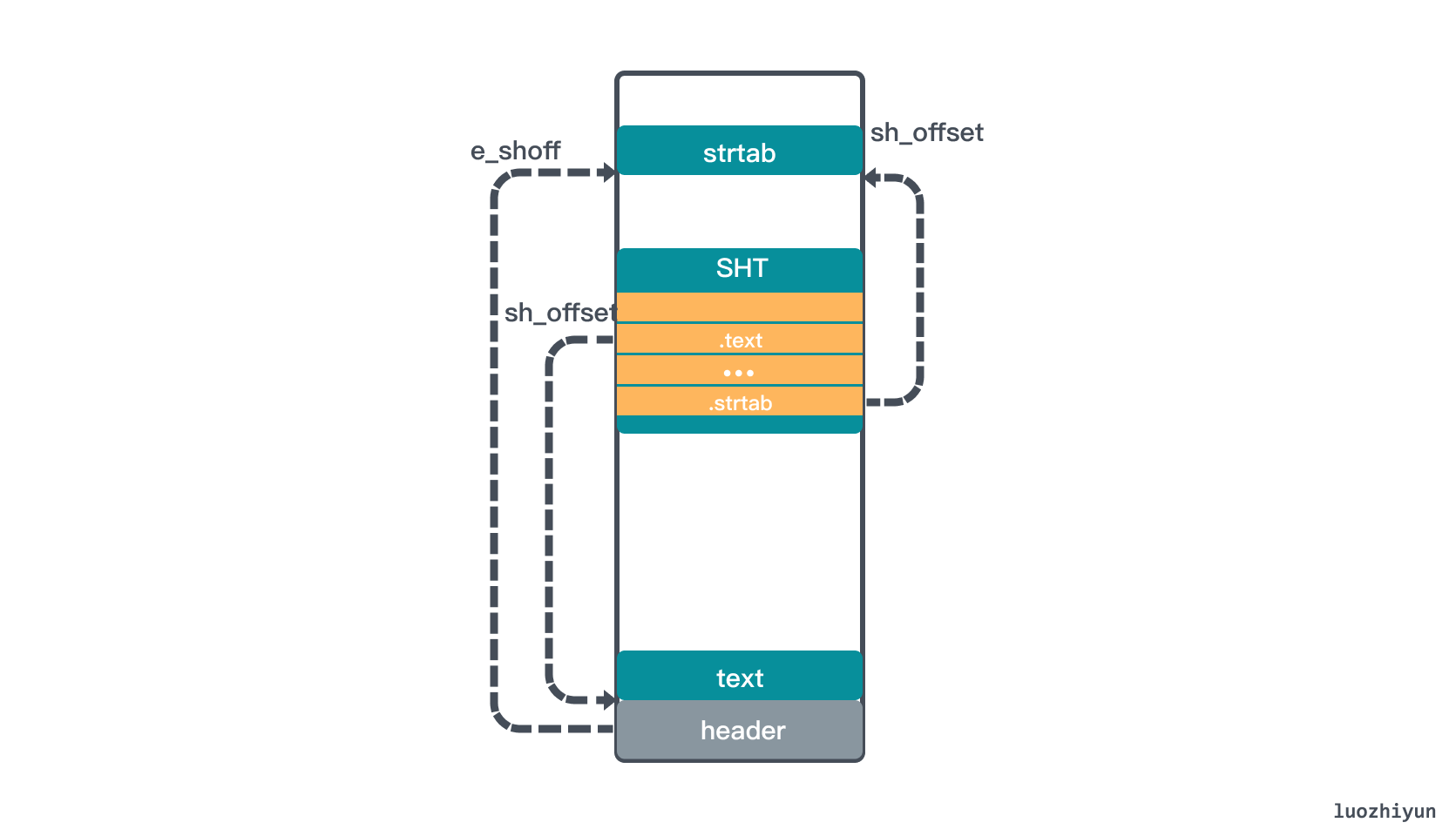
Let’s first look at how to locate the Section Header Table (SHT) with header information. A set of Sections are stored in the SHT, and the common ones are .text, .bss, .data, .bss, etc. Then to locate the SHT, you need to know the starting position, the size of the Section in the Table, and the number of Sections in the Table.
In the above header data structure, e_shoff is the offset position of SHT in the starting address of ELF, through which the starting position of SHT can be calculated; e_shentsize is the size of Section in SHT; e_shnum is the number of entries in SHT.
Also worth noting in the header data structure is the e_shstrndx field, which is an index into the string table and can help locate the string table.
Next, I will give you a clearer understanding of the ELF file structure by manually parsing the hexadecimal ELF file structure. Interested friends can follow along to verify it.
Let’s take an example to illustrate:
testelf.c unsigned long long data1 = 1234455; unsigned long long data2 = 66778899; void func1() {}; void func2() {};
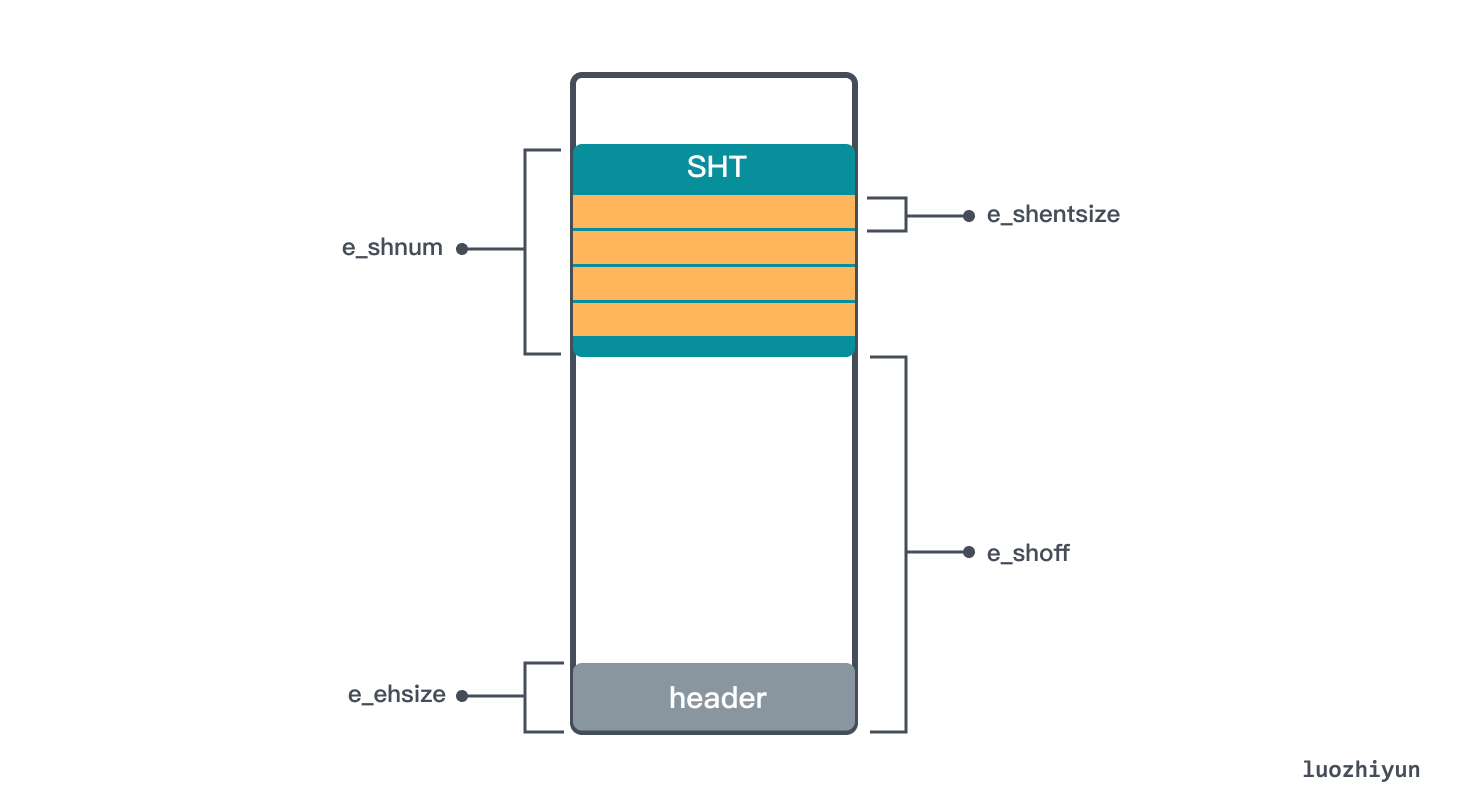
Compile the above file with the command gcc -c testelf.c -o testelf.o , and then view the content of the compiled testelf.o through hexdump testelf.o . According to the structure format of Elf64_Ehdr, we can interpret the Header information of ELF:

According to the mark in the above figure, you can find that e_shoff indicates that the SHT offset is 0x0140 (320 bytes), e_ehsize indicates that the size of the ELF header is 0x0040 (64 bytes), e_shentsize indicates that the size of the Section in the SHT is 0x0040 (64 bytes), and e_shnum indicates the number of SHT Sections 0x000b (11 bytes), e_shstrndx string table offset 0x0008 (8 bytes).
Section table
Therefore, according to e_shoff, we can find the offset position of the corresponding SHT. From e_shentsize, we can know that the size of each Section is 64 bytes, with a total of 11 items, then we can find the data corresponding to the corresponding SHT. The Section in the SHT is described by the Elf64_Shdr structure:
/usr/include/elf.h typedef uint32_t Elf64_Word; typedef uint64_t Elf64_Addr; typedef uint64_t Elf64_Off; typedef uint64_t Elf64_Xword; typedef struct { Elf64_Word sh_name; /* Section name (string tbl index) */ Elf64_Word sh_type; /* Section type */ Elf64_Xword sh_flags; /* Section flags */ Elf64_Addr sh_addr; /* Section virtual addr at execution */ Elf64_Off sh_offset; /* Section file offset */ Elf64_Xword sh_size; /* Section size in bytes */ Elf64_Word sh_link; /* Link to another section */ Elf64_Word sh_info; /* Additional section information */ Elf64_Xword sh_addralign; /* Section alignment */ Elf64_Xword sh_entsize; /* Entry size if section holds table */ } Elf64_Shdr;
Then we can continue to parse according to the above structural question and the character information output by hexdump testelf.o :
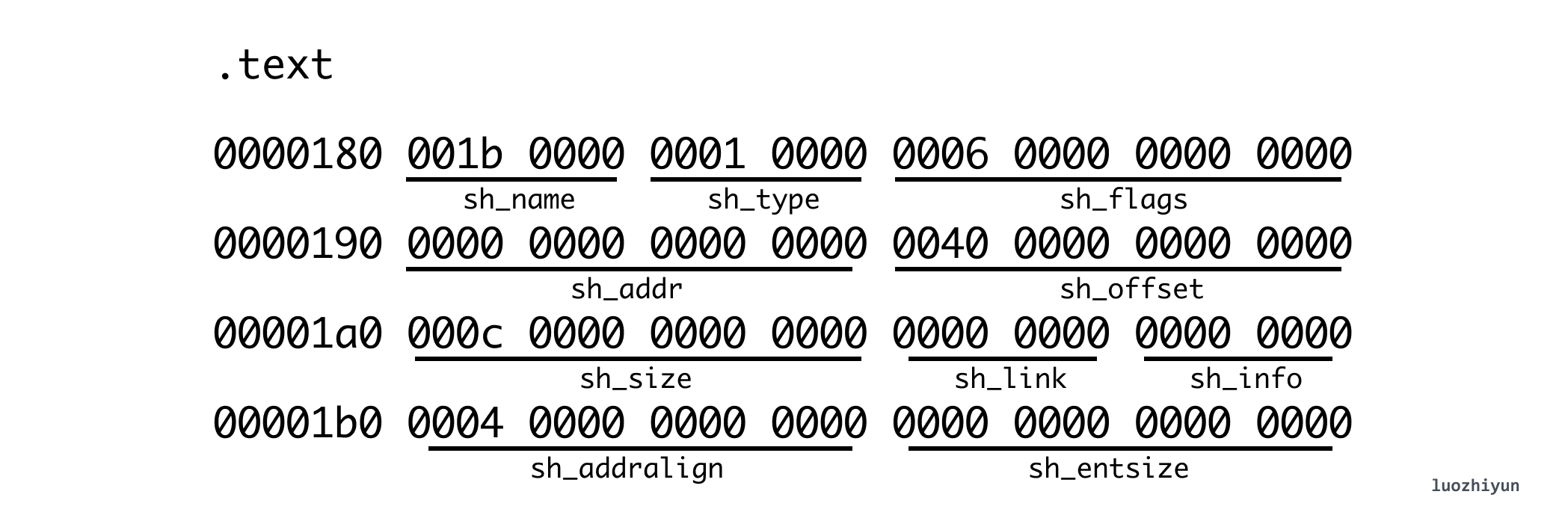
I only parsed the text Section here, from which we can see that sh_offset is 0x0040 (64 bytes), which means it directly points to the memory block behind the ELF header. When sh_size is 0x00c (12 bytes), it means that the two empty functions func1 and func2 occupy 12 bytes. It should be noted that Section[0] is only used for placeholders, and all are 0.
That is to say, we can find the specific data information of the corresponding Section through the above Section description information. Another example is the following strtab Section:
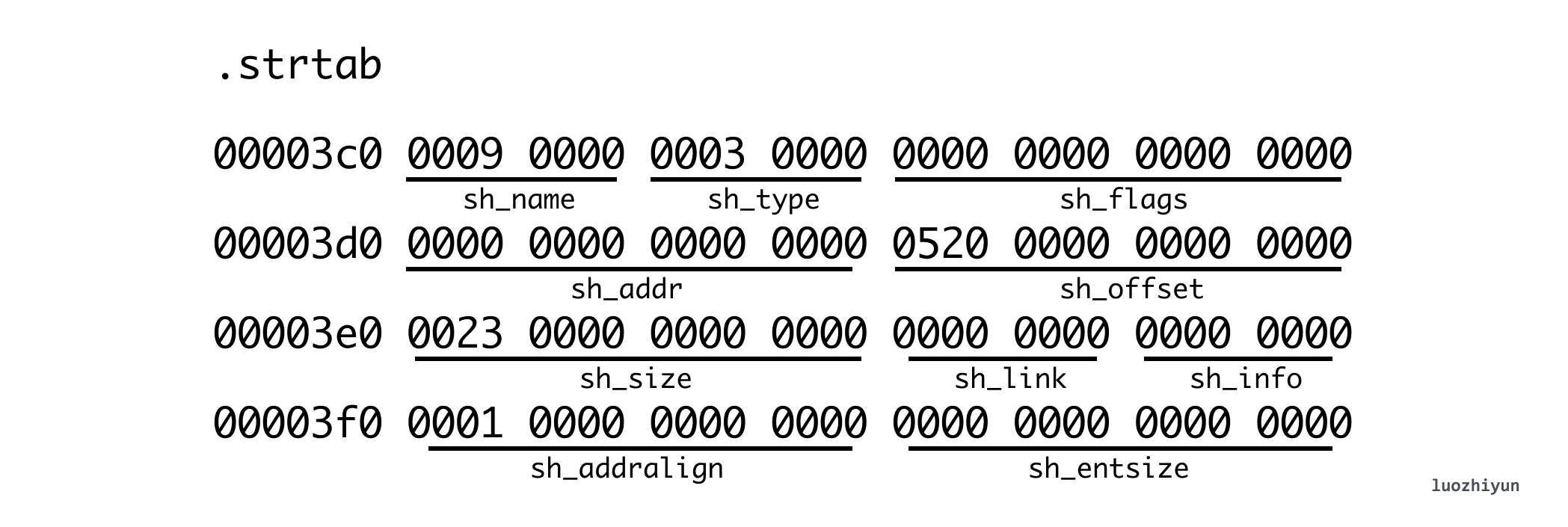
Through the above sh_offset, we can know that its offset position in the ELF file is 0x520, and the size is 0x0023 (35 bytes). Then you can use this information to find the data of the corresponding string table (the right side is the character corresponding to hexadecimal ascii), we can output the string ascii on the right side of hexdump -C :
00000520 00 74 65 73 74 65 6c 66 2e 63 00 64 61 74 61 31 |.testelf.c.data1| 00000530 00 64 61 74 61 32 00 66 75 6e 63 31 00 66 75 6e |.data2.func1.fun| 00000540 63 32 00 00 00 00 00 00 20 00 00 00 00 00 00 00 |c2...... .......|
It is worth mentioning that Elf64_Shdr.sh_name stores the offset pointed to by .shstrtab, you can find it yourself. Through the above analysis, it can be roughly seen that the ELF file has this structure:
Symbol table
One of the Sections in the SHT we mentioned above is .symtab, which is the symbol table. In the context of the linker, there are three different symbols:
- Global symbols, which can be referenced by other modules, that is, ordinary C functions and global variables;
- External symbols, symbols defined in other modules and referenced. For example, functions or variables modified by extern in C;
- Local symbols are symbols that can only be referenced by this module, that is, C functions and global variables with static attributes, which can be referenced in this module, but cannot be referenced by other modules.
In the above example, we can find the symbol table .symtab in the SHT:
.symtab Section points to another piece of memory, which is the symbol table, which consists of multiple entries. The corresponding symtab in the file looks like this:
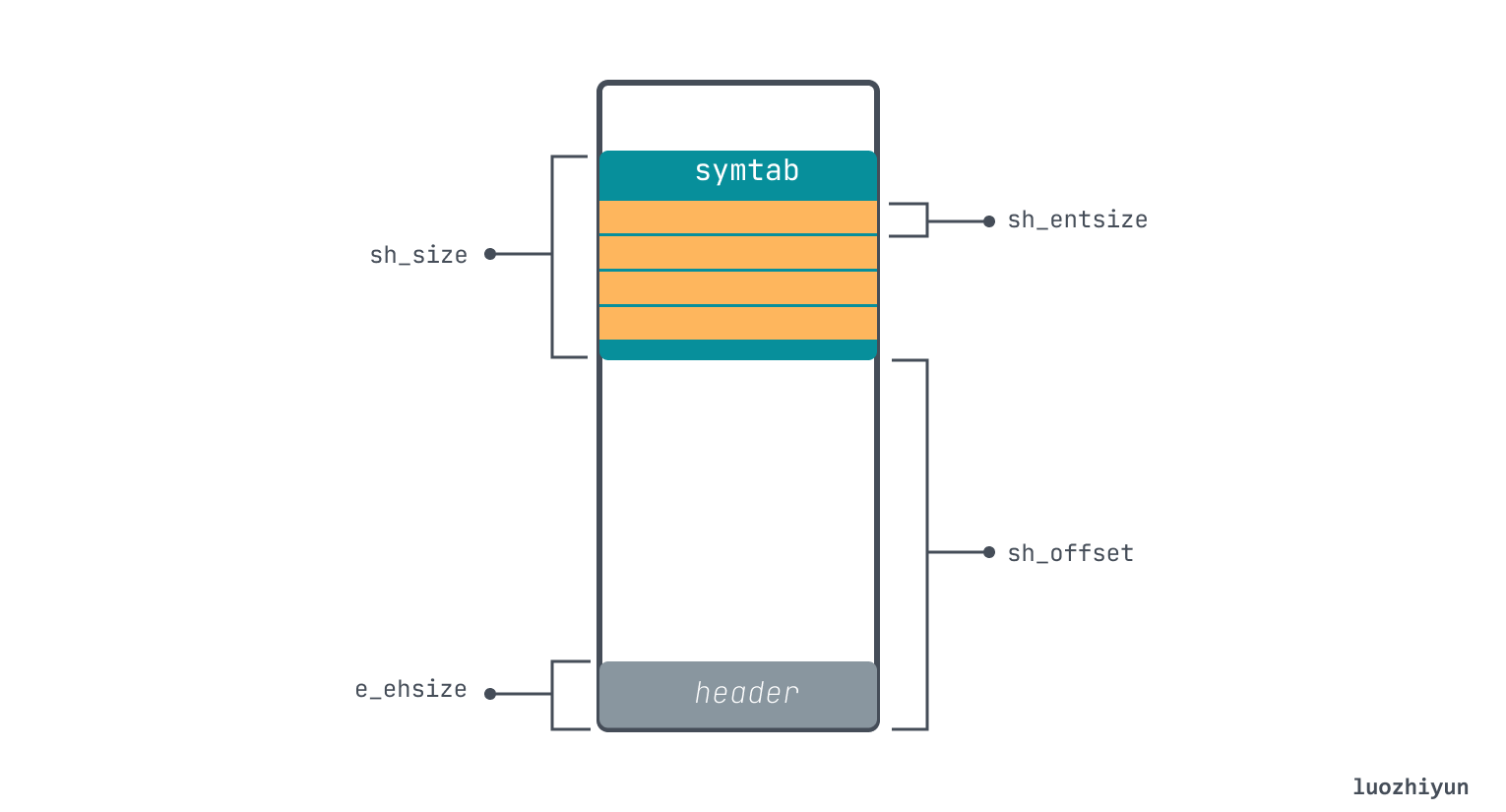
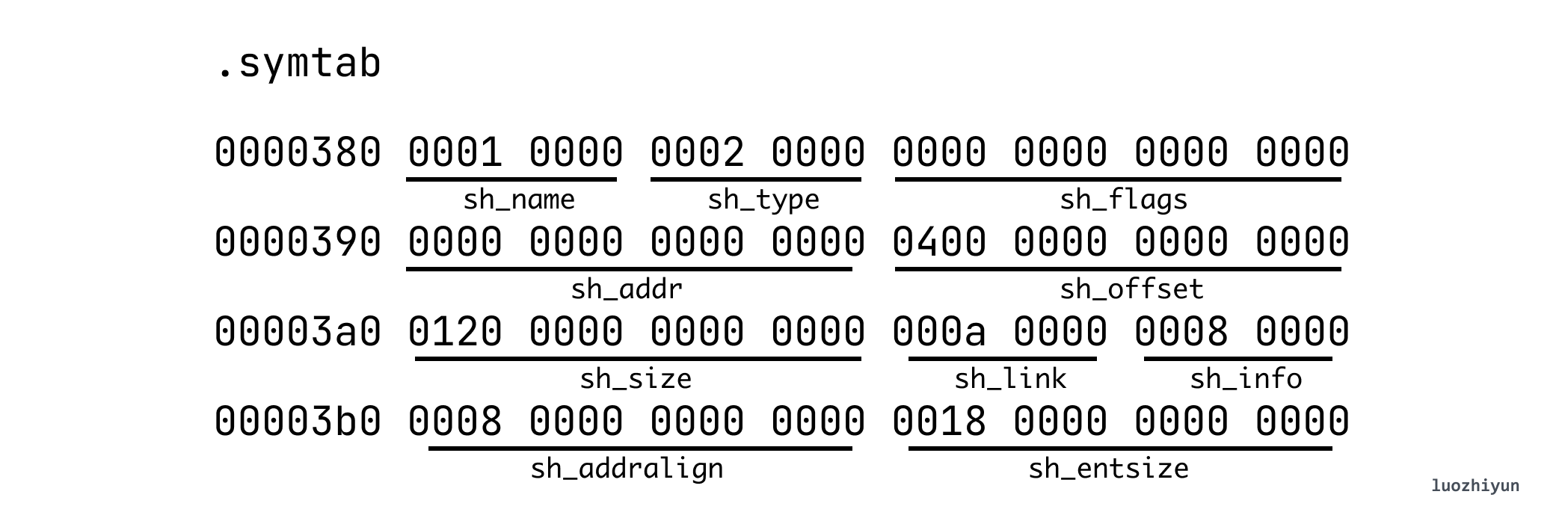
According to the method of looking at Section above, we can know that its offset is 0x400, the total size is 0x120 (288 bytes), and each item of .symtab has a fixed size of sh_entsize 0x18 (24 bytes), then it can be known that it has a total of 12 items . The data structure of the symtab entry is as follows:
/usr/include/elf.h typedef uint32_t Elf64_Word; typedef uint16_t Elf64_Section; typedef uint64_t Elf64_Addr; typedef uint64_t Elf64_Xword; typedef struct { Elf64_Word st_name; /* Symbol name (string tbl index) */ unsigned char st_info; /* Symbol type and binding */ unsigned char st_other; /* Symbol visibility */ Elf64_Section st_shndx; /* Section index */ Elf64_Addr st_value; /* Symbol value */ Elf64_Xword st_size; /* Symbol size */ } Elf64_Sym;
According to the offset position of symtab, the corresponding table entry can be found, and we take out the table entry we defined from it:

Among them, data1.st_name 0x0b (11 bytes) represents the start from offset 0x0b to 00 (‘\0’) in the .strtab table, and the obtained hexadecimal code is 64 61 74 61 31, corresponding to ascii is data 1.
st_shndx represents the SHT index position, and data1.st_shndx is 0x02, which means that the data is in SHT[2], that is, in the .data Section;
st_value is the address represented by each symbol. In the object file, the symbol address is relative to the Section where the symbol is located. In the executable file, this value represents the virtual address. Currently we are parsing the object file. , so data1.st_value is 0x00, corresponding to the offset of 0 in the .data Section;
st_size is the size occupied by the symbol, data1.st_size is 0x08 (8 bytes), then according to this information, the value in data can be taken out as 0x0012d617, and converted to decimal is the 1234455 we filled in. So you can also find out that data2 is 0x03faf713 and converted to decimal is 66778899.

Then according to the description of the symtab entry, we can determine the following positions:
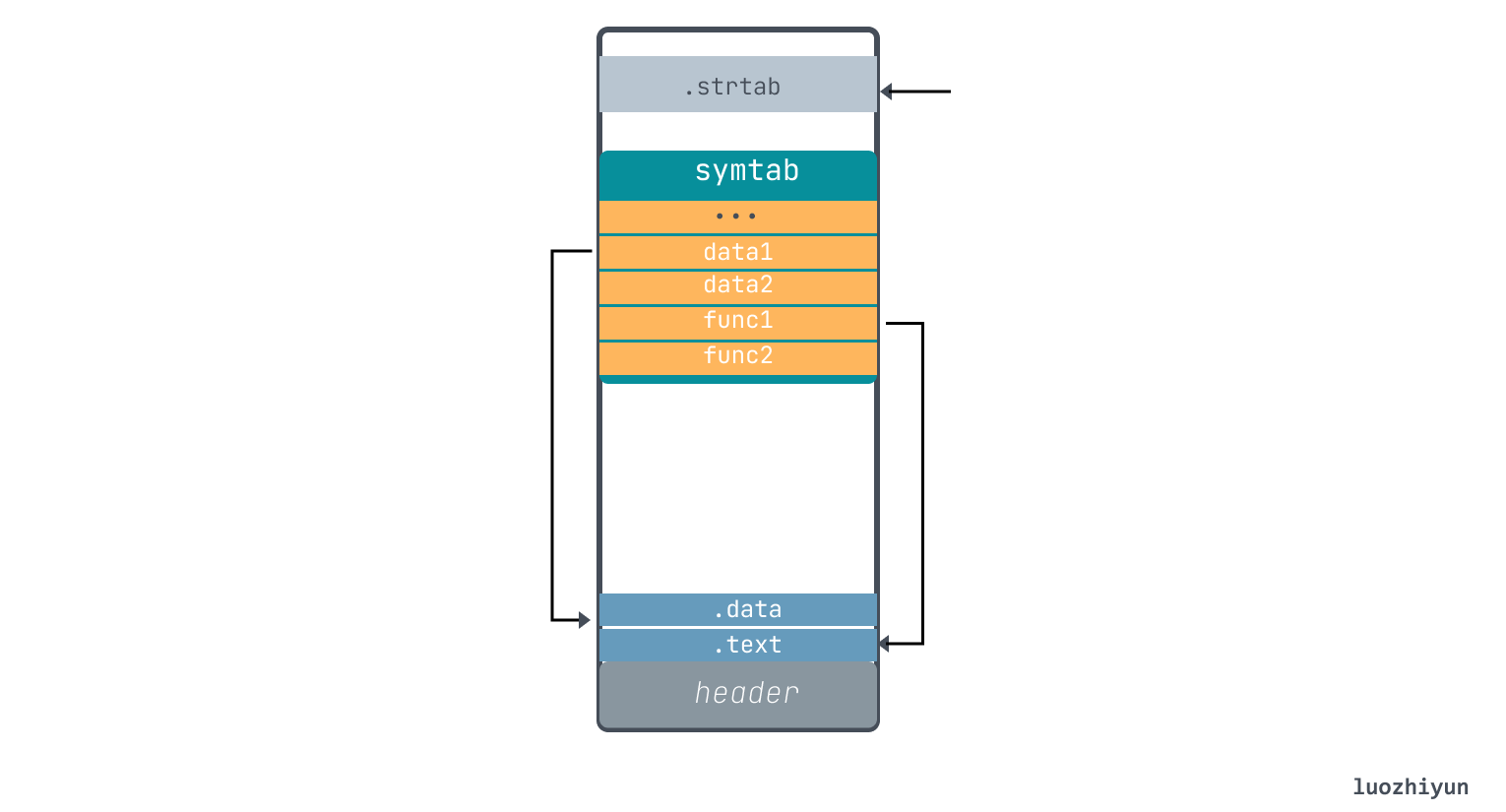
Let’s take a look at the field Elf64_Sym.st_info. The lower four bits of this field are the type of the symbol (Type), and the upper four bits are the association (Bind) of the symbol in the source file.
Type mainly expresses whether the symbol is defined as a variable or a function, etc. We mainly look at the following:
/usr/include/elf.h #define STT_NOTYPE 0 /* Symbol type is unspecified */ #define STT_OBJECT 1 /* Symbol is a data object */ #define STT_FUNC 2 /* Symbol is a code object */
In the above example, data1 and data2 Type are both 0x1, which means it is an Object object. Both func1 and func2 are 0x2, indicating a func function.
Bind mainly describes the type of this symbol and defines 9 types. Let’s look at the first two:
/usr/include/elf.h #define STB_LOCAL 0 /* Local symbol */ #define STB_GLOBAL 1 /* Global symbol */
data1, data2, func1, and func2 are all global symbols, so 0x1 is STB_GLOBAL.
Next, we can look at the variables and functions modified by static. For example, we can declare it as follows:
static unsigned long long data3 = 0xdddd; static void func3(){}
In addition to finding the symbol table according to hexadecimal above, we can also quickly view it through readelf -s :
$ readelf -s testelf.o Symbol table '.symtab' contains 15 entries: Num: Value Size Type Bind Vis Ndx Name ... 5: 0000000000000010 8 OBJECT LOCAL DEFAULT 2 data3 6: 0000000000000016 11 FUNC LOCAL DEFAULT 1 func3 ...
From the above we can see that the static variables data3 and func3 are still in .data and .text respectively compared with global variables. Because they are still variables and functions, the Type has not changed, but because they are modified by static, the Bind type has become STB_LOCAL. This is the main difference between static symbols and global symbols.
For external symbols, extern is generally used to modify, but extern can be omitted when modifying, so we need to discuss functions and variables. For functions, whether or not they are modified by extern, as long as they are not defined, the same symbols will be generated. But it should be noted that the compiler will optimize this useless declaration if it is not referenced in the current file. It will only appear in the symbol table if it is referenced:
extern void fun4(); int fun5();
For the above two functions, they are not defined, so they will not occupy space in the .text Section. Their table entries are as follows:
$ readelf -s testelf.o Symbol table '.symtab' contains 18 entries: Num: Value Size Type Bind Vis Ndx Name ... 16: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND fun4 17: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND fun5
st_shndx are all UND, that is, SHT[0], which means undefined. At the same time, their Type is also NOTYPE, which means no type. But because it is not modified by static, Bind is still GLOBAL to represent global symbols.
For variables, the situation is a little more complicated, because if extern is omitted, it is not necessarily of type extern, it may just define a global variable. We define these three variables below:
extern int data4; int data5; int data6 = 0;
Let’s take a look at the corresponding symbol table:
Symbol table '.symtab' contains 13 entries: Num: Value Size Type Bind Vis Ndx Name ... 9: 0000000000000004 4 OBJECT GLOBAL DEFAULT COM data5 10: 0000000000000000 4 OBJECT GLOBAL DEFAULT 4 data6 ... 12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND data4
For data4, it is displayed with extern decoration, so it behaves the same as the extern-modified function above. Although data4 and data5 can be represented as an extern variable, data5 is initialized by default assignment, and its address is located in the .comment Section of SHT, which belongs to a weak symbol and will be further processed in symbol resolution. .comment is a temporary Section in ELF and does not exist in the execution file. The variable stored in .comment will determine its whereabouts in the link. If the link finds its definition, the address is in the .data Segment in the execution file. Otherwise initialize to 0 and point the address to the .bss Segment.
For data6, it is displayed to be initialized to 0. ELF will put all the variables initialized to 0 into the .bss Section, and there is no need to define multiple times in .data. The role of .bss is to save space, it is specially used to store uninitialized global and static variables.
From the above we can also see that the difference between .comment and .bss is very subtle. The current version of GCC assigns symbols in relocatable object files to .comment and .bss according to the following rules:
- .comment: uninitialized global variable;
- .bss: uninitialized static variables, and global or static variables initialized to 0;
relocation table
When the assembler generates an ELF object file, it will encounter unhandled references. It is possible that a function or variable defined in another ELF file is referenced by the current ELF file code. So for these unknown object references, it generates a relocation entry that tells the linker how to modify this reference when merging the object file into an executable.
Relocation entries for code are placed in .rel.text, and relocation entries for initialized data are placed in .rel.data. The format of the relocation entry is as follows:
typedef struct { Elf64_Addr r_offset; /* Address */ Elf64_Xword r_info; /* Relocation type and symbol index */ Elf64_Sxword r_addend; /* Addend */ } Elf64_Rela;
r_offset records the position of the reference, which is relative to the byte offset of the current section; r_info is a composite structure, the type of the relocation of the lower 4 bytes, which prompts the linker how to deal with this relocation item, and the upper 4 bytes are the referenced item The serial number of the symbol in the symbol table.symtab; r_addend is the offset value in the relocation calculation, which is used to correct the final calculated position.
Let’s take an example below:
test_rel.c extern void undef_func(); extern int undef_array[2]; void main() { undef_func(); // reference<1> undef_array[0] = 1; // reference<2> undef_array[1] = 2; // reference<3> }
By looking up the table we can know:

Then we execute the disassembly objdump -d test_rel.o to see that the hexadecimal and assembly corresponding to the text section can find the corresponding code according to the r_offset offset:
Disassembly of section .text: 0000000000000000 <main>: 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp 8: b8 00 00 00 00 mov $0x0,%eax d: e8 00 00 00 00 callq 12 <main+0x12> 12: c7 05 00 00 00 00 01 movl $0x1,0x0(%rip) # 1c <main+0x1c> 19: 00 00 00 1c: c7 05 00 00 00 00 02 movl $0x2,0x0(%rip) # 26 <main+0x26> 23: 00 00 00 26: 90 nop 27: 5d pop %rbp 28: c3 retq
For a symbol index we can also find the corresponding symbol in the symbol:
Symbol table '.symtab' contains 13 entries: Num: Value Size Type Bind Vis Ndx Name ... 11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND undef_func 12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND undef_array
There is also a type field in Elf64_Rela that is not mentioned, because it involves specific strategies for calculating the location of the referenced object, and different strategies have different calculation methods. These strategies are actually accomplishing one thing, that is, when the program accesses the reference object, it will calculate the position of the referee based on the current position of the reference object. These strategies will not be discussed in detail here.
static linking
Because our code is stored in separate files in the actual development process, there will be a dependency between different files, so what static linking needs to do is to process multiple input object files and merge them into one executable file.
Let’s assume that there are only two files in the program:
ac extern void undef_func(); extern int undef_array[2]; void main() { undef_func(); // reference<1> undef_array[0] = 1; // reference<2> undef_array[1] = 2; // reference<3> } ------------------------------- bc void undef_func(){ }; int undef_array[2] = {1,2};
Then by using gcc ao bo -o ab to process the object files into an executable file, of course, we can also use gcc ac bc -o ab to directly generate an executable file from the source file.
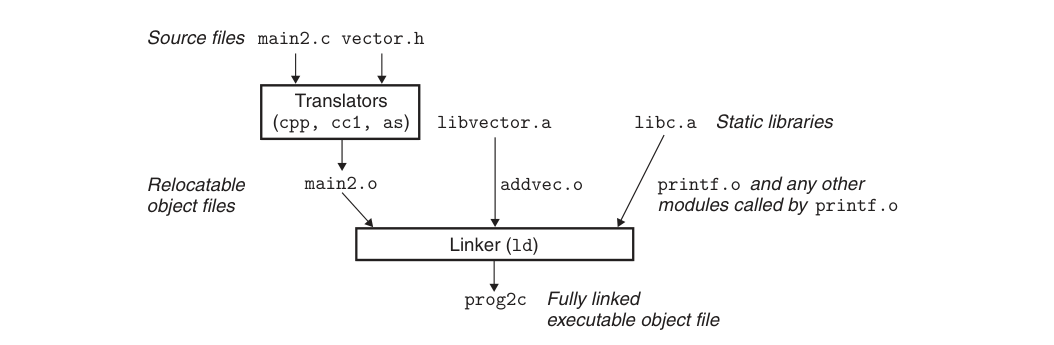
The entire linking process is divided into the following steps:
- Symbol analysis, when all ELF files are read into memory, different files may declare the same symbols, this step mainly resolves conflicts;
- Section merge, different files will have the same section, then you need to put the same section into the same section;
- Relocation, when the assembler generates an ELF object file, it will encounter unhandled references. Maybe a function or variable defined in other ELF files is referenced by the code of the current ELF file, so the reference position needs to be reset;
Symbol Analysis
This step mainly solves the symbol conflict between different files, so the symbol table is needed. In the symbol table, we mainly look at global symbols, because only global symbols can be referenced in different files. When talking about the symbol table above, it was also mentioned that in .symtab st_shndx represents the index of the symbol in the SHT, and the representation of the number is defined. In addition, there are several types of special pseudosections (pseudosections) exist. : ABS, COM, UND.
ABS represents a symbol that should not be relocated, and we can ignore it here; COM represents an uninitialized data object that has not been allocated a location. Since it does not exist in the executable file, it represents a temporarily defined symbol; UND represents an undefined symbol, that is, a symbol that is referenced in this object module but defined in another file.
In addition to the ones mentioned above, there is also a symbol modified by __attribbute__((weak)) , which is also a weak reference.
So the summary is: the defined symbol is a strong symbol, and several of COM, UND, __attribbute__((weak)) are weak symbols. Then according to the rules in CSAPP:
- Multiple strong symbols with the same name are not allowed;
- If there is a strong symbol and multiple if symbols with the same name, then the strong symbol is selected;
- If there are multiple weak symbols with the same name, choose any one of these symbols.
Section merge
Our compiler converts our code text into multiple object files ending in .o and the linker merges the multiple object files into one Executable Object File. Through the above analysis, we know that each object file will contain sections, so sections of the same type need to be merged.
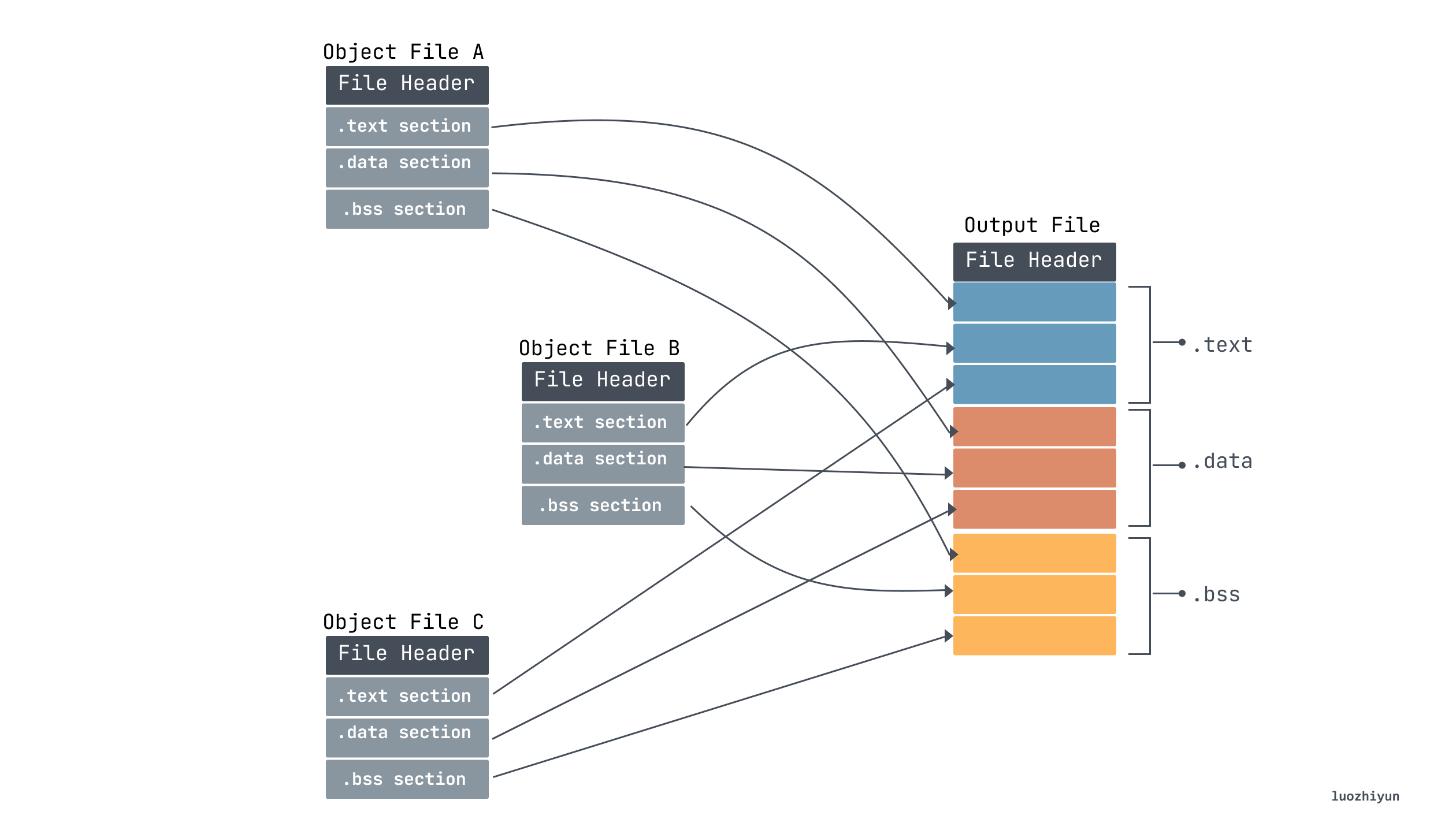
At the same time, after the merging is completed, multiple sections will be merged into segments, and the Program Header Table in the ELF Header is used to describe the segment information. Because the Program Header Table is not used during the linking process, it generally does not exist in the target file. The Segment is only used when it is loaded. The Loader loads and runs the program according to the Segment information in the executable file, so in the It exists when the executable is generated.
After we link the above two files a and b, we can use readelf -l to view the corresponding segment information:
Elf file type is DYN (Shared object file) Entry point 0x1040 There are 13 program headers, starting at offset 64 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flags Align PHDR 0x0000000000000040 0x0000000000000040 0x0000000000000040 0x00000000000002d8 0x00000000000002d8 R 0x8 INTERP 0x0000000000000318 0x0000000000000318 0x0000000000000318 0x000000000000001c 0x000000000000001c R 0x1 [Requesting program interpreter: /lib64/ld-linux-x86-64.so.2] LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x00000000000005c8 0x00000000000005c8 R 0x1000 LOAD 0x0000000000001000 0x0000000000001000 0x0000000000001000 0x00000000000001e5 0x00000000000001e5 RE 0x1000 LOAD 0x0000000000002000 0x0000000000002000 0x0000000000002000 0x0000000000000158 0x0000000000000158 R 0x1000 LOAD 0x0000000000002df0 0x0000000000003df0 0x0000000000003df0 0x0000000000000228 0x0000000000000230 RW 0x1000 DYNAMIC 0x0000000000002e00 0x0000000000003e00 0x0000000000003e00 0x00000000000001c0 0x00000000000001c0 RW 0x8 NOTE 0x0000000000000338 0x0000000000000338 0x0000000000000338 0x0000000000000020 0x0000000000000020 R 0x8 NOTE 0x0000000000000358 0x0000000000000358 0x0000000000000358 0x0000000000000044 0x0000000000000044 R 0x4 GNU_PROPERTY 0x0000000000000338 0x0000000000000338 0x0000000000000338 0x0000000000000020 0x0000000000000020 R 0x8 GNU_EH_FRAME 0x0000000000002004 0x0000000000002004 0x0000000000002004 0x0000000000000044 0x0000000000000044 R 0x4 GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 RW 0x10 GNU_RELRO 0x0000000000002df0 0x0000000000003df0 0x0000000000003df0 0x0000000000000210 0x0000000000000210 R 0x1 Section to Segment mapping: Segment Sections... 00 01 .interp 02 .interp .note.gnu.property .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn 03 .init .plt .plt.got .text .fini 04 .rodata .eh_frame_hdr .eh_frame 05 .init_array .fini_array .dynamic .got .data .bss 06 .dynamic 07 .note.gnu.property 08 .note.gnu.build-id .note.ABI-tag 09 .note.gnu.property 10 .eh_frame_hdr 11 12 .init_array .fini_array .dynamic .got
For the above segment information, you can clearly see the mapping relationship with the section. The definition of segment can be found in the Elf64_Phdr structure in /usr/include/elf.h . The type LOAD in the segment table indicates that it is a loadable segment, and the content of the segment will be copied from the file to the memory.
reset
After completing the symbol analysis and section summation, the symbols and references need to be relocated. During the relocation process, a virtual address will be calculated according to their positions, and the corresponding implementation can be found only when the program is running according to this address.
Let’s first take a look at the main function reference location objdump -d ab
0000000000001129 <main>: 1129: f3 0f 1e fa endbr64 112d: 55 push %rbp 112e: 48 89 e5 mov %rsp,%rbp 1131: b8 00 00 00 00 mov $0x0,%eax 1136: e8 17 00 00 00 callq 1152 <undef_func> # reference<1> 113b: c7 05 cb 2e 00 00 01 movl $0x1,0x2ecb(%rip) # 4010 <undef_array> reference<2> 1142: 00 00 00 1145: c7 05 c5 2e 00 00 02 movl $0x2,0x2ec5(%rip) # 4014 <undef_array+0x4> reference<3> 114c: 00 00 00 114f: 90 nop 1150: 5d pop %rbp 1151: c3 retq
Let’s see how the relocation is calculated. First, let’s look at the relocation item of ao:
Relocation section '.rela.text' at offset 0x268 contains 3 entries: Offset Info Type Sym. Value Sym. Name + Addend 00000000000e 000b00000004 R_X86_64_PLT32 0000000000000000 undef_func - 4 000000000014 000c00000002 R_X86_64_PC32 0000000000000000 undef_array - 8 00000000001e 000c00000002 R_X86_64_PC32 0000000000000000 undef_array - 4
The Type item represents the addressing method. We know the following by querying Relocation Types. Calculation represents the calculation method:
| Name | Value | Field | Calculation |
|---|---|---|---|
R_X86_64_NONE |
0 | none | none |
R_X86_64_64 |
1 | word64 | S + A |
R_X86_64_PC32 |
2 | word32 | S + A - P |
R_X86_64_GOT32 |
3 | word32 | G + A |
R_X86_64_PLT32 |
4 | word32 | L + A - P |
R_X86_64_COPY |
5 | none | none |
R_X86_64_GLOB_DAT |
6 | word64 | S |
R_X86_64_JUMP_SLOT |
7 | word64 | S |
R_X86_64_RELATIVE |
8 | word64 | B + A |
R_X86_64_GOTPCREL |
9 | word32 | G + GOT + A - P |
R_X86_64_32 |
10 | word32 | S + A |
R_X86_64_32S |
11 | word32 | S + A |
R_X86_64_16 |
12 | word16 | S + A |
R_X86_64_PC16 |
13 | word16 | S + A - P |
R_X86_64_8 |
14 | word8 | S + A |
R_X86_64_PC8 |
15 | word8 | S + A - P |
A : Indicates the Addend value of the relocation item;
GOT : indicates the address of the global offset table;
L : The segment offset or address of the symbolic procedure linkage table entry;
P : The segment offset or address of the relocated storage unit, calculated using r_offset;
S : the value of the symbol whose index is in the relocation entry;
Symbol table '.symtab' contains 65 entries: Num: Value Size Type Bind Vis Ndx Name .... 46: 0000000000004010 8 OBJECT GLOBAL DEFAULT 23 undef_array .... 59: 0000000000001152 11 FUNC GLOBAL DEFAULT 14 undef_func ... 61: 0000000000001129 41 FUNC GLOBAL DEFAULT 14 main
For the marked reference<1> position, the Type corresponding to undef_func is called R_X86_64_PLT32, then its calculation method is L + A - P . L here is 0x1152 by looking up the symbol table, and A we look up the .rela.text table above and know that it is – 4. P is equal to the current main function address + r_offset, we know that the main address is 0x1129, and r_offset is equal to 0xe, so P is 0x1137. So the final calculated result is 0x17, which is e8 17 00 00 00 callq 1152 <undef_func> when converted to assembly instructions.

Let’s look at the undef_array reference at the reference<2> location. Its Type is R_X86_64_PC32, which is the relative addressing of the program counter. The relative object is %rip, that is, when the program runs to this line, it needs to use the %rip pointer to find the The location of the reference, which is the location of the undef_array symbol. It is calculated as S + A - P . We also know that S is 0x4010 by looking up the table, A looks up the .rela.text table above and knows that it is – 8, P is equal to the main address value + r_offset is 0x113D, the final result is 0x4010 + (- 8) – 0x113D is 0x2ECB, this result The corresponding specification is the offset of %rip movl $0x1,0x2ecb(%rip) .

Dynamically Linked Shared Libraries
According to static linking, the .text and .data sections of all ELF files will be copied to the executable after each static linking is completed. If there are n executable files, the .text and .data data will be copied to the memory many times, which is a waste of memory. In addition, with the expansion of the program scale, because the static link must be recompiled and linked every time the module is updated, it is also a waste of time.
Shared library (shared library) is a product born to solve the problem of static linking. It is an object module, which can be loaded to any memory address when running or loaded, and linked with a program in memory. This process is called dynamic linking, which is performed by the dynamic linker. ) to execute. Shared libraries are also called shared objects and are usually represented by the .so suffix in Linux systems.
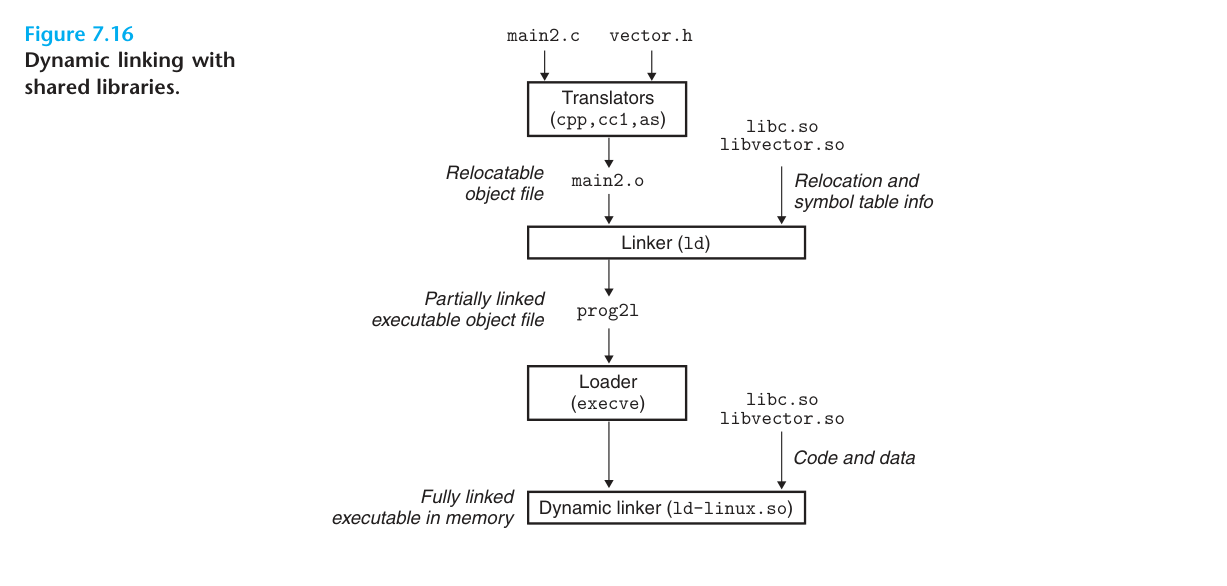
The above figure shows the process of shared library linking. First we create a shared library libvector.so with the following instructions:
$ gcc -shared -fpic -o libvector.so addvec.c multvec.c
-fpic means to generate address-independent code (PIC, Position-independent Code will be discussed below), and the -shared option means to create a shared object file.
Then link the libvector.so library with our main2.c file through dynamic linking to create the executable prog21:
$gcc -o prog21 main2.c ./libvect.so
The above step will compile main2.c successfully main2.o and then link the executable file called prog21. The difference from static linking is that when dynamic linking is compiled into main2.o, the compiler does not know the vector-related function addresses. If the vector-related function addresses are statically linked, the main.o and vector-related function address references will be re-referenced according to the static linking rules. location, but for dynamic linking, the linker will mark this reference as a dynamic link symbol, do not relocate it, and leave this process until load time.
When the loader loads and runs the executable prog21, the loader runs the dynamic linker and then completes the relocation of libvector.so and its symbolic references.
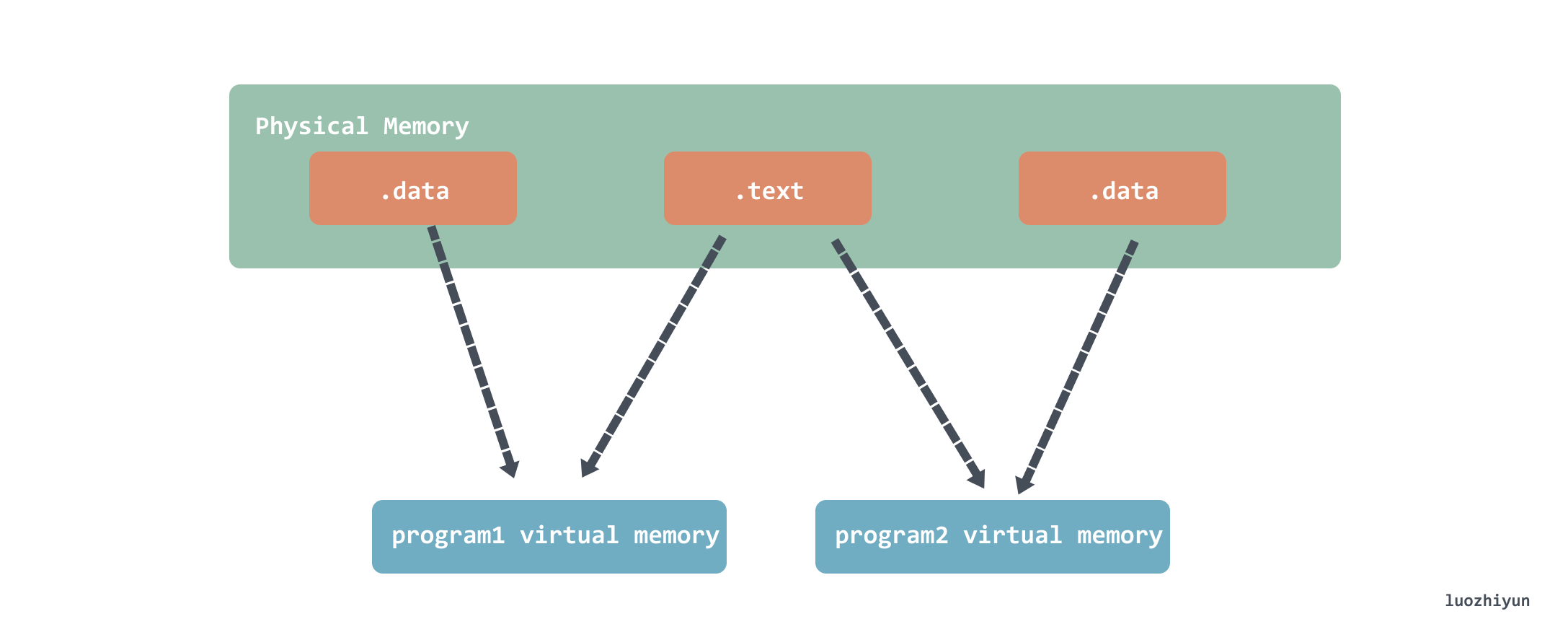
It should be noted that sharing does not share the entire libvector.so content, but only the code segment readable by .text, and the data is still separate:
Address Independent Code (PIC, Position-independent Code)
Because the dynamic link shares the code, but the instruction part, that is, the .text part, is unchanged, so it is necessary to allow the instruction to access the data or functions of other modules at runtime.
PIC data reference
In order to allow instructions to access data or functions of other modules, the compiler creates a global offset table (GOT, global offset table) at the beginning of the .data section. The size of each entry in GOT is 8 bytes, and it stores the runtime absolute address of the symbol in the referenced shared library.
For example the following example:
extern int b; void ext(){ int local_b = b; }
We compile the shared library test.so:
$gcc -shared -fpic -o test.so test.c
The global variable b in another shared library referenced here is actually address-independent, and the address of b needs to be determined through the GOT and the dynamic linker:
<ext>: mov 0x2ed0(%rip),%rax # 3fd8 mov (%rax),%eax
Here, the relative address 0x2ed0(%rip) of the PC is used to find the entry whose GOT address is 0x3fd8.
$ objdump -R test.so DYNAMIC RELOCATION RECORDS OFFSET TYPE VALUE 0000000000003fd8 R_X86_64_GLOB_DAT b
Then the real value is written from the GOT to %rax at runtime, and the value of the address in (%rax) memory is copied to the register %eax, so the value of b at runtime is obtained.
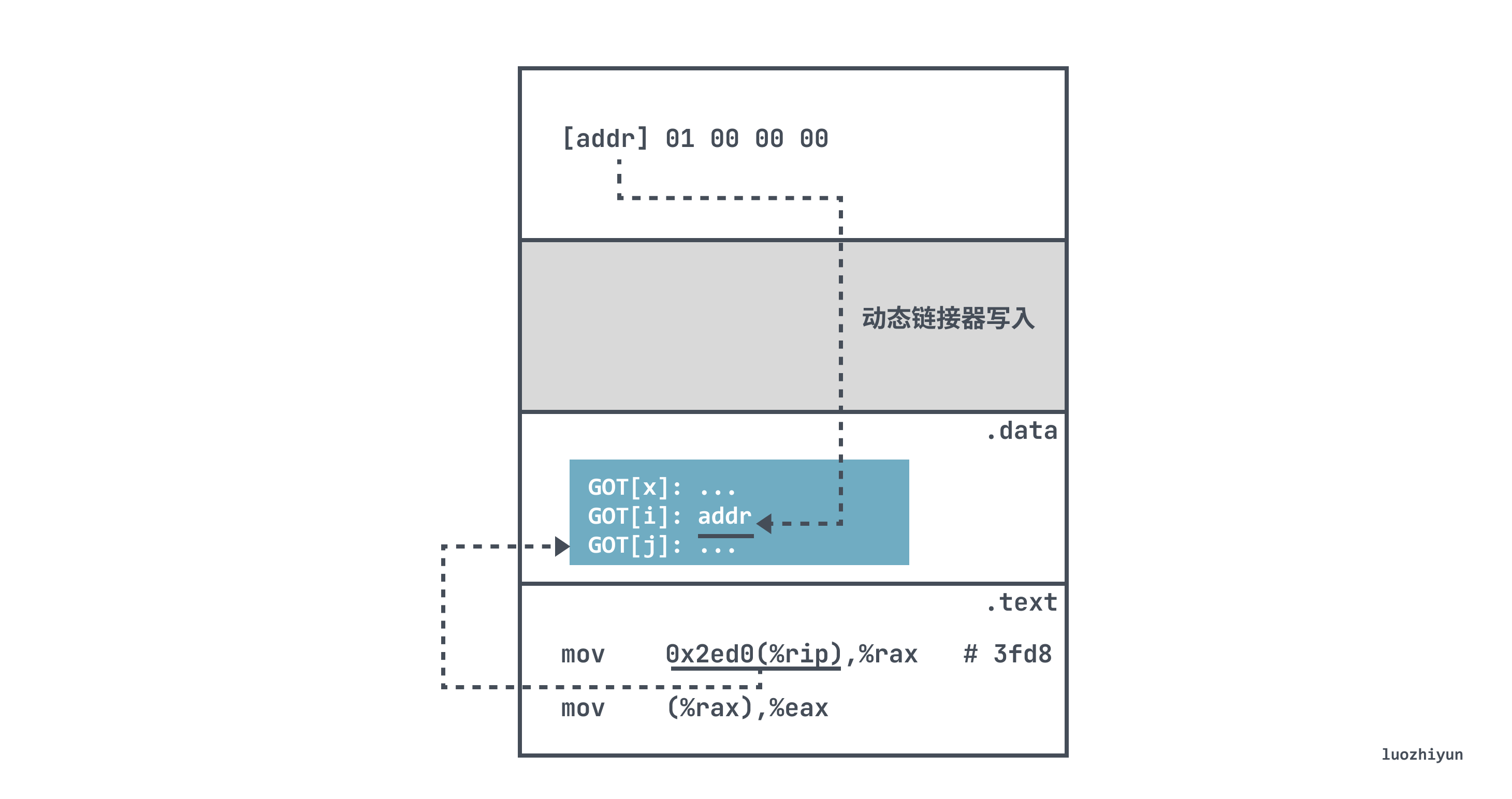
Among them, 0x2ed0 is the fixed distance between GOT[2] and the mov instruction at runtime, so that the compiler can use the constant distance between .text and .data to generate a relative reference to the variable a and the PC. When loading, the dynamic linker Each entry in the GOT is relocated to contain the correct absolute address of the target.
PIC function reference
The function reference is slightly different from the data reference. The function reference uses a method called delayed binding. The basic idea is to bind (symbol lookup, relocation, etc.) when the function is used for the first time. If it is not used, it will not be bound.
This is because a large number of function references are included between program modules under dynamic linking (global variables tend to be relatively small, because a large number of global variables will cause the coupling between modules to become larger), so the dynamic linking performs functions before the program starts executing. Too many symbol lookups and relocations can take a lot of time. Another reason is that during the running of a program, many functions may not be used after the program is executed. It is actually a waste to link all the functions at the beginning.
In order to implement delayed binding, function references are implemented with the help of a procedure connection table (PLT, Procedure Linkage Table). PLT is an array, each entry is 16 bytes, implemented in the .text section, the content is a number of goto-like labels, and rip can jump to this address.
Let’s make a simple example to illustrate:
#include <stdlib.h> void main() { int *a = malloc(64*sizeof(int)); }
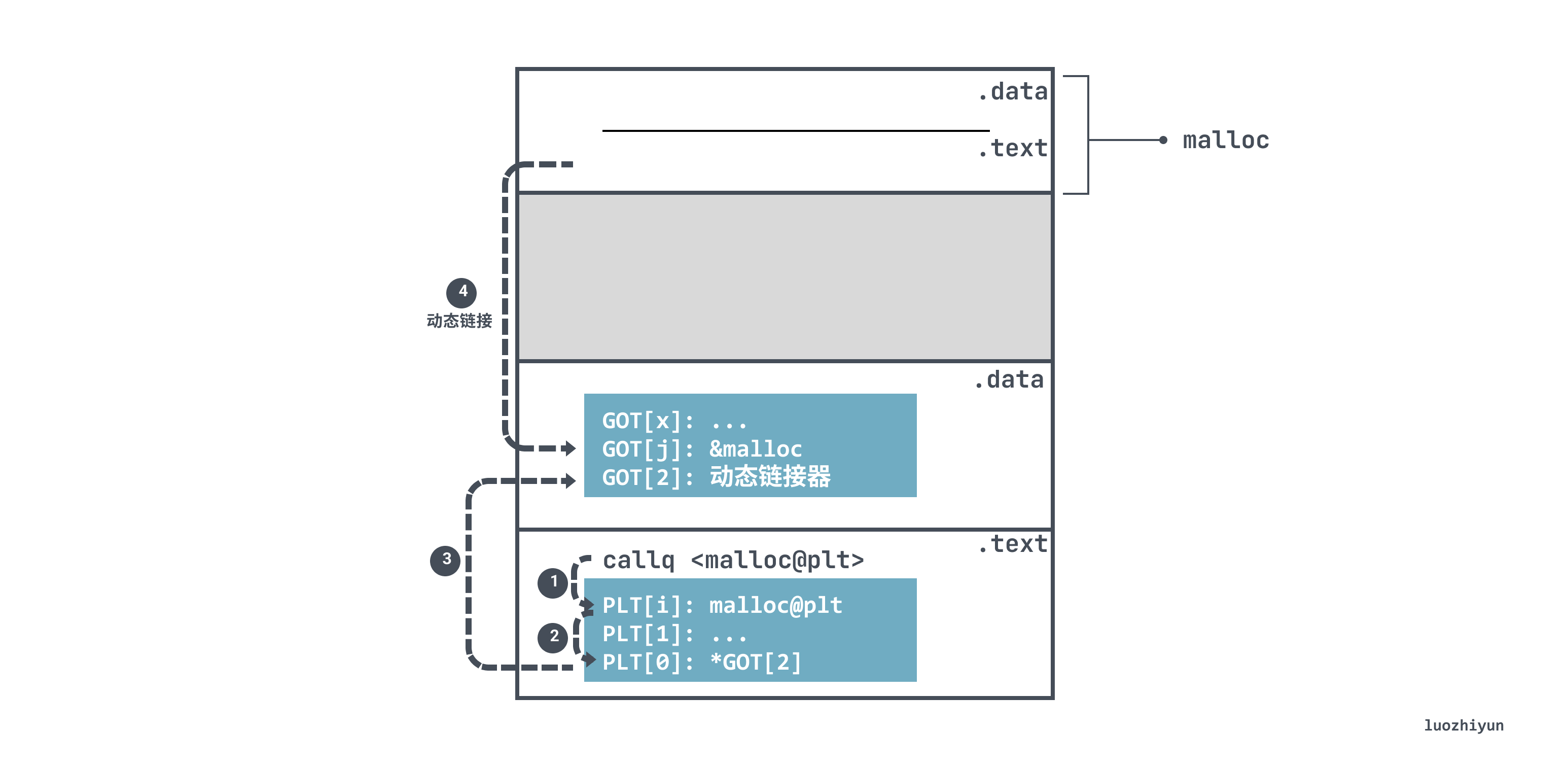
Taking the above malloc function call as an example, since the code in the .text segment does not know the running address of malloc, it will jump to the PLT entry malloc@plt corresponding to malloc when executing the call instruction:
115a: callq 1050 <malloc@plt>
malloc@plt takes advantage of the address independence and uses the relative offset to obtain the malloc address 0x3fd0 cached in the GOT table:
<malloc@plt>: 1054: bnd jmpq *0x2f75(%rip) # 3fd0 <malloc@GLIBC_2.2.5>
However, due to the delayed binding, the value in the GOT entry that jumps to when running for the first time is actually the location of the dynamic linker in <.plt>, and then jumps to the code segment of the dynamic linker. .
When the dynamic linker obtains the runtime address of malloc, it will fill the corresponding address value into the GOT entry. If malloc@plt is called again, when jmpq *0x2f75(%rip) is executed, the value in it is the real address of malloc. You can jump directly to malloc without going through the dynamic linker in the <.plt> item.
Summarize
This article actually consists of three parts in general:
-
Explains the ELF file structure to help us understand the linking process behind;
-
Through static linking, several processes generally included in linking are described;
-
Finally, I talked about the disadvantages of static linking, why there is dynamic linking, and how it does it.
Through the explanation of these parts, you can clearly see what the linker does during the connection process.
Reference
http://www.skyfree.org/linux/references/ELF_Format.pdf
http://chuquan.me/2018/06/03/linking-static-linking-dynamic-linking/
https://www.bilibili.com/video/BV17K4y1N7Q2?p=26&vd_source=f482469b15d60c5c26eb4833c6698cd5
https://github.com/yangminz/bcst_csapp
https://zhuanlan.zhihu.com/p/389408697
https://www.ucw.cz/~hubicka/papers/abi/node19.html
https://mp.weixin.qq.com/s/4ZsNOxHUHOeTk9eI1X0Tcg
“Programmer’s Self-Cultivation – Linking, Loading and Libraries”
“Understanding Computer Systems”

What exactly does a link do? first appeared on luozhiyun`s Blog .
This article is reproduced from: https://www.luozhiyun.com/archives/721
This site is for inclusion only, and the copyright belongs to the original author.