Original link: https://www.kawabangga.com/posts/4714
In a distributed system, if service A wants to call service B, and both services have multiple instances deployed, the problem of load balancing must be solved. That is, we want the QPS to reach B to be balanced across all instances of B.
In the previous implementation similar to HTTP/1.1, each time service A initiates a request, it needs to establish a TCP connection with B. Therefore, the implementation of load balancing is generally based on the number of connections. But every time a new connection is established, the performance will be very low. So there is a way to realize the long connection later: establish a TCP connection, send many requests on it, and reuse this TCP connection. gRPC is implemented based on HTTP/2 and uses this long connection method.
Using persistent connections will improve performance because you don’t have to re-establish a TCP connection every time. But there are some problems.
The first problem is load balancing. This Kubernetes blog explains why gRPC requires special load balancing. Obviously, in the HTTP/1.1 method, an instance is randomly selected to call each time, and the load is balanced. But HTTP/2, which always uses a connection, will always be used once the connection is made. Which instance is used depends on who is selected at the beginning.
Even if there is a way to balance the connections in the first place, there are some situations that break this balance. For example, restart the service instance one by one.
After each restart of an instance, the client that originally connected to this instance will disconnect from it and connect to other available instances instead. Therefore, there will be no connection after the first restarted instance is restarted. Other instances will increase: (1/n)/(n-1) * total connections connections. n is the total number of instances.
Because each instance restart will increase the number of connections of other instances, there are two problems:
- The first restarted instance will have the largest number of connections in the end, and the last restarted instance will have no connections, which is very unbalanced.
- The last restarted instance will cause a large number of clients to reconnect when restarting
The second problem is that when the server instance is added, there will be no client to connect to it. That is, the problem of server migration/online and offline. Because all clients use the previously established connections, they will not know that a new instance is available. In fact, it is almost the same as the first question.
There are 3 solutions to think of.
The first is to add a load balancer between the clinet and the server, as mentioned in the blog above, to maintain the connection to the backend. It can perfectly solve the above two problems. The disadvantage is that the resources will be relatively high, and the architecture will increase the complexity.
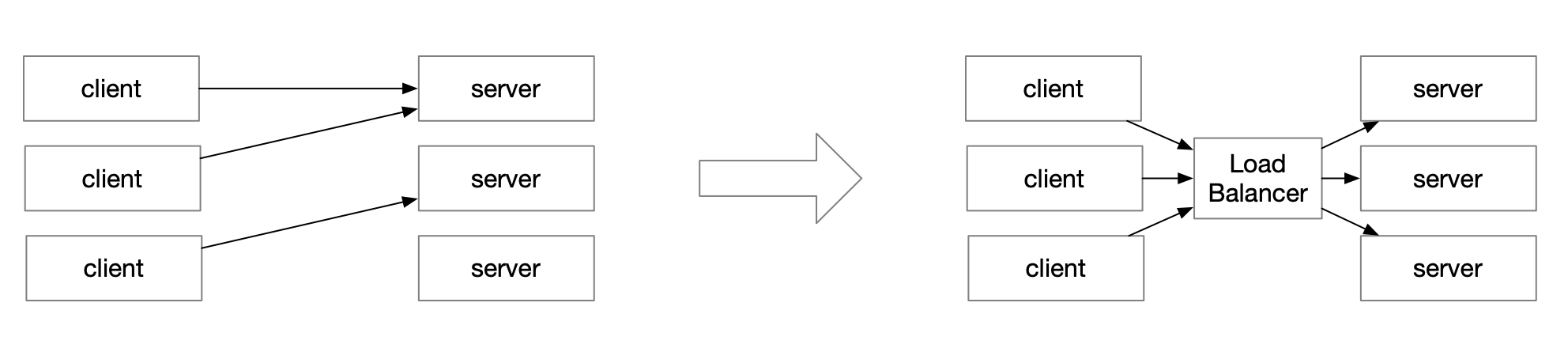
The second method is to solve it from the server side: the server side can send the GOAWAY command to the client from time to time, instructing the client to connect to another server instance. api-server has an option to specify how much probability to use to send this command to the client: –goaway-chance float.
To prevent HTTP/2 clients from getting stuck on a single apiserver, randomly close a connection (GOAWAY). The client’s other in-flight requests won’t be affected, and the client will reconnect, likely landing on a different apiserver after going through the load balancer again. This argument sets the fraction of requests that will be sent a GOAWAY. Clusters with single apiservers, or which don’t use a load balancer, should NOT enable this. Min is 0 (off), Max is .02 (1/50 requests); .001 (1/1000) is a recommended starting point.
Another advantage of this is that when you go offline, instead of rudely exiting, you can send the GOAWAY command to all your current connections. Then exit without damage.
The third method is to solve it from the client: the client does not use a single connection to connect to the server, but uses a connection pool:
- Every time the client wants to send a request, it needs to request an available connection from its own connection pool:
- At this time, if there is, return a connection
- If not, initiate a connection
- After using it, put the connection back into the connection pool
- The connection pool supports setting some parameters, such as:
- If idle for a certain period of time, close the connection
- After a connection has served a number of requests, or has been used for a number of times, it is closed and no longer used.
In this way, the problem that a connection is used indefinitely can be solved, and the closing of the connection is also lossless, because the connection in the connection pool is not used by anyone and is managed by the connection pool itself. In fact, database clients, such as jdbc, and Redis clients, are implemented in this way.
The post Issues with Long Connection Load Balancing first appeared on Kawabanga! .
related articles:
This article is reprinted from: https://www.kawabangga.com/posts/4714
This site is for inclusion only, and the copyright belongs to the original author.